 Mask R-CNN:自动从视频中制作目标物体的GIF动图
Mask R-CNN:自动从视频中制作目标物体的GIF动图
在上一篇文章中,我们介绍了用深度学习结合摄像机的方法自动检测并拍摄小鸟的照片。今天,我们用另一种新颖的深度学习模型——Mask R-CNN,自动从视频中制作目标物体的GIF动图。
Mask R-CNN已经有很多应用了,论智君此前还介绍过Facebook利用这一模型实现全身AR的项目。不过在这个项目中,作者Kirk Kaiser使用的是MatterPort版本。它支持Python 3,拥有超棒的样本代码,也许是最容易安装的版本了。
第一步,输入正确的内容
在开始制作gif自动生成器时,我选择先做一件最蠢的事,这种模式在有创意性编码项目中表现得很好。
首先,输入的视频中只能含有一个人,不要尝试跟踪监测视频中的多个人。这样我们就可以将目标物体与其他对象隔离开,同时更容易评估模型掩盖目标对象的程度如何。如果目标对象不见了,我们就能发现,同时还能看到模型识别边框的噪声。
我选用的是自己在后院拍摄的视频。
用Python处理视频
尽管用Python处理视频有其他方法,但我更喜欢将视频转换为图像序列,然后再使用ffmpeg将其转换回来。
使用以下命令,我们就能从输入的视频中获取一系列图像。根据输入的视频来源,它可能在每秒24到60帧之间。你需要跟踪每秒输入的视频帧数,以便在转换后保持同步。
$ ffmpeg -i FILENAME.mp4 -qscale:v 2 %05d.jpg
这将创建一个5位、0填充的图像序列,如果您输入的视频长度超过5位,则可以将%05d改成%09d。
数字序列将与视频持续的时间一样长(以秒为单位),乘以每秒的帧数。所以一个时长为三秒、每秒24帧的视频,将有72帧。
由此,我们得到了一系列静止的图像,可以使用我们的静态掩码R-CNN代码输入。
完成了对图像的处理后,稍后将使用以下命令把它们重新放回视频中:
$ ffmpeg -r 60 -f image2 -i %05d.jpg OUTPUT.mp4
参数-r规定了每秒中我们需要使用构建输出视频的帧数。如果我们想放慢视频,可以降低参数的值,如果想加快速度,可以增加参数的值。
按照顺序,让我们先用Mask R-CNN来检测并处理图像。
检测并标记图像
Matterport版的Mask R-CNN附带了Jupyter Notebook,帮助深入了解Mask R-CNN的工作原理。
一旦你在本地设置好了repo,我建议在demo笔记本上运行,并评估图像检测工作的水平。
通常掩码是无符号的8位整数,形状与输入的图像一致。当没有检测到目标对象时,掩码是0或者黑色。当检测到对象时,掩码是255或白色。
为了处理蒙版,我们需要把它作为一个通道,复制或粘贴另一张图像。用类似下面的代码,可以从每个视频的图像中将单个人物抠出来,生成一张透明底的图像:
import numpy as np
import os
import coco
import model as modellib
import glob
import imageio
import cv2
# Root directory to project
ROOT_DIR = os.getcwd()
# Directory to save logs and trained model
MODEL_DIR = os.path.join(ROOT_DIR, "logs")
# Path to trained weights file
# Download this file and place in the root of your
# project (See README file for details)
COCO_MODEL_PATH = os.path.join(ROOT_DIR, "mask_rcnn_coco.h5")
classInferenceConfig(coco.CocoConfig):
# Set batch size to 1 since we'll be running inference on
# one image at a time. Batch size = GPU_COUNT * IMAGES_PER_GPU
GPU_COUNT = 1
IMAGES_PER_GPU = 1
config = InferenceConfig()
# Create model object in inference mode.
model = modellib.MaskRCNN(mode="inference", model_dir=MODEL_DIR, config=config)
# Load weights trained on MS-COCO
model.load_weights(COCO_MODEL_PATH, by_name=True)
class_names = ['BG', 'person', 'bicycle', 'car', 'motorcycle', 'airplane',
'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird',
