 利用NVIDIA RAPIDS加速DolphinDB Shark平台提升计算性能
利用NVIDIA RAPIDS加速DolphinDB Shark平台提升计算性能
DolphinDB 是一家高性能数据库研发企业,也是 NVIDIA 初创加速计划成员,其开发的产品基于高性能分布式时序数据库,是支持复杂计算和流数据分析的实时计算平台,适用于金融、电力、物联网和零售等行业。
DolphinDB 公司推出的 CPU-GPU 异构计算平台 Shark,将 DolphinDB 上的复杂指标计算能力无缝切换到 GPU 算力平台,从而大幅提升了计算性能。
DolphinDB 开发团队与 NVIDIA 团队合作,通过利用NVIDIA RAPIDS加速 Shark 异构计算平台的因子挖掘算法运行效率,帮助 Shark 将因子挖掘的效率提升 2 - 10 倍,并基于NVIDIA cuDF实现 Shark 因子高效计算,大幅减少开发成本,缩短开发周期。
RAPIDS 的 RMM 是一套开源的内存/显存管理库,提供 C++ 和 Python 接口,相比 cuMalloc、cuFree 等操作来讲,具有更好的性能和灵活性;RAPIDS libcudf 是基于 GPU 的 C++ DataFrame 库,提供了基础数据结构,并且内置了基础的函数算子。
Shark 的因子挖掘功能,能通过利用遗传算法从数据中挖掘出有效的因子。在这一场景中,遗传算法会随机生成大量因子并进行计算。这一过程会频繁地创建和释放临时空间来存储中间结果,直接使用原生的 CUDA C 显存分配和释放接口,会严重降低执行效率。
Shark 的因子计算功能,针对金融领域的数据分析与处理,提供了丰富的函数库。如果从零开始将 CPU 的函数迁移至 GPU,需要为 GPU 重新实现一套底层数据结构以及基础计算函数,会导致开发周期的延长以及开发成本的增加。
基于以上挑战,DolphinDB 开发团队与 NVIDIA 团队及 RAPIDS 开发团队合作,通过利用 RAPIDS RMM,解决因子挖掘过程中频繁申请和释放显存导致的性能问题;通过基于 RAPIDS libcudf 进行二次开发,实现因子计算,从而缩短开发周期,降低开发成本。
Shark 进行因子挖掘时,会通过遗传算法随机生成海量的因子计算公式。这些公式长度不等,接受的参数数量也不尽相同。因此在计算时,需要频繁地申请和释放临时空间用于存储中间结果。DolphinDB 开发团队通过使用 RMM 对显存进行池化,从而对中间结果所使用的显存进行高效地分配、释放和重用。
Shark 支持用户输入自定义的公式,自动将自定义公式转换为计算图,并在 GPU 完成计算,从而加快数据分析和处理的效率。如果从零开始将 DolphinDB 的计算函数迁移至 Shark,则需要在 GPU 构建 array、table 等底层数据结构,并实现大量基础计算函数。经过调研后,DolphinDB 开发团队决定基于 RAPIDS libcudf 进行二次开发,复用 cuDF 的 column、table 等底层数据结构,并借助 cuDF 的 groupby 和 rolling 框架,只需要完成算子的核心计算逻辑,即可完成 DolphinDB 时序算子和横截面算子的迁移,这样不仅极大提升了开发效率,还降低了开发成本。
下图展示了在不同规模数据下,使用 RAPIDS 的 RMM 显存管理库相对于原生的 CUDA 显存分配 API,Shark 因子挖掘效率的对比。可以清楚地看到,使用 RMM 可以显著提升 Shark 因子挖掘效率,最高可达到 10 倍的加速比。
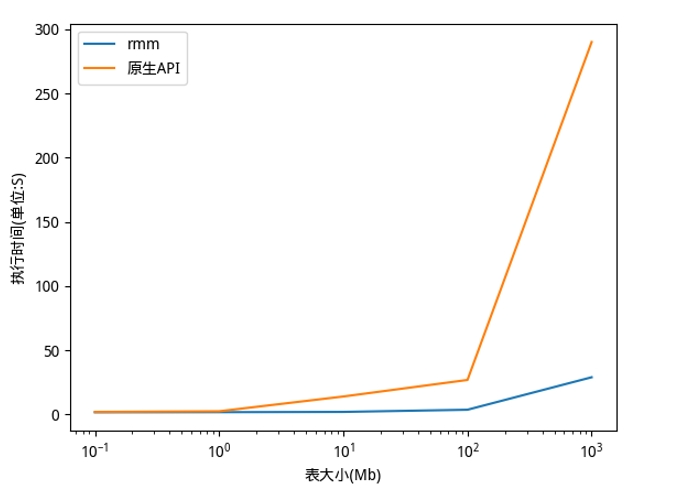
除此之外,Shark 通过使用 RAPIDS libcudf,大大提升了因子的计算效率。下图中对比了 1000 个 group,每个 group 有 10 万行的数据,采用分组方式计算下面的算子。可以看到与 CPU 相比,利用 GPU 总体耗时(包含拷贝时间),基本达到了一个数量级的加速比。
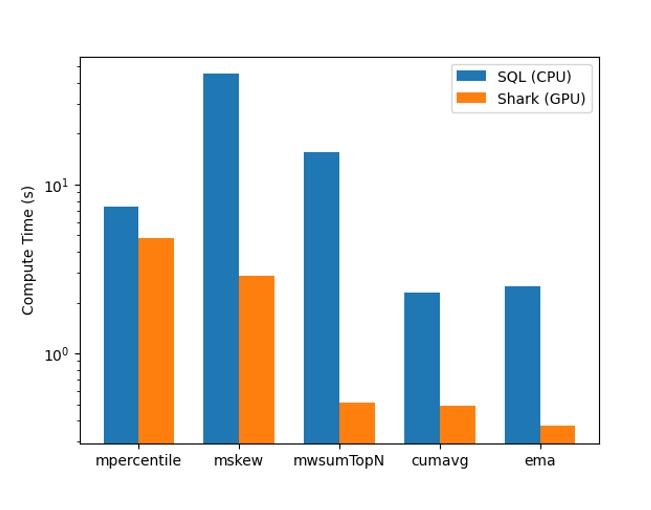
借助 RAPIDS ,Shark 的因子挖掘效率提升了 10 倍。除此之外,基于 cuDF 进行二次开发,只需要实现算子的核心逻辑,就可以达到一个数量级的加速,并极大降低了算子迁移成本。
-
NVIDIA
+关注
关注
14文章
4978浏览量
102980 -
gpu
+关注
关注
28文章
4729浏览量
128886 -
数据库
+关注
关注
7文章
3794浏览量
64352
原文标题:NVIDIA RAPIDS 助力 Shark 平台实现高效数据挖掘和计算
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
《CST Studio Suite 2024 GPU加速计算指南》
将NVIDIA加速计算引入Polars

使用NVIDIA TensorRT提升Llama 3.2性能
RAPIDS cuDF将pandas提速近150倍

NVIDIA加速计算如何推动医疗健康
NVIDIA向开放计算项目捐赠Blackwell平台设计
以实时,见未来——DolphinDB 2024 年度峰会圆满举办

NVIDIA通过CUDA-Q平台为全球各地的量子计算中心提供加速
NVIDIA 通过 CUDA-Q 平台为全球各地的量子计算中心提供加速






 工商网监
工商网监
评论