 京东搜索重排:基于互信息的用户偏好导向模型
京东搜索重排:基于互信息的用户偏好导向模型

SIGIR 24: A Preference-oriented Diversity Model Based on Mutual-information in Re-ranking for E-commerce Search
链接:https://dl.acm.org/doi/abs/10.1145/3626772.3661359
摘要:重排是一种通过考虑商品之间的相互关系来重新排列商品顺序以更有效地满足用户需求的过程。现有的方法主要提高商品打分精度,通常以牺牲多样性为代价,导致结果可能无法满足用户的多样化需求。相反,旨在促进多样性的方法可能会降低结果的精度,无法满足用户对准确性的要求。为了解决上述问题,本文提出了一种基于互信息的偏好导向多样性模型(PODM-MI),在重排过程中同时考虑准确性和多样性。具体而言,PODM-MI采用基于变分推理的多维高斯分布来捕捉具有不确定性的用户多样性偏好。然后,我们利用最大变分推理下界来最大化用户多样性偏好与候选商品之间的互信息,以增强它们的相关性。随后,我们基于相关性得出一个效用矩阵,使项目能够根据用户偏好进行自适应排序,从而在上述目标之间建立平衡。在京东主搜上的实验结果证明了PODM-MI的显著提升。
1、背景及现状
•用户从搜索到下单过程中存在不同的决策阶段(买、逛等),用户不同的决策阶段对多样性也有不同需求,现阶段模型没有直接建模不同决策阶段和多样性的关系。
•用户需求考虑。
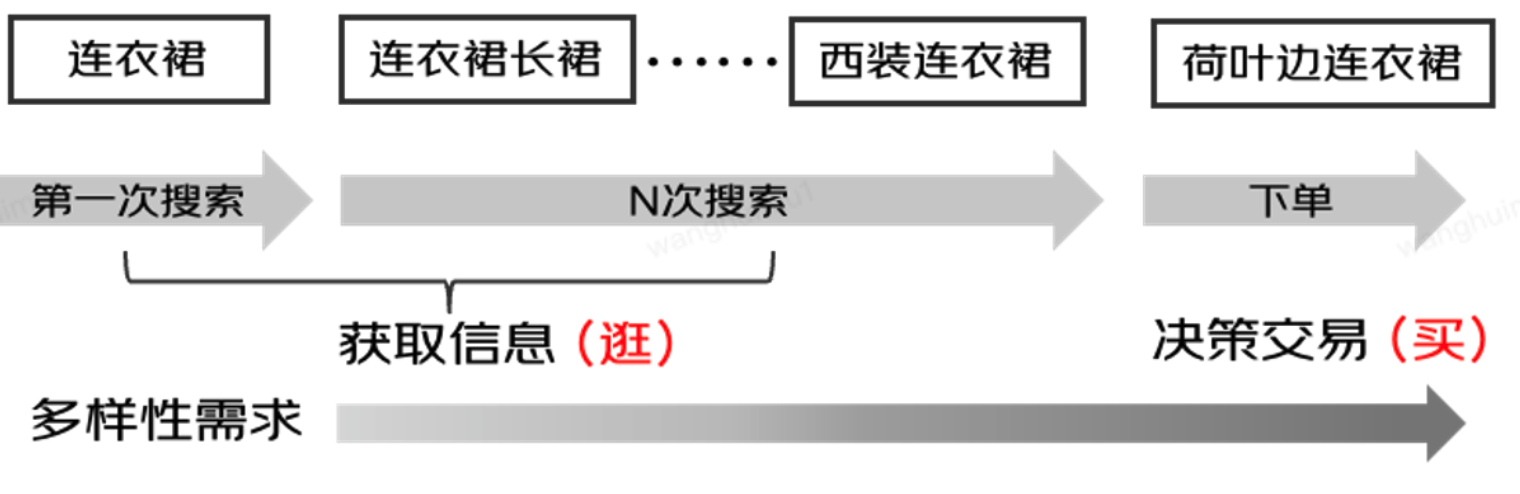
◦重排阶段需要充分考虑用户需求。通常来说,用户的需求是个性化的,即部分场景下对于排序结果的准确性要求较高,而另一部分场景下对于排序结果的多样性要求较多。在这种情况下,一个合适的重排排序算法应该自适应地根据用户需求进行结果调整,即当用户需要多样性时,搜索排序结果应当包含尽可能不同的商品来满足用户的多种兴趣来满足用户的多样性需求;而当用户需要准确性时,排序结果应包含最符合用户或用户最感兴趣的单一类别商品。例如,用户从搜索“连衣裙”到逐渐缩小范围到“荷叶边连衣裙”,这一过程中,他们的搜索意图从多样化逐渐变得明确和具体。要在重排阶段平衡效率指标和多样性,我们面临两个主要挑战:
1.准确建模用户的决策意图困难,因为其意图会在多次搜索中逐渐演变。
2.即使成功建模了用户的意图,如何加强搜索结果与用户演变意图的匹配关系?
