 从算法角度看 SLAM(第 2 部分)
从算法角度看 SLAM(第 2 部分)
作者: Aswin S Babu
正如我们在[第 1 部分]中所讨论的,SLAM 是指在无地图区域中估计机器人车辆的位置,同时逐步绘制该区域地图的过程。根据使用的主要技术,SLAM 算法可分为三种,分别是基于滤波器的 SLAM、基于图形的 SLAM 和基于深度学习的 SLAM。
基于滤波器的 SLAM 将 SLAM 视为状态估计问题。在这种 SLAM 中,通常使用扩展卡尔曼滤波器 (EKF) 或无迹卡尔曼滤波器 (UKF) 等概率滤波器,来递归估计机器人的状态并根据传感器测量值更新地图。该滤波器根据机器人的运动模型预测机器人的下一个状态,然后使用传感器测量值来修正该预测。
与基于滤波器的 SLAM 相比,基于图形的 SLAM 将问题视为图形优化问题。在这种 SLAM 中,SLAM 问题被表述成一个图形,其中节点表示机器人姿态或环境中的地标,边缘表示它们之间的测量值或约束。基于图形的 SLAM 的目标是优化机器人的姿态和地标的位置,以便尽可能准确地满足测量的约束条件,例如地标之间的距离、机器人姿态之间的相对姿态。
基于深度学习的 SLAM 方法则利用神经网络直接从传感器数据中学习环境表征,而不依赖手工创建的特征或模型。这些方法可以学习传感器测量值和机器人姿态或地图之间的复杂映射,从而实现端到端的 SLAM 解决方案。
SLAM 的地图绘制和定位这两项核心功能彼此之间相互依存,其中机器人根据传感器数据不断更新其地图并相应地调整位置估计。作为一种模块化工具,SLAM 及其概念允许将替换和更改规划在内。因此,很多时候,人们会同时开发和使用几种算法,这使得将 SLAM 作为单一算法进行概括和解释变得有些麻烦。因此,理解 SLAM 的最佳方式是聚焦一种具体的 SLAM 实现。既然如此,我们就详细讨论一下基于滤波器的视觉 SLAM (vSLAM)。
视觉 SLAM
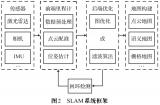
顾名思义,vSLAM 使用视觉传感器(相机)作为其主要传感器。此外,它可能还配备编码器、惯性测量装置 (IMU) 和其他传感器。图 1 显示了这种实现的通用框图。
 图 1:基于特征的 SLAM 过程的简化通用框图。(复制自 kudan.io)
图 1:基于特征的 SLAM 过程的简化通用框图。(复制自 kudan.io)
相机测量
相机捕捉机器人周围环境的图像,包括地标、边缘和纹理等特征。然而,由于大多数相机镜头都会产生一定程度的失真,因此需要对捕捉的图像进行失真校正。使用的相机可以是立体相机、单目相机或[带有飞行时间 (ToF) 深度传感器的 RGB-D 相机]。立体相机和 RGB-D 相机的优点是可以轻松获取深度信息。但单目相机存在尺度不确定性问题。也就是说,单目 SLAM 无法仅从特征对应关系来识别平移运动的长度(比例因子)。不过,有一些方法可以缓解这种情况,但不在本文的讨论范围内。
特征提取
使用相机传感器捕捉图像后,我们需要通过找出特定帧的特征来唯一地识别该帧,以供将来参考。在这种情况下,特征是唯一且可以一致识别的像素的集合。或者我们可以说像素是图像中的独特点,不会因旋转、缩放和失真而发生变化,因此即使在图像处理之后也很容易重新识别它们。考虑到我们使用立体相机作为主要传感器,我们应该能够看到相机捕捉的立体图像之间的重叠特征。然后,可以使用这些相同的特征来估计与传感器之间的距离。然而,如前所述,在此之前,我们需要识别立体图像对上的共同特征。这一过程由特征检测器和匹配器来完成。一些常见特征检测器的示例包括尺度不变特征转换 (SIFT)、定向 FAST 和旋转 BRIEF (ORB) 以及良好特征跟踪 (GFTT)。图 2 显示了使用一些热门特征检测器识别的特征。一旦识别出特征,就会使用相同的特征检测器对其进行描述。此过程有助于将来轻松地重新识别这些特征。
 GFTT b) SIFT") 图 2:使用 a) GFTT b) SIFT 在 XRP 机器人图像上检测到的关键点。(来源:SparkFun Electronics)
图 2:使用 a) GFTT b) SIFT 在 XRP 机器人图像上检测到的关键点。(来源:SparkFun Electronics)
找出关键点之后,我们通过匹配来建立这些点之间的对应关系。一些可使用的特征匹配算法包括暴力匹配器或快速最近邻搜索库 (FLANN)。图 3 显示了匹配算法作用机制的视觉表示。图中所示直线连接匹配之处,由于我们使用了镜像,理想情况下,如果系统是完美的,我们应该只得到水平(平行)直线。但遗憾的是,特征匹配算法并不完美,因此会导致错误匹配,其中一些用斜线表示。这就是为什么我们需要随机抽样一致性 (RANSAC) 这样的异常值剔除工具。
 图 3:使用 FLANN 在两幅对称图像上表示特征匹配的直线。(来源:SparkFun Electronics)
图 3:使用 FLANN 在两幅对称图像上表示特征匹配的直线。(来源:SparkFun Electronics)
