 医院SQL数据库系统语句优化
医院SQL数据库系统语句优化
本文就如何优化大型数据库的性能进行了一些探索,提出了优化数据库访问性能的若干策略,特别是对SQL语句进行了有效的分析设计的问题,以使其加快执行速度,减少网络传输,能更高效地工作,充分发挥系统的效率。
随着医院信息系统模块的不断增加,特别是近两年电子病历的使用,临床诊疗信息大量写入数据库,数据量急剧增加,造成业务数据库非常庞大,业务处理的速度明显下降。基于这一问题,本文就如何优化大型数据库的性能进行了一些探索,提出了优化数据库访问性能的若干策略,特别是对SQL语句进行了有效的分析设计的问题,以使其加快执行速度,减少网络传输,能更高效地工作,充分发挥系统的效率。
医院经过多年的信息化建设,取得了显著成效,信息化由原来的以收费、记帐为主,逐步向临床医疗、服务病人过渡。随着医院信息系统模块的不断增加,特别是近两年电子病历的使用,临床诊疗信息大量写入数据库,数据量急剧增加,造成业务数据库非常庞大,业务处理的速度明显下降。加之在频繁的业务数据库中还要进行大数据量查询或报表统计,导致在业务处理时经常出现阻塞或死锁现象,严重影响到日常的工作。故如何对数据库性能在进行优化设计,即提高数据库的吞吐量、减少用户等待时间具有重大意义。
传统的数据库性能优化主要从操作系统、客户端应用软件程序设计、网络及其它硬件设备等方面来考虑,这种方法只是调整数据库的周边环境,只能暂时缓解问题,而不能从根本上解决问题。实际应用中,更多情况是医院信息系统(包括数据库系统)都已设计好,只是在运行的过程中随着数据规模的增大,使得系统出现周期性性能问题。本文提出的医院数据库系统性能优化是在己有的硬件设施升级、数据库的物理设计、关系规范化等方面进行改进基础之上,对SQL语句进行了有效的分析设计的问题,以使其加快执行速度,减少网络传输,能更高效地工作,充分发挥系统的效率。
1 合理使用索引
提高数据库查询速度最有效的方法就是优化索引。索引是建立在实体表上的一种数据组织,它可以提高访问表中一条或多条记录的查询效率,使用索引的目的是为了避免全表扫描,减少磁盘I/O的次数,加快查询速度,在大型的表中进行索引的建立对加快表的查询有着重要的意义。但是也并不对任何的数据表都要建立索引,索引通常能提高select、update以及delete语句的性能(当访问的行较少时),但会降低insert语句的性能(因为需要同时对表和索引进行插入)。此外,过多的索引会产生维护上的开销,只会降低而不是增加系统的性能,索引的使用要恰到好处。索引使用原则如下:
(1)在经常进行连接,但是没有指定为外键的列上建立索引,而不经常连接的字段则由优化器自动生成索引。
(2)在频繁进行排序或分组(即进行group by或order by操作)的列上建立索引,而频繁进行删除、插入操作的表不要建立过多的索引。
(3)在条件表达式中经常用到的不同值较多的列上建立检索,在不同值少的列上不要建立索引。比如在雇员表的“性别”列上只有“男”与“女”两个不同值,因此就没有必要建立索引,如果在此建立索引不但不会提高查询效率,反而会严重降低更新速度。
(4)如果待排序的列有多个,可以在这些列上建立复合索引(compound index)。尽量使用较窄的索引, 这样数据页每页上能因存放较多的索引行而减少操作。
(5)在查询中经常作为条件表达式并且不同值较多的列上建立索引,而不同值较少的列上不要建立索引。
(6)当数据库表更新大数据后, 删除并重新建立索引来提高查询速度。
总之,建立索引一定要慎重,对每个索引建立的必要性都要仔细分析,一定要有建立的依据。过多的索引或不充分、不正确的索引对提升数据库的性能毫无益处。
2 SQL语句优化
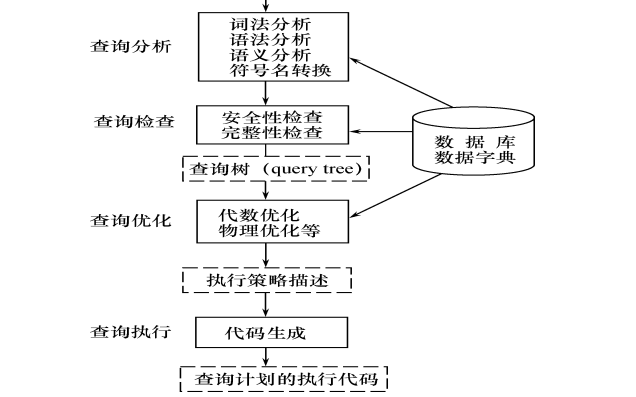
SQL语言是一种非常灵活的语言,相同功能的实现常可以用几种不同的语句来表达,但语句的执行效率可能存在很的差别。因此,任何一个数据库应用系统中,合理的对SQL语句进行优化将大大的提高整个数据库系统的性能。所有的SQL语句执行过程分三个阶段,分别是进行处理语法分析、执行、读取数据。
图1 SQL语句执行过程
在使用SQL时,性能差异在大型的或是复杂的数据库环境中,如在HIS的一些大型表中表现尤为明显。经过一段时间的总结,发现SQL语句比较低下的原因主要来自于不恰当的索引设计、不充分的连接条件和不可优化的WHERE子句及其它不恰当的语句操作等,在对它们进行适当的优化后,其运行速度有了明显提高。下面将从这几个方面分别进行说明:
