 全流程演示:如何从0到1构建分布式GPU计算环境
全流程演示:如何从0到1构建分布式GPU计算环境
随着AI、大模型的快速发展,传统的集中式计算已无法应对激增的数据处理需求,而分布式计算是指将一个计算任务分解成多个子任务,由多个计算节点并行地进行计算,并将结果汇总得到最终结果的计算方式,能够更高效、更稳定、更灵活地处理大规模数据和复杂计算任务,在各行各业中得到了广泛的应用。
那如何从零到一搭建分布式计算的环境呢?本文将从硬件选型,到服务器侧的基础配置、GPU驱动安装和集合通讯库配置,以及无损以太网的启用,直至大模型导入和训练测试,带您跑通搭建分布式计算环境的全流程。
硬件准备
GPU服务器选型
GPU拥有大量的计算核心,可以同时处理多个数据任务,是构成智算中心的关键硬件。
从智算中心方案的整体设计层面来看:GPU服务器集群和存储服务器集群分别通过计算网络(Scale-out网络)和存储网络连接。另外两张管理网中,业务管理网用于GPU服务器互联,进行AIOS管理面通信,带外管理则连接整个智算中心的所有设备,用于运维接入管理。
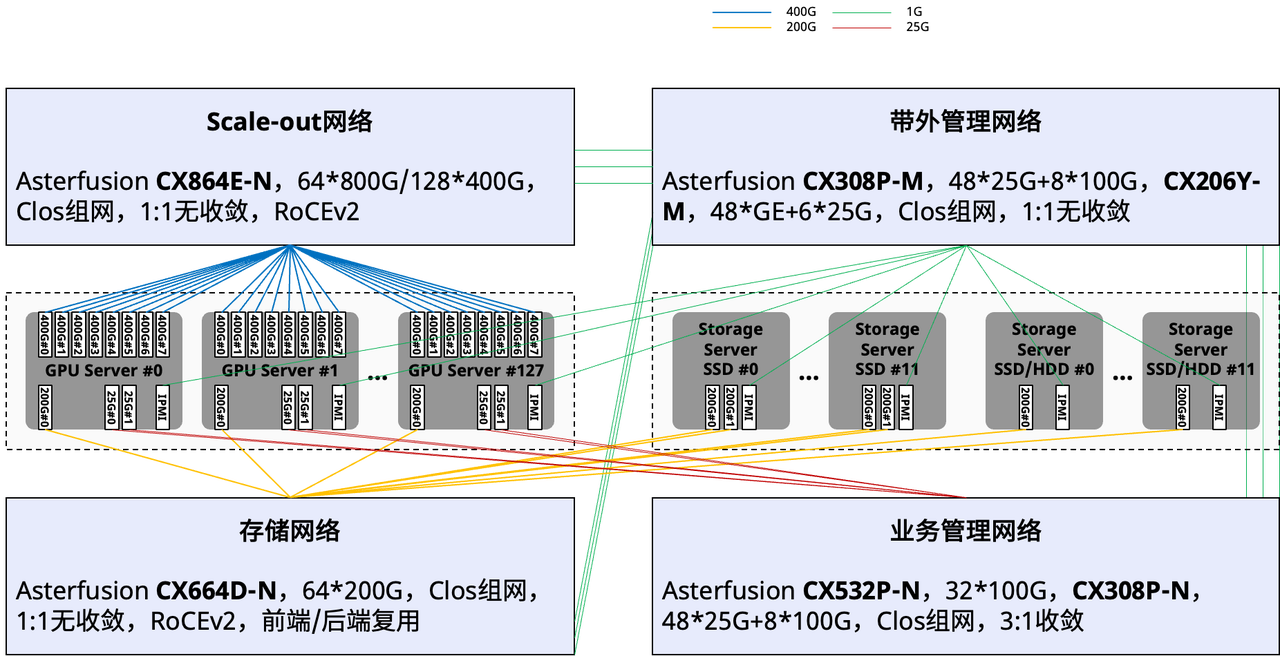 图1:智算中心方案的概要设计拓扑
图1:智算中心方案的概要设计拓扑明确了智算中心的整体设计后,我们将对比通用计算服务器与GPU服务器的内部硬件连接拓扑图,来具体了解GPU服务器的选型逻辑:
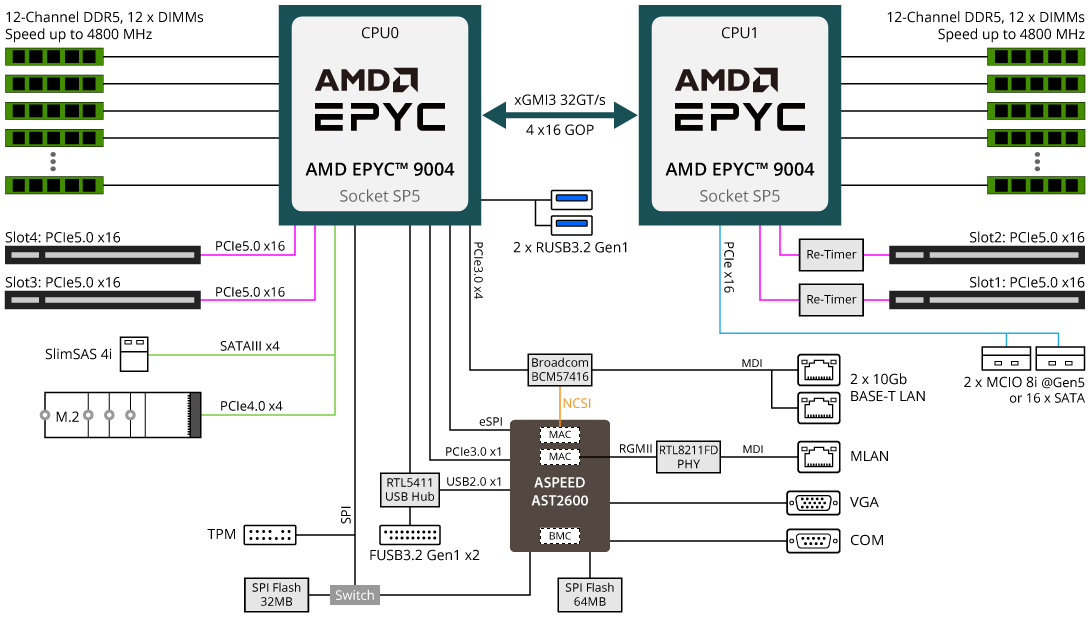 图2:通用计算服务器内部的硬件连接拓扑
图2:通用计算服务器内部的硬件连接拓扑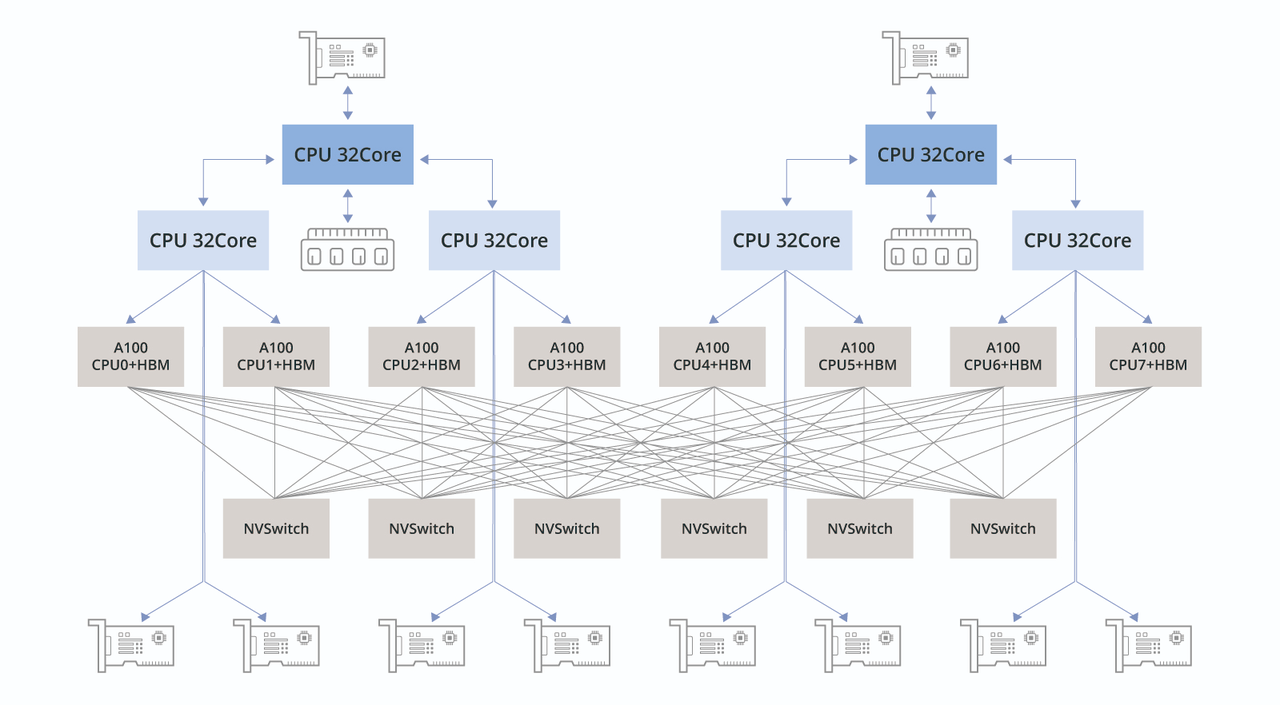 图3:GPU服务器内部的硬件连接拓扑
图3:GPU服务器内部的硬件连接拓扑
图2是一台通用计算服务器内部的硬件连接拓扑,这台服务器的核心是两块AMD的EPYC CPU,根据IO Chiplet扩展出了若干接口,辅助CPU充分释放通用计算能力。
图3是一台GPU服务器内部的硬件连接拓扑,这台服务器配备了8块A100 GPU,8张用于计算通信的RDMA网卡,以及2张用于存储通信的RDMA网卡,所有的IO组件设计,都是为了让这8块GPU充分释放算力。
通过上面两张硬件连接拓扑图可以看到,通用服务器和GPU服务器从基本的硬件构造上就有着非常大的差异,一个是围绕通用CPU来构建,另一个是围绕着GPU来构建的。因此,在硬件选型阶段,就需要注意差别,通常来讲通用服务器是没有办法复用改造成一台高性能的GPU服务器,PCIe接口数量、服务器空间、散热设计、电源等方面都不能满足要求。
当通过计算任务确定算力需求,进而确定了所需要的GPU型号和数量之后,我们也就可以再继续规划整个GPU集群的组网了。
由于资源限制,本次实验验证中,使用三台通用服务器稍加改造进行后续的并行训练和推理测试。
计算节点的硬件配置如下:
CPU:Intel(R) Xeon(R) CPU E5-2678 v3 @ 2.50GHz * 2
GPU:NVIDIA GeForce RTX 4060 Ti 16G * 1
内存:128G
存储:10T HDD * 2
网卡:MGMT、CX5
其他部分:
散热:GPU为全高尺寸,但服务器只有2U,所以只能拆掉上盖板;
电源:通用服务器通常没有预留足够的供电接口,因此需要使用外置电源对GPU进行额外供电;
电源选择的是Great Wall 额定650W X6,功率上可以同时满足3块GPU(RTX4060Ti需要外接150W的供电)的供电要求,并且支持3个8pin接口,用来分别连接三块GPU。
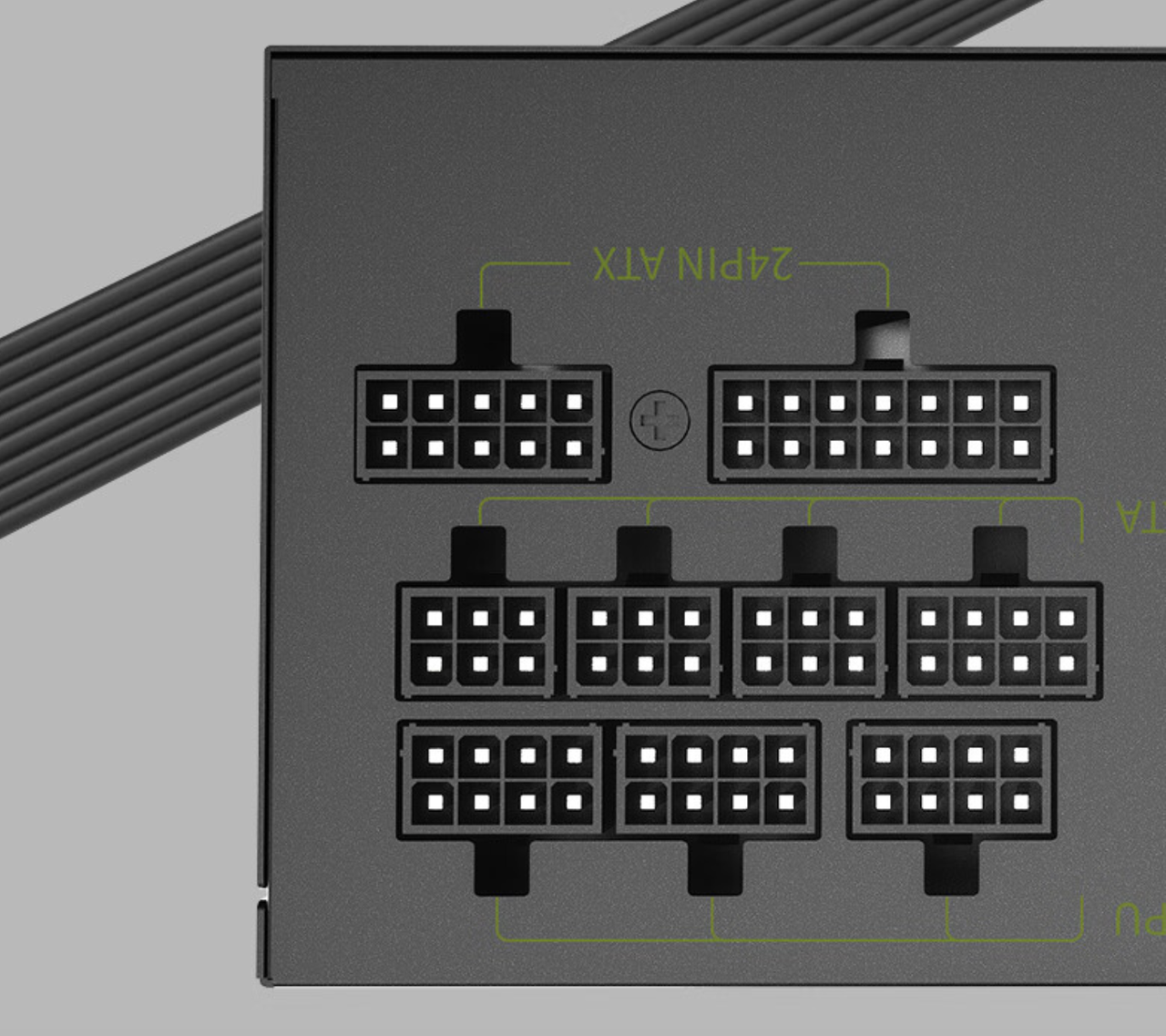 图4:电源选型示意图
图4:电源选型示意图 图5:GPU和RDMA网卡上机安装后的实拍图
图5:GPU和RDMA网卡上机安装后的实拍图高性能计算网选型
智算中心的管理网相较于传统的通用计算数据中心来说,没有太大差异。比较特殊的就是Scale-out计算网络和存储网络,这两张网络承载的业务流量决定了交换机设备的选型需求:支持RDMA、低时延、高吞吐。
如下图所示,在组网连接方面也有所不同,这里会通过将GPU分组(图中#L0~7一组,#L8~15一组),组成只有一跳的高带宽互联域(HB域),并通过针对智算场景优化的Rail交换机连接,实现了高效的数据传输和计算协同。
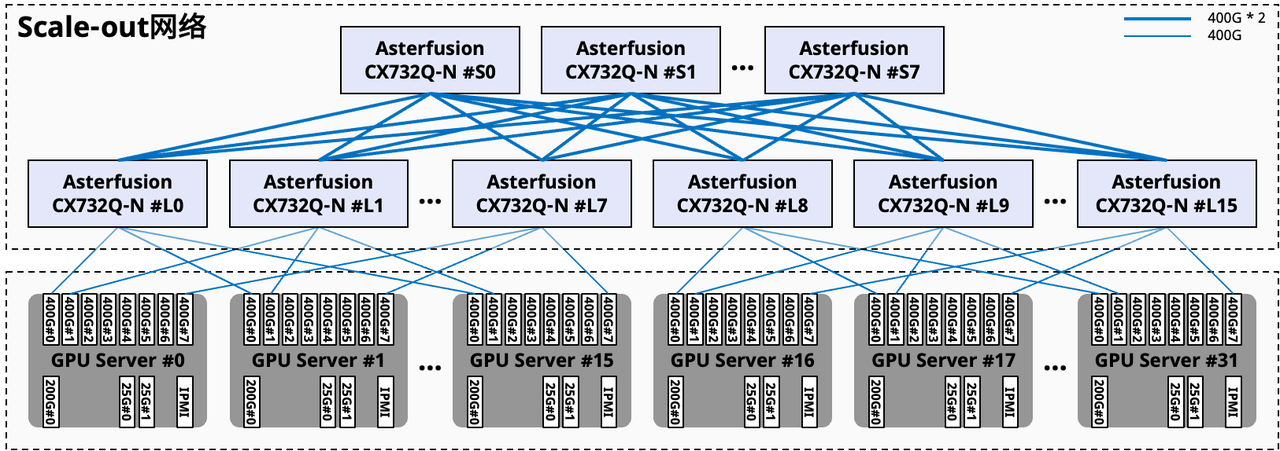 图6:组网连接示意
图6:组网连接示意
这次实验验证中,计算网的交换机选用星融元Asterfusion®️ CX-N系列超低时延交换机,具体型号为CX308P-48Y-N。
|
型号 |
业务接口 |
交换容量 |
|
CX864E-N |
64 x 800GE OSFP,2 x 10GE SFP+ |
102.4Tbps |
|
CX732Q-N |
32 x 400GE QSFP-DD, 2 x 10GE SFP+ |
25.6Tbps |
|
CX664D-N |
64 x 200GE QSFP56, 2 x 10GE SFP+ |
25.6Tbps |
|
CX564P-N |
64 x 100GE QSFP28, 2 x 10GE SFP+ |
12.8Tbps |
|
CX532P-N |
32 x 100GE QSFP28, 2 x 10GE SFP+ |
6.4Tbps |
|
CX308P-48Y-N |
48 x 25GE SFP28, 8 x 100GE QSFP28 |
4.0Tbps |
表1:具体型号规格示意
提升大模型训练效率
CX-N数据中心交换机的单机转发时延(400ns)低至业界平均水平的1/4~1/5,将网络时延在AI/ML应用端到端时延中的占比降至最低,同时多维度的高可靠设计确保网络在任何时候都不中断,帮助大模型的训练大幅度降低训练时间、提升整体效率。
全系列标配RoCEv2能力
区别于传统厂家多等级License权限管理方式,CX-N数据中心交换机所有应用场景License权限一致,全系列标配RoCEv2能力,提供PFC、ECN、Easy RoCE等一系列面向生产环境的增强网络特性,用户无须为此类高级特性额外付出网络建设成本,帮助用户获得更高的ROI。
开放、中立的AI/ML网络
星融元AI/ML网络解决方案的开放性确保用户能够重用已有的系统(K8s、Prometheus等)对网络进行管理,无需重复投入;星融元以“中立的网络供应商参与AI生态”的理念为用户提供专业的网络方案,帮助用户规避“全栈方案锁定”的风险。
最终,实验环节的组网拓扑和基础配置如下所示。
 图7:实验拓扑和基础配置示意
图7:实验拓扑和基础配置示意
软件准备
以上,我们已经完成了硬件选型,接下来我们将进行软件层面的配置:部署 RoCEv2 交换机、配置GPU 服务器、安装 GPU 驱动和集合通讯库。
RoCEv2交换机
 图8:CX308P-48Y-N设备图
图8:CX308P-48Y-N设备图
本次并行训练的环境中设备数量较少,组网相对简单:
1. 将CX5网卡的25GE业务接口连接到CX308P;
