 Linux内存管理中HVO的实现原理
Linux内存管理中HVO的实现原理
以下文章来源于Linux内核远航者 ,作者Linux内核远航者
开场白
环境:
内核源码:linux-6.6.29
ubuntu版本:20.04.1
代码阅读工具:vim+ctags+cscope
本文主要介绍内存管理中的HVO(HugeTLB Vmemmap Optimization)特性,通过HVO可以节省管理HugeTLB 页面元数据(struct page)的内存占用,甚至在缓存的空间局部性表现上也更好。本文通过图解结合源代码分析的方式让大家彻底理解HVO的实现原理,且本文主要以2M大小的HugeTLB 页面为例讲解。
1.术语解释
文中会提到三种物理页面,为了便于阐述,后面统一使用以下几个概念讲解:
例如2M大小的hugetlb页面,struct page结构大小为64Byte, 则需要 2M/4K = 512个struct page结构来管理hugetlb页面,那么这些struct page结构占用的物理内存为:512*64 = 32768Byte = 8个4k页面,即是page0 - page7。
head vmemmap page:hugetlb页面使用struct page结构占用的第一个物理页面, 2M大小的hugetlb页面则head vmemmap page就是page0。
tail vmemmap page:可以优化释放掉的struct page结构占用的物理页面,2M大小的hugetlb页面则tail vmemmap page就是page1 - page7。
new head vmemmap page:如果vmemmap page是连续的物理页面,假如只释放掉tail vmemmap page,可能会破坏掉连续性,HVO中会申请新的head vmemmap page,然后将head vmemmap page拷贝到这个页面,最后同时释放掉所有的struct page结构占用的物理页面, 2M大小的hugetlb页面则释放掉page0 - page7。
2.HVO优化原理及触发场景
2.1 HVO优化原理
下面我们从内核源码角度来看以下HVO优化原理。
//mm/hugetlb_vmemmap.c
hugetlb_vmemmap_optimize
->vmemmap_start=(unsignedlong)head//hugetlb页面的head vmemmap page所在地址。
->vmemmap_should_optimize//判断当前的hugetlb页面大小是否适合做HVO优化,
没有打开vmemmap_optimize_enabled或者hugetlb页面使用structpage结构占用的
内存小于一个4k页面不做优化。
->vmemmap_end=vmemmap_start+hugetlb_vmemmap_size(h);//获得优化的tailvmemmappage地址
vmemmap_reuse=vmemmap_start;//重复映射使用headvmemmappage地址
vmemmap_start+=HUGETLB_VMEMMAP_RESERVE_SIZE;//从第一个tailvmemmappage开始优化
->vmemmap_remap_free(vmemmap_start,vmemmap_end,vmemmap_reuse)//释放掉hugetlb页面使用struct page结构冗余的物理页面。
->walk.reuse_page=alloc_pages_node(nid,gfp_mask,0);
if(walk.reuse_page){
copy_page(page_to_virt(walk.reuse_page),
¦(void*)walk.reuse_addr);
list_add(&walk.reuse_page->lru,&vmemmap_pages);
}
//优化1:申请一个新的4k页面,即new head vmemmap page,然后将head vmemmap page拷贝到这个页面,然后将new head vmemmap page加入vmemmap_pages链表
(用于失败释放此页面使用)
->mmap_read_lock(&init_mm)//读方式获得init_mm的mmap_lock
->vmemmap_remap_range//遍历页表,释放冗余的物理页面(由于优化1,这里会释放掉所有的管理hugetlb页面使用的struct page结构占用的内存)。
->mmap_read_unlock(&init_mm)//读方式释放init_mm的mmap_lock
->free_vmemmap_page_list(&vmemmap_pages)//释放调用hugetlb页面使用structpage结构冗余的物理页面(例如2M大小的hugetlb页面,释放掉8页(page0-page7))
->SetHPageVmemmapOptimized(head)//为hugetlb页面设置HVO优化标记,定义在include/linux/hugetlb.h(HPAGEFLAG(VmemmapOptimized,vmemmap_optimized))
vmemmap_remap_pte的核心代码如下:
staticvoidvmemmap_remap_pte(pte_t*pte,unsignedlongaddr,
¦structvmemmap_remap_walk*walk)
{
/*
¦*Remapthetailpagesasread-onlytocatchillegalwriteoperation
¦*tothetailpages.
