 特伦托大学与Inria合作:使用GAN生成人体的新姿势图像
特伦托大学与Inria合作:使用GAN生成人体的新姿势图像
意大利Trento大学和法国国立计算机及自动化研究院研究人员(Aliaksandr Siarohin、Enver Sangineto、Stephane Lathuiliere、Nicu Sebe)合作,使用GAN(对抗生成网络)生成人体的新姿势图像。研究人员提出的可变形跳跃连接和最近邻损失函数,更好地捕捉了局部的纹理细节,缓解了之前研究生成图像模糊的问题,生成了更可信、质量更好的图像。
网络架构
生成视觉内容的深度学习方法,最常用的就是变分自动编码器(VAE)和生成对抗网络(GAN)。VAE基于概率图模型,通过最大化相应数据的似然的下界进行训练。GAN模型基于两个网络:一个生成网络和一个判别网络。两个网络同时训练,生成网络尝试“愚弄”判别网络,而判别网络则学习如何分辨真实图像和虚假图像。
现有的姿势生成方面的工作大部分基于条件GAN,这里研究人员也使用了条件GAN。之前一些工作使用了两段式方法:第一个阶段进行姿势集成,第二个阶段进行图像改良。研究人员则使用了端到端的方法。
既然使用GAN,那网络架构的设计就包括两部分,生成网络和判别网络。其中,一般而言,判别网络的设计相对容易。这符合直觉,比如,判别画作的真假要比制作一幅足以以假乱真的赝品容易得多。因此,我们首先考虑判别网络的情形。
判别网络
我们考虑判别网络的输入和输出。
首先是相对简单的输出。判别网络的输出,基本上就是两种,一种是离散的分类结果,真或假,一种是连续的标量,表明判别网络对图像是否为真的信心(confidence)。这里研究人员选择了后者作为判别网络的输出。
判别网络的输入,最简单的情形,就是接受一张图像,可能是真实图像,也可能是生成网络伪造的图像(即生成网络的输出)。不过,具体到这个特定的问题,从原始图像生成同一人物的新姿势图像,那么,其实模型还可以给判别网络提供一些额外的信息,帮助判别网络判断图像的真假。
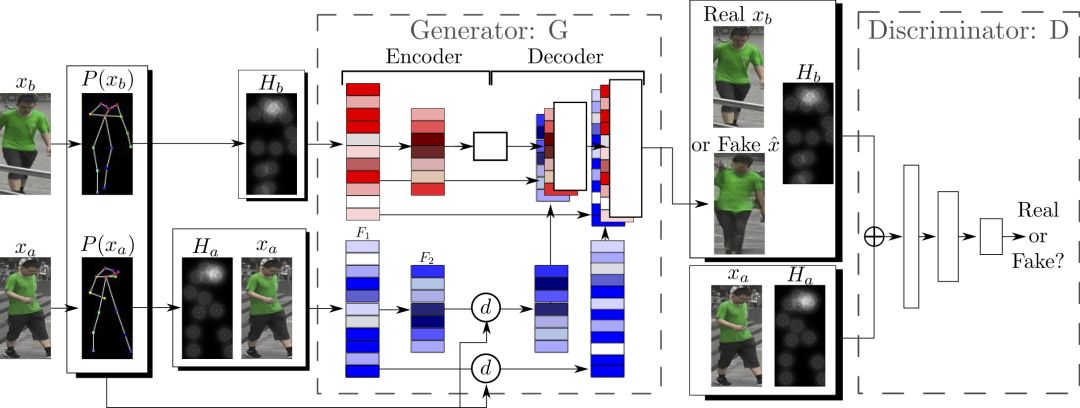
首先可以提供的是原始图像。其次,是相关的姿势信息,具体而言,包括从原始图像中提取的姿势信息,也包括目标姿势信息。因此,实际上判别网络接受的输入是4个tensor构成的元组(xa, Ha, y, Hb)。其中,xa是表示原始图像的tensor,Ha与Hb分别表示原始图像的姿势和目标姿势。y是真实图像(xb)或生成网络的输出。
