 揭秘智算中心的互联技术决策
揭秘智算中心的互联技术决策
作者:张景涛
英伟达设计的DGX H100 NVL256超级计算集群,原本计划集成256个NVIDIA H100 GPU,但最终其在商业市场上却难觅其踪。这一现象引发了业界对其开发中止原因的广泛讨论。普遍观点认为,主要障碍在于成本收益不成正比。该系统在连接GPU时大量使用光纤,导致BOM成本激增,超出了标准NVL8配置的经济合理性范围。
DGX H100 NVL256 SuperPOD
尽管英伟达声称扩展后的NVL256能够为400B MoE训练提供高达2倍的吞吐量。然而,大客户经过计算分析,对英伟达的这一声明表示怀疑。尽管最新代的NDR InfiniBand即将达到400Gbit/s的速度,而NVLink4则达到450GB/s,理论上提供了约9倍的峰值带宽速度提升。该系统设计中使用了128个L1 NVSwitch和36个L2外部NVSwitch,形成了2:1的阻塞比,意味着每个服务器只能有一半的带宽连接至另一服务器。英伟达依赖NVlink SHARP技术来优化网络,以实现allToall带宽的等效性。
H100 NVL256 成本分析
在Hot Chips 34会议上对H100 NVL256 BoM的分析表明,扩展NVLink256使得每个超级单元(SU)的BoM成本增加了约30%。当扩展到超过2048个H100 GPU时,由于需要从两层InfiniBand网络拓扑转变为三层的网络拓扑,InfiniBand的成本百分比增加,这一比例略有降低。
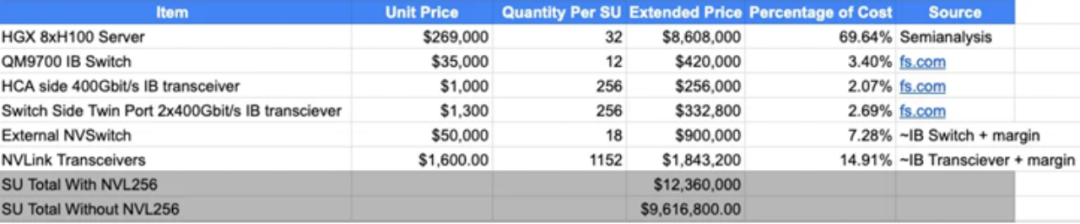
图2 NVL256成本分析
大客户和超大规模计算公司对他们当前的工作负载进行了性能/总拥有成本(perf/TCO)分析,并得出结论:相比支付NVL256扩展NVLink的成本,额外花费30%购买更多的HGX H100服务器能获得更好的性能/成本比。这一分析结果导致英伟达最终决定不推出DGX H100 NVL256产品。
GH200 NVL32 重新设计
随后,英伟达对NVL256进行了重新设计,将其缩减至NVL32,并采用了铜背板spine,这与他们NVL36/NVL72 Blackwell设计相似。据悉,AWS已同意为其Project Ceiba项目购买16k GH200 NVL32。据估计,这种重新设计的NVL32的成本溢价将比标准高级HGX H100 BoM高出10%。随着工作负载的持续增长,英伟达声称对于GPT-3 175B和16k GH200,NVL32的速度将比16k H100快1.7倍,在500B LLM推理上快2倍。这些性能/成本比对客户来说更具吸引力,也使得更多客户倾向于采用英伟达的这种新设计。
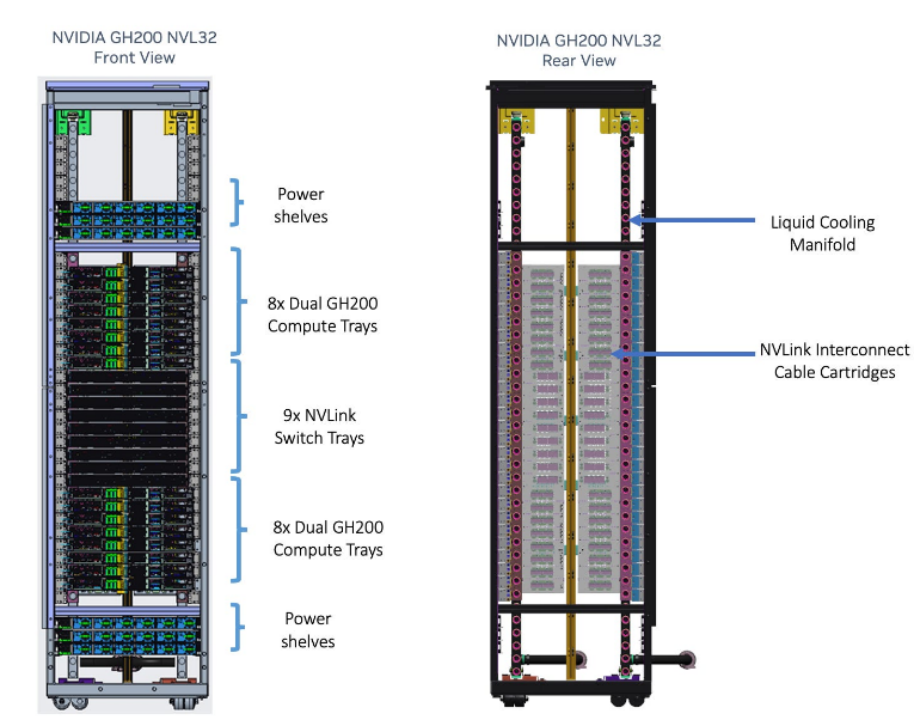
图3 GH200 NVL32
GB200 NVL72的突破