RANSAC
使用像 RANSAC 这样的算法可滤除这些不正确的匹配,确保仅使用正确值(正确的匹配)作进一步处理。RANSAC 的工作方式是使用所提供数据的随机子集构建模型。也就是说,我们将一些随机点视为内群值(正常值),并尝试根据这些选定的点匹配所有剩余的点。然后,我们会评估模型与整个数据集的匹配程度。这个过程不断重复,直到找到一个由成本函数确定的模型,该模型能够准确描述数据且误差最小。
特征和数据关联
在此步骤中,我们采用检测到的特征及其在空间中的估计位置来创建这些特征的地图。随着在后续帧继续进行该过程,系统会将新特征与地图的已知元素关联,并丢弃不确定的特征。
当在后续帧中跟踪相机运动时,可以根据已知特征以及它们预计随运动变化的方式来进行预测。不过,计算资源和时间约束(尤其是在实时应用中)给 SLAM 带来了限制。随着系统收集更多的特征测量值并更新位置/姿态,环境表示的约束和优化变得至关重要。
位置、姿态和地图更新
卡尔曼滤波器
随着 SLAM 过程的深入,会不断积累噪声,并在相机捕捉的图像与其相关运动之间产生不确定性。通过根据观察到的测量值不断生成预测、更新并微调模型,卡尔曼滤波器可以减少不同测量值之间的噪声和不确定性的影响。这有助于创建线性系统模型。在 SLAM 的实际实现中,我们使用扩展卡尔曼滤波器 (EKF),其采用非线性系统,并围绕平均值对预测和测量值进行线性化处理。EKF 可以通过执行传感器融合(例如,相机、IMU)整合来自多个传感器的数据,以提高状态和地图估计的准确性。这种数据源的融合有助于获得更可靠的 SLAM 结果。基于 EKF 的 SLAM 中的状态向量包括机器人的姿态(位置和方向)和地图中地标的位置。
关键帧选择
在捕捉的图像中选择关键帧,可减少处理全部捕捉图像所需的大量计算。我们选择的是可以很好地表示环境的帧,并仅将它们用于计算。这种方法又是一次准确性和效率之间的权衡。
通过闭环和重定位来纠正误差
随着构建环境模型的过程不断推进,测量误差和传感器漂移会逐渐积累,从而影响生成的地图。闭环可以在一定程度上缓解这种情况。当系统发现自己正在重新访问已经构建地图的区域时,就会发生闭环。通过重新对齐当前地图与先前建立的同一区域的地图,SLAM 系统可以纠正累积的误差。
重定位
当系统不知道其位置和方向 (POSE) 时,需要重定位。此刻,我们需要利用当前可观察到的特征重新估计姿态。一旦系统成功将当前获得的特征与可用地图匹配,我们就可以正常继续 SLAM 过程。
结语
SLAM 是一边估计机器人车辆位置一边绘制未知区域地图的过程。SLAM 技术包括基于滤波器、基于图形和基于深度学习(使用神经网络)的方法。视觉 SLAM 使用相机捕捉图像、提取特征、匹配特征并滤除不正确的匹配点。该系统通过将新特征与已知元素关联、使用卡尔曼滤波器更新机器人的位置和姿态、选择关键帧,并通过闭环和重定位纠正误差来创建地图。
参考资料
- [Remote Sensing | Free Full-Text | SLAM Overview: From Single Sensor to Heterogeneous Fusion (mdpi.com)]
- [Understanding how V-SLAM (Visual SLAM) works | Kudan global]
- [Feature-based visual simultaneous localization and mapping: a survey | Discover Applied Sciences (springer.com)]
- [Introduction to Visual SLAM: Chapter 1 —Introduction to SLAM | by Daniel Casado | Medium]
- [An Introduction to Key Algorithms Used in SLAM - Technical Articles (control.com)]
- [What Is SLAM (Simultaneous Localization and Mapping) – MATLAB & Simulink - MATLAB & Simulink (mathworks.com)]
- [A survey of state-of-the-art on visual SLAM - ScienceDirect]
审核编辑 黄宇
-
滤波器
+关注
关注
161文章
7795浏览量
177989 -
算法
+关注
关注
23文章
4607浏览量
92821 -
SLAM
+关注
关注
23文章
423浏览量
31819 -
深度学习
+关注
关注
73文章
5500浏览量
121109
发布评论请先 登录
相关推荐
SLAM技术的应用及发展现状
SLAM大法之回环检测
激光SLAM与视觉SLAM有什么区别?
基于SLAM的移动机器人设计
激光雷达在SLAM算法中的应用综述





 工商网监
工商网监
评论