如前所述,判别网络的工作相对简单,因此判别网络的输入层也就不对这4个tensor组成的元组做什么特别的处理了,直接连接(concatenate)就行了。
生成网络
如前所述,生成网络的设计需要多费一点心思。
同样,我们先考虑生成网络的输出,很简单,生成网络的输出就是图像,具体而言,是一个表示图像的tensor。
那么,生成网络的输入是什么呢?其实很简单,从判别网络的输入,我们不难得到生成网络的输入。判别网络的输入,正如我们前面提到的,是4个tensor构成的元组(xa, Ha, y, Hb)。其中,这个y正是生成网络需要生成的,所以我们去掉y,得到(xa, Ha, Hb)。这个差不多就可以作为生成网络的输入了。生成网络和判别网络两者输入上的相似性,很符合直觉。那些有助于判别图像真假的信息,同样有助于伪造虚假的图像。
不过,图像多少存在噪点,因此,为了处理数据样本的噪点问题,以更好地学习以假乱真的技术,生成网络还额外接受一个噪声向量z作为输入。因此,生成网络的输入为(z, xa, Ha, Hb)。判别网络就不操心噪点的问题,这是因为判别网络的工作要容易很多,不是吗?
判别网络的输入是直接连接的,生成网络,因为面临的任务要困难很多,因此并不直接连接xa、Ha、Hb。因为,Ha是基于xa提取的姿势信息,所以,两者之间存在着一致性,或者说,紧密的联系。而Hb是目标姿势,与xa和Ha的关系不那么紧密。因此,分开来处理比较好。研究人员正是这么做的,将xa和Ha连接起来,使用编码器的一个卷积流处理,而Hb则使用另一个卷积流处理,两者之间不共享权重。
姿势的表示
上面我们提到了Ha和Hb,也就是姿势信息,可是这些姿势信息到底是如何表示的呢?
表示姿势最简单的方法就是找出各个关节(抽象成点),然后将这些关节连起来(线),用点线组合(关节位置)来表示姿势。
从图像中提取姿势(关节位置)后,还需要转换成生成网络能够理解的形式。以往的工作发现用热图的效果不错,这里研究人员也同样使用热图来表示姿势。也就是说,如果我们用P(xa)表示从x中提取的姿势(P为pose即姿势的首字母),那么Ha= H(P(xa))(H为heat map即热图的首字母)。其中,Ha由k张热图组成,Hj(1<=j<=k)是一个维数与原始图像一致的二维矩阵。热图与关节位置满足以下关系:
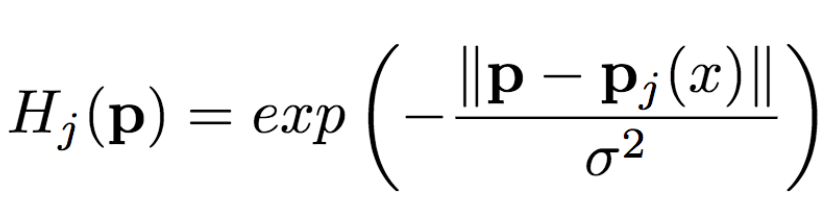
其中,pj为第j个关节位置,σ = 6像素。
整个网络架构如下图所示:
可变形跳跃连接
姿势的转变,可以看成是一个空间变形问题。常见的思路是由编码器编码相关的变形信息,然后由解码器将编码的变形信息加以还原。而由编码器和解码器组成的网络架构,常用的为U-Net。因此,以往的一些研究广泛使用基于U-Net的方法完成基于姿势的人像图片生成任务。然而,普通的U-Net跳跃连接不太适合较大的空间变形,因为在空间变形较大的情况下,输入图像和输出图像的局部信息没有对齐。
既然,较大的空间变形有局部信息不对齐的问题,那将空间变形分拆成不同的部分,这样每个部分之间就对齐了。
研究人员基于以上的想法提出了可变形跳跃连接(deformable skip connection),将全局变形分解为一组由关节的子集定义的局部仿射变换,然后再将这些局部仿射变换组合起来以逼近全局变形。
分解人体
如前所述,局部仿射变换是由关节的子集定义的。因此我们先要划分关节的子集,也就是,分解人体。研究人员将人体分解为10个部分,头、躯干、左上臂、右上臂、左前臂、右前臂、左大腿、左小腿、右大腿、右小腿。
每个部分具体区块的划分,基于关节进行。
头部和躯干的区块定义很简单,只要对齐轴线,划出包围所有关节的矩形即可。
四肢的情形比较复杂。四肢由两个关节组成,研究人员使用一个倾斜的矩形来划分四肢区块。这个矩形的一条边r1为平行于关节连线的直线,另一条边r2和r1垂直,长度等于躯干对角线均值的三分之一(统一使用此值)。这样我们就得到了一个矩形。
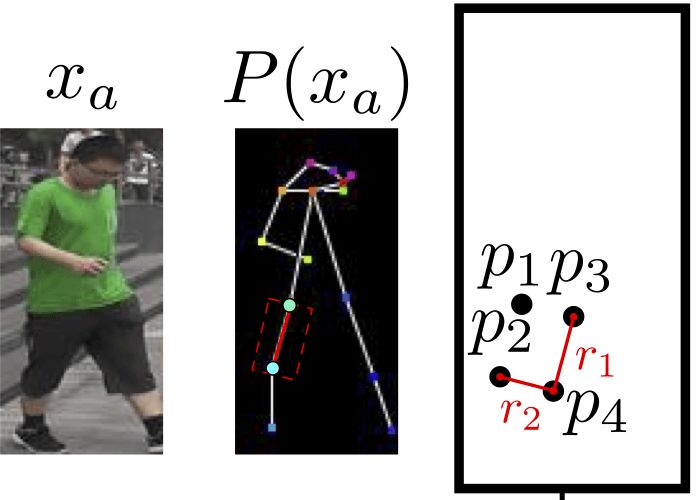
上图为一个例子。我们可以将切分的区域表示为Rha= {p1, ..., p4}。其中,R代表区域(region的首字母),h表示这是人体的第h个区域,a表示这一区域属于图像xa,p1到p4为区域矩形的四个顶点,注意,这些并非关节。
仿射变换
然后,我们可以计算Rha的二元掩膜Mh(p),除了Rha内的点之外,其余位置的值均为零。
