 高并发系统的艺术:如何在流量洪峰中游刃有余
高并发系统的艺术:如何在流量洪峰中游刃有余
前言
我们常说的三高,高并发、高可用、高性能,这些技术是构建现代互联网应用程序所必需的。对于京东618备战来说,所有的中台系统服务,无疑都是围绕着三高来展开的。而对于京东庞大的客户群体,高并发的要求尤为重要。用户对在线服务的需求和期望不断提高,系统的并发处理能力成为衡量其性能和用户体验的关键指标之一。高并发系统不仅仅是大型互联网企业的专利,对于任何希望在市场中占据一席之地的公司来说,能够处理大量并发请求的能力都是至关重要的。
高并发系统的设计和实现是一个复杂且多层次的过程,涉及到硬件资源的合理利用、系统架构的精心设计、并发控制技术的应用以及性能调优等多个方面。无论是电商平台在大促期间应对突发流量,还是社交媒体在热点事件发生时的流量激增,抑或是金融系统在交易高峰期的平稳运行,都需要一个高效、稳定、可扩展的高并发系统作为支撑。
接下来我通过一张思维导图展开我的分享,帮大家梳理一下一个高并发系统所需要考虑的技术点。
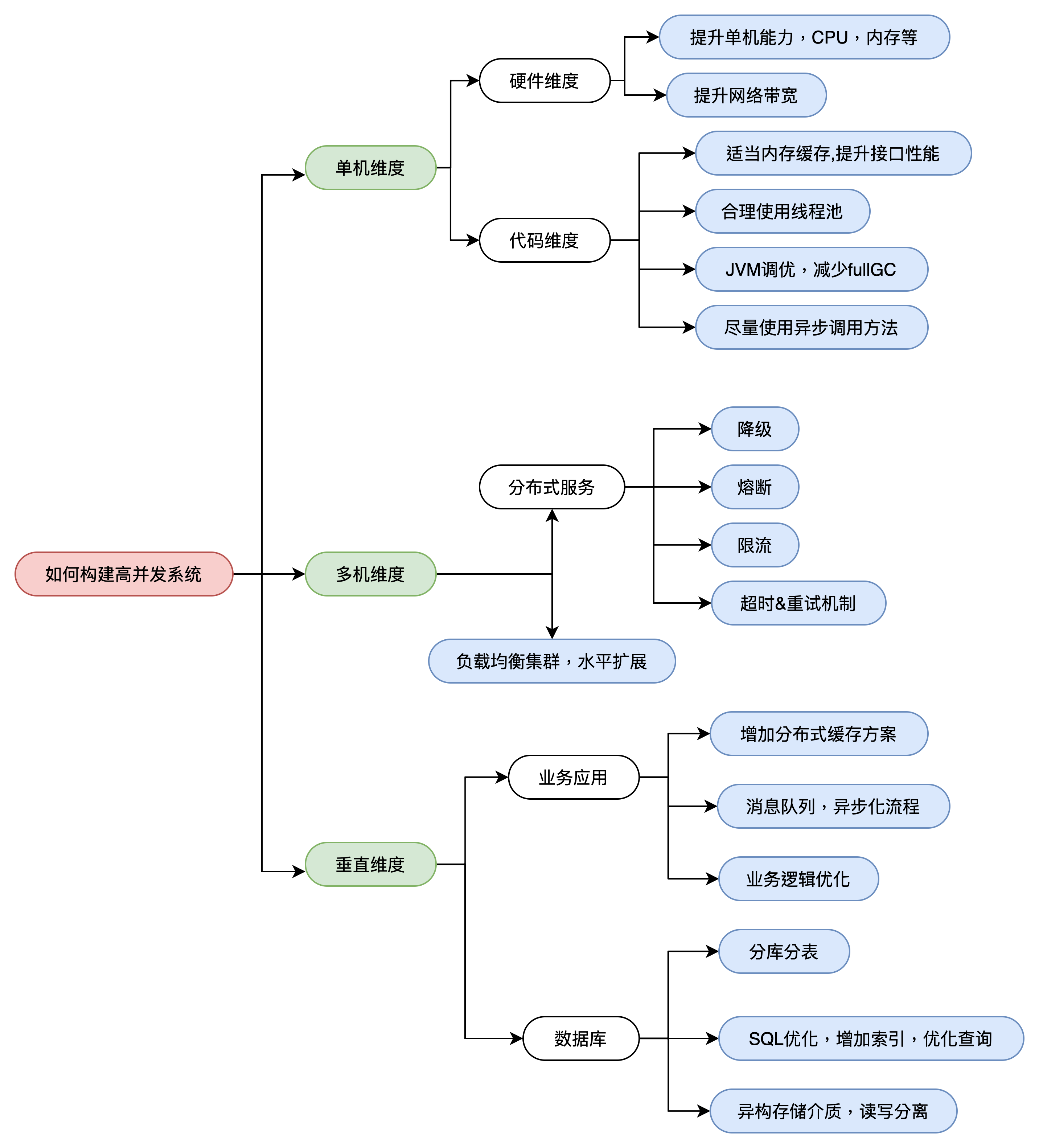
单机维度
在单机维度上, 我们一般分为硬件维度和代码维度两个方向考虑。硬件维度比较简单,就是提升单机的硬件性能和网络带宽。而代码维度,则是在高并发系统架构设计时,最容易被大家忽视的,尤其是大量的脱离一线研发并进化成PPT架构师的今天,单机维度基本不在考量范围。
但不积跬步无以至千里,有的时候单机接口的的性能优化,会带来很高的经济成本价值。在代码维度,我这里重点介绍一种情况,关于多线程和异步方法。
a. 多线程和异步方法的误区
关于多线程和异步方法的概念,我再面试候选人的时候,发现很多人对此都有误区。在此,我先详细的一下他俩的概念:
多线程:多线程是指在一个进程中可以同时运行多个线程,每个线程执行不同的任务。Java通过java.lang.Thread类和java.util.concurrent包提供了多线程编程的支持。多线程的主要目的是为了充分利用CPU资源,提高程序的执行效率。
异步方法:异步方法是指在调用某个方法时,不需要等待该方法执行完成即可继续执行后续代码。Java通过CompletableFuture和异步回调机制提供了异步编程的支持。异步方法的主要目的是为了提高系统的响应能力和资源利用率。
b. 多线程能够解决高并发场景么
当大家了解了多线程和异步方法的概念后,那么我们就可以认真思考一下,多线程一定能提升系统的并发能力么?
我的结论是:多线程可以提升部分服务的并发能力,但并不能显著提高性能。