为了解决这些挑战,我们提出了PODM-MI(基于互信息的偏好导向多样性模型)。
2、PODM-MI
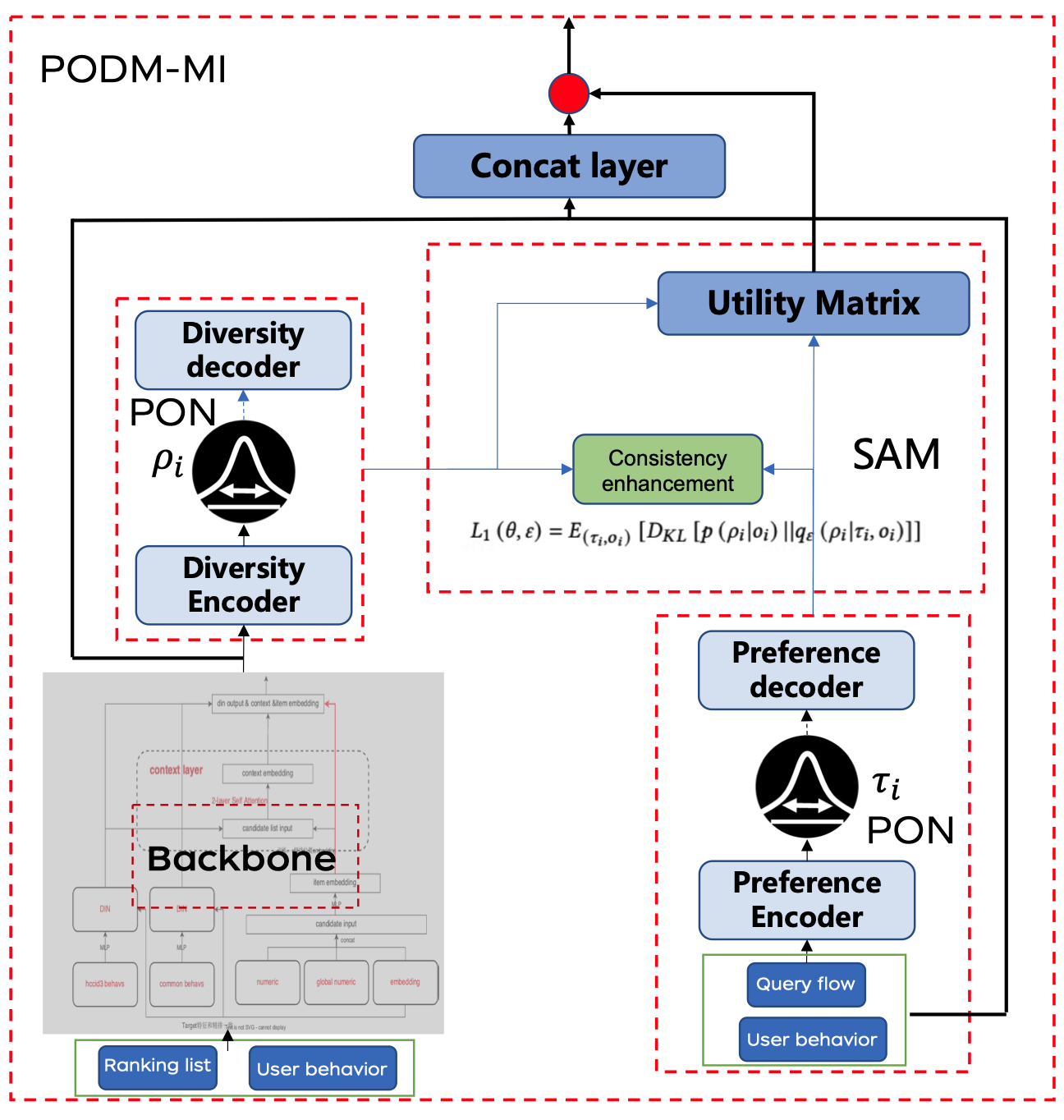
PODM-MI模型以排序列表和用户行为数据(如点击流和加入购物车的行为)为输入。首先,我们使用PON捕捉用户的多样性偏好和候选商品的多样性表示。然后,SAM增强用户多样性偏好与候选商品多样性之间的一致性。从这种增强的一致性中,我们得出一个效用矩阵,该矩阵会动态调整用户偏好,从而重新排序最终的排名结果以更好地满足用户需求。
2.1 PON 用户偏好建模
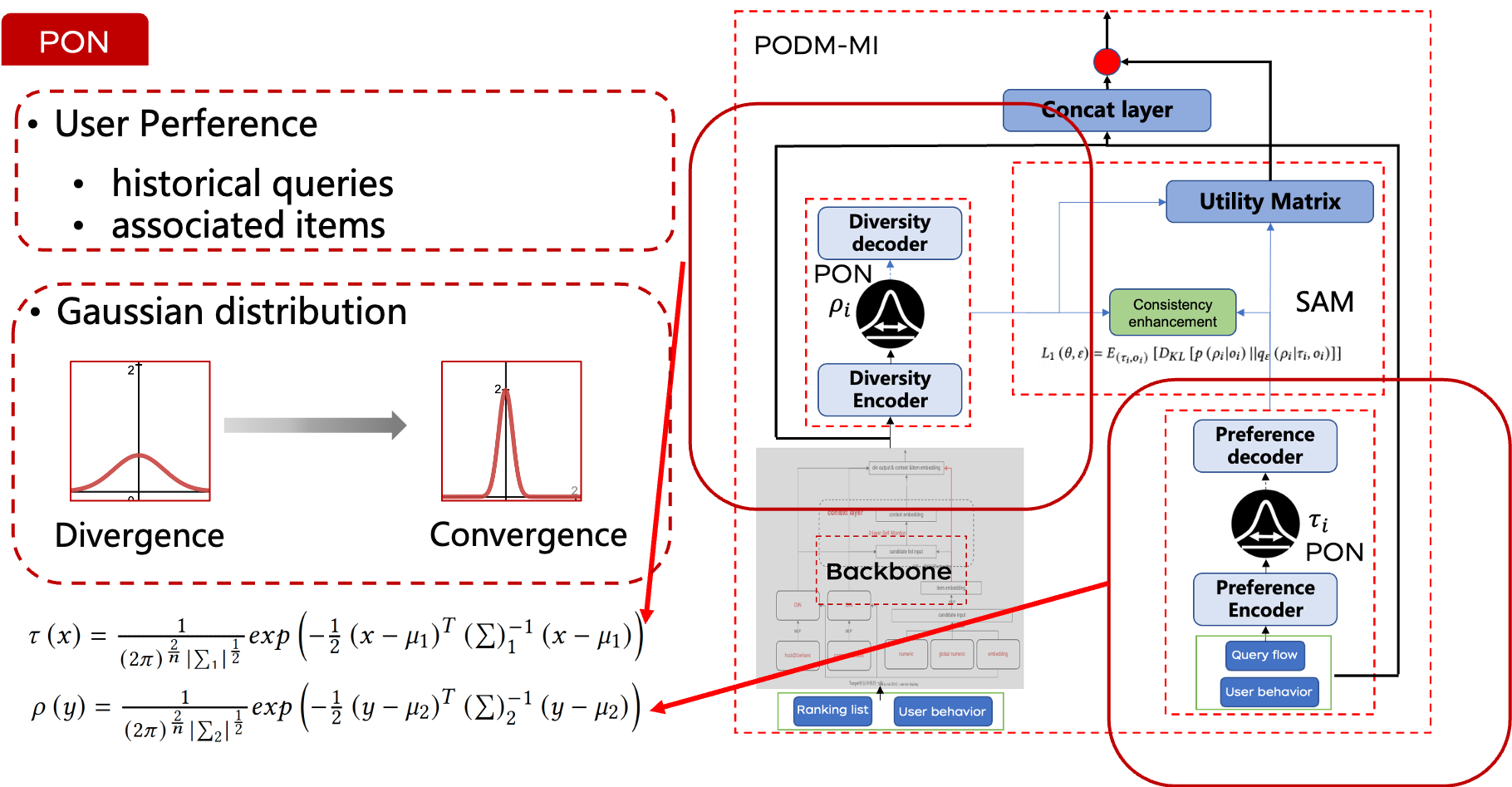
在电商搜索场景中,历史查询及其关联商品提供了用户意图的有价值表示。因此,我们的方法不仅包括点击流和加入购物车的行为,还包括查询轨迹,以更好地捕捉用户偏好。
传统模型通常将用户偏好视为静态,在潜在空间中创建固定的用户嵌入。然而,这种方法在捕捉用户偏好的复杂和动态特性时显得不足。相比之下,分布表示引入了不确定性,提供了比单一固定嵌入更多的灵活性。
