 深度神经网络(DNN)架构解析与优化策略
深度神经网络(DNN)架构解析与优化策略
引言
深度神经网络(Deep Neural Network, DNN)作为机器学习领域中的一种重要技术,以其强大的特征学习能力和非线性建模能力,在多个领域取得了显著成果。DNN的核心在于其多层结构,通过堆叠多个隐藏层,逐步提取和转化输入数据的特征,最终实现复杂的预测和分类任务。本文将对DNN的架构进行详细解析,并探讨其优化策略,以期为相关研究和应用提供参考。
DNN架构解析
基本结构
DNN主要由输入层、隐藏层和输出层组成,每层之间通过权重连接。
- 输入层(Input Layer) :接收原始数据,如图像像素、文本向量等。输入层的数据通常需要进行预处理,如归一化、标准化等,以便后续处理。
- 隐藏层(Hidden Layers) :DNN的核心部分,包含一个或多个隐藏层。每个隐藏层由多个神经元组成,每个神经元接收来自前一层的输出,并通过加权求和及非线性激活函数产生本层的输出。隐藏层之间的连接形成了网络的深度,使得DNN能够捕捉复杂的数据关系和模式。
- 输出层(Output Layer) :最后一层,生成网络的最终输出,如类别概率、回归值等。输出层的结构和激活函数取决于具体任务的需求。
神经元与激活函数
每个神经元接收来自前一层的所有神经元的连接(称为权重),加上一个偏置项,然后通过一个非线性激活函数产生自身的输出。常见的激活函数包括Sigmoid、Tanh、ReLU及其变种(如Leaky ReLU、Parametric ReLU)等。这些激活函数赋予网络非线性表达能力,使得DNN能够处理复杂的非线性问题。
工作原理
DNN的工作原理主要包括前向传播和反向传播两个过程。
- 前向传播(Forward Propagation) :从输入层开始,依次计算各层神经元的输出,直至得到输出层的结果。此过程用于预测给定输入的输出。
- 反向传播(Backpropagation) :利用链式法则计算损失函数关于每个权重和偏置项的梯度,这些梯度指示了如何调整权重以减小损失。反向传播是深度学习中最重要的算法之一,它允许网络学习并更新其参数。
DNN优化策略
损失函数与优化算法
DNN的训练目标是通过调整网络权重和偏置参数来最小化损失函数。常见的损失函数包括均方误差(MSE)用于回归任务,交叉熵损失(Cross-Entropy Loss)用于分类任务。优化算法则包括梯度下降法(含其变种如批量梯度下降、随机梯度下降、小批量梯度下降)以及更先进的优化算法如Adam、RMSProp等。这些优化算法利用反向传播计算出的梯度更新权重和偏置,逐步迭代优化模型。
正则化与Dropout
为了防止DNN过拟合,通常需要使用正则化技术。L1和L2正则化通过对权重施加惩罚项来约束模型复杂度。另一种常用的正则化手段是Dropout,它随机“丢弃”一部分神经元的输出,有助于提高模型泛化能力。
学习率调整与初始化策略
学习率的选择对模型训练至关重要。合适的初始学习率可以加快训练进程,后期可能需要逐渐减小以微调模型。常见的学习率调整策略包括学习率衰减、指数衰减、余弦退火等。此外,初始化权重的策略对训练过程也有很大影响。常见的有随机初始化(如Xavier初始化和He初始化),它们确保了在网络初始化阶段输入和输出信号的方差不会发生太大变化。
批量大小与计算资源
批量大小是指每次更新权重时使用的样本数量。过大可能导致收敛慢,过小则可能导致训练不稳定。选择合适的批量大小有助于优化训练过程。此外,DNN的训练和推断通常需要大量的计算资源,包括高性能计算机、图形处理器(GPU)等。硬件加速和模型压缩技术(如量化、剪枝)有助于降低成本。
深度与宽度
DNN的深度和宽度对其性能有重要影响。一般来说,更深的网络能够捕捉更复杂的数据模式和特征,但也可能导致梯度消失或梯度爆炸问题。更宽的网络则能够同时处理更多的特征,但也可能增加计算复杂度和过拟合风险。因此,在设计DNN架构时,需要根据具体任务和数据集的特点来选择合适的深度和宽度。