¦*/
pgprot_tpgprot=PAGE_KERNEL_RO;//映射tailvmemmappage为只读
structpage*page=pte_page(ptep_get(pte));//通过页表项获得structpage指针
pte_tentry;
/*Remappingtheheadpagerequiresr/w*/
if(unlikely(addr==walk->reuse_addr)){//如果当前的虚拟地址是reuse_addr
pgprot=PAGE_KERNEL;////映射headvmemmappage为可读可写
list_del(&walk->reuse_page->lru);//之前在hugetlb_vmemmap_optimize中将这个new head vmemmap page加入了vmemmap_pages,现在删除,供页面共享使用。
/*
¦*Makessurethatprecedingstorestothepagecontentsfrom
¦*vmemmap_remap_free()becomevisiblebeforetheset_pte_at()
¦*write.
¦*/
smp_wmb();
}
entry=mk_pte(walk->reuse_page,pgprot);//重要步骤:页表映射尾页到头页上!
list_add_tail(&page->lru,walk->vmemmap_pages);//将需要释放的页面加入vmemmap_pages链表
set_pte_at(&init_mm,addr,pte,entry);//设置页表项
}
优化之前图解:
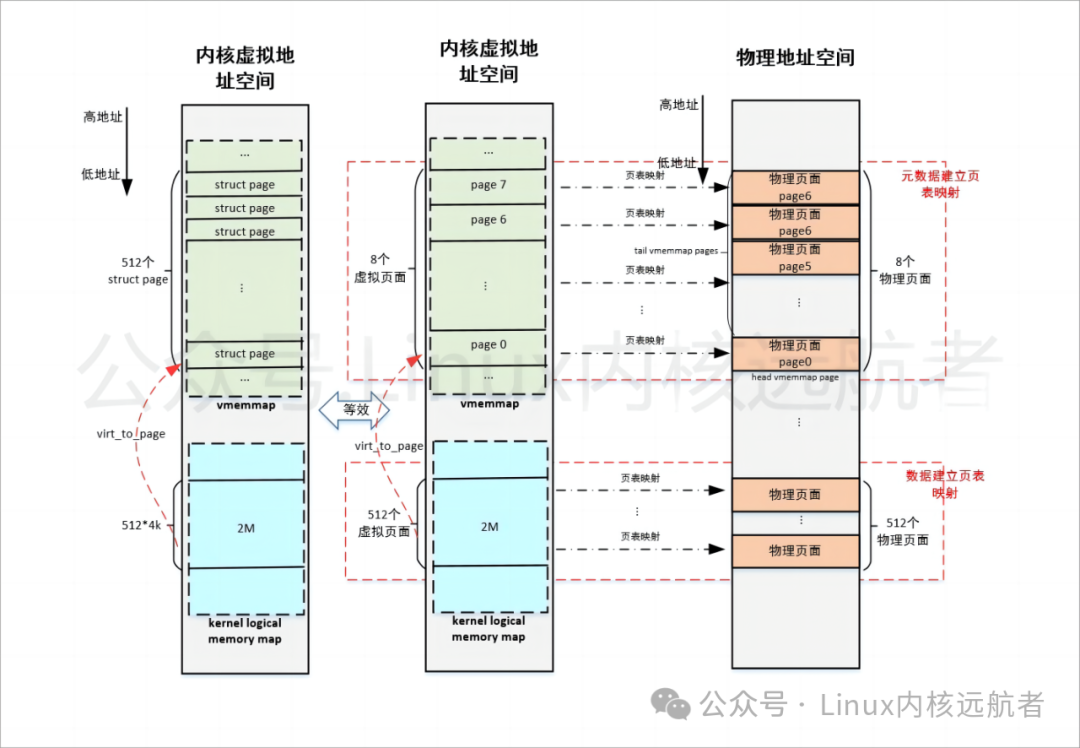
注意:数据建立页表映射是在内核初始化阶段的start_kernel->setup_arch->paging_init来做的线性页表映射,而元数据(struct page)建立页表映射是在内核初始化阶段的start_kernel->bootmem_init->sparse_init->sparse_init_nid->__populate_section_memmap来做,通过virt_to_page可以获得数据的元数据地址,后面HVO优化是改变之前的元数据的映射。
优化之后图解:
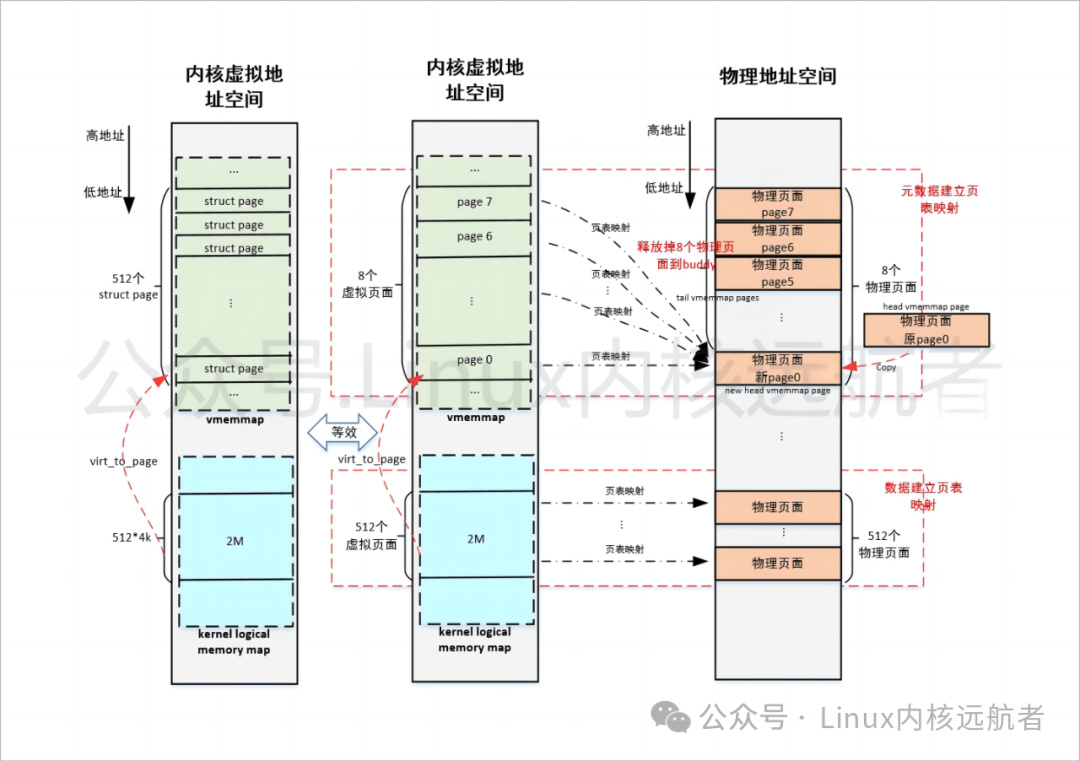
可以看出对于2M大小的hugetlb页面优化之后节省元数据(struct page)占用内存:7/8= 87.5%, 如果是 1G 的大页,可以节约的元数据(struct page)内存占用近乎 100%(读者可自行计算)。
2.2 HVO触发场景
HVO触发场景主要为需要申请hugetlb页面的时候:举例如下,
场景1:解析cmdline的hugepages=参数
如hugepages=100,启动阶段申请100个2M的hugetlb页面到大页池。
mm/hugetlb.c
__setup("hugepages=",hugepages_setup)
->hugepages_setup
->hugetlb_hstate_alloc_pages
->alloc_pool_huge_page
->alloc_fresh_hugetlb_folio//分配2M的hugetlb页面
->prep_new_hugetlb_folio
->__prep_new_hugetlb_folio
->hugetlb_vmemmap_optimize//触发HVO优化