我们使用多维高斯分布来建模用户偏好的演变趋势。该分布由均值向量和对角协方差矩阵表征,使我们能够更好地捕捉用户偏好的动态特性。此外,高斯分布还可以用于测量收敛和发散趋势。较大的方差表示更均匀的分布,而较小的方差则表示更集中的分布。这个方差可以间接反映用户的偏好趋势。
2.2 SAM 利用互信息优化排序结果
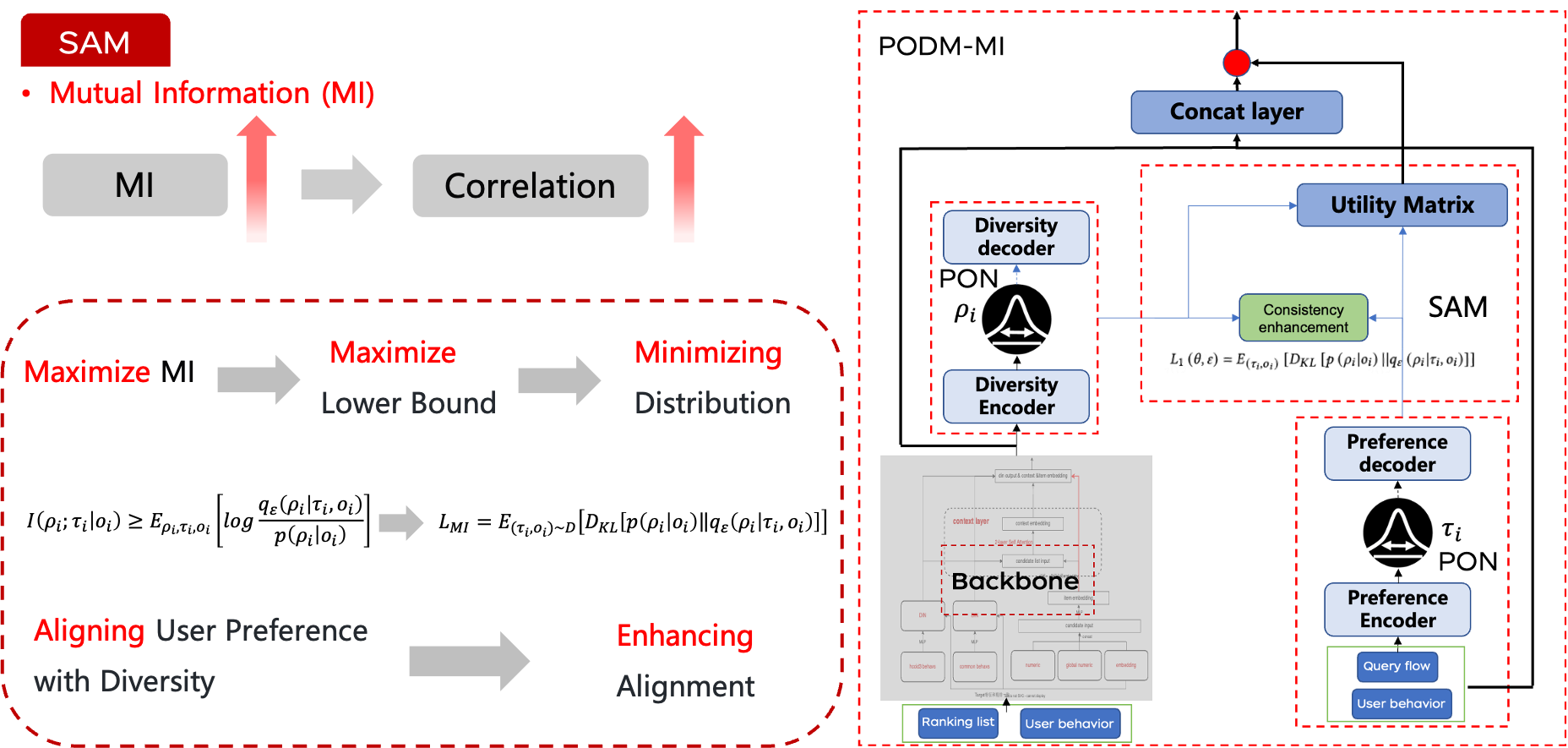
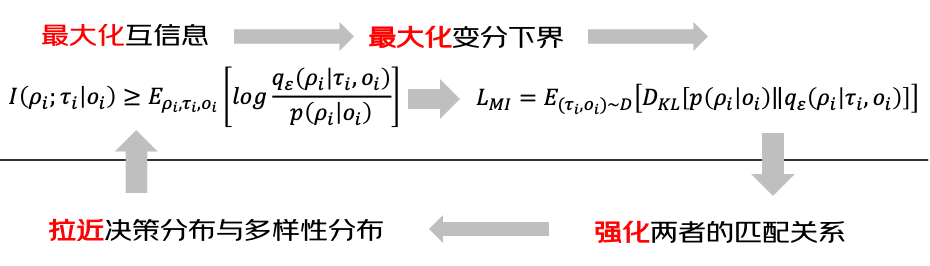
在建模用户偏好和候选商品的多样性之后,下一步是确保排序结果与用户意图紧密匹配。为此,我们可以使用互信息(一种衡量两个变量之间共享信息量的方法)来量化候选商品与用户偏好之间的相关性。通过最大化这两个因素(用户偏好和多样性)之间的互信息,我们确保候选商品的分布与用户意图的分布紧密对齐。
然而,估计和最大化互信息通常是不可行的。为了解决这一挑战,我们借鉴了变分推理的文献,引入了一个变分后验估计器。该方法允许我们为互信息目标推导出一个可行的下界。
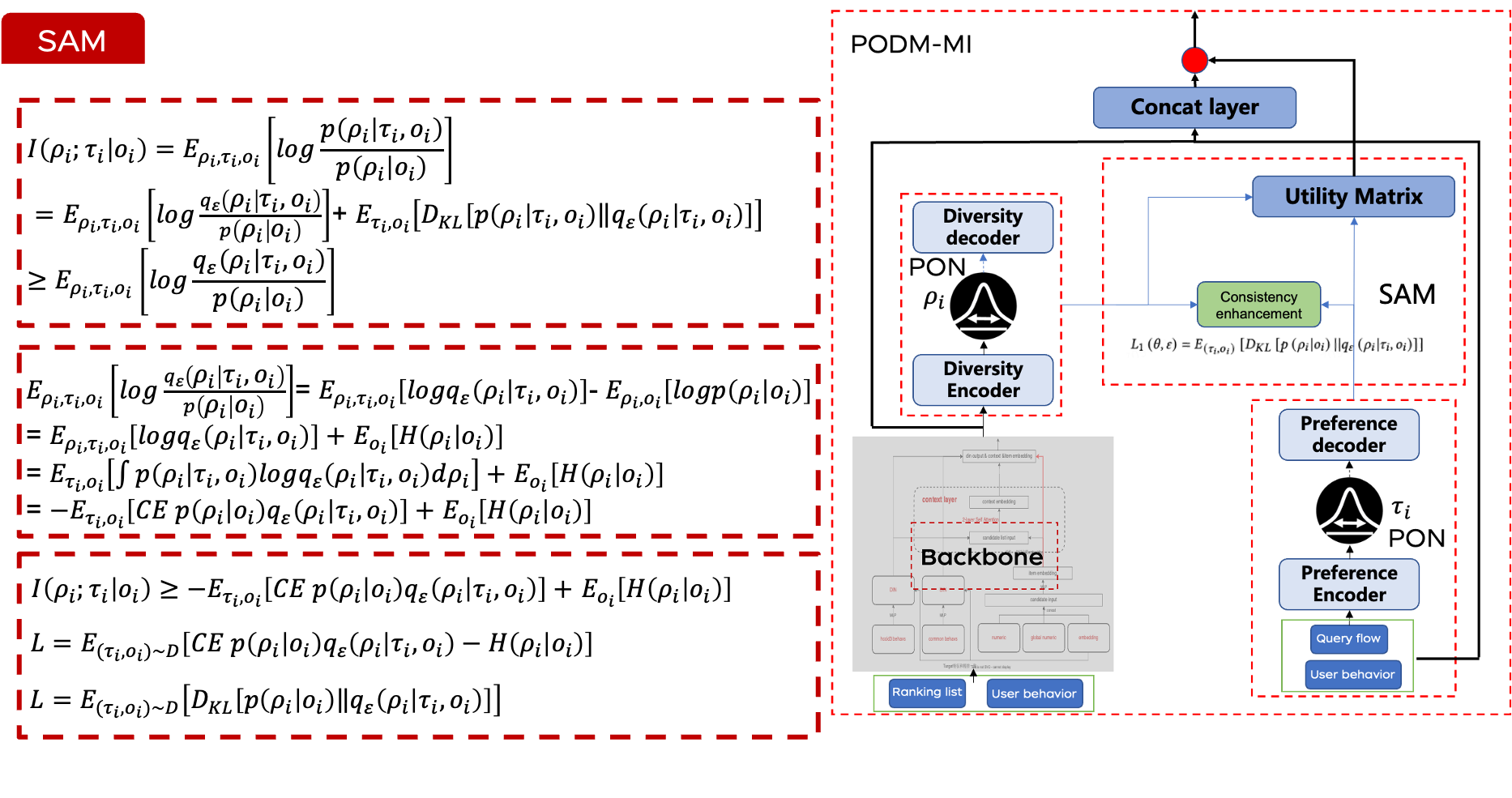
在增强一致性之后,我们设计了一个可学习的效用矩阵,以进一步使最终的排序结果与用户偏好对齐。该矩阵通过可学习权重矩阵与对齐特征的点积获得。然后,我们将效用矩阵与从主干网络计算的分数相乘以得到最终结果。