应用案例与性能分析
图像分类
DNN在图像分类领域取得了显著成果。例如,AlexNet、VGG、Inception系列、ResNet等深度神经网络结构在ImageNet大规模视觉识别挑战赛中取得了突破性成果。这些模型通过引入残差学习、批量归一化等技术,成功解决了深度神经网络训练过程中的梯度消失问题,提高了识别准确率。
语音识别
DNN在语音识别领域的应用也取得了显著成效。例如,谷歌的DeepMind团队开发的WaveNet模型,就是一种基于深度神经网络的语音合成系统,能够生成高度自然流畅的语音。WaveNet采用了自回归的卷积神经网络结构,通过堆叠多个卷积层来捕捉音频信号中的时序依赖关系,实现了高质量的语音合成。此外,DNN还被广泛应用于语音识别任务中,通过提取音频信号中的特征并映射到对应的文本标签,实现了高精度的语音转文字功能。
自然语言处理
在自然语言处理(NLP)领域,DNN同样发挥了重要作用。随着Transformer模型的提出,基于自注意力机制的深度神经网络成为了NLP领域的主流架构。Transformer通过自注意力层捕捉输入序列中任意两个位置之间的依赖关系,极大地提高了模型处理长距离依赖的能力。基于Transformer的模型,如BERT、GPT系列等,在文本分类、情感分析、机器翻译、文本生成等多个任务上取得了卓越的性能。这些模型通过预训练大量文本数据,学习到了丰富的语言知识表示,能够灵活应用于各种NLP任务。
深度强化学习
深度强化学习(Deep Reinforcement Learning, DRL)是深度学习与强化学习的结合体,它通过DNN来近似强化学习中的价值函数或策略函数,从而解决复杂环境中的决策问题。在DRL中,DNN作为智能体的“大脑”,通过不断与环境交互来学习最优策略。AlphaGo和AlphaZero等围棋AI就是DRL的成功案例,它们通过DNN和蒙特卡洛树搜索的结合,在围棋领域达到了超越人类的水平。
未来展望
随着计算能力的提升和算法的不断创新,DNN的架构和优化策略将继续发展。以下几个方面可能成为未来的研究方向:
- 更高效的模型结构 :研究更加紧凑、高效的DNN结构,以减少计算复杂度和内存占用,同时保持或提升模型性能。
- 自适应学习率与优化算法 :开发能够根据训练过程中数据分布和模型状态自适应调整学习率的优化算法,以提高训练效率和稳定性。
- 可解释性增强 :提升DNN模型的可解释性,使其决策过程更加透明和可理解,有助于在实际应用中建立信任。
- 跨模态学习与融合 :研究如何有效地结合不同模态的数据(如图像、文本、音频等)进行学习和推理,以捕捉更丰富的信息。
- 量子神经网络 :随着量子计算技术的发展,探索量子神经网络(QNN)的潜力和应用前景,可能带来计算能力和模型性能的飞跃。
总之,DNN作为深度学习的重要分支,其架构优化和应用研究将继续推动人工智能技术的发展和进步。通过不断的技术创新和实践应用,我们有理由相信DNN将在更多领域发挥更大的作用,为人类社会带来更多便利和价值。
-
机器学习
+关注
关注
66文章
8406浏览量
132553 -
深度神经网络
+关注
关注
0文章
61浏览量
4524 -
dnn
+关注
关注
0文章
60浏览量
9051
发布评论请先 登录
相关推荐

从AlexNet到MobileNet,带你入门深度神经网络
深度神经网络是什么
可分离卷积神经网络在 Cortex-M 处理器上实现关键词识别
基于深度神经网络的激光雷达物体识别系统
一文带你了解(神经网络)DNN、CNN、和RNN
浅析深度神经网络(DNN)反向传播算法(BP)
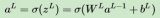





 工商网监
工商网监
评论