关于GB200 NVL72的预期推出,英伟达据信已经从H100 NVL256的失败中吸取了教训,转而采用铜缆互连,称为“NVLink spine”,以期解决成本问题。这种设计变更预计将降低商品成本(COG cost of goods),并为GB200 NVL72铺平成功之路。英伟达声称,采用铜设计,NVL72的成本将节省约6倍,每个GB200 NVL72架可节省约20kW电力,每个GB200 NVL32架子节省约10kW。
与H100 NVL256不同,GB200 NVL72将不会在计算节点内使用任何NVLink switch,而是采用平坦轨道优化(flat rail-optimized)的网络拓扑。对于每72个GB200 GPU,将有18个NVLink switch。由于所有连接都在同一机架内,最远的连接只需跨越19U(0.83米),这在有源铜缆的范围内是可行的。
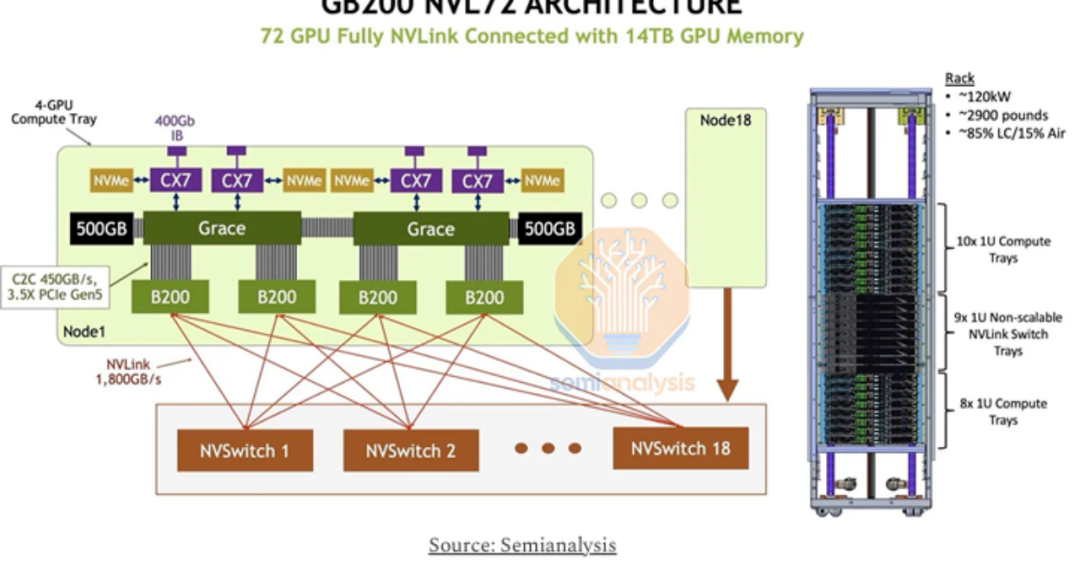
图4 GB200 NVL72架构
据Semianalysis报道,英伟达声称其设计可以支持在单个NVLink域内连接多达576个GB200 GPU。这可能通过增加额外的NVLink switch层来实现。预计英伟达将保持2:1的阻塞比,即在GB NVL576 SU内,将使用144个L1 NVLink switch加36个L2 NVLink switch。或者,他们也可能采取更积极的1:4阻塞比,仅使用18个L2 NVLink switch。他们将继续使用光学OSFP收发器来扩展从机架内的L1 NVLink switch到L2 NVLink switch的连接。

图5 GB200 NVL576架构
有传言称NVL36和NVL72已经占NVIDIA Blackwell交付量的20%以上。然而,对于大客户是否会选择成本更高的NVL576,这仍然是个问题,因为扩展到NVL576需要额外的光学器件成本。英伟达似乎已经吸取了教训,认识到铜缆的互联成本远低于光纤器件。
专家观点
其实对于到底该使用铜还是光,以及对NVL72的看法,半导体产业大神Doug O’Langhlin在其文章《The Data Center is the New Compute Unit:Nvidia's Vision for System-Level Scaling》也做了阐述:
铜缆互联将在机架级取得统治地位,并且在用光之前要榨干铜的所有价值。
I conclude that Copper will reign supreme at the rack scale level and can push Moore’sLaw scaling further. AI networking aims to scale copper networking as hard as possible before we have to use Optics.