2. 在交换机上一键启用全局RoCE的无损配置;
3. 将三个25G业务口划分到一个VLAN下组成一个二层网络;
如前文提到,CX-N数据中心交换机全系列标配RoCEv2能力,配合星融元AsterNOS网络操作系统,只需要两行命令行便可配置所有必要的QoS规则和参数,具体命令行如下:
noone@MacBook-Air ~ % ssh admin@10.230.1.17
Linux AsterNOS 5.10.0-8-2-amd64 #1 SMP Debian 5.10.46-4 (2021-08-03) x86_64
_ _ _ _ ___ ____
/ ___ | |_ ___ _ __ | | | / _ / ___|
/ _ / __|| __| / _ | '__|| | || | | |___
/ ___ __ | |_ | __/| | | | || |_| | ___) |
/_/ _|___/ __| ___||_| |_| _| ___/ |____/
------- Asterfusion Network Operating System -------
Help: http://www.asterfusion.com/
Last login: Sun Sep 29 17:10:46 2024 from 172.16.20.241
AsterNOS# configure terminal
AsterNOS(config)# qos roce lossless
AsterNOS(config)# qos service-policy roce_lossless
AsterNOS(config)# end
AsterNOS# show qos roce
operational description
------------------ ------------- ---------------------------------------------------
status bind qos roce binding status
mode lossless Roce Mode
cable-length 40m Cable Length(in meters) for Roce Lossless Config
congestion-control
- congestion-mode ECN congestion-control
- enabled-tc 3,4 Congestion config enabled Traffic Class
- max-threshold 750000 Congestion config max-threshold
- min-threshold 15360 Congestion config max-threshold
pfc
- pfc-priority 3,4 switch-prio on which PFC is enabled
- rx-enabled enable PFC Rx Enabled status
- tx-enabled enable PFC Tx Enabled status
trust
- trust-mode dscp Trust Setting on the port for packet classification
RoCE DSCP->SP mapping configurations
==========================================
dscp switch-prio
----------------------- -------------
0,1,2,3,4,5,6,7 0
10,11,12,13,14,15,8,9 1
16,17,18,19,20,21,22,23 2
24,25,26,27,28,29,30,31 3
32,33,34,35,36,37,38,39 4
40,41,42,43,44,45,46,47 5
48,49,50,51,52,53,54,55 6
56,57,58,59,60,61,62,63 7
RoCE SP->TC mapping and ETS configurations
================================================
switch-prio mode weight
------------- ------ --------
6 SP
7 SP
RoCE pool config
======================
name switch-prio
----------------------- -------------
egress_lossy_profile 0 1 2 5 6
ingress_lossy_profile 0 1 2 5 6
egress_lossless_profile 3 4
roce_lossless_profile 3 4

GPU服务器基础配置
以下所有操作,在三台服务器上都需要执行,本文档中的配置步骤以server3为例。
关闭防火墙和SELinux
[root@server3 ~]# systemctl stop firewalld
[root@server3 ~]# systemctl disable firewalld
[root@server3 ~]# setenforce 0
[root@server3 ~]# sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/sysconfig/selinux
配置服务器间免密登陆
[root@server3 ~]# ssh-keygen
[root@server3 ~]# ssh-copy-id root@server1
[root@server3 ~]# ssh-copy-id root@server2
配置服务器软件源
[root@server3 ~]# ll /etc/yum.repos.d/
总用量 80
-rw-r--r-- 1 root root 2278 9月 19 08:00 CentOS-Base.repo
-rw-r--r-- 1 root root 232 9月 19 08:00 cuda-rhel7.repo
-rw-r--r-- 1 root root 210 9月 19 08:00 cudnn-local-rhel7-8.9.7.29.repo
drwxr-xr-x 2 root root 4096 9月 19 07:58 disable.d
-rw-r--r-- 1 root root 664 9月 19 08:00 epel.repo
-rw-r--r-- 1 root root 381 9月 19 08:00 hashicorp.repo
-rw-r--r-- 1 root root 218 9月 19 08:00 kubernetes.repo