类似地,Rhb= {q1, ..., q4}为图像xb中对应的矩形局域。匹配Rha与Rhb中的点,可以计算出这一部分的仿射变换fh的6个参数kh:
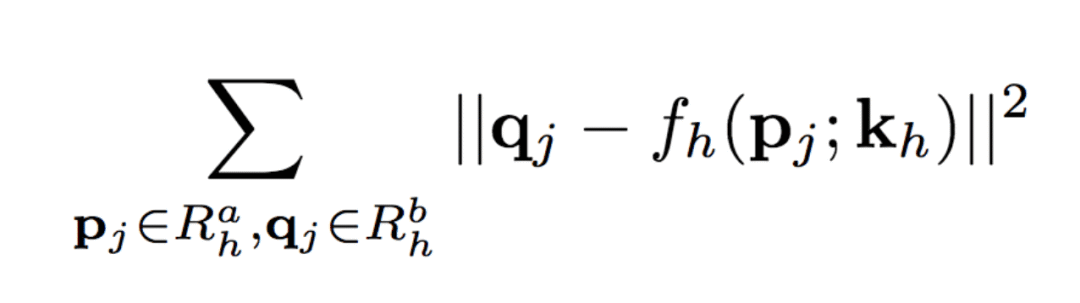
以上的仿射变换的参数向量kh基于原始图像的分辨率计算,然后根据不同卷积特征映射的特定分辨率分别计算相应的版本。类似地,可以计算每个二元掩膜Mh的不同分辨率的版本。
实际图像中,相应的区域可能被其他部分遮蔽,或者位于图像边框之外,或者未被成功检测到。对于这种情况,研究人员直接将Mh设定为所有元素值为0的矩阵,不计算fh。(其实,当缺失的区域为四肢时,如果对称的身体部分未缺失,例如右上臂缺失,而左上臂被成功检测到,那么可以拷贝对称部分的信息。)
对于数据集中的每对真实图像(xa, xb),(fh(), Mh)及其分辨率较低的变体只需计算一次。
另外,这也是整个模型中唯一与人体相关的部分,因此,整个模型可以很容易地扩展,用于解决其他可变形物体的生成任务。
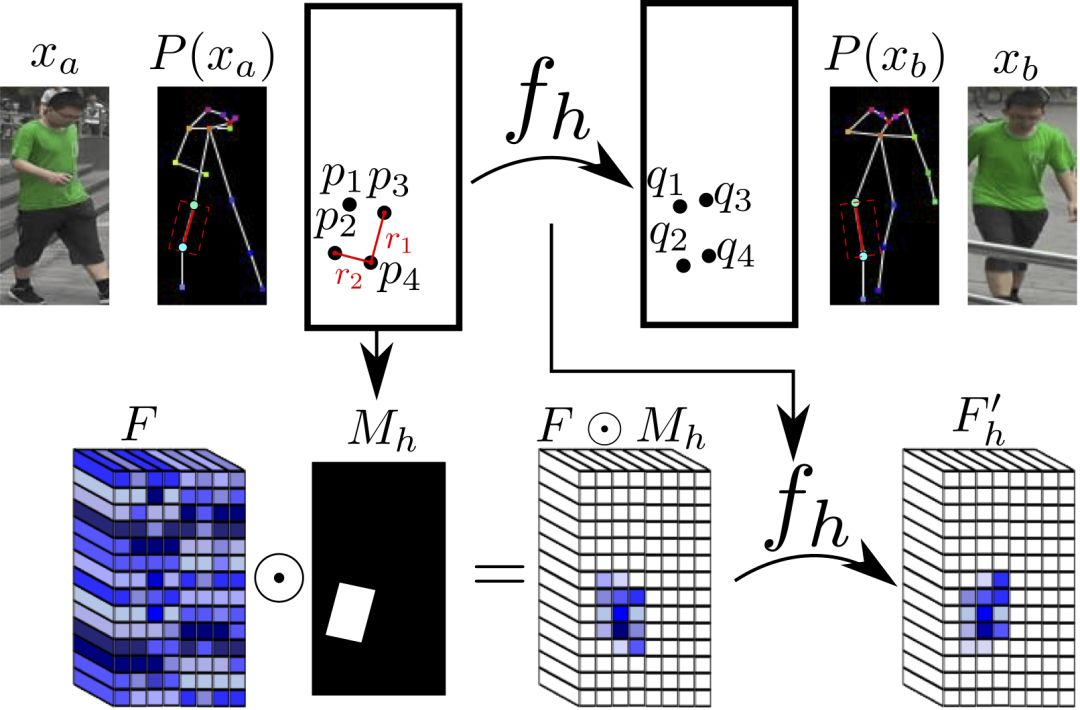
仿射变换示意图
组合仿射变换
一旦计算出人体各个区域的(fh(), Mh)后,这些局部的仿射变换可以组合起来逼近全局姿势变形。
具体而言,研究人员首先基于每个区域计算:
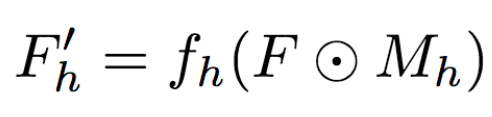
然后,研究人员将其组合:
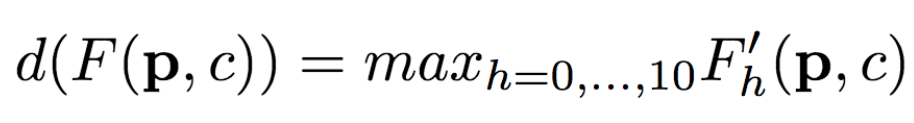
其中,F'0= F(未变形),可以提供背景点的纹理信息。这里,研究人员选用了最大激活,研究人员还试验了平均池化,平均池化的效果要稍微差一点。
最近邻损失
训练生成网络和判别网络时,除了标准的条件对抗损失函数LcGAN外,研究人员还使用了最近邻损失LNN。
LcGAN的具体定义为:
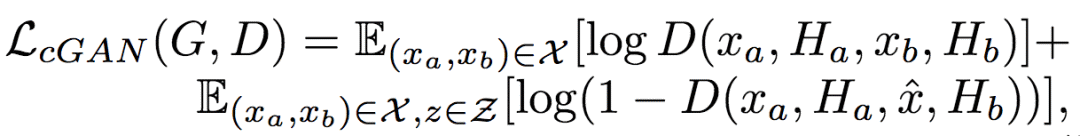
其中,带帽子的x为生成网络的生成图像G(z, xa, Ha, Hb)。
在标准的LcGAN之外,之前的一些研究配合使用基于L1或L2的损失函数。比如,L1计算生成图像和真实图像之间像素到像素的差别:
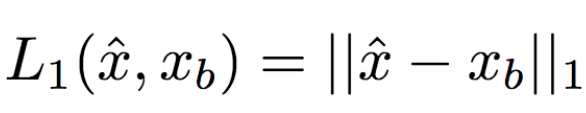