'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear',
'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie',
'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball',
'kite', 'baseball bat', 'baseball glove', 'skateboard',
'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup',
'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza',
'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed',
'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote',
'keyboard', 'cell phone', 'microwave', 'oven', 'toaster',
'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors',
'teddy bear', 'hair drier', 'toothbrush']
numFiles = len(glob.glob('extractGif/*.jpg'))
counter = 0
for i in range(1, numFiles):
filename = 'extractGif/%05d.jpg' % i
print("doing frame %s" % filename)
frame = cv2.imread(filename)
results = model.detect([frame], verbose=0)
r = results[0]
masky = np.zeros((frame.shape[0], frame.shape[1]), dtype='uint8')
humans = []
if r['rois'].shape[0] >= 1:
for b in range(r['rois'].shape[0]):
if r['class_ids'][b] == class_names.index('person'):
masky += r['masks'][:,:,b] * 255
humansM = r['masks'][:,:,b] * 255
y1, x1, y2, x2 = r['rois'][b]
humansCut = frame[y1:y2, x1:x2]
humansCut = cv2.cvtColor(humansCut.astype(np.uint8), cv2.COLOR_BGR2RGBA)
humansCut[:,:,3] = humansM[y1:y2, x1:x2]
humans.append(humansCut)
if len(humans) >= 1:
counter += 1
for j, human in enumerate(humans):
fileout = 'giffer%i/%05d.png' % (j, counter)
ifnot os.path.exists('giffer%i' % j):
os.makedirs('giffer%i' % j)
print(fileout)
#frame = cv2.cvtColor(frame.astype('uint8'), cv2.COLOR_BGRA2BGR)
imageio.imwrite(fileout, human)
其中的class_names变量非常重要,它表示我们用COCO数据集分出的不同事物的类别。然后只需要把列表中的任意类别的名字更换成if r[class_ids][b] == class_names.index(‘person’),你就可以从视频中获取带有蒙版的版本了。
把图片转换成GIF
现在我们有了一组透明图像,可以打开看看它们的效果。我的结果并不是很好,人物抠的不是很精致,不过也挺有趣的。
然后我们就可以将图像输入进ffmpeg中制作动图了,只需要找到图像序列的最大宽度(width)和高度(height),然后将其粘贴到一个新的图像序列中:
import glob
from PIL importImage
maxW = 0
maxH = 0
DIRECTORY = 'wave-input'
numFiles = len(glob.glob(DIRECTORY + '/*.png'))
for num in range(numFiles - 1):
im = Image.open(DIRECTORY + '/%05d.png' % (num + 1))
if im.width > maxW:
maxW = im.width
if im.height > maxH:
maxH = im.height