场景2:写相关hugetlb页面的sys节点,增大相关页池中hugetlb页面数量
如:echo 1000 > /sys/kernel/mm/hugepages/hugepages-64B/nr_hugepages
mm/hugetlb.c nr_hugepages_store ->nr_hugepages_store_common ->set_max_huge_pages ->alloc_pool_huge_page ->alloc_fresh_hugetlb_folio//分配2M的hugetlb页面 ->prep_new_hugetlb_folio ->__prep_new_hugetlb_folio ->hugetlb_vmemmap_optimize//触发HVO优化
场景3:写proc节点,增大默认页池(如2M)中hugetlb页面数量
如:echo 1000 > /proc/sys/vm/nr_hugepages
mm/hugetlb.c hugetlb_table[] ->hugetlb_sysctl_handler ->hugetlb_sysctl_handler_common ->__nr_hugepages_store_common ->set_max_huge_pages ->alloc_pool_huge_page ->alloc_fresh_hugetlb_folio//分配2M的hugetlb页面 ->prep_new_hugetlb_folio ->__prep_new_hugetlb_folio ->hugetlb_vmemmap_optimize//触发HVO优化
3.撤销HVO优化原理及触发场景
3.1 撤销HVO优化原理
有的时候需要撤销HVO所作的优化,如需要缩小hugetlb页池中页面数量。
相关源码分析如下:
mm/hugetlb_vmemmap.c hugetlb_vmemmap_restore ->首先通过HPageVmemmapOptimized(head)判断是否hugetlb页面被HVO优化了,没有则直接返回 ->vmemmap_end=vmemmap_start+hugetlb_vmemmap_size(h);//获得优化的tailvmemmappage地址 vmemmap_reuse=vmemmap_start;//重复映射使用的headvmemmappage地址 vmemmap_start+=HUGETLB_VMEMMAP_RESERVE_SIZE;//从第一个tailvmemmappage开始优化 ->vmemmap_remap_alloc(vmemmap_start,vmemmap_end,vmemmap_reuse)//还原HVO之前所作的优化:重新映射vmemmap的虚拟地址范围到vmemmap_pages页面 ->alloc_vmemmap_page_list(start,end,&vmemmap_pages)//分配所有的tailvmemmappage,如2M大小的hugetlb页面,分配page1-page7,共7个页面,page0已有不需要分配 ->mmap_read_lock(&init_mm)//读方式获得init_mm的mmap_lock ->vmemmap_remap_range(reuse,end,&walk)//遍历页表,重新映射vmemmap的虚拟地址范围到vmemmap_pages中分配的页面 ->vmemmap_restore_pte//对于每个页表项,调用vmemmap_restore_pte处理 ->mmap_read_unlock(&init_mm)//读方式释放init_mm的mmap_lock ->ClearHPageVmemmapOptimized(head)//清除hugetlb页面的优化标记 vmemmap_remap_pte的核心代码如下: /* *Howmanystructpagestructsneedtobereset.Whenwereusethehead *structpage,thespecialmetadata(e.g.page->flagsorpage->mapping) *cannotcopytothetailstructpagestructs.Theinvalidvaluewillbe *checkedinthefree_tail_page_prepare().Inordertoavoidthemessage *of"corruptedmappingintailpage".Weneedtoresetatleast3(one *headstructpagestructandtwotailstructpagestructs)structpage *structs. */ #defineNR_RESET_STRUCT_PAGE3 staticinlinevoidreset_struct_pages(structpage*start) { structpage*from=start+NR_RESET_STRUCT_PAGE; BUILD_BUG_ON(NR_RESET_STRUCT_PAGE*2>PAGE_SIZE/sizeof(structpage)); memcpy(start,from,sizeof(*from)*NR_RESET_STRUCT_PAGE); } staticvoidvmemmap_restore_pte(pte_t*pte,unsignedlongaddr, structvmemmap_remap_walk*walk) { pgprot_tpgprot=PAGE_KERNEL;//页表属性可读可写 structpage*page; void*to; BUG_ON(pte_page(ptep_get(pte))!=walk->reuse_page); page=list_first_entry(walk->vmemmap_pages,structpage,lru);//vmemmap_pages链表中获得一个物理页面 list_del(&page->lru);//page从vmemmap_pages链表中删除 to=page_to_virt(page); copy_page(to,(void*)walk->reuse_addr);//将headvmemmappage的页面内容拷贝到这个物理页面 reset_struct_pages(to);//由于描述hugetlb页面的structpage结构,只有前3个structpage结构用于描述hugetlb页面信息, 其他的structpage结构都只是有compound_head是有意义的,为了防止free_tail_page_prepare有错误的检查报告,这里将所有tailvmemmappage的 内容都设置为正常值。 /* ¦*Makessurethatprecedingstorestothepagecontentsbecomevisible ¦*beforetheset_pte_at()write. ¦*/ smp_wmb(); set_pte_at(&init_mm,addr,pte,mk_pte(page,pgprot));//重新映射页表到这个物理页面 }