然而,L1和L2会导致生成模糊的图像。研究人员猜想,其原因可能是这两类损失函数无法容纳生成图像和真实图像间细小的空间不对齐。比如,假定生成网络生成的图像看起来很可信,在语义上也与真实图像相似,但是两张图片服饰上的纹理细节的像素没有对齐。L1和L2都会惩罚这样不精确的像素级别的对齐,尽管在人类看来,这些并不重要。为了缓和这一问题,研究人员提出了新的最近邻LNN:

其中,N(p)是点p的n x n局部近邻。g(x(p))是点p附近的补丁的向量表示,g(x(p))由卷积过滤器得出。研究人员通过比较生成图像和真实图像之间的补丁表示(g()),以便高效地计算LNN。具体而言,研究人员选用了在ImageNet上训练过的VGG-19的第二个卷积层(conv12)。VGG-19的头两个卷积层(conv11和conv12)的卷积跨距均为1,因此,图像x在conv12中的特征映射Cx和原始图像x具备相同的分辨率。利用这一事实,研究人员得以在conv1_2上直接计算最近邻,这不会损害空间准确度,即g(x(p)) = Cx(p)。据此,LNN的定义变为:
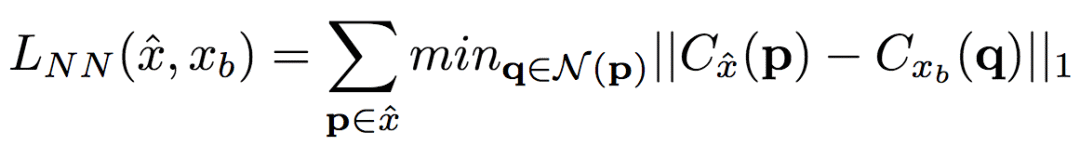
研究人员最终优化了以上LNN的实现,使其得以在GPU上并行运算。
因此,最终的基于LNN的损失函数定义为:
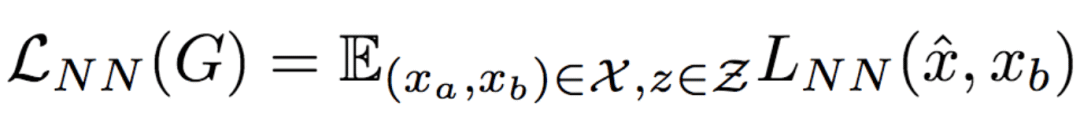
将上式与LcGAN结合,得到目标函数:
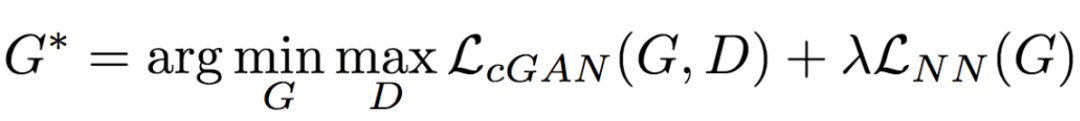
研究人员将上式中的λ的值设定为0.01,λ起到了正则化因子的作用。
实现细节
训练生成网络和判别网络时,研究人员使用了9万次迭代,并使用了Adam优化(学习率:2x10-4,β1= 0.5, β2= 0.999)。
如前所述,生成网络的编码器部分包含两个流,每个流由以下层的序列组成:
CN641- CN1282- CN2562- CN5122- CN5122- CN5122
其中,CN641表示使用实例归一化、ReLU激活、64个过滤器、跨距为1的卷积层,后同。
相应的生成网络的解码器部分由以下序列组成:
CD5122- CD5122- CD5122- CN5122- CN1282- CN31