-rw-r--r-- 1 root root 152 9月 19 08:00 MariaDB.repo
-rw-r--r-- 1 root root 855 9月 19 08:00 remi-modular.repo
-rw-r--r-- 1 root root 456 9月 19 08:00 remi-php54.repo
-rw-r--r-- 1 root root 1314 9月 19 08:00 remi-php70.repo
-rw-r--r-- 1 root root 1314 9月 19 08:00 remi-php71.repo
-rw-r--r-- 1 root root 1314 9月 19 08:00 remi-php72.repo
-rw-r--r-- 1 root root 1314 9月 19 08:00 remi-php73.repo
-rw-r--r-- 1 root root 1314 9月 19 08:00 remi-php74.repo
-rw-r--r-- 1 root root 1314 9月 19 08:00 remi-php80.repo
-rw-r--r-- 1 root root 1314 9月 19 08:00 remi-php81.repo
-rw-r--r-- 1 root root 1314 9月 19 08:00 remi-php82.repo
-rw-r--r-- 1 root root 2605 9月 19 08:00 remi.repo
-rw-r--r-- 1 root root 750 9月 19 08:00 remi-safe.repo
[root@server3 ~]# more /etc/yum.repos.d/*.repo
::::::::::::::
/etc/yum.repos.d/CentOS-Base.repo
::::::::::::::
# CentOS-Base.repo
#
# The mirror system uses the connecting IP address of the client and the
# update status of each mirror to pick mirrors that are updated to and
# geographically close to the client. You should use this for CentOS updates
# unless you are manually picking other mirrors.
#
# If the mirrorlist= does not work for you, as a fall back you can try the
# remarked out baseurl= line instead.
#
#
[base]
name=CentOS-7 - Base - mirrors.aliyun.com
failovermethod=priority
baseurl=http://mirrors.aliyun.com/centos/7/os/x86_64/
http://mirrors.aliyuncs.com/centos/7/os/x86_64/
http://mirrors.cloud.aliyuncs.com/centos/7/os/x86_64/
gpgcheck=1
gpgkey=http://mirrors.aliyun.com/centos/RPM-GPG-KEY-CentOS-7
#released updates
[updates]
name=CentOS-7 - Updates - mirrors.aliyun.com
failovermethod=priority
baseurl=http://mirrors.aliyun.com/centos/7/updates/x86_64/
http://mirrors.aliyuncs.com/centos/7/updates/x86_64/
http://mirrors.cloud.aliyuncs.com/centos/7/updates/x86_64/
gpgcheck=1
gpgkey=http://mirrors.aliyun.com/centos/RPM-GPG-KEY-CentOS-7
#additional packages that may be useful
[extras]
name=CentOS-7 - Extras - mirrors.aliyun.com
failovermethod=priority
baseurl=http://mirrors.aliyun.com/centos/7/extras/x86_64/
http://mirrors.aliyuncs.com/centos/7/extras/x86_64/
http://mirrors.cloud.aliyuncs.com/centos/7/extras/x86_64/
gpgcheck=1
gpgkey=http://mirrors.aliyun.com/centos/RPM-GPG-KEY-CentOS-7
#additional packages that extend functionality of existing packages
[centosplus]
name=CentOS-7 - Plus - mirrors.aliyun.com
failovermethod=priority
baseurl=http://mirrors.aliyun.com/centos/7/centosplus/x86_64/
http://mirrors.aliyuncs.com/centos/7/centosplus/x86_64/
http://mirrors.cloud.aliyuncs.com/centos/7/centosplus/x86_64/
gpgcheck=1
enabled=0
gpgkey=http://mirrors.aliyun.com/centos/RPM-GPG-KEY-CentOS-7
#contrib - packages by Centos Users
[contrib]
name=CentOS-7 - Contrib - mirrors.aliyun.com
failovermethod=priority
baseurl=http://mirrors.aliyun.com/centos/7/contrib/x86_64/
http://mirrors.aliyuncs.com/centos/7/contrib/x86_64/
http://mirrors.cloud.aliyuncs.com/centos/7/contrib/x86_64/
gpgcheck=1
enabled=0
gpgkey=http://mirrors.aliyun.com/centos/RPM-GPG-KEY-CentOS-7
::::::::::::::