对于NVL72的前途,大神也相当看好,认为这是摩尔定律在机架级的体现:
It all starts with Moore’s Law. There is a profound beauty in semiconductors, as thesame problem that is happening at the chip scale is the same problem that is happening at the data center level. Moore’s Law is a fractal, and the principles that apply tonanometers apply to racks.
基于无源铜缆的nvlink域将是一个新的成功基准,并且具备更好的成本收益比。
The new Moore’s Law is about pushing the most compute into a rack. Also, looking at Nvidia’s networking moat as InfiniBand versus Ethernet is completely missing the entirepoint. I think the NVLink domain over passive copper is the new benchmark of success,and it will make a lot of sense to buy GB200 NV72 racks instead of just B200s.
业界视角
财通证券的研报《铜互联,数据中心通信网络重要解决方案》也给出了自己的看法。研报中指出:
短距通信场景铜互联相对优势还是很明显的,铜连接产品在数据中心高速互联中一直扮演着重要角色。在数据中心能耗攀升,以及建设成本高企的背景下,铜互联在散热效率、低功耗、低成本方面有着一定优势。伴随Serdes 速率逐步从56G、112G 向224G升级,单端口速率将基于8 通道达到1.6T,高速传输成本有望大幅下降,对应铜缆速率也向着224Gbps 演进。为解决高速铜缆的传输损耗问题,AEC、ACC通过内置信号增强芯片提升传输距离,铜缆模组生产工艺也在同步升级。
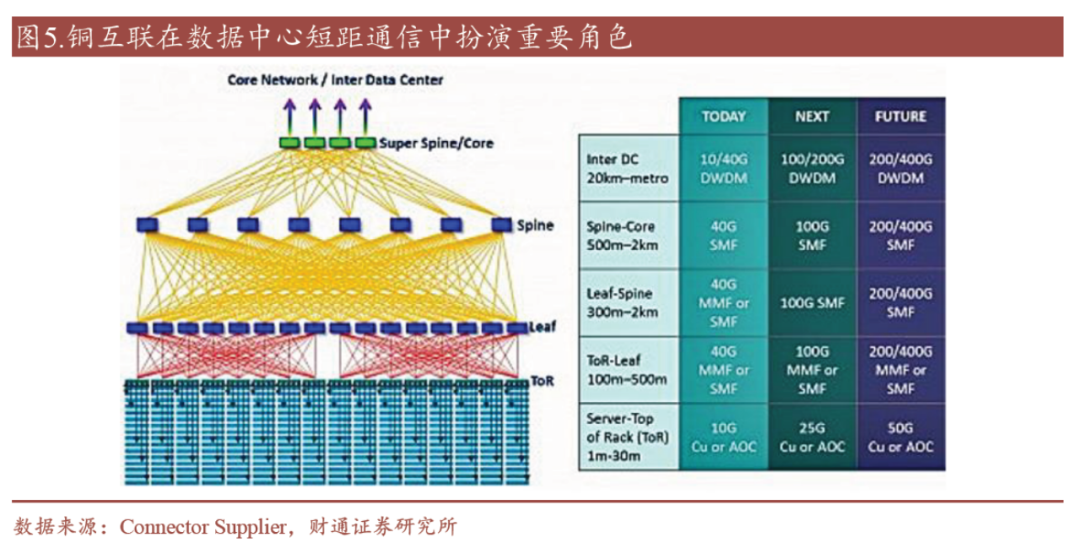
图7 铜互联在数据中心短距互联中的重要角色
根据Light Counting,全球无源直连电缆DAC 和有源电缆AEC 的市场规模将分别以25%和45%的年复合增长率增长。
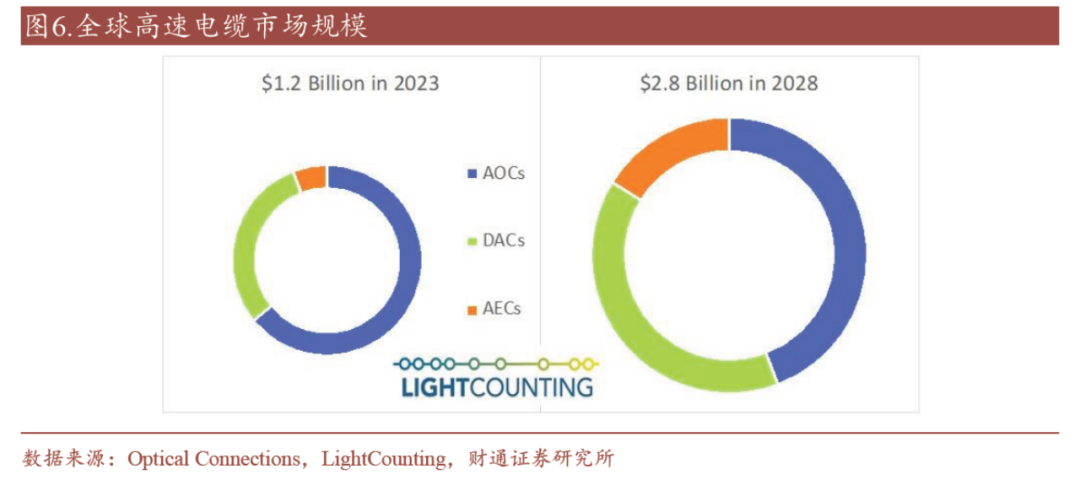
图8 铜缆高速复合增长
2010 年至2022 年间,交换机芯片带宽容量从640 Gbps 增长到了51.2 Tbps,80倍的带宽增长带来了22 倍的系统总功耗提升,其中光学元件功率(26 倍)的功耗提升尤为明显。
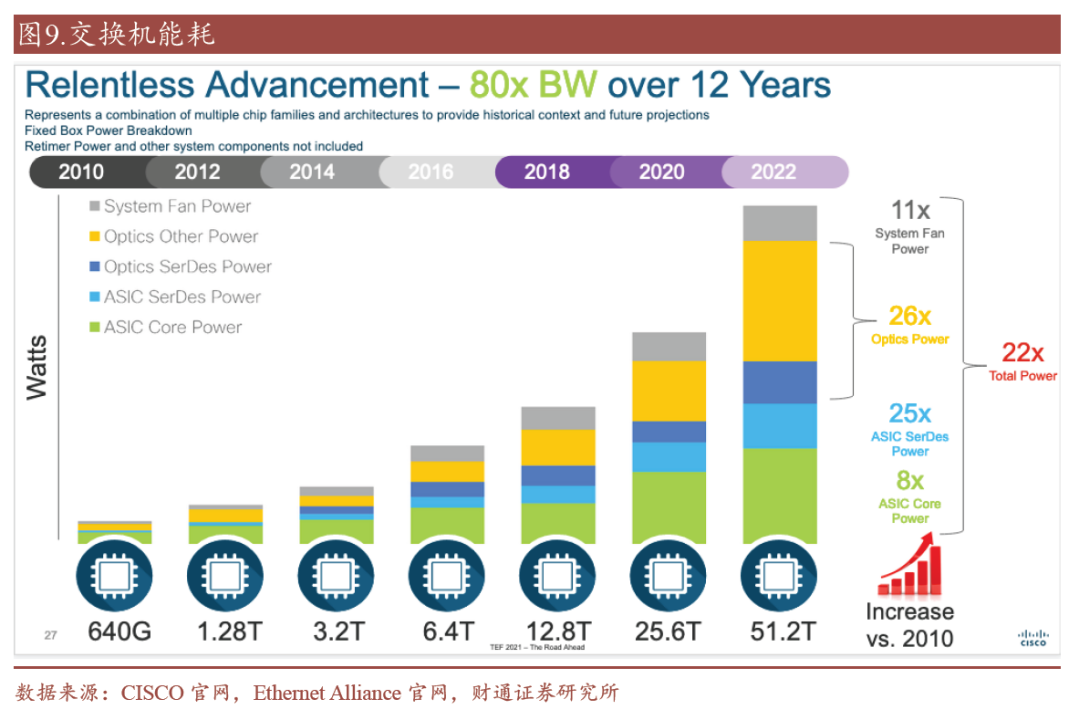
图9 光学器件功耗占比逐步提升
铜缆互联由于不涉及光电转化,因此具有低功耗特点,相比于有源光缆(AOC),目前的铜直接连接电缆(DAC)的功耗小于0.1 W,可以忽略不计,有源电缆(AEC)亦可将功耗控制在5w 以内,可在一定程度上降低算力集群整体功耗。

