 LIBS结合机器学习算法的江西名优春茶采收期鉴别
LIBS结合机器学习算法的江西名优春茶采收期鉴别
一、引言
激光诱导击穿光谱(LIBS)技术是近些年发展起来的一种对材料所含元素进行定性和定量分析的检测技术,相对于其他分析技术,LIBS技术具有多元素同时检测、结构简单、检测速度快等独特优势。目前,利用LIBS检测技术对茶叶样品进行快速分类已成为国内外LIBS领域研究的热点。这些研究表明,利用LIBS表征的物质元素光谱信息结合化学计量学模型对茶叶的地理来源和品种进行追溯是可行的。然而,目前缺乏春茶采收期LIBS鉴别相关研究。因此,本工作通过分析江西特色名优春茶不同采收期的LIBS特征光谱,寻找春茶采收期快速鉴别方法。
材料与方法
2.1 样品制备
本文分析的春茶样品均采自中国江西省,分为明前(清明节气前采收)茶与雨前(清明节气到谷雨节气间采收)茶两类采收期春茶,样品具体信息如表1所示,其中,CNY/50g表示的是每50g茶叶的价格。本研究以这两种江西特色名优茶叶为例,开展基于LIBS的春茶采收期鉴别分析工作,并据此将样品进行规范保存、预处理和实验。
对于茶叶样品,为获得较好的LIBS信号,并减少样品中元素物理、化学基体的影响,采用粉碎机将茶叶粉碎后过100目筛,利用电子天平称量3g样品粉末,在压片机20t的压力下将待测样品压制成直径约为25mm、厚度约为3mm的圆饼片。每类春茶取10个重复样本,共得到40个实验样本。对于茶水样品,当LIBS技术应用于液体中重金属元素检测时,激光能量损耗大、水体的淬灭效应、水体对等离子体的压缩作用和水中等离子体的离散结构等会导致检测的光谱信号弱且不稳定。
为了解决这一问题,本实验组探索了多种改变液体样品形态的方法,包括原始溶液、冷冻样品、木片富集和滤纸富集。经过测试,滤纸富集技术被确定为最有效的方法。最终采取如下茶水富集实验方案:将3g茶叶称入100mL烧杯中,加入50mL的100℃蒸馏水,浸泡5min,再将茶水样品浸入直径为60mm含有定量滤纸的培养皿中,目的是将茶水中浸出的物质富集在滤纸上,并让滤纸自然干燥。对每类春茶的10个茶水样品重复此方案,共获得40个测试样品。获得的单个茶叶及茶水富集的样品如图1所示。