/etc/yum.repos.d/cuda-rhel7.repo
::::::::::::::
[cuda-rhel7-x86_64]
name=cuda-rhel7-x86_64
baseurl=https://developer.download.nvidia.com/compute/cuda/repos/rhel7/x86_64
enabled=1
gpgcheck=1
gpgkey=https://developer.download.nvidia.com/compute/cuda/repos/rhel7/x86_64/D42D0685.pub
::::::::::::::
/etc/yum.repos.d/cudnn-local-rhel7-8.9.7.29.repo
::::::::::::::
[cudnn-local-rhel7-8.9.7.29]
name=cudnn-local-rhel7-8.9.7.29
baseurl=file:///var/cudnn-local-repo-rhel7-8.9.7.29
enabled=1
gpgcheck=1
gpgkey=file:///var/cudnn-local-repo-rhel7-8.9.7.29/90F10142.pub
obsoletes=0
::::::::::::::
/etc/yum.repos.d/epel.repo
::::::::::::::
[epel]
name=Extra Packages for Enterprise Linux 7 - $basearch
baseurl=http://mirrors.aliyun.com/epel/7/$basearch
failovermethod=priority
enabled=1
gpgcheck=0
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-7
[epel-debuginfo]
name=Extra Packages for Enterprise Linux 7 - $basearch - Debug
baseurl=http://mirrors.aliyun.com/epel/7/$basearch/debug
failovermethod=priority
enabled=0
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-7
gpgcheck=0
[epel-source]
name=Extra Packages for Enterprise Linux 7 - $basearch - Source
baseurl=http://mirrors.aliyun.com/epel/7/SRPMS
failovermethod=priority
enabled=0
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-7
gpgcheck=0
::::::::::::::
/etc/yum.repos.d/hashicorp.repo
::::::::::::::
[hashicorp]
name=Hashicorp Stable - $basearch
baseurl=https://rpm.releases.hashicorp.com/RHEL/$releasever/$basearch/stable
enabled=0
gpgcheck=1
gpgkey=https://rpm.releases.hashicorp.com/gpg
[hashicorp-test]
name=Hashicorp Test - $basearch
baseurl=https://rpm.releases.hashicorp.com/RHEL/$releasever/$basearch/test
enabled=0
gpgcheck=1
gpgkey=https://rpm.releases.hashicorp.com/gpg
::::::::::::::
/etc/yum.repos.d/kubernetes.repo
::::::::::::::
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.28/rpm/
enabled=1
gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.28/rpm/repodata/repomd.xml.key
::::::::::::::
/etc/yum.repos.d/MariaDB.repo
::::::::::::::
[mariadb]
name = MariaDB
baseurl = https://mirror.mariadb.org/yum/11.2/centos74-amd64
gpgkey = https://yum.mariadb.org/RPM-GPG-KEY-MariaDB
gpgcheck = 0
::::::::::::::
/etc/yum.repos.d/remi-modular.repo
::::::::::::::
# Repository: https://rpms.remirepo.net/
# Blog: https://blog.remirepo.net/
# Forum: https://forum.remirepo.net/
[remi-modular]
name=Remi's Modular repository for Enterprise Linux 7 - $basearch
#baseurl=http://rpms.remirepo.net/enterprise/7/modular/$basearch/
#mirrorlist=https://rpms.remirepo.net/enterprise/7/modular/httpsmirror
mirrorlist=http://cdn.remirepo.net/enterprise/7/modular/mirror
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
[remi-modular-test]
name=Remi's Modular testing repository for Enterprise Linux 7 - $basearch
#baseurl=http://rpms.remirepo.net/enterprise/7/modular-test/$basearch/
#mirrorlist=https://rpms.remirepo.net/enterprise/7/modular-test/httpsmirror
mirrorlist=http://cdn.remirepo.net/enterprise/7/modular-test/mirror
