 神经网络专用硬件实现的方法和技术
神经网络专用硬件实现的方法和技术
神经网络专用硬件实现是人工智能领域的一个重要研究方向,旨在通过设计专门的硬件来加速神经网络的训练和推理过程,提高计算效率和能效比。以下将详细介绍神经网络专用硬件实现的方法和技术,并附上相关的代码示例。
一、神经网络专用硬件实现的主要方法
- FPGA(现场可编程门阵列)实现
FPGA是一种半定制电路,具有大量的通用逻辑单元和可编程的连接。通过编程,FPGA可以实现特定的神经网络结构和算法,从而加速神经网络的计算。FPGA的优点在于其可重配置性和高并行性,非常适合于实现复杂的神经网络模型。
代码示例 (假设使用Verilog或VHDL语言):
// 示例:FPGA实现简单的神经网络层
module neural_layer(
input wire [7:0] in_data[16:0], // 假设有17个8位输入
input wire [7:0] weights[16:0][8:0], // 权重,假设每个神经元连接9个输入(包括偏置)
output reg [7:0] out_data[8:0] // 假设有9个神经元输出
);
// 激活函数(简单示例,实际应用中可能需要更复杂的实现)
always @(in_data, weights) begin
for (int i = 0; i < 9; i = i + 1) begin
integer sum = 0;
for (int j = 0; j < 17; j = j + 1) begin
sum = sum + (in_data[j] * weights[j][i]);
end
// 添加偏置(这里假设weights[16][i]为偏置)
sum = sum + weights[16][i];
// 简单的ReLU激活函数
if (sum > 0)
out_data[i] = sum;
else
out_data[i] = 0;
end
end
endmodule
- ASIC(应用特定集成电路)实现
ASIC是为特定应用定制的集成电路,与FPGA相比,ASIC具有更高的性能和更低的功耗,但设计成本和时间也更高。神经网络处理器(NNP)和神经网络加速器(NNA)是典型的ASIC实现方式。
描述 :NNP和NNA通常包含多个处理单元(PE),每个PE可以执行神经网络中的基本计算(如乘法累加、激活函数等)。这些处理单元通过高效的数据通路和内存结构连接,以实现高并行度的计算。 - GPU(图形处理器)和TPU(张量处理器)
GPU和TPU虽然不是专门为神经网络设计的硬件,但由于其强大的并行计算能力,被广泛应用于神经网络的训练和推理中。GPU擅长处理大规模并行浮点数运算,而TPU则针对机器学习进行了专门的优化。
描述 :GPU通过大量的计算核心(CUDA核心或流处理器)和高速显存,可以同时处理大量的神经网络计算任务。TPU则通过其专门的矩阵乘法单元和高效的内存管理,进一步提高了神经网络的计算效率。 - 光处理器和量子处理器
光处理器和量子处理器是新兴的神经网络硬件实现方式,它们利用光学和量子物理学的原理来实现神经网络的计算。这些技术仍处于研究阶段,但具有巨大的潜力。
描述 :光处理器利用光子的高速传输和并行处理能力,可以实现超高速的神经网络计算。量子处理器则利用量子比特的叠加和纠缠特性,实现比经典计算机更高效的计算。
二、神经网络专用硬件实现的技术
- 并行计算技术
神经网络计算具有高度并行的特点,因此并行计算技术是神经网络专用硬件实现的关键。通过设计高效的并行计算架构和算法,可以显著提高神经网络的计算效率。 - 数据量化与低精度计算
神经网络模型通常使用浮点数进行计算,但浮点数计算需要较高的计算资源和能耗。通过将模型参数和计算过程进行量化和低精度化(如使用8位或16位整数代替32位浮点数),可以减少计算和存储开销,提高神经网络的运行速度。 - 模型剪枝与压缩
神经网络模型通常具有大量的参数和冗余连接,这导致了计算和存储开销的增加。通过模型剪枝和压缩技术,可以去除冗余的参数和连接,从而减少模型的大小和计算量,提高模型的运行效率。 - 存储优化技术
神经网络计算需要大量的内存来存储权重、输入数据和中间结果。通过设计高效的存储结构和数据访问模式(如使用缓存、数据重用等),可以减少内存访问次数和降低数据移动的开销,从而提高神经网络的执行效率。 - 定制化指令集
