 神经网络中的激活函数有哪些
神经网络中的激活函数有哪些
一、引言
在神经网络中,激活函数是一个至关重要的组成部分,它决定了神经元对于输入信号的反应方式,为神经网络引入了非线性因素,使得网络能够学习和处理复杂的模式。本文将详细介绍神经网络中常用的激活函数,包括其定义、特点、数学形式以及在神经网络中的作用和用途。
二、常用的激活函数
Sigmoid函数
Sigmoid函数是一种常用的S型激活函数,它将输入的实数映射到(0,1)之间。数学形式为:f(x) = 1 / (1 + e^(-x))。
优点:输出范围在(0,1)之间,可以表示概率;具有平滑的S形曲线,可以保持梯度的连续性,有利于反向传播算法的稳定性。
缺点:当输入较大或较小时,梯度会接近于零,导致梯度消失问题;输出不是以零为中心,可能导致梯度更新不均匀,影响训练速度。
Tanh函数(双曲正切函数)
Tanh函数也是一种S型激活函数,将输入的实数映射到(-1,1)之间。数学形式为:f(x) = (ex - e(-x)) / (ex + e(-x))。
优点:输出范围在(-1,1)之间,相比Sigmoid函数更广泛,可以提供更大的梯度,有利于神经网络的学习;是Sigmoid函数的平移和缩放版本,具有相似的S形曲线,但输出以零为中心,有助于减少梯度更新不均匀的问题。
缺点:在极端输入值时,梯度仍然会变得非常小,导致梯度消失的问题。
ReLU函数(Rectified Linear Unit,修正线性单元)
ReLU函数是一种简单而有效的激活函数,它将输入的实数映射到大于等于零的范围。数学形式为:f(x) = max(0, x)。
优点:在实践中,ReLU函数比Sigmoid和Tanh函数更快地收敛;当输入为正时,ReLU函数的梯度为常数,避免了梯度消失的问题;计算简单,只需比较输入和零的大小即可,运算速度快。
缺点:当输入为负时,ReLU函数的梯度为0,这被称为“神经元死亡”现象,可能导致一些神经元永远不会被激活,影响模型的表达能力;ReLU函数输出不包括负值,这可能会导致一些神经元的输出偏向于0。
Leaky ReLU函数
Leaky ReLU函数是对ReLU函数的改进,它解决了ReLU函数在负数部分输出为零的问题。数学形式为:f(x) = max(αx, x),其中α是一个小的正数(如0.01)。
优点:Leaky ReLU函数解决了ReLU函数的“死亡”现象,使得神经元可以在输入为负时被激活;保留了ReLU函数的快速计算速度。
缺点:需要额外的超参数α,这增加了模型的复杂性;当α设置不当时,Leaky ReLU函数可能会导致神经元输出过大或过小,影响模型的表达能力。
ELU函数(Exponential Linear Unit,指数线性单元)
ELU函数也是ReLU函数的一种改进形式,它在负数部分采用指数函数来避免“死亡”现象。数学形式为:f(x) = x(如果x > 0),α(e^x - 1)(如果x ≤ 0),其中α是一个超参数。
优点:解决了ReLU函数的“死亡”现象;当输入为负时,ELU函数具有负饱和度,这有助于提高模型的鲁棒性;ELU函数的输出可以被归一化,这有助于模型的训练。
缺点:需要计算指数函数,这可能会增加模型的计算复杂度;当输入为正时,ELU函数的梯度仍然可能变得非常小,导致梯度消失的问题。
Softmax函数
Softmax函数通常用于多分类问题的输出层,它将神经网络的原始输出转换为概率分布。数学形式为:f(x)_i = e^(x_i) / Σ_j e^(x_j),其中x_i表示第i个神经元的输出,Σ_j e^(x_j)表示所有神经元输出的指数和。
优点:可以将输出映射到概率空间,适用于分类问题;在多分类问题中表现良好。
缺点:可能会导致梯度消失或梯度爆炸的问题;计算复杂度较高,特别是在输出维度较大时。
三、总结
激活函数在神经网络中扮演着重要的角色,它们为神经网络引入了非线性因素,使得网络能够学习和处理复杂的模式。不同的激活函数具有不同的特点和优缺点,适用于不同的任务和数据集。在选择激活函数时,需要根据具体的应用场景和需求进行权衡和选择。同时,随着深度学习技术的不断发展,新的激活函数也不断被提出和应用,为神经网络的优化和改进提供了新的思路和方法
-
神经网络
+关注
关注
42文章
4771浏览量
100704 -
函数
+关注
关注
3文章
4327浏览量
62567 -
神经元
+关注
关注
1文章
363浏览量
18449
发布评论请先 登录
相关推荐
【PYNQ-Z2试用体验】神经网络基础知识
【案例分享】ART神经网络与SOM神经网络
神经网络移植到STM32的方法
ReLU到Sinc的26种神经网络激活函数可视化大盘点

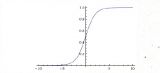
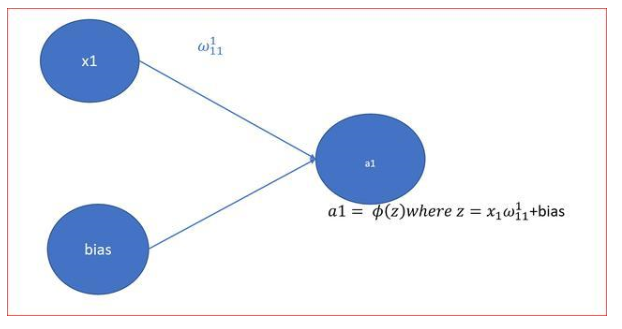
神经网络初学者的激活函数指南
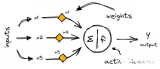
神经网络初学者的激活函数指南






 工商网监
工商网监
评论