首先我们先了解,Tomcat的Servlet机制是基于多线程实现的,而如果你在单次请求中在此开辟线程池进行多线程处理,在一定的并发情况下,你可能只是改善了单次请求的TP99,但无法有效提升系统的并发能力。因为多线程的性能提升与CPU核心数密切相关。如果系统只有一个CPU核心,那么多个线程只能在该核心上轮流执行,无法实现真正的并行处理。而我们的宿主机一般也就是8C或者16C,在面单机上千的QPS请求时,多线程只会增加CPU上下文切换的负担。
举个简单并且常见的例子,批量下单接口。我们常见的做法就是在批量下单接口中开辟线程池,然后建个多个下单在线程池中并行处理。这样做的结果是,在请求量低的情况下,效果还是可以的,单次请求的QPS也会很低,但如果单机面临每秒上千次的下单请求,这种实现方式就会出现问题。最直观的观察,可以通过TP99的监控曲线发现,就是请求量跟TP99呈现严重的正相关性。
而真正有效的提升下单接口的并发能力,是通过异步方式实现。但异步方式又会增加系统的设计复杂度,比如下单失败,异步回调设计和数据一致性设计等等,也在考量范围之内,这里就不详细展开说明。
c. 小结
多线程和异步方法是Java开发中两种重要的并发处理技术,它们在提高系统性能和响应能力方面各有优势。多线程通过并行处理任务,充分利用CPU资源,适用于CPU密集型任务和需要并行处理的场景。异步方法通过非阻塞I/O操作和异步回调机制,提高系统的响应能力和资源利用率,适用于I/O密集型任务和事件驱动架构。
此外当然还有大家经常乐于讨论的JVM调优问题,基于JVM调优,包括垃圾回收器的选择,参数的合理优化,当然,还有一点,其实大家平时关注不多,就是采用更高版本的JDK和更新的Spring框架,因为高版本的框架会对性能本身有不错的优化。关于这点,我在另一篇文章中有重点介绍:性能加速包: SpringBoot 2.7&JDK 17,你敢尝一尝吗
多机维度
在多机维度考虑系统的高并发性能,应该是大家最长能够想到的场景了,也是架构师们最热衷讨论的点。
首先是对系统的拆分角度来说,第一个是单体应用的水平扩展问题,就是我们所说的负载均衡集群,换成我们经常听到的一个词: 扩容。扩容一般针对负载均衡集群进行水平扩展,用于解决单机无法承载高并发的情况,这也是互联网公司解决高并发场景的最常用手段,就比如每次双十一或者618前夕,我们都会成倍的扩容我们的服务实例。
对系统的另一个拆分角度,叫做垂直拆分,也就是我们常见的分布式系统。比如按照领域划分,我们将一个大的单体服务,拆分成不同的子领域系统,然后每个子领域系统单独承担各自的流量,而不会相互影响。还比如说长江的CQRS设计架构,翻译过来是指令查询分离的设计方式,通过查询和指令服务拆分,来讲高并发的查询场景单独拆分出来进行设计。