表1春茶样品信息


图1单个实验样品 (a)茶叶;(b)茶水富集
2.2 LIBS实验装置
LIBS检测系统主要装置如图2所示。
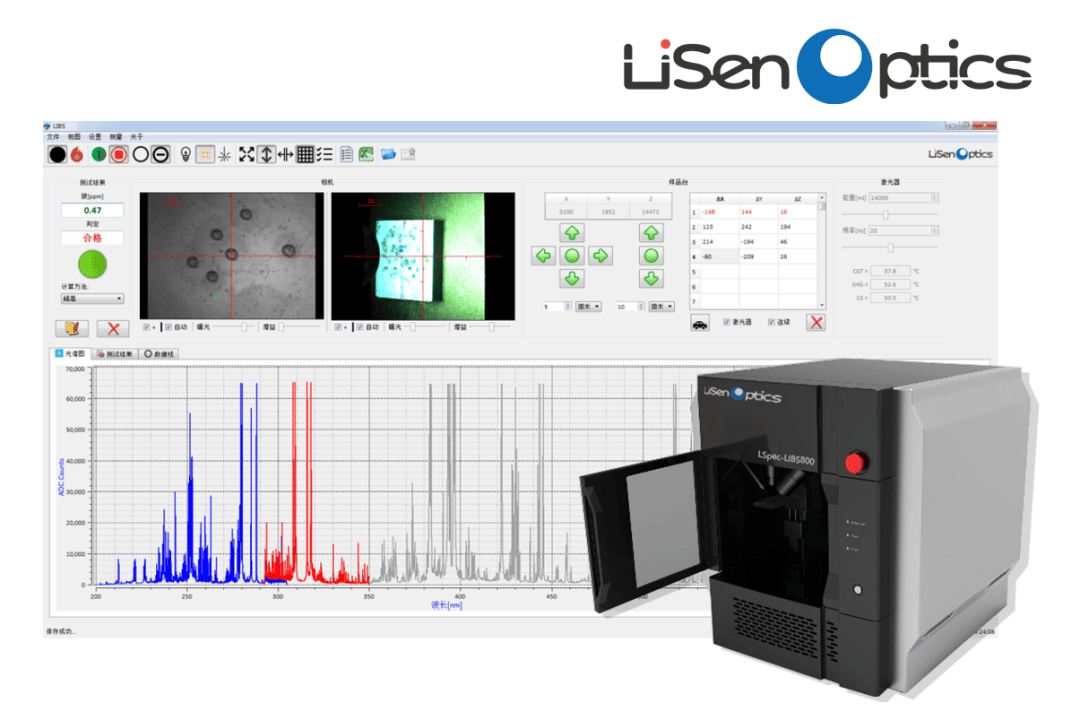
图2LIBS主要装置示意图
需要说明的是,对于每类采收期春茶,前期分别获得10个茶叶样品和10个茶水样品。而针对于每个样本,随机取10个测试位点进行光谱采集,同时为减少光谱的波动性,将每个位点产生的3个脉冲光谱均值作为一幅光谱,即每类茶叶和茶水样品得到100幅光谱数据,4类关联采收期春茶的茶叶和茶水分别获得400幅光谱数据。
结果与讨论
3.1 样品LIBS特征谱线分析
在优化的LIBS实验条件下,采集的庐山云雾茶和狗牯脑茶明前、雨前原始茶叶的LIBS平均光谱对比如图3(a)、(b)所示,茶水富集后的LIBS平均光谱对比如图4(a)、(b)所示。
可以看出,LIBS光谱包含众多离散的光谱线,而光谱线的强度与特定化学元素的浓度有关,这些元素可通过原子光谱数据库来确定。在200~1050nm波长范围内,所测特征谱线波长差异小,即不同采收期茶叶所含元素类型几乎相同;而不同采收期LIBS光谱强度在特定的波长上观察到明显的区别。
同时,本工作中的两类名优茶的雨前整体LIBS光谱强度较明前更高,可能的原因是雨前茶的生长周期更长。此外,可看到原始光谱在550~700nm等波段存在轻微的连续背景干扰。
因此,采用一种典型的基线校正方法对原始LIBS数据进行预处理,即对谱峰进行识别,扣除基线强度,其能有效地避免基线强度对谱线强度造成的影响和防止模型过拟合。以庐山云雾春茶为例,基线校正后LIBS茶叶平均图谱如图5所示,LIBS光谱中连续背景辐射得到了有效消除,且光谱预处理前后的整体趋势未发生改变。
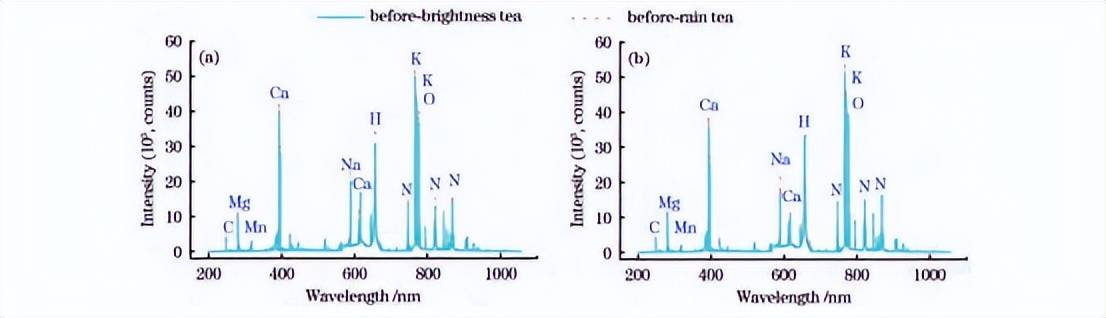
图3茶叶LIBS平均光谱图。(a)庐山云雾茶叶原始光谱;(b)狗牯脑茶叶原始光谱
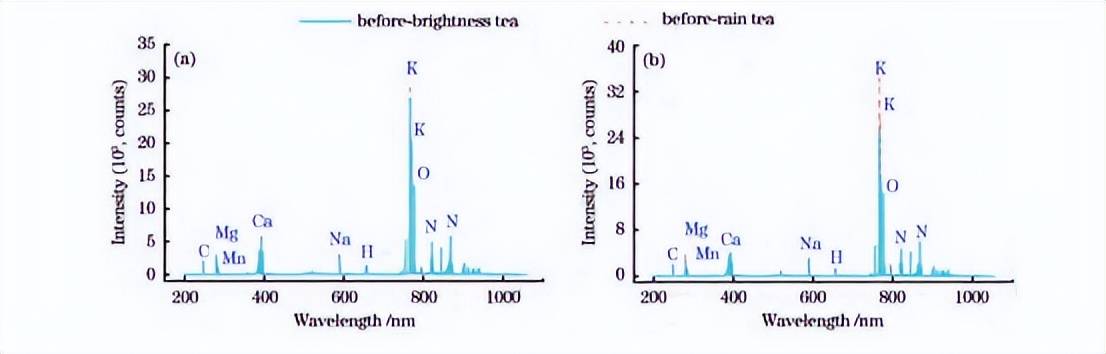
图4茶水LIBS平均光谱图。(a)庐山云雾茶原始光谱;(b)狗牯脑茶原始光谱