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
::::::::::::::
/etc/yum.repos.d/remi-php54.repo
::::::::::::::
# This repository only provides PHP 5.4 and its extensions
# NOTICE: common dependencies are in "remi-safe"
[remi-php54]
name=Remi's PHP 5.4 RPM repository for Enterprise Linux 7 - $basearch
#baseurl=http://rpms.remirepo.net/enterprise/7/php54/$basearch/
#mirrorlist=https://rpms.remirepo.net/enterprise/7/php54/httpsmirror
mirrorlist=http://cdn.remirepo.net/enterprise/7/php54/mirror
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
::::::::::::::
/etc/yum.repos.d/remi-php70.repo
::::::::::::::
# This repository only provides PHP 7.0 and its extensions
# NOTICE: common dependencies are in "remi-safe"
[remi-php70]
name=Remi's PHP 7.0 RPM repository for Enterprise Linux 7 - $basearch
#baseurl=http://rpms.remirepo.net/enterprise/7/php70/$basearch/
#mirrorlist=https://rpms.remirepo.net/enterprise/7/php70/httpsmirror
mirrorlist=http://cdn.remirepo.net/enterprise/7/php70/mirror
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
[remi-php70-debuginfo]
name=Remi's PHP 7.0 RPM repository for Enterprise Linux 7 - $basearch - debuginfo
baseurl=http://rpms.remirepo.net/enterprise/7/debug-php70/$basearch/
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
[remi-php70-test]
name=Remi's PHP 7.0 test RPM repository for Enterprise Linux 7 - $basearch
#baseurl=http://rpms.remirepo.net/enterprise/7/test70/$basearch/
#mirrorlist=https://rpms.remirepo.net/enterprise/7/test70/httpsmirror
mirrorlist=http://cdn.remirepo.net/enterprise/7/test70/mirror
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
[remi-php70-test-debuginfo]
name=Remi's PHP 7.0 test RPM repository for Enterprise Linux 7 - $basearch - debuginfo
baseurl=http://rpms.remirepo.net/enterprise/7/debug-test70/$basearch/
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
::::::::::::::
/etc/yum.repos.d/remi-php71.repo
::::::::::::::
# This repository only provides PHP 7.1 and its extensions
# NOTICE: common dependencies are in "remi-safe"
[remi-php71]
name=Remi's PHP 7.1 RPM repository for Enterprise Linux 7 - $basearch
#baseurl=http://rpms.remirepo.net/enterprise/7/php71/$basearch/
#mirrorlist=https://rpms.remirepo.net/enterprise/7/php71/httpsmirror
mirrorlist=http://cdn.remirepo.net/enterprise/7/php71/mirror
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
[remi-php71-debuginfo]
name=Remi's PHP 7.1 RPM repository for Enterprise Linux 7 - $basearch - debuginfo
baseurl=http://rpms.remirepo.net/enterprise/7/debug-php71/$basearch/
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
[remi-php71-test]
name=Remi's PHP 7.1 test RPM repository for Enterprise Linux 7 - $basearch
#baseurl=http://rpms.remirepo.net/enterprise/7/test71/$basearch/
#mirrorlist=https://rpms.remirepo.net/enterprise/7/test71/httpsmirror
mirrorlist=http://cdn.remirepo.net/enterprise/7/test71/mirror
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
[remi-php71-test-debuginfo]
name=Remi's PHP 7.1 test RPM repository for Enterprise Linux 7 - $basearch - debuginfo