其中,CD5122与CN5122类似,只不过额外附加了50%的dropout。另外,最后一个卷积层没有应用实例归一化,同时使用tanh而不是ReLU作为激活函数。
判别网络使用如下序列:
CN642- CN1282- CN2562- CN5122- CN12
其中,最后一个卷积层没有应用实例归一化,同时使用sigmoid而不是ReLU作为激活函数。
用于DeepFashion数据集(研究人员使用的其中一个数据集,详见下节)的生成网络的编码器和解码器使用了一个额外的卷积层(CN5122),因为数据集中的图像有更高的分辨率。
试验
数据集
研究人员使用了两个数据集:
Market-1501
DeepFashion
Market-1501包含使用6个监控摄像头拍摄的1501人的32668张图像。由于图像的低分辨率(128x64),及姿势、光照、背景和视角的多样性,这一数据集很具挑战性。研究人员首先剔除了未检测到人体的图像,得到了263631对训练图像(一对图像为同一人的不同姿势图像)。研究人员随机选择了12000对图像作为测试集。
DeepFashion包含52712张服饰图像,其中有200000对相同服饰、不同姿势或尺码的图像。图像的分辨率为256x256。研究人员选择了同一人穿戴相同服饰但姿势不同的图像对,其中,随机选择1000种服饰作为测试集,剩余12029种服饰作为训练集。去除未检测到人体的图像后,研究人员最终收集了101268对图像作为训练集,8670对图像作为测试集。
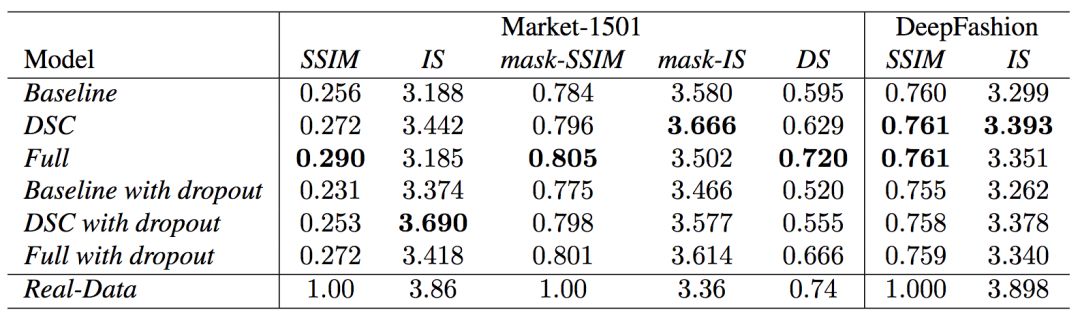
定量评估
定量评估生成内容本身是一个正在研究中的问题。目前的研究文献中出现了两种衡量标准:SSIM(Structural Similarity,结构化相似性)和IS(Inception Score)。
然而,姿势生成任务中只有一个物体分类(人类),IS指标却基于外部分类器的分类神经元计算所得的熵值,因此两者不是十分契合。实际上,研究人员发现IS值与生成图像的质量间的相关性常常比较弱。因此,研究人员提出了一个额外的DS(Detection Score,检测分数)指标。DS基于最先进的物体检测模型SSD的检测输出,SSD基于Pascal VOC 07数据集进行训练。这意味着,DS衡量生成图像的真实性(有多像人)。

上为当前最先进模型,中为研究人员使用的模型,下为真实图像
