 算力服务器为什么选择GPU
算力服务器为什么选择GPU
随着人工智能技术的快速普及,算力需求日益增长。智算中心的服务器作为支撑大规模数据处理和计算的核心设备,其性能优化显得尤为关键。而GPU服务器也进入了大众的视野,成为高性能计算的首选。那么,为什么算力服务器会选择GPU而不是传统的CPU呢?
GPU和CPU的区别
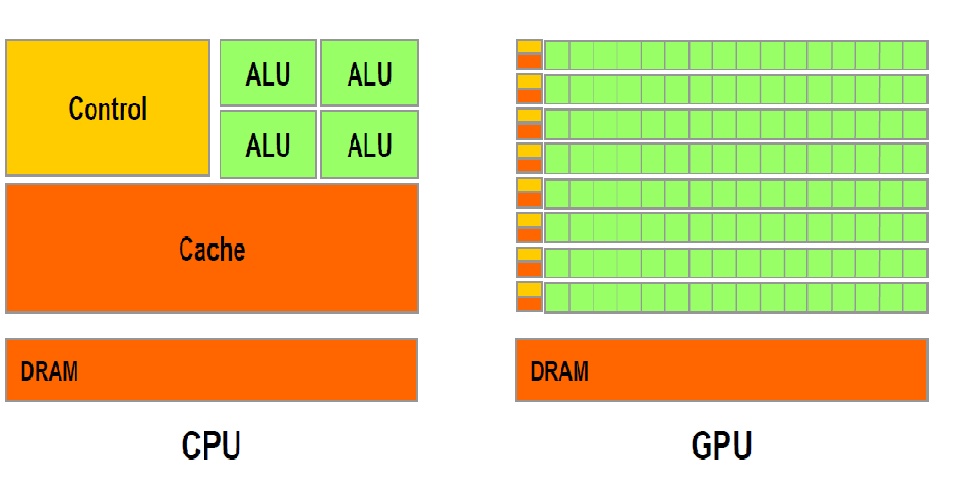
GPU和CPU二者都由寄存器、控制器、逻辑单元构成,但结构和比例很大不同,决定了CPU擅长指令处理,函数调用上,单核计算能力极强;GPU在数据处理(数学运算/逻辑运算)能力更强,它的核心特点是拥有大量的并行处理单元,可以同时处理大量简单、重复的计算任务。并行处理能力使得GPU在处理大规模数据集、进行矩阵运算等任务时具有显著优势。
一台500万的微型服务器,CPU核心数一般也就上千个,而GPU因为独特的架构,天然支持多线程,一块30万左右的显卡能够轻松支持18000的核心,且拥有自己的独立内存,有自己的一套指令集合,和多级缓存,也能够单独计算。
而GPU相对于CPU另一个比较重要的优势就是内存结构:在已经披露的显卡性能参数中,每个流处理器集群末端设有共享内存。相比于CPU每次操作数据都要返回内存再进行调用,GPU线程之间的数据通讯不需要访问全局内存,而在共享内存中就可以直接访问。这种设置的带来最大的好处就是线程间通讯速度的提高。
目前GPU上普遍采用GDDR6的显存颗粒,始终比主机内存领先一级,不仅具有更高的工作频率从而带来更快的数据读取/写入速度,而且具有更大的显存带宽。而在CPU构架中,尽管有高速缓存(Cache)的存在,但是由于其容量较小,大量的数据只能存放在内存(RAM)中。进行数据处理时,数据要从内存中读取然后在CPU中运算最后返回内存中。与之相比,大显存带宽的GPU具有更大的数据吞吐量。在大规模深度神经网络的训练中,必然带来更大的优势。
GPU在能效比和成本效益方面的优势
随着制造工艺的不断提高,GPU的能效比得到了显著提高。这意味着在相同功耗下,GPU可以提供更高的计算能力。在处理大规模数据集时能够显著缩短计算时间,从而提高整体效率。从成本效益的角度来看,虽然GPU的单价较高,但在处理大规模数据时,其总体成本远低于使用大量CPU的方案。
市场趋势和生态系统的发展也为GPU在算力服务器领域的应用提供了有力支持。随着深度学习、人工智能等技术的广泛应用,越来越多的企业和研究机构开始投资研发基于GPU的高性能计算平台。这推动了GPU硬件和软件的不断发展,形成了庞大的生态系统。在这个生态系统中,各种优化算法、框架和工具不断涌现,使得GPU在算力服务器领域的应用变得更加便捷和高效。
GPU服务器能替代传统服务器吗
尽管GPU在算力服务器领域具有诸多优势,但并不意味着它可以完全取代CPU。在实际应用中,CPU和GPU各有擅长领域,它们之间的协同作用才能更好地发挥整体性能。例如,在一些复杂的控制流程、逻辑判断和数据处理任务中,CPU仍然具有不可替代的优势。因此,在构建高性能计算系统时,需要根据具体应用场景和需求来合理配置CPU和GPU的比例和类型。
此外GPU服务器因为基本都是多张显卡同时工作,一般都至少4至6张,有的甚至达到10张以上,其功耗是数据服务器的几倍甚至十几倍,以前的普通机房根本无法承载如此的高能耗。从成本来看,对于处理传统业务来,还是CPU服务器更为合适。
综上所述,算力服务器选择GPU而不是CPU的原因,主要包括GPU在结构和工作原理上的优势、算力需求的变化、能效比和成本效益的考量以及市场趋势和生态系统的发展。在未来,随着技术的不断进步和应用需求的不断变化,我们有理由相信GPU在算力服务器领域的应用将会更加广泛和深入。
来源:互盟数据中心
-
cpu
+关注
关注
68文章
10853浏览量
211563 -
gpu
+关注
关注
28文章
4729浏览量
128882 -
服务器
+关注
关注
12文章
9123浏览量
85318 -
算力
+关注
关注
1文章
964浏览量
14790
发布评论请先 登录
相关推荐
“算力”的分层定义-初级算力
如何为深度学习选择 GPU 服务器?_目前哪里可以租用到GPU服务器?_gpu服务器出租价格
GPU服务器到底是什么?GPU服务器与普通服务器到底有什么区别
热虹吸散热技术解决GPU服务器散热问题
GPU服务器与FPGA云服务器的区别介绍

高算力AI模组前沿应用:基于ARM架构的SoC阵列式服务器

gpu服务器是干什么的 gpu服务器与cpu服务器的区别

AI高算力服务器散热,需要用到哪些导热界面材料?






 工商网监
工商网监
评论