baseurl=http://rpms.remirepo.net/enterprise/7/debug-test71/$basearch/
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
::::::::::::::
/etc/yum.repos.d/remi-php72.repo
::::::::::::::
# This repository only provides PHP 7.2 and its extensions
# NOTICE: common dependencies are in "remi-safe"
[remi-php72]
name=Remi's PHP 7.2 RPM repository for Enterprise Linux 7 - $basearch
#baseurl=http://rpms.remirepo.net/enterprise/7/php72/$basearch/
#mirrorlist=https://rpms.remirepo.net/enterprise/7/php72/httpsmirror
mirrorlist=http://cdn.remirepo.net/enterprise/7/php72/mirror
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
[remi-php72-debuginfo]
name=Remi's PHP 7.2 RPM repository for Enterprise Linux 7 - $basearch - debuginfo
baseurl=http://rpms.remirepo.net/enterprise/7/debug-php72/$basearch/
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
[remi-php72-test]
name=Remi's PHP 7.2 test RPM repository for Enterprise Linux 7 - $basearch
#baseurl=http://rpms.remirepo.net/enterprise/7/test72/$basearch/
#mirrorlist=https://rpms.remirepo.net/enterprise/7/test72/httpsmirror
mirrorlist=http://cdn.remirepo.net/enterprise/7/test72/mirror
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
[remi-php72-test-debuginfo]
name=Remi's PHP 7.2 test RPM repository for Enterprise Linux 7 - $basearch - debuginfo
baseurl=http://rpms.remirepo.net/enterprise/7/debug-test72/$basearch/
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
::::::::::::::
/etc/yum.repos.d/remi-php73.repo
::::::::::::::
# This repository only provides PHP 7.3 and its extensions
# NOTICE: common dependencies are in "remi-safe"
[remi-php73]
name=Remi's PHP 7.3 RPM repository for Enterprise Linux 7 - $basearch
#baseurl=http://rpms.remirepo.net/enterprise/7/php73/$basearch/
#mirrorlist=https://rpms.remirepo.net/enterprise/7/php73/httpsmirror
mirrorlist=http://cdn.remirepo.net/enterprise/7/php73/mirror
enabled=1
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
[remi-php73-debuginfo]
name=Remi's PHP 7.3 RPM repository for Enterprise Linux 7 - $basearch - debuginfo
baseurl=http://rpms.remirepo.net/enterprise/7/debug-php73/$basearch/
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
[remi-php73-test]
name=Remi's PHP 7.3 test RPM repository for Enterprise Linux 7 - $basearch
#baseurl=http://rpms.remirepo.net/enterprise/7/test73/$basearch/
#mirrorlist=https://rpms.remirepo.net/enterprise/7/test73/httpsmirror
mirrorlist=http://cdn.remirepo.net/enterprise/7/test73/mirror
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
[remi-php73-test-debuginfo]
name=Remi's PHP 7.3 test RPM repository for Enterprise Linux 7 - $basearch - debuginfo
baseurl=http://rpms.remirepo.net/enterprise/7/debug-test73/$basearch/
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
::::::::::::::
/etc/yum.repos.d/remi-php74.repo
::::::::::::::
# This repository only provides PHP 7.4 and its extensions
# NOTICE: common dependencies are in "remi-safe"
[remi-php74]
name=Remi's PHP 7.4 RPM repository for Enterprise Linux 7 - $basearch
