 奇异摩尔专用DSA加速解决方案重塑人工智能与高性能计算
奇异摩尔专用DSA加速解决方案重塑人工智能与高性能计算
写在开头,奇异摩尔的 NDSA 互联系列产品基于高性能RoCEv2 RDMA引擎,是面向智算网络通信加速及无损数据传输的专用DSA加速解决方案。
本文部分内容来源于麦肯锡白皮书
随着摩尔定律下的晶体管缩放速度放缓,单纯依靠增加晶体管密度的通用计算的边际效益不断递减,促使专用计算日益多样化,于是,针对特定计算任务的专用架构成为计算创新的焦点。
在过去的几十年的时间里,半导体晶圆上的晶体管密度几乎每两年翻一番,这一趋势令人瞩目。但在过去几年中,晶体管缩放的速度显著放缓,比摩尔定律预测的速度落后了大约十倍。
2018年,著名计算机架构师约翰·亨尼斯西(John Hennessy)和大卫·帕特森(David Patterson)在图灵讲座中指出,半导体工艺创新的放缓将逐渐增加对架构创新的激励——即集成电路的设计方式,以执行计算任务。
“他们认为,通用计算架构(如CPU)固有的低效性将开始被专门针对特定计算任务的架构(也称为领域专用架构,DSAs)的计算能力和成本效益所取代 。”
与此同时,随着计算和数字化在云计算(人工智能和高性能计算)、网络、边缘、物联网(IoT)和自动驾驶等众多应用领域中普及,高度领域专用的计算工作负载正在为DSAs提供有意义的性能优势。大型语言模型(生成式AI的核心引擎),例如ChatGPT,在高容量的AI工作负载中提供了进一步的专业化,这促进了进一步的硬件专业化。 DSA(domain-specific architecture)为特定应用领域开发的硬件和软件的商业潜力是巨大的。专用的图形处理单元 (GPU) 和张量处理单元 (TPU) 已经在数据中心获得了重要的市场份额,它们在 AI 工作负载学习和推理方面的表现优于 CPU。使用GPU和TPU对某些应用的性能提升是非常显著的,特定工作负载的可以实现15 到 50 倍的加速。此外,在汽车领域,来自领先供应商的定制的专用于某些计算场景的DSA硬件也提供了安全支持日益提高的自动驾驶水平所需的低延迟、高性能推理。
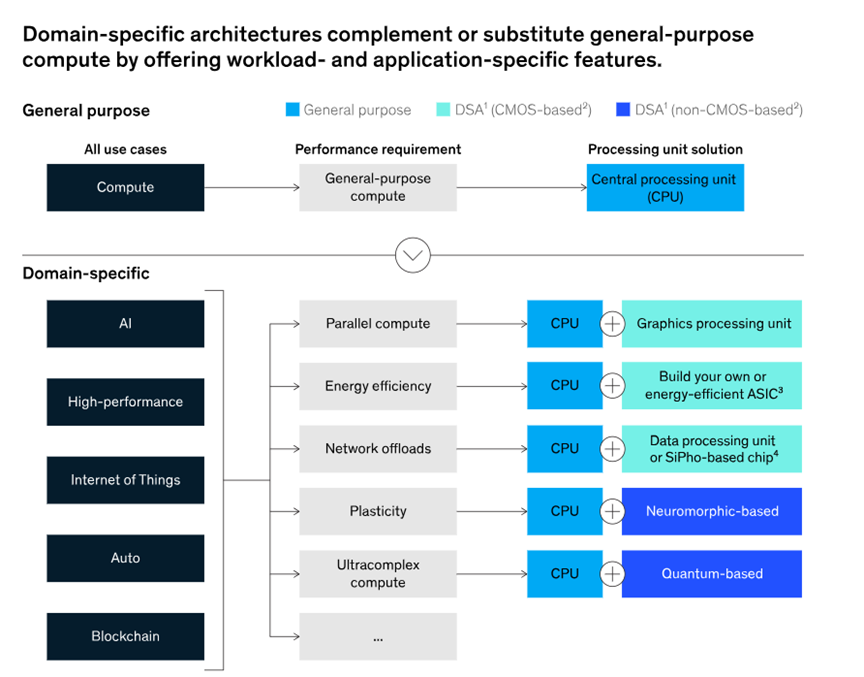
随着 DSA 扩展到其他应用领域,麦肯锡咨询估计到 2026 年,DSA 将占约 900 亿美元的收入(约占全球半导体市场的 10% 至 15%),高于 2022 年的约 400 亿美元。因此,我们看到在这个方向的硬件类的风险投资显着增加也就不足为奇了。
01 算力革命下的高性能网络DSA
随着人工智能及高性能计算的高速发展,服务器集群的瓶颈逐渐从单CPU、GPU、APU的算力转换到硬件间的互联能力。传统的数据中心架构中包含CPU、内存、存储和网络等组件,但CPU目前已经公认不再是运行基础设施功能的最佳位置了。对于下一代数据中心而言,面向网络加速的DSA将扮演重要的角色,根据不同应用场景的需求,加速数据传输。同时,以太网速度从25G增加到100G、200G、400G,再到800G,甚至还有持续增长的趋势,超大规模数据中心的硬件架构在逐渐转变。
据估计,对于超大规模数据中心来说,大约有一半的CPU被用在了非创收型任务上。网络DSA可以承担大部分繁重的工作,将CPU解放出来,专注于创收的应用处理上。同时,由于功能和作用不同,北向网络和高带宽域在设计时侧重点不同。北向网络侧重于网络控制与管理,主要是网络控制器与上层应用之间的接口和通信。高带宽域网络侧重于数据传输性能,旨在提供高速度、低延迟的网络连接。基于RoCE的RDMA技术,兼容现有的以太网基础设施,拥抱开放生态,是业界解决高带宽域网络与北向网络数据传输的重要解决方案。