图10 功耗对比
在铜缆可触达的高速信号传输距离内,相比光纤连接,铜连接方案的成本较低,此外,铜缆模组在短距离内可以提供极低延迟的电信号传输并具有高可靠性,不会出现光纤在某些环境下可能出现的信号丢失或干扰风险。同时,铜缆的物理特性使得它更易于处理和维护,并且其具有高兼容度并不需要额外的转换设备。
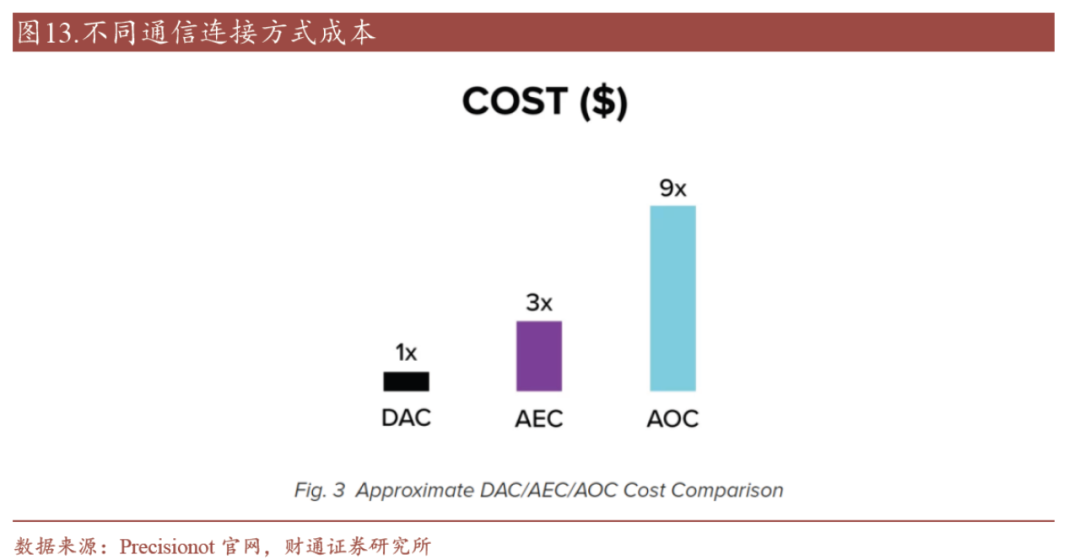
图11 成本对比
-
gpu
+关注
关注
28文章
4729浏览量
128882 -
服务器
+关注
关注
12文章
9123浏览量
85318 -
英伟达
+关注
关注
22文章
3770浏览量
90977 -
智算中心
+关注
关注
0文章
68浏览量
1690
原文标题:揭秘智算中心的互联技术决策
文章出处:【微信号:SDNLAB,微信公众号:SDNLAB】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
智算中心网络架构选型原则
智算中心加速布局,上游计算、存储、互联都涉及哪些芯片技术

数据中心光互联解决方案
智算中心,智慧时代的“发电站”
华中最火爆的算力中心-中亿云矿 带你揭秘Chia挖矿的致富之道!

北鲲云超算与传统超算中心的区别
基于华为云打造的成都智算中心正式上线
如何定义AI算力中心新实践
天数智芯与算力互联公司签署算力互联网合作框架协议
“捷智算”正式入驻国家超算互联网平台







 工商网监
工商网监
评论