为了进一步提高神经网络的计算效率,许多神经网络专用硬件会设计定制化的指令集。这些指令集针对神经网络中常见的计算模式进行了优化,如矩阵乘法、卷积操作、池化操作等。通过使用这些定制化指令,可以减少指令数量和计算延迟,提高硬件的利用率和性能。 - 自动化设计工具
随着神经网络硬件的复杂性增加,手动设计硬件变得越来越困难且耗时。因此,自动化设计工具在神经网络专用硬件实现中发挥着越来越重要的作用。这些工具可以根据神经网络的架构和需求,自动生成硬件描述语言(HDL)代码或布局布线文件,大大简化了设计流程并提高了设计效率。 - 电源管理和热管理技术
神经网络专用硬件通常需要处理大量的数据和计算任务,这会导致较高的功耗和热量产生。因此,电源管理和热管理技术对于确保硬件的稳定运行和延长使用寿命至关重要。这些技术包括动态电压频率调整(DVFS)、低功耗待机模式、以及有效的散热设计等。
三、未来趋势和展望
- 异构计算
随着神经网络应用的不断扩展,单一类型的硬件已经难以满足所有需求。因此,异构计算成为了一个重要的趋势。通过将不同类型的硬件(如GPU、FPGA、ASIC等)组合在一起,可以充分发挥各自的优势,实现更高效的神经网络计算。 - 边缘计算
随着物联网和智能设备的普及,边缘计算变得越来越重要。将神经网络模型部署到边缘设备上,可以实现更快的响应时间和更低的延迟。因此,未来神经网络专用硬件将更加注重低功耗、小体积和高效能的设计,以适应边缘计算的需求。 - 可重构计算
可重构计算是一种介于FPGA和ASIC之间的硬件实现方式。它可以在运行时动态地改变硬件的配置,以适应不同的计算任务。这种灵活性使得可重构计算在神经网络专用硬件中具有很大的潜力,可以根据不同的网络结构和应用需求进行优化。 - 新型材料和技术
随着新型材料和技术的发展,如量子计算、光计算、神经形态计算等,未来神经网络专用硬件的实现方式也将发生革命性的变化。这些新技术有望带来更高的计算速度和更低的能耗,为神经网络的发展提供新的动力。
结论
神经网络专用硬件实现是人工智能领域的一个重要研究方向,通过设计专门的硬件来加速神经网络的训练和推理过程,可以显著提高计算效率和能效比。本文介绍了神经网络专用硬件实现的主要方法和技术,包括FPGA、ASIC、GPU/TPU、光处理器和量子处理器等,并探讨了并行计算、数据量化与低精度计算、模型剪枝与压缩、存储优化、定制化指令集、自动化设计工具以及电源管理和热管理等技术。同时,本文还展望了神经网络专用硬件的未来趋势和发展方向,包括异构计算、边缘计算、可重构计算以及新型材料和技术等。随着技术的不断进步和创新,相信神经网络专用硬件将在未来的人工智能应用中发挥更加重要的作用。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表德赢Vwin官网
网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
FPGA
+关注
关注
1629文章
21729浏览量
602960 -
神经网络
+关注
关注
42文章
4771浏览量
100708 -
人工智能
+关注
关注
1791文章
47183浏览量
238209
发布评论请先 登录
相关推荐
labview BP神经网络的实现
请问:我在用labview做BP神经网络实现故障诊断,在NI官网找到了机器学习工具包(MLT),但是里面没有关于这部分VI的帮助文档,对于”BP神经网络分类“这个范例有很多不懂的地方,比如
发表于 02-22 16:08
基于赛灵思FPGA的卷积神经网络实现设计
FPGA 上实现卷积神经网络 (CNN)。CNN 是一类深度神经网络,在处理大规模图像识别任务以及与机器学习类似的其他问题方面已大获成功。在当前案例中,针对在 FPGA 上实现 CN
发表于 06-19 07:24
人工神经网络实现方法有哪些?
人工神经网络(Artificial Neural Network,ANN)是一种类似生物神经网络的信息处理结构,它的提出是为了解决一些非线性,非平稳,复杂的实际问题。那有哪些办法能实现人工神经
发表于 08-01 08:06
如何设计BP神经网络图像压缩算法?
神经网络的并行特点,而且它还可以根据设计要求配置硬件结构,例如根据实际需要,可灵活设计数据的位宽等。随着数字集成电路技术的飞速发展,FPGA芯片的处理能力得到了极大的提升,已经完全可以承担神经
发表于 08-08 06:11
如何构建神经网络?