#baseurl=http://rpms.remirepo.net/enterprise/7/php74/$basearch/
#mirrorlist=https://rpms.remirepo.net/enterprise/7/php74/httpsmirror
mirrorlist=http://cdn.remirepo.net/enterprise/7/php74/mirror
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
[remi-php74-debuginfo]
name=Remi's PHP 7.4 RPM repository for Enterprise Linux 7 - $basearch - debuginfo
baseurl=http://rpms.remirepo.net/enterprise/7/debug-php74/$basearch/
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
[remi-php74-test]
name=Remi's PHP 7.4 test RPM repository for Enterprise Linux 7 - $basearch
#baseurl=http://rpms.remirepo.net/enterprise/7/test74/$basearch/
#mirrorlist=https://rpms.remirepo.net/enterprise/7/test74/httpsmirror
mirrorlist=http://cdn.remirepo.net/enterprise/7/test74/mirror
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
[remi-php74-test-debuginfo]
name=Remi's PHP 7.4 test RPM repository for Enterprise Linux 7 - $basearch - debuginfo
baseurl=http://rpms.remirepo.net/enterprise/7/debug-test74/$basearch/
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
::::::::::::::
/etc/yum.repos.d/remi-php80.repo
::::::::::::::
# This repository only provides PHP 8.0 and its extensions
# NOTICE: common dependencies are in "remi-safe"
[remi-php80]
name=Remi's PHP 8.0 RPM repository for Enterprise Linux 7 - $basearch
#baseurl=http://rpms.remirepo.net/enterprise/7/php80/$basearch/
#mirrorlist=https://rpms.remirepo.net/enterprise/7/php80/httpsmirror
mirrorlist=http://cdn.remirepo.net/enterprise/7/php80/mirror
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
[remi-php80-debuginfo]
name=Remi's PHP 8.0 RPM repository for Enterprise Linux 7 - $basearch - debuginfo
baseurl=http://rpms.remirepo.net/enterprise/7/debug-php80/$basearch/
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
[remi-php80-test]
name=Remi's PHP 8.0 test RPM repository for Enterprise Linux 7 - $basearch
#baseurl=http://rpms.remirepo.net/enterprise/7/test80/$basearch/
#mirrorlist=https://rpms.remirepo.net/enterprise/7/test80/httpsmirror
mirrorlist=http://cdn.remirepo.net/enterprise/7/test80/mirror
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
[remi-php80-test-debuginfo]
name=Remi's PHP 8.0 test RPM repository for Enterprise Linux 7 - $basearch - debuginfo
baseurl=http://rpms.remirepo.net/enterprise/7/debug-test80/$basearch/
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
::::::::::::::
/etc/yum.repos.d/remi-php81.repo
::::::::::::::
# This repository only provides PHP 8.1 and its extensions
# NOTICE: common dependencies are in "remi-safe"
[remi-php81]
name=Remi's PHP 8.1 RPM repository for Enterprise Linux 7 - $basearch
#baseurl=http://rpms.remirepo.net/enterprise/7/php81/$basearch/
#mirrorlist=https://rpms.remirepo.net/enterprise/7/php81/httpsmirror
mirrorlist=http://cdn.remirepo.net/enterprise/7/php81/mirror
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
[remi-php81-debuginfo]
name=Remi's PHP 8.1 RPM repository for Enterprise Linux 7 - $basearch - debuginfo