3.2 撤销HVO触发场景
场景1:写相关hugetlb页面的sys节点,减小相关页池中hugetlb页面数量
例如 写/sys/kernel/mm/hugepages/hugepages-xxxkB/nr_hugepages
echo 500 > /sys/kernel/mm/hugepages/hugepages-64B/nr_hugepages //从之前1000减小到500
mm/hugetlb.c nr_hugepages_store nr_hugepages_store_common set_max_huge_pages ->flush_free_hpage_work(h); ->free_hpage_workfn ->__update_and_free_hugetlb_folio ->hugetlb_vmemmap_restore ->update_and_free_pages_bulk ->__update_and_free_hugetlb_folio ->hugetlb_vmemmap_restore
场景2:写proc节点,减小默认页池中hugetlb页面数量
例如 写/proc/sys/vm/nr_hugepages
echo 500 > /proc/sys/vm/nr_hugepages //从之前1000减小到500
mm/hugetlb.c hugetlb_table[] ->hugetlb_sysctl_handler ->hugetlb_sysctl_handler_common ->__nr_hugepages_store_common ->set_max_huge_pages ->flush_free_hpage_work(h); ->free_hpage_workfn ->__update_and_free_hugetlb_folio ->hugetlb_vmemmap_restore ->update_and_free_pages_bulk ->__update_and_free_hugetlb_folio ->hugetlb_vmemmap_restore
场景3:写/sys/kernel/mm/hugepages/hugepages-xxxkB/demote
mm/hugetlb.c demote_store ->demote_pool_huge_page ->demote_free_hugetlb_folio ->hugetlb_vmemmap_restore
4.HVO中头页的获取问题
通过上面的分析,我们知道通过将tail vmemmap page映射head vmemmap page,然后释放掉tail vmemmap page,从而达到节省vmemmap page占用内存的目的,但是会出现我们获得的尾页的struct page指向头页的struct page的情况。如图所示,以2M大小的hugetlb页面为例:
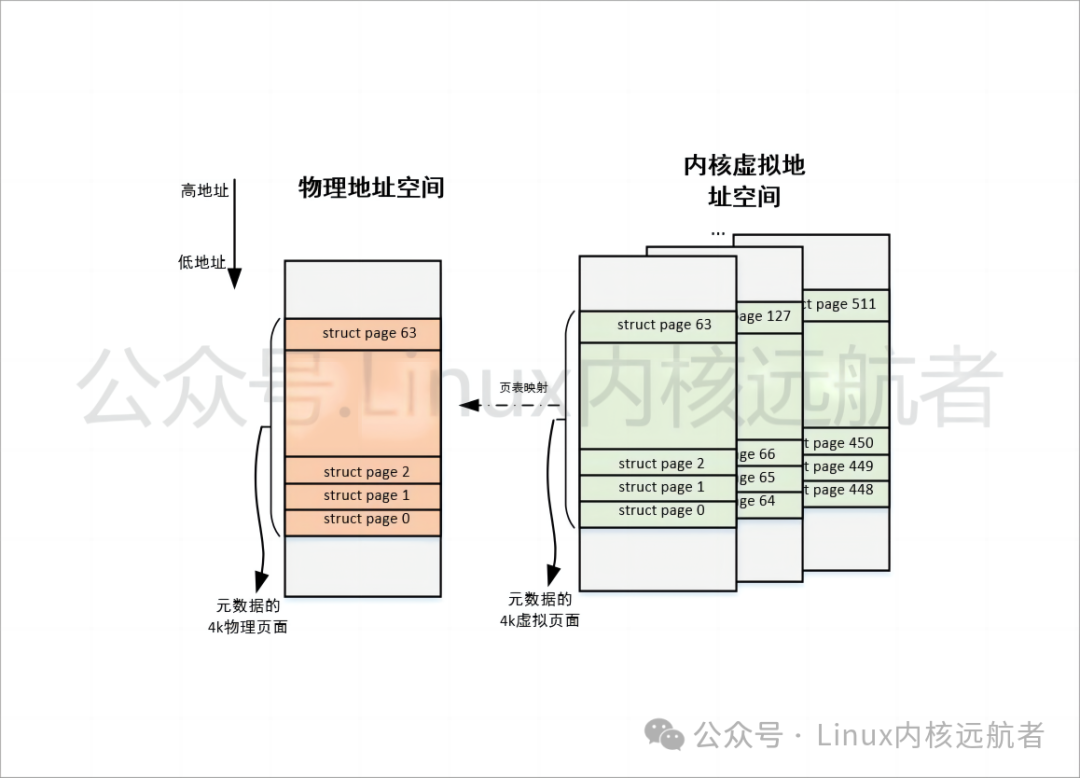
可以看到需要struct page0 - struct page511,512个struct page来描述hugetlb页面,那么通过HVO优化后:
[struct page0, struct page63]<----> head vmemmappage