2.3 优化函数及最终loss
优化函数:
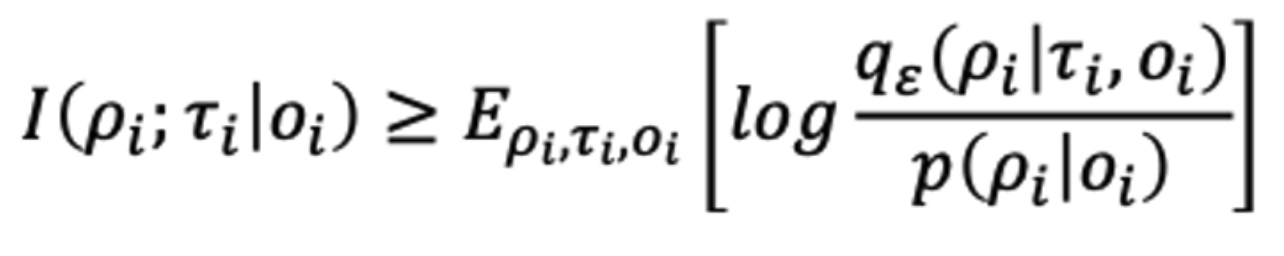
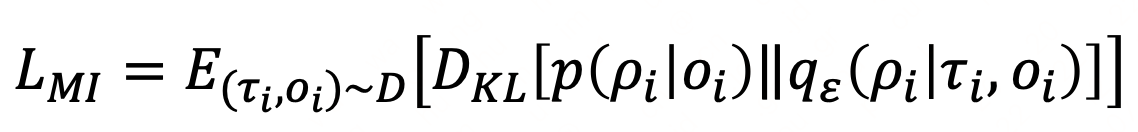
最终loss:
前者是prm分类loss,后者是互信息loss
方案总结:
2.4 实验结果及可视化分析

为了验证PODM-MI的有效性,我们在京东电商搜索引擎中进行了在线A/B测试。PODM-MI不仅提高了用户购买的可能性,还增加了搜索结果中商品的多样性。需要注意的是,每增加0.10%的UCVR都会为公司带来巨大的收入,因此PODM-MI取得的提升是非常显著的。

进一步的,我们对用户query流降维后的趋势使用TSNE可视化,同时降维可视化需要label足够明显,所以采用人工分桶的方法,对排序结果的多样性熵进行人工分桶,分成多个label。可以看出,不同发散收敛趋势的query流有着很明显的分层,query流同对应的熵聚集在了一起,这表明不同的query流的发散趋势对应着不同的结果的熵。也就是说,query流越发散,session的排序结果越发散,query流越收敛,session的排序结果越收敛。