既然采用了分布式的微服务架构,那么分布式系统的一些常见痛点也是高并发要考虑的,比如熔断,降级,限流,超时等设计,这些本身是为了增强分布式系统的鲁棒性,从而间接的增强系统的高并发承载能力。关于微服务架构,在此处不再赘述,有兴趣的,可以看我的另一篇文章:【实践篇】教你玩转微服务--基于DDD的微服务架构落地实践之路
垂直维度
所谓垂直维度,是为了区分于单机维度和多机维度的,垂直的意思是针对一个业务系统在系统层级的垂直划分,包括业务应用和数据库。要知道,很多高并发场景,不管是写场景还是读场景,当数据库维度出现瓶颈,扩容就不想业务应用服务那么简单了,所以要区分来说。
a. 业务应用
唯物辩证法中有一个重要概念,就是一切从实际出发,具体问题具体分析。对于高并发系统的构建,虽然有通用的手段和方法论,但没有统一的落地方案,必须根据具体的业务应用场景进行分析和设计。比如你的系统是高并发读还是高并发写,处理思路也是完全不一样的。当然常见的手段和方法论核心包括两点:缓存和异步。但具体到相应的业务,需要仔细思考缓存逻辑怎么设计,异步流程怎么设计,如何保证数据一致性等等。
这块我有一个项目案例,就是在SAAS商城中秒杀场景下,如何设计高性能库存扣减逻辑,我将这块内容写在了我另一篇文章里:高并发场景下的库存管理,理论与实战能否兼得?
b. 数据库
在存储媒介这块其实高并发是不好设计的。比如关系型数据库MySQL, 在进行扩展要比业务应用复杂不少,涉及到的就是数据库的分库分表逻辑。
这块可以参考之前我写过的一篇文章:分而治之--浅谈分库分表及实践之路。
而对于读场景下的高并发请求,还有一种最常见的处理手段,就是异构存储介质,实现读写分离,最常见的就是MySQL关系型数据库负责写,ES这种文档类数据库负责读。而他的技术难点则在于数据的同步和数据一致性上。
审核编辑 黄宇
-
JAVA
+关注
关注
19文章
2966浏览量
104700 -
数据库
+关注
关注
7文章
3794浏览量
64354
发布评论请先 登录
相关推荐
水电站生态下泄流量监测系统:实时捕捉流量的细微变化
灌区渠道生态流量监测系统:保障水资源可持续利用的核心利器

生态流量在线监测系统解决方案


测试聊并发-入门篇

重塑定位边界:革新 UWB 信标定位系统测试套件,精准并发融合引领未来

“远程IO控制问题全解析:常见报错及一站式解决方案”

大促高并发系统性能优化实战--京东联盟广告推荐系统
高并发物联网云平台是什么
迈威通信TSN工业自动化系统解决方案助力智能制造实现确定性服务

stm32wb55rg ZigBee和蓝牙并发运行时,连接蓝牙失败的原因?怎么解决?
生态流量动态监测系统解决方案及系统功能






 工商网监
工商网监
评论