原文链接:http://tecdat.cn/?p=5725 神经网络是一种基于现有数据创建预测的计算系统。如何构建神经网络?神经网络包括:输入层:根据现有数据获取输入的层隐藏层:使用反向传播优化输入变量权重的层,以提高模型的预测
发表于 07-12 08:02
神经网络移植到STM32的方法
将神经网络移植到STM32最近在做的一个项目需要用到网络进行拟合,并且将拟合得到的结果用作控制,就在想能不能直接在单片机上做神经网络计算,这样就可以实时计算,不依赖于上位机。所以要解决的主要是两个
发表于 01-11 06:20
基于FPGA的人工神经网络实现方法的研究
基于FPGA的人工神经网络实现方法的研究
引 言 人工神经网络(Artificial Neural Network,ANN)是一种类似生物
发表于 11-17 17:17
•1224次阅读
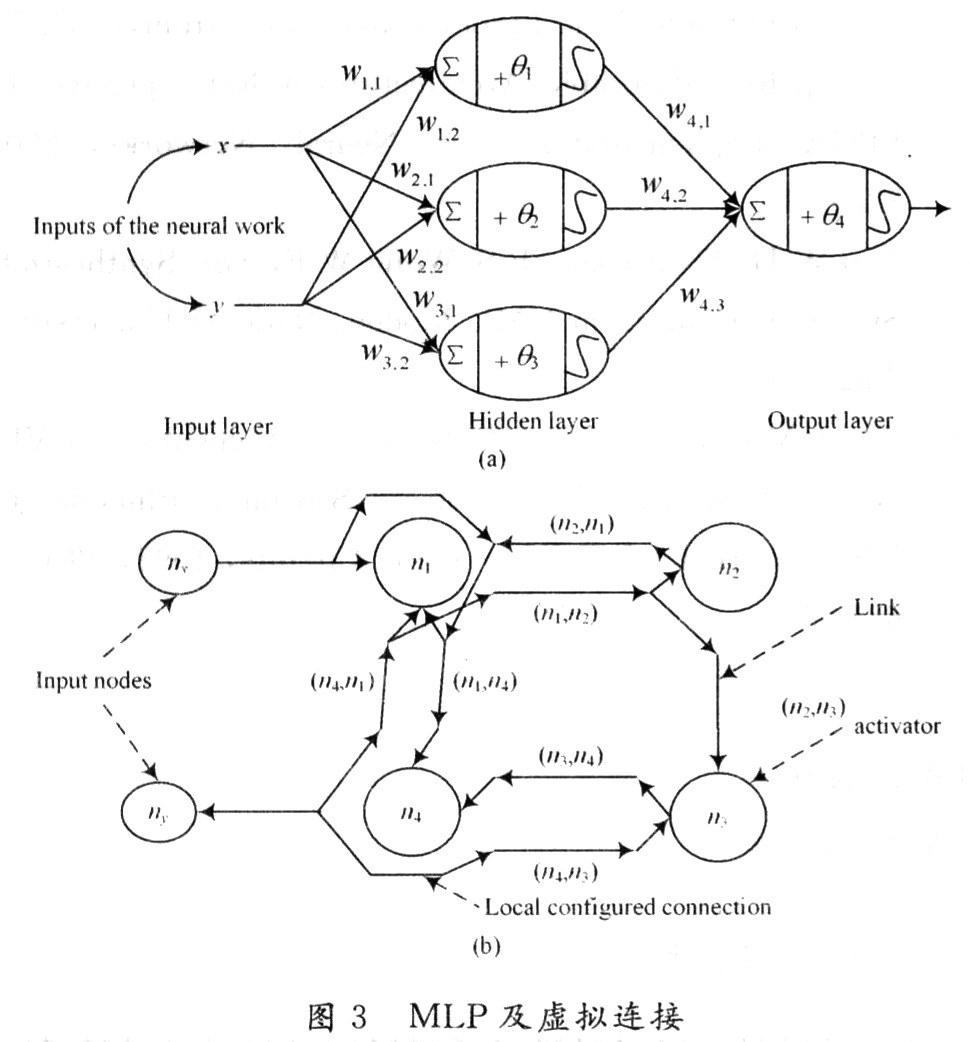
基于FPGA的人工神经网络实现方法的研究
基于FPGA的人工神经网络实现方法的研究
引言
人工神经网络(ArtificialNeuralNetwork,ANN)是一种类似生物神经网
发表于 11-21 16:25
•4796次阅读
如何使用FPGA实现神经网络硬件的设计方法
提出了一种可以灵活适应不同的工程应用中神经网络在规模、拓扑结构、传递函数和学习算法上的变化,并能及时根据市场需求快速建立原型的神经网络硬件可重构实现
发表于 02-02 17:12
•6次下载
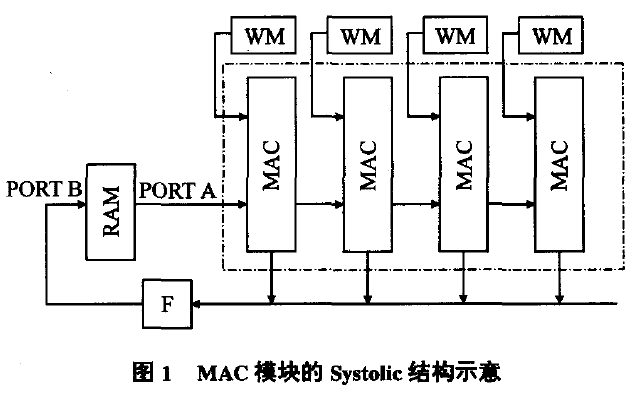

递归神经网络的实现方法
(Recurrent Neural Network,通常也简称为RNN,但在此处为区分,我们将循环神经网络称为Recurrent RNN)不同,递归神经网络更侧重于处理树状或图结构的数据,如句法分析树、自然语言的语法结构等。以下将从递归





 工商网监
工商网监
评论