此外,我们还用一个更具体的案例来说明我们方法的有效性。当用户的历史搜索查询非常多样时,如:Switch,塞尔达,手机壳,锤子,油烟机,排气管,在这种情况下,当用户输入“蔬菜水果脱水机”后,我们的方法比基线方法产生了更多样化的结果。另外,还有一个收敛趋势的案例。当用户搜索“连衣裙”并访问相应的店铺后,再次输入该店铺时,我们的方法比基线方法产生的结果更加集中,并且更好地与用户的历史搜索记录相匹配。
3、未来迭代方向
• 引入更精细的特征,更好的建模用户的逛买意图
• 用户意图建模更新的进一步优化
• 用户意图建模显式影响
Note:
欢迎大家交流与探讨,如有任何问题或建议,请随时联系:{wanghuimu1, limingming65}@jd.com。
我们京东搜索算法部目前有大量的社招和实习机会,诚邀有志之士加入。无论您是技术专家还是新兴人才,我们都期待您的加入,共同推动技术的进步和创新。欢迎大家踊跃投递简历,期待与您在京东相遇!
团队最近相关工作:
1. Breaking the Hourglass Phenomenon of Residual Quantization: Enhancing the Upper Bound of Generative Retrieval (arxiv:2407.21488)
2. Generative Retrieval with Preference Optimization for E-commerce Search(arxiv:2407.19829)
3. A Preference-oriented Diversity Model Based on Mutual-information in Re-ranking for E-commerce Search(SIGIR 24 ACCEPTED)
4. MODRL-TA: A Multi-Objective Deep Reinforcement Learning Framework for Traffic Allocation in E-Commerce Search(CIKM 24 ACCEPTED)
5. Optimizing E-commerce Search: Toward a Generalizable and Rank-Consistent Pre-Ranking Model(SIGIR 24 ACCEPTED)