[struct page64, struct page127] <----> tail vmemmap page
... <----> tail vmemmappage
[struct page448, struct page511] <----> tail vmemmappage
都页表映射到head vmemmap page。
那么struct page0, struct page64,..., struct page448都会指向struct page0,可能会在判断是否为头页的代码中造成混乱,也可以看出这些struct page地址都是对齐4k的。
这里需要补充说明下:对于复合页(THP、hugetlb都属于复合页),头页会设置PG_head标记,而尾页的compound_head=head_page | 0x1。
像这些描述尾页的struct page,被成为"伪造的头页",内核中处理如下(page_folio为例):
include/linux/page-flags.h
page_folio
->_compound_head
->staticinlineunsignedlong_compound_head(conststructpage*page)
{
unsignedlonghead=READ_ONCE(page->compound_head);//获取页面的compound_head成员
if(unlikely(head&1))//是真正的尾页
returnhead-1;//计算出头页地址,返回
return(unsignedlong)page_fixed_fake_head(page);//为真正的头页或者为伪造的头页。
}
page_fixed_fake_head处理如下:
/*
*Returntherealheadpagestructiffthe@pageisafakeheadpage,otherwise
*returnthe@pageitself.SeeDocumentation/mm/vmemmap_dedup.rst.
*/
static__always_inlineconststructpage*page_fixed_fake_head(conststructpage*page)
{
if(!static_branch_unlikely(&hugetlb_optimize_vmemmap_key))
returnpage;
/*
¦*OnlyaddressesalignedwithPAGE_SIZEofstructpagemaybefakehead
¦*structpage.Thealignmentcheckaimstoavoidaccessthefields(
¦*e.g.compound_head)ofthe@page[1].Itcanavoidtoucha(possibly)
¦*coldcachelineinsomecases.
¦*/
if(IS_ALIGNED((unsignedlong)page,PAGE_SIZE)&&
¦test_bit(PG_head,&page->flags)){//structpage结构地址只有对齐PAGE_SIZE才有可能为伪造的头页
/*
¦*Wecansafelyaccessthefieldofthe@page[1]withPG_head
¦*becausethe@pageisacompoundpagecomposedwithatleast
¦*twocontiguouspages.