for num in range(numFiles - 1):
each_image = Image.new("RGBA", (maxW, maxH))
im = Image.open(DIRECTORY + '/%05d.png' % (num + 1))
each_image.paste(im, (0,0))
each_image.save('gifready/%05d.png' % num)
上面的代码打开了我们的giffer0这个目录,并在所有图像中迭代,寻找最大尺寸图像的width和height。然后它将这些图像都放到一个新目录(gifready)中,我们就能将其生成gif。
在这里,我们利用Imagemagick生成gif:
$ convert -dispose Background *.png outty.gif
但是仅仅从视频中自动生成动图也没什么好激动的,让我们继续把它们混合起来,看看会发生什么……
在Pygame或视频中应用生成的GIFs
最近,我直接将这些提取的图像用在了Pygame中。我并没有将它们转换成gifs,而是保留了原始PNG格式。
我自创了一个创意性小编程环境,其中包括一个setup和draw功能,将图像序列作为输入。使用这个设置,我可以将图像旋转、缩放或干扰它们。以下是代码:
import pygame
import random
import time
import math
import os
import glob
imageseq = []
def setup(screen, etc):
global imageseq
numIn = len(glob.glob('wave-input/*.png'))
for i in range(numIn):
if os.path.exists('wave-input/%05d.png' % (i + 1)):
imagey = pygame.image.load('wave-input/%05d.png' % (i + 1)).convert_alpha()
imageseq.append(imagey)
counter = 1
def draw(screen, etc):
# our current animation loop frame
global counter
current0 = imageseq[counter % len(imageseq)]
counter += 1
for i in range(0, 1920, 200):
screen.blit(current0, (i, 1080 // 2 - 230))
它将每个目录中的图像加载到一个alphapygame.surface中。其中的每一个都被添加到列表中,然后我们可以在循环中blit或将每张图片画到屏幕上。
这只是基本设置,更高级的操作请看上面的代码,或者到我的GitHub中查看其他有趣的实验。
用提取的Mask修改输入视频
为了产生上图的效果,我记录了视频的前n帧,以及人物(person)和滑板(skateboard)的位置。
然后我将把之前抠出来的图一个一个叠好,最后粘贴最后一张图像。
除此之外我还试着将我的蒙版和其他视频混合起来。这里就是合成的一个案例:
同时调试环境和滑板者的每一帧,然后在环境上盖上蒙版,覆盖在滑板视频的顶部。这个代码也可以在我的GitHub里找到。
结语
想将深度学习与艺术结合,这种项目只是一个开始。另外还有一个名为OpenPose的模型,能够预测一个人的动作,并且模型十分稳定。我计划将OpenPose合并到未来的项目中,创建更有趣的作品。
-
视频
+关注
关注
6文章
1942浏览量
72883 -
python
+关注
关注
56文章
4792浏览量
84624 -
深度学习
+关注
关注
73文章
5500浏览量
121109
原文标题:用Mask R-CNN自动创建动图
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
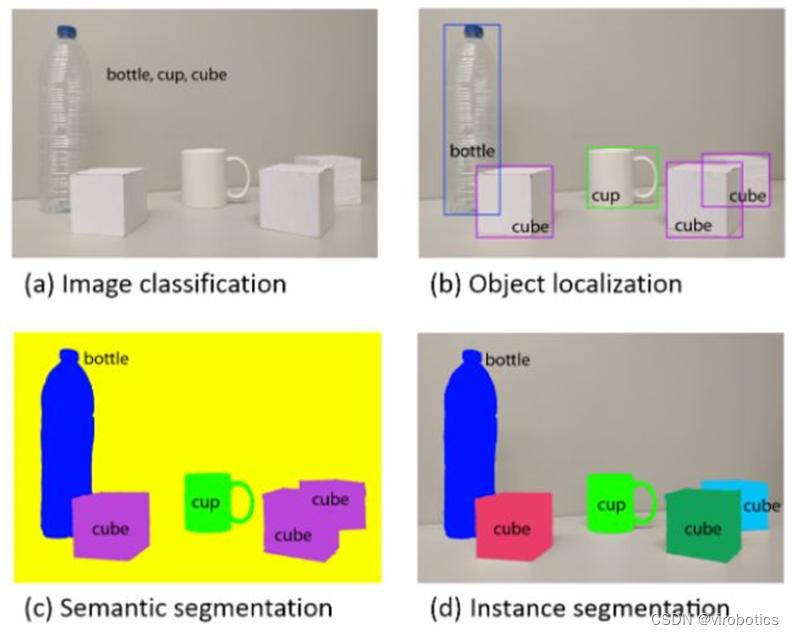
深度卷积神经网络在目标检测中的进展
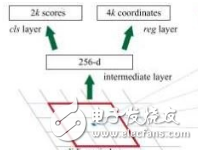
介绍目标检测工具Faster R-CNN,包括它的构造及实现原理

什么是Mask R-CNN?Mask R-CNN的工作原理
引入Mask R-CNN思想通过语义分割进行任意形状文本检测与识别
手把手教你操作Faster R-CNN和Mask R-CNN
一种新的带有不确定性的边界框回归损失,可用于学习更准确的目标定位

基于MASK模型的视频问答机制设计方案

基于改进Faster R-CNN的目标检测方法
用MATLAB制作GIF格式动图资料下载

一种基于Mask R-CNN的人脸检测及分割方法

基于Mask R-CNN的遥感图像处理技术综述
用于实例分割的Mask R-CNN框架
PyTorch教程14.8之基于区域的CNN(R-CNN)
PyTorch教程-14.8。基于区域的 CNN (R-CNN)






 工商网监
工商网监
评论