分享嘉宾:
王彗木博士
中科院自动化所博士,研究方向为大模型、强化学习,亦城优秀人才,CCF 中国计算机学会专业会员,目前在京东从事主搜排序及生成式召排工作
李明明博士
资深算法专家中科院信工所博士,研究方向为大模型、语义检索,亦城优秀人才,CCF 中国计算机学会专业会员,目前在京东从事主搜召回及生成式召排工作
审核编辑 黄宇
-
算法
+关注
关注
23文章
4606浏览量
92817 -
模型
+关注
关注
1文章
3226浏览量
48804 -
可视化
+关注
关注
1文章
1194浏览量
20932
发布评论请先 登录
相关推荐
基于最大互信息方法的机械零件图像识别
基于互信息的功能磁共振图像配准
基于图嵌入和最大互信息组合的降维
基于互信息梯度优化计算的信息判别特征提取
Powell和SA混合优化的互信息图像配准
基于规范互信息和动态冗余信号识别技术的特征选择方法

基于互信息和余弦的不良文档过滤
面向评分数据中用户偏好发现的隐变量模型构建
密码芯片时域互信息能量分析
训练表示学习函数(即编码器)以最大化其输入和输出之间的互信息
一种改进互信息的加权朴素贝叶斯算法






 工商网监
工商网监
评论