¦*/
unsignedlonghead=READ_ONCE(page[1].compound_head);//获得下一个structpage地址的compound_head成员,实际上就是获取第一个尾页的compound_head
if(likely(head&1))
return(conststructpage*)(head-1);//计算获得真正的头页地址
}
returnpage;
}
通过上面计算我们就可以得到真正的头页,简单来说就是通过struct page1->compound_head计算获得头页。
所有打开HVO优化后,可能描述hugetlb页面的struct page有三种情况:
真正的头页,如上例子中的struct page0,计算头页的时候直接返回struct page0地址即可。
伪造的头页,如上例子中的struct page64,struct pageN(N=n*64, n=1-6) ,struct page448。通过struct page1->compound_head计算获得头页地址。
真正的尾页,除了1和2的所有情况,直接通过当前struct page->compound_head计算获得头页地址。
5.总结
通过以上的分析,我们知道:HVO主要是并不节省实际用户数据(如2M大小的HugeTLB 页面)的内存占用,而是节省管理HugeTLB 页面元数据(如描述2M大小的HugeTLB 页面的512个struct page)的内存占用,巧妙的利用了HugeTLB机制的一些特性(如HugeTLB 页面使用头三个struct page来描述其页面状态,不支持分裂,不支持部分unmap等),使得我们可以共享struct page所在的第一个物理页面,释放掉其他冗余的物理页面,从而达到节省内存的目的。
-
处理器
+关注
关注
68文章
19259浏览量
229638 -
内核
+关注
关注
3文章
1372浏览量
40273 -
Linux
+关注
关注
87文章
11291浏览量
209307 -
内存管理
+关注
关注
0文章
168浏览量
14132
原文标题:深入理解Linux内核之HVO(HugeTLB Vmemmap Optimization)
文章出处:【微信号:LinuxDev,微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
走进Linux内存系统探寻内存管理的机制和奥秘
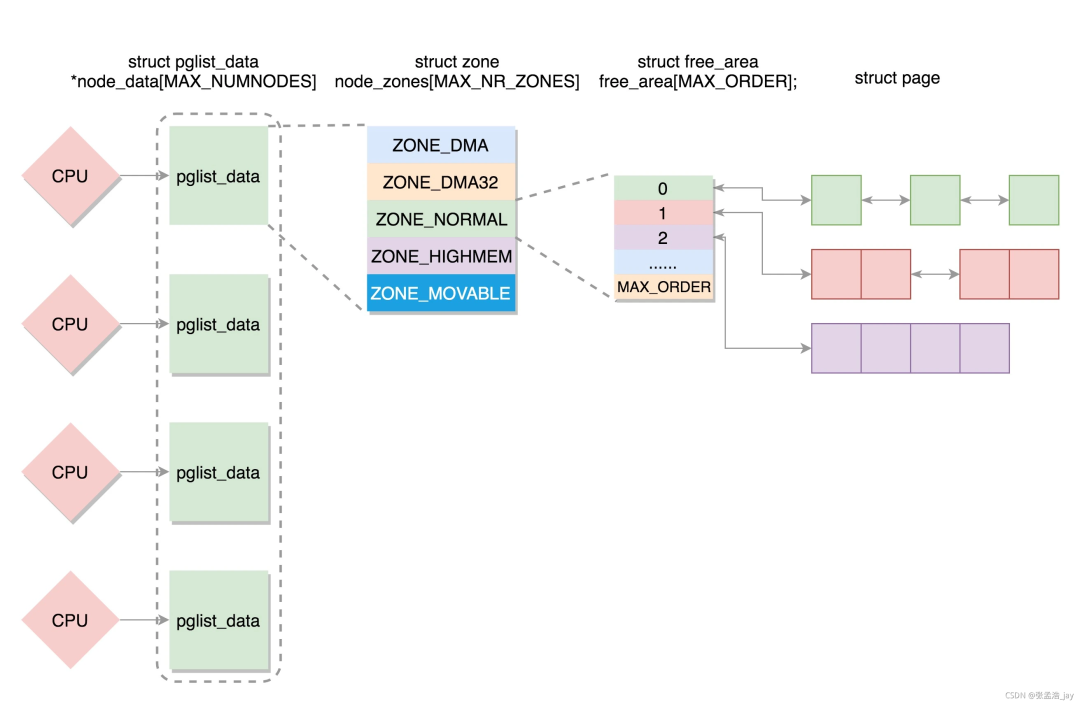

Linux中内存管理子系统开发必知的3个结构概念





 工商网监
工商网监
评论