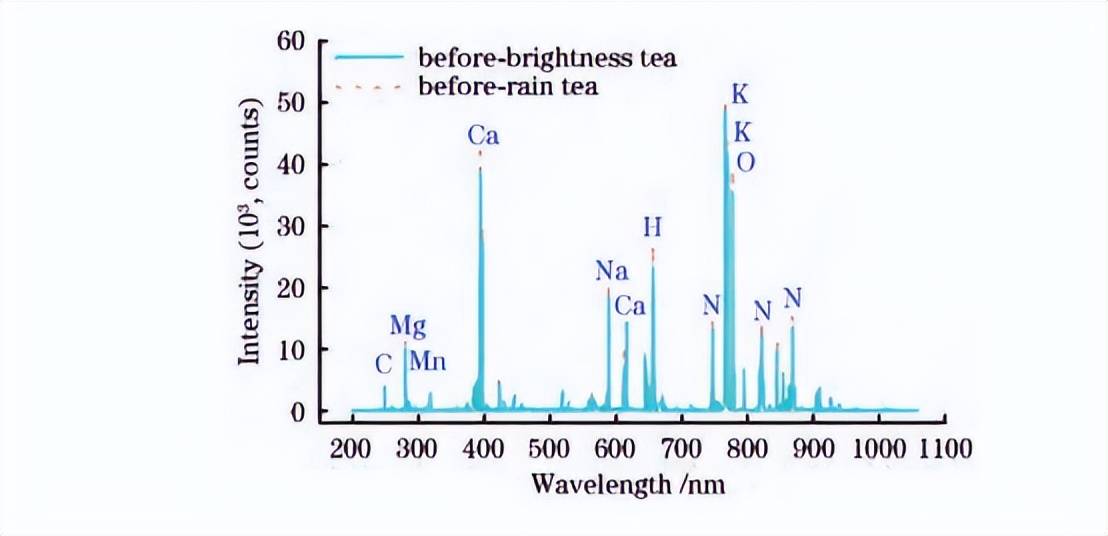
图5基线校正庐山云雾茶叶平均光谱图
3.2 光谱特征提取
在LIBS检测过程中,会产生高维度的光谱数据,这项工作中单幅光谱直接获得的数据维度为16359维,而LIBS分析通常只使用特征峰的波长和强度信息。因此,对LIBS光谱数据进行特征提取有助于提高分类的识别准确率和效率。对其主要的元素组成进行鉴定和标记后可以看出Mg、Mn、Ca、Na、K等金属以及C、H、O、N等非金属元素清晰的特征谱线。由于实验在自然环境下进行,为减少空气中氧气和氮气对结果的影响,故不参考O和N的特征谱线。优选出11条谱线差异的信息作为光谱指纹来识别不同类型的茶,如表2所示。
表2优选的11条谱峰

3.3 春茶样品PCA探索性分析
将上述优选的11条特征谱线数据作为输入变量,分别采用PCA法对春茶样品的茶叶、茶水及茶叶茶水融合的光谱数据进行聚类分析。值得说明的是,茶叶茶水融合的方法是特征级融合,即将茶叶和茶水各自优选的11个特征峰拼接起来,形成22个谱峰数据融合的特征空间。分别利用庐山云雾春茶和狗牯脑春茶的PCA前三主成分得分绘制三维散点图,并标出95%的置信区间,如图6、7所示。可以看出,尽管类内样本较为集中,但茶叶类别之间有重叠的PCA聚类属性,这表明了区分的挑战性。其可能的原因是明前茶、雨前茶生长条件类似(包括气候和土壤等)。因此,有必要引入其他算法以实现春茶采收期鉴别。
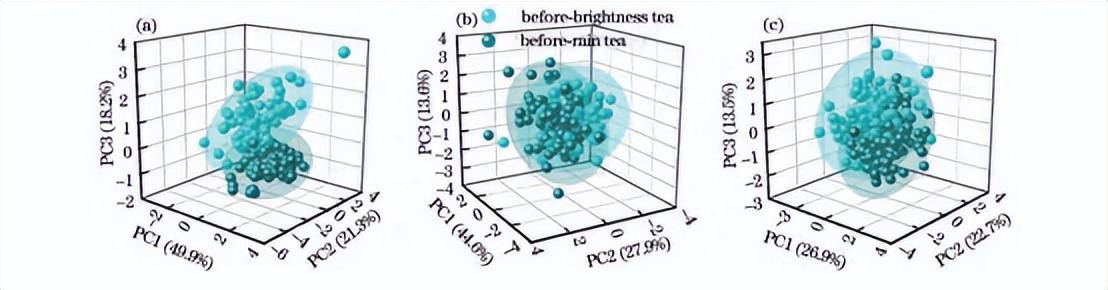
图6庐山云雾春茶PCA三维散点图。(a)茶叶;(b)茶水;(c)融合数据
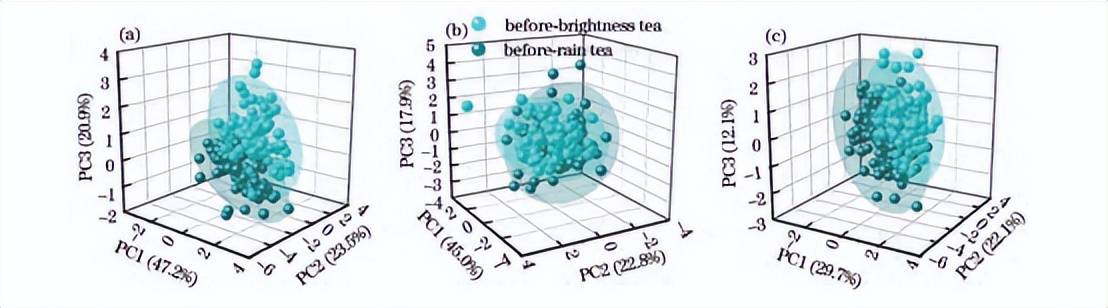
图7狗牯脑春茶PCA三维散点图。(a)茶叶;(b)茶水;(c)融合数据
将优选的茶叶、茶水以及茶叶茶水融合谱峰构建特征空间,同时采用机器学习中常用的随机化测试策略,对于每个分类任务,光谱数据以3∶2的比例随机分为训练样本和测试样本。