2.1 LIKE操作符
LIKE操作符可以应用通配符查询,里面的通配符组合可能达到几乎是任意的查询,但是如果用得不好则会产生性能上的问题,如like 'a%' 使用索引,like ‘%a’ 不使用索引。用 like ‘%a%’ 查询时,查询耗时和字段值总长度成正比,所以不能用CHAR类型,而是VARCHAR。
2.2 限制返回行
在查询Select语句中用Where字句限制返回的行数,避免表扫描,如果返回不必要的数据,浪费了服务器的I/O资源,加重了网络的负担降低性能。如果表很大,在表扫描的期间将表锁住,禁止其他的联接访问表,后果严重。可以使用TOP语句来限制返回结果。当返回多行数据时,尽可能不使用光标,因为它占用大量的资源,应该使用datastore。
2.3 UNION操作符
UNION在进行表链接后会筛选掉重复的记录,所以在表链接后会对所产生的结果集进行排序运算,删除重复的记录再返回结果。实际大部分应用中是不会产生重复的记录,最常见的是过程表与历史表UNION。推荐采用UNION ALL操作符替代UNION,因为UNION ALL操作只是简单的将两个结果合并后就返回。
2.4 Between与IN
Between在某些时候比IN速度更快,Between能够更快地根据索引找到范围。如:
select * from YF_KCMX where YPXH in (12,13)
Select * from YF_KCMX where between 12 and 13
一般在GROUP BY 个HAVING字句之前就能剔除多余的行,所以尽量不要用它们来做剔除行的工作。他们的执行顺序应该如下最优:select 的Where字句选择所有合适的行,Group By用来分组个统计行,Having字句用来剔除多余的分组。这样Group By 个Having的开销小,查询快。对于大的数据行进行分组和Having十分消耗资源。如果Group BY的目的不包括计算,只是分组,那么用Distinct更快。
2.5 注意细节
一般不要用如下的字句: “<>”, “!=”, “!>”, “!<”, “NOT”, “NOT EXISTS”, “NOT IN”, “NOT LIKE”, and “LIKE ‘%500’”,因为他们不走索引全是表扫描。NOT IN会多次扫描表,使用EXISTS、NOT EXISTS ,IN , LEFT OUTER JOIN 来替代,特别是左连接,而Exists比IN更快,最慢的是NOT操作.如果列的值含有空,以前它的索引不起作用, “<>”, “!=”, “!>”,等还是不能优化,用不到索引。
不要在WHere字句中的列名加函数,如Convert,substring等,如果必须用函数的时候,创建计算列再创建索引来替代。还可以变通写法:
WHERE SUBSTRING(firstname,1,1) = ‘m’
改为:WHERE firstname like ‘m%’(索引扫描),但MIN() 和 MAX()能使用到合适的索引。
select * form ZY_FYMX where FYDJ > 3000
分析在此语句中若FYDJ是Float类型的,则优化器对其进行优化为Convert(float,3000),因为3000是个整数,我们应在编程时使用3000.0而不要等运行时让DBMS进行转化。同样字符和整型数据的转换。应改为:
select * form ZY_FYMX where FYDJ > 3000.00
2.6 避免相关子查询
一个列的标签同时在主查询和where子句中的查询中出现,那么很可能当主查询中的列值改变之后,子查询必须重新查询一次。查询嵌套层次越多,效率越低,因此应当尽量避免子查询。如果子查询不可避免,那么要在子查询中过滤掉尽可能多的行。
-
数据库
+关注
关注
7文章
3794浏览量
64351 -
索引
+关注
关注
0文章
59浏览量
10468
发布评论请先 登录
相关推荐
数据库SQL的优化
请教如何用SQL语句来压缩ACCESS数据库
请问labview如何通过语句连接sql sever数据库?
DCS组态软件实时数据库系统的设计
数据库系统概论之如何进行数据库编程的资料概述
数据库系统概论之如何进行关系查询处理和查询优化





 工商网监
工商网监
评论