02 Chiplet设计方法与DSA的完美结合
结合Chiplet设计方法学与DSA的设计,可以构建出高效、灵活且高度定制化的计算平台。Chiplet设计方法学通过将处理器设计拆分为多个独立的Chiplet,每个Chiplet可以针对特定功能进行优化。这样可以在设计、制造和测试中提高灵活性。同时,不同的Chiplet分工明确,可以专门处理不同的任务,例如CPU核心、内存控制器、I/O接口等。而DSA针对特定计算任务进行优化,例如生成式人工智能、图形处理、网络处理等,相比于通用处理器,DSA在其特定领域内具有更高的性能和能效比。
通过Chiplet方法学,可以将多个DSA集成到一个系统中,创建一个高度定制化的平台。比如,一个系统可以包含CPU、GPU、TPU、DPU等Chiplet,根据应用需求灵活组合。在这一背景下,组件之间的高速可连接对于确保顺利快速的数据传输至关重要。互联标准、带宽、延迟和低延迟是关键指标。
03奇异摩尔NDSA网络加速与无损数据传输解决方案
在智算中心领域,奇异摩尔 的NDSA互联系列产品复用以太网基础设施,基于高性能RoCEv2 RDMA引擎,面向智算网络通信加速及无损数据传输的专用DSA加速解决方案。
AI原生智能网卡
奇异摩尔的Kiwi NDSA-SNIC AI原生智能网卡针对网络数据传输,基于RoCE V2 RDMA技术,自适应网络调度算法,搭载可编程加速核心SDPU,高达800G传输带宽,实现Tb级万卡集群无损数据传输。
高性能网络加速芯粒
奇异摩尔的高性能网络加速芯粒 – Kiwi NDSA互联芯粒针对高带宽域数据传输,基于RoCEv2 RDMA技术,单芯粒传输带宽高达800G,携带UCIe-D2D芯粒可扩展互联接口,实现集群内TB级的高速通信。
写在最后,无论是在高性能计算领域还是在人工智能领域,我们会预见更多加速数据传输的DSA问世。它们通过提供高吞吐量效率,计算节点之间的超快速互连,或提升人工智能训练的效率,为半导体价值链的参与者及其客户带来更多的革新和挑战。
-
芯片
+关注
关注
455文章
50714浏览量
423113 -
人工智能
+关注
关注
1791文章
47183浏览量
238207 -
奇异摩尔
+关注
关注
0文章
49浏览量
3399
原文标题:Kiwi Talks | DSA专用领域芯片正在重塑人工智能与高性能计算
文章出处:【微信号:奇异摩尔,微信公众号:奇异摩尔】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Banana Pi 携手 ArmSoM 推出人工智能加速 RK3576 CM5 计算模块
德晟达推出高性能医疗专用AI一体机
机智云入选广州市“人工智能+”优秀解决方案册
嵌入式和人工智能究竟是什么关系?
《AI for Science:人工智能驱动科学创新》第6章人AI与能源科学读后感
《AI for Science:人工智能驱动科学创新》第一章人工智能驱动的科学创新学习心得
risc-v在人工智能图像处理应用前景分析
FPGA在人工智能中的应用有哪些?
人工智能与大模型的关系与区别
奇异摩尔上海总部进驻上海浦东科海大楼

三星电子将为代工业务提供人工智能解决方案
人工智能数据中心的新型连接解决方案

奇异摩尔携手SEMiBAY Talk 邀您畅谈互联与计算

摩尔线程携手瑞莱智慧共同打造人工智能、大模型的整体解决方案






 工商网监
工商网监
评论