值得说明的是,训练集识别率的统计采用小样本的5-折交叉验证法,即将样本随机分为5等份,每次将其中1份作为验证集,剩下4份作为训练集进行训练,将5次结果的正确率平均值作为对训练集精度的估计。基于此,采用机器学习算法实现江西名优春茶快速鉴别。此外,为了保证训练集和测试集的代表性和平衡性,以及避免过拟合或欠拟合的问题。
评估随机划分训练集和测试集1000次的分类效果,同时这个过程并没有进行迭代优化,以保证结果的独立性和可靠性。值得提出的是,茶叶、茶水和融合数据在单次的模式识别用时都稳定在0.1s左右,说明茶叶茶水融合之后数据处理过程并没有增加太多时间消耗。庐山云雾春茶、狗牯脑春茶的每种模式识别连续1000次交叉验证集和测试集平均识别率结果如表3、表4所示,括号内数值表示的是1000次分类结果的标准误差。
表3 庐山云雾茶的交叉验证集和测试集的分类模型结果比较

表4 狗牯脑茶的交叉验证集和测试集的分类模型结果比较

绘制庐山云雾春茶、狗牯脑春茶测试集连续1000次平均识别率,如图8(a)、(b)所示,误差棒表示的是1000次分类结果的标准误差。
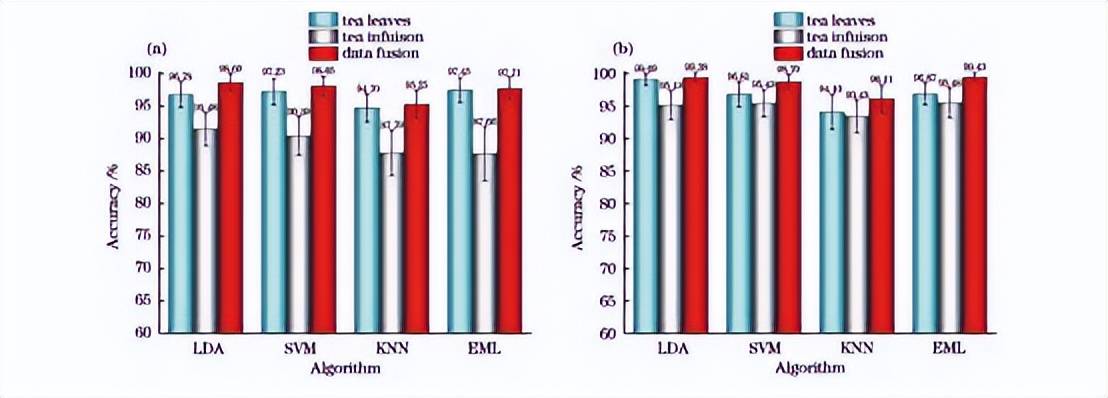
图81000 次平均识别率对比图。(a)庐山云雾春茶;(b)狗牯脑春茶
分析验证集和测试集的平均识别率结果可知,茶叶的分类效果优于茶水,而数据融合之后的效果最好,同时数据融合之后1000次运行结果的标准差变小了,即分类结果更为稳定。以LDA模型为例:庐山云雾春茶数据融合之后测试集准确率相较于茶叶和茶水分别提升了约1.82个百分点和7.12个百分点,而标准差分别降低了约30.81%和45.42%;狗牯脑春茶数据融合之后测试集准确率相较于茶叶和茶水分别提升了约0.29个百分点和4.25个百分点,而标准差分别降低了约13.48%和64.84%。因此,融合方法比单独的方法具有更好的稳定性和鲁棒性。
通过比较4种识别算法,发现LDA模型具有更好的性能和稳定性:庐山云雾春茶的茶叶、茶水及数据融合的1000次测试集平均识别率分别为96.78%、91.48%和98.60%;狗牯脑春茶的茶叶、茶水及数据融合的1000次测试集平均识别率分别为99.09%、95.13%和99.38%。而KNN模式识别测试结果较差,但表现较差的茶水分类结果仍在87%以上,数据融合之后可达95%的准确率,可见所使用的机器学习算法均具有良好的分类性能。
