 全新开源工具,助力FPGA上轻松实现二值化神经网络
全新开源工具,助力FPGA上轻松实现二值化神经网络
神经网络技术起源于上世纪五、六十年代,当时叫感知机,拥有输入层、输出层和一个隐含层。输入的特征向量通过隐含层变换达到输出层,在输出层得到分类结果,早期感知机的推动者是Ronsenblatt。后来又发展到多层感知机,而多层感知机在摆脱早期离散传输函数的束缚,在训练算法上使用Werbos发明的反向传播BP算法,这个就是现在大家常数的神经网络NN,而目前存在的神经网络最常见的有:ANN,RNN,以及CNN。CNN是一种多层神经网络,擅长处理图像特别是大图像的相关机器学习问题,它可以通过一系列方法,成功将数据量庞大的图像识别问题不断将维,最终使其能够被训练。
GUNNESS开源工具
一个叫做GUNNESS的全新的开源工具,可以帮助用户通过SDSoC 开发环境很轻松的将二值化神经网络(BNNs)实现在Zynq SoC芯片和Zynq UltraScale+ MPSoC芯片上。GUINNESS基于GUI工具而开发,内部实现利用深度学习框架来训练一个二值的CNN。关于这部分内容在今年IEEE的国际并行和分布式处理的workshop上有一篇论文对此进行了较为全面的介绍(论文名为“on-chip Memory Based binarized Convolutional Deep Neural Network Applying Batch Normalization Free Technique on an FPGA”),论文中,作者Haruyoshi Yonekawa和Hiroki Nakahara描述了一个他们实现的系统:他们通过在Xilinx ZCU102 Eval 套件上实现一个用于运行VGG-16 benchmark的二值化CNN逻辑系统,其中ZCU102套件其实是基于Zynq UltraScale+ MPSoC芯片而搭建的。在后来比利时 Ghent的FPL2017中作者Nakahara就GUINNESS工具再次进行了介绍。
根据IEEE中发表的这篇paper所述,在Zynq上实现的CNN相比较与在ARM Cortex-A57处理器上运行CNN,运行速度加快了136.8倍,并且功率有效性也提高了44.7倍之多。与在Nvidia Maxwell GPU上运行同样的CNN相比较,基于Zynq实现的BNN速度加快了4.9倍之多,功耗效率也增长了3.8倍。
不过,对于我们这些游离爱好者来说最值得庆幸的是整个GUINNESS工具可以在Github上access到(https://github.com/HirokiNakahara/GUINNESS)。
图:Xilinx ZCU102 Zynq UltraScale+ MPSoC Eval Kit
目前的比较火的概念莫过于机器学习,深度学习,人工智能这三方面了,而这些技术的实现都离不开神经网络的训练,可以说当前技术的热点非神经网络莫属。但是神经网络算法往往较为复杂,软件实现速度往往无法达到需求,专用芯片设计又功能单一且成本高,而通过FPGA实现的话,不仅避免的单用途高成本的投入,同时得到了用户期望的运算速度,一举两得。也相信在以后FPGA将会为神经网络的研究实现方面有更大的发挥空间。
-
FPGA
+关注
关注
1629文章
21729浏览量
602955 -
神经网络
+关注
关注
42文章
4771浏览量
100707 -
人工智能
+关注
关注
1791文章
47183浏览量
238200
原文标题:开源工具助你在FPGA上轻松实现二值化神经网络
文章出处:【微信号:FPGA-EETrend,微信公众号:FPGA开发圈】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
MATLAB神经网络工具箱函数
labview BP神经网络的实现
【PYNQ-Z2申请】基于PYNQ的卷积神经网络加速
【PYNQ-Z2试用体验】神经网络基础知识
基于赛灵思FPGA的卷积神经网络实现设计
如何设计BP神经网络图像压缩算法?
如何移植一个CNN神经网络到FPGA中?
用FPGA去实现大型神经网络的设计
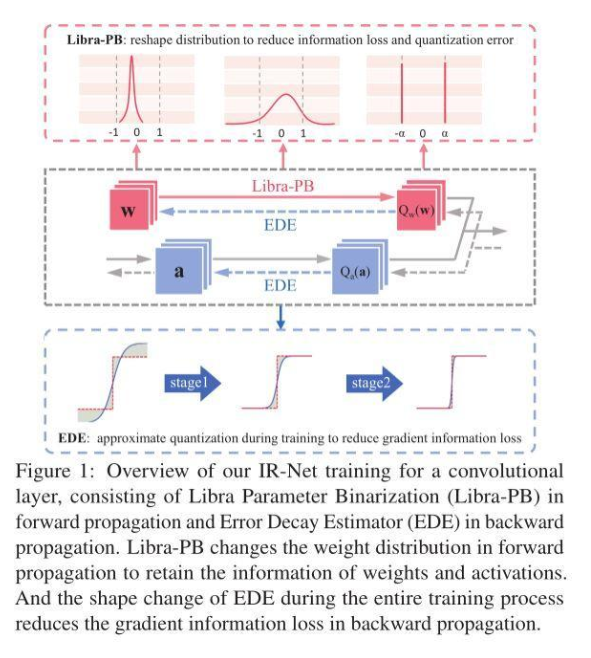
信息保留的二值神经网络IR-Net,落地性能和实用性俱佳






 工商网监
工商网监
评论