可以看到,总体而言,模型的表现超过了当前最先进的模型。另外,注意真实图像的DS值不为1,这是因为SSD不能100%检测出人体。
定性评估
研究人员同样进行了定性评估。

可以很明显地看出,由于采用了基于LNN的损失函数,模型显著减少了生成图像的模糊程度。
DeepFashion上的定性评估结果类似。
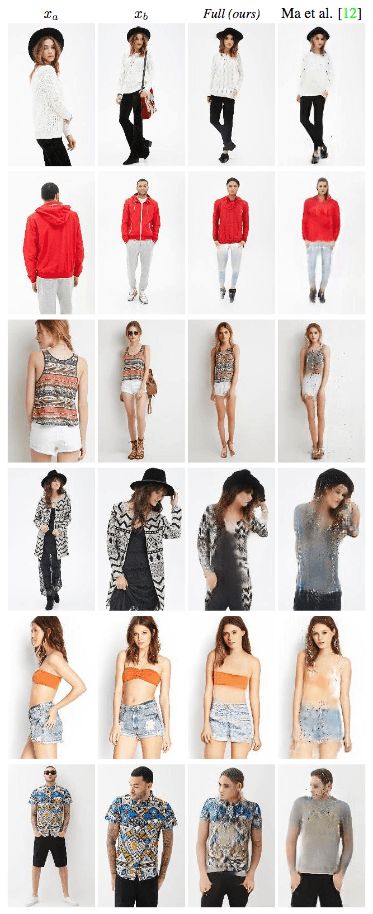
消融测试
为了验证模型的有效性,研究人员还进行了定性和定量的消融测试。

Market-1501
上图为在Market-1501数据集上进行的定性消融测试。第1、2、3列表示模型的输入。第4列为真实图像。第5列为基准输出(不使用可变形跳跃连接的U-Net架构,另外,生成网络中,xa、Ha、Hb直接连接作为输入,也就是说生成网络的编码器只包含一个流,训练网络时使用基于L1的损失函数),第6列DSC为使用基于L1的损失函数训练的模型,第7列Full为完整的模型。
可以看到,研究人员提出的模型生成的图像看起来更真实,也保留了更多的纹理细节。
研究人员在DeepFashion上取得了相似的结果。

研究人员也进行了定量的消融测试,并额外试验了加上dropout(生成网络和判别网络同时应用dropout)的效果。
-
GaN
+关注
关注
19文章
1933浏览量
73278 -
网络架构
+关注
关注
1文章
93浏览量
12581 -
深度学习
+关注
关注
73文章
5500浏览量
121109
原文标题:特伦托大学、Inria合作研究:基于GAN生成人体的新姿势图像
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于扩散模型的图像生成过程

图像生成对抗生成网络gan_GAN生成汽车图像 精选资料推荐
探讨条件GAN在图像生成中的应用
FAIR和INRIA的合作提出人体姿势估计新模型,适用于人体3D表面构建
图像迁移最新成果:人体姿势和舞蹈动作迁移
基于DensePose的姿势转换系统,仅根据一张输入图像和目标姿势
GAN在图像生成应用综述

必读!生成对抗网络GAN论文TOP 10
生成对抗网络GAN论文TOP 10,帮助你理解最先进技术的基础





 工商网监
工商网监
评论