四、总结
在茶叶检测中,对不同采收期春茶的鉴别是一项重要工作。本研究采集了2022年江西两种名优茶春季不同采收期LIBS光谱,采用基线校正方法对LIBS光谱背景信号进行修正,并优选出11组特征变量,引入算法构建训练分类模型。结果表明,融合数据的分类结果优于单独使用茶叶或茶水获得的结果,其中,LDA模型表现较好,对于庐山云雾春茶与狗牯脑春茶的1000次交叉验证集和测试集,平均准确率分别达到98.29%和98.60%以及99.20%和99.38%。研究结果表明,LIBS结合机器学习方法对春茶采收期鉴别具有可观潜力。此外,针对茶叶和茶水的LIBS光谱学和化学计量学相结合的方法可以扩展到其他茶叶类型的识别。
推荐:
激光诱导击穿光谱技术在低碳钢铁冶金行业的应用
LlBS激光诱导击穿光谱系统是该技术通过超短脉冲激光聚焦样品表面形成等离子体,利用光谱仪对等离子体发射光谱进行分析,识别样品中的元素组成成分,可以进行材料的识别、分类、定性以及定量分析。
审核编辑 黄宇
-
算法
+关注
关注
23文章
4607浏览量
92819 -
机器学习
+关注
关注
66文章
8406浏览量
132553 -
LDA
+关注
关注
0文章
29浏览量
10605 -
激光诱导
+关注
关注
0文章
25浏览量
5585
发布评论请先 登录
相关推荐
基于LIBS技术的植物及其生长环境检测—LIBS技术的土壤元素检测

为什么LIBS激光诱导击穿光谱技术备受关注?
NPU与机器学习算法的关系
LIBS应用于液体样品
人工智能、机器学习和深度学习存在什么区别

螯合树脂辅助 LIBS 技术对水中铁元素检测研究
LIBS激光诱导击穿光谱技术是什么
基于LIBS的中药质量检测技术与应用
码垛机器人在江西建材厂的应用
机器学习算法原理详解
名单公布!【书籍评测活动NO.35】如何用「时间序列与机器学习」解锁未来?
春茶大量上市,直线电机炒茶机正当忙

机器学习怎么进入人工智能
机器学习8大调参技巧






 工商网监
工商网监
评论