 人脸检测模型的精确度怎么算
人脸检测模型的精确度怎么算
人脸检测模型的精确度评估是一个复杂的过程,涉及到多个方面的因素。本文将从以下几个方面进行介绍:人脸检测模型的基本概念、评估指标、评估方法、影响因素以及提高精确度的策略。
- 人脸检测模型的基本概念
人脸检测是计算机视觉领域的一个重要研究方向,其目的是在图像或视频中快速准确地定位人脸的位置。人脸检测模型通常包括两个主要步骤:人脸候选区域的生成和人脸的分类。人脸候选区域的生成通常采用滑窗法、特征点法等方法,而人脸分类则采用深度学习、支持向量机等算法。
- 评估指标
评估人脸检测模型的精确度通常需要考虑以下几个指标:
2.1 准确率(Accuracy)
准确率是最直观的评估指标,表示模型正确检测到的人脸数量与总人脸数量的比例。计算公式为:
[ Accuracy = frac{TP + TN}{TP + TN + FP + FN} ]
其中,TP(True Positive)表示正确检测到的人脸数量,TN(True Negative)表示正确未检测到的人脸数量,FP(False Positive)表示错误检测到的人脸数量,FN(False Negative)表示未检测到的人脸数量。
2.2 精确度(Precision)
精确度表示模型检测到的人脸中,真正是人脸的比例。计算公式为:
[ Precision = frac{TP}{TP + FP} ]
2.3 召回率(Recall)
召回率表示所有真实人脸中,被模型检测到的比例。计算公式为:
[ Recall = frac{TP}{TP + FN} ]
2.4 F1分数(F1 Score)
F1分数是精确度和召回率的调和平均值,用于综合考虑两者的性能。计算公式为:
[ F1 = 2 times frac{Precision times Recall}{Precision + Recall} ]
2.5 平均精度(Average Precision, AP)
平均精度是在不同阈值下计算的精确度的平均值,用于评估模型在不同置信度下的性能。计算公式为:
[ AP = sum_{i=1}^{n} P_i times (R_{i} - R_{i-1}) ]
其中,P_i表示第i个阈值下的精确度,R_i表示第i个阈值下的召回率。
- 评估方法
3.1 交叉验证(Cross-validation)
交叉验证是一种常用的评估方法,通过将数据集分为训练集和测试集,对模型进行多次训练和测试,以评估模型的泛化能力。常见的交叉验证方法有K折交叉验证(K-fold Cross-validation)。
3.2 混淆矩阵(Confusion Matrix)
混淆矩阵是一种可视化评估方法,通过将模型的预测结果与真实结果进行对比,生成一个表格,直观地展示模型的性能。
3.3 接收者操作特征曲线(Receiver Operating Characteristic Curve, ROC Curve)
ROC曲线是一种评估模型性能的方法,通过绘制真正类率(True Positive Rate, TPR)和假正类率(False Positive Rate, FPR)之间的关系,评估模型在不同阈值下的性能。
- 影响因素
4.1 数据集的质量
数据集的质量直接影响模型的性能。数据集中的人脸图像应具有多样性,包括不同年龄、性别、种族、表情、光照条件等。此外,数据集的标注质量也非常重要,错误的标注会导致模型学习到错误的特征。
4.2 模型的复杂度
模型的复杂度决定了模型的学习能力。过于简单的模型可能无法捕捉到人脸的特征,而过于复杂的模型可能导致过拟合。因此,选择合适的模型复杂度是提高精确度的关键。
4.3 训练策略
训练策略包括学习率、批大小、迭代次数等。合适的训练策略可以加速模型的收敛速度,提高模型的性能。
4.4 正则化方法
正则化方法可以防止模型过拟合,提高模型的泛化能力。常见的正则化方法有L1正则化、L2正则化、Dropout等。
4.5 模型融合
模型融合是一种提高精确度的方法,通过结合多个模型的预测结果,提高整体性能。常见的模型融合方法有投票法、堆叠法、加权平均法等。
- 提高精确度的策略
5.1 数据增强
数据增强是一种提高模型泛化能力的方法,通过对原始数据进行旋转、缩放、翻转等操作,生成新的训练样本,增加数据集的多样性。
5.2 特征提取
特征提取是提高模型性能的关键。可以通过深度学习、传统机器学习等方法提取人脸的特征,提高模型的识别能力。
-
模型
+关注
关注
1文章
3226浏览量
48806 -
人脸检测
+关注
关注
0文章
80浏览量
16457 -
计算机视觉
+关注
关注
8文章
1698浏览量
45968
发布评论请先 登录
相关推荐
准确度、精密度和精确度
高精确度无需校准的温度测量怎么实现?
YOLOv5全面解析教程之目标检测模型精确度评估
提高霍尔传感器精确度的研究
提高回弹法检测混凝土抗压强度精确度的探讨
什么是GPS设备安装位置精确度
电流检测精确度的影响要素

工程师设计分析:影响电流检测精确度的几种规范
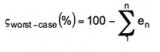
基于时间约束的精确度模型预测方法






 工商网监
工商网监
评论