baseurl=http://rpms.remirepo.net/enterprise/7/debug-php81/$basearch/
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
[remi-php81-test]
name=Remi's PHP 8.1 test RPM repository for Enterprise Linux 7 - $basearch
#baseurl=http://rpms.remirepo.net/enterprise/7/test81/$basearch/
#mirrorlist=https://rpms.remirepo.net/enterprise/7/test81/httpsmirror
mirrorlist=http://cdn.remirepo.net/enterprise/7/test81/mirror
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
[remi-php81-test-debuginfo]
name=Remi's PHP 8.1 test RPM repository for Enterprise Linux 7 - $basearch - debuginfo
baseurl=http://rpms.remirepo.net/enterprise/7/debug-test81/$basearch/
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
::::::::::::::
/etc/yum.repos.d/remi-php82.repo
::::::::::::::
# This repository only provides PHP 8.2 and its extensions
# NOTICE: common dependencies are in "remi-safe"
[remi-php82]
name=Remi's PHP 8.2 RPM repository for Enterprise Linux 7 - $basearch
#baseurl=http://rpms.remirepo.net/enterprise/7/php82/$basearch/
#mirrorlist=https://rpms.remirepo.net/enterprise/7/php82/httpsmirror
mirrorlist=http://cdn.remirepo.net/enterprise/7/php82/mirror
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
[remi-php82-debuginfo]
name=Remi's PHP 8.2 RPM repository for Enterprise Linux 7 - $basearch - debuginfo
baseurl=http://rpms.remirepo.net/enterprise/7/debug-php82/$basearch/
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
[remi-php82-test]
name=Remi's PHP 8.2 test RPM repository for Enterprise Linux 7 - $basearch
#baseurl=http://rpms.remirepo.net/enterprise/7/test82/$basearch/
#mirrorlist=https://rpms.remirepo.net/enterprise/7/test82/httpsmirror
mirrorlist=http://cdn.remirepo.net/enterprise/7/test82/mirror
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
[remi-php82-test-debuginfo]
name=Remi's PHP 8.2 test RPM repository for Enterprise Linux 7 - $basearch - debuginfo
baseurl=http://rpms.remirepo.net/enterprise/7/debug-test82/$basearch/
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
::::::::::::::
/etc/yum.repos.d/remi.repo
::::::::::::::
# Repository: http://rpms.remirepo.net/
# Blog: http://blog.remirepo.net/
# Forum: http://forum.remirepo.net/
[remi]
name=Remi's RPM repository for Enterprise Linux 7 - $basearch
#baseurl=http://rpms.remirepo.net/enterprise/7/remi/$basearch/
#mirrorlist=https://rpms.remirepo.net/enterprise/7/remi/httpsmirror
mirrorlist=http://cdn.remirepo.net/enterprise/7/remi/mirror
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
[remi-php55]
name=Remi's PHP 5.5 RPM repository for Enterprise Linux 7 - $basearch
#baseurl=http://rpms.remirepo.net/enterprise/7/php55/$basearch/
#mirrorlist=https://rpms.remirepo.net/enterprise/7/php55/httpsmirror
mirrorlist=http://cdn.remirepo.net/enterprise/7/php55/mirror
# NOTICE: common dependencies are in "remi-safe"
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
[remi-php56]
name=Remi's PHP 5.6 RPM repository for Enterprise Linux 7 - $basearch
#baseurl=http://rpms.remirepo.net/enterprise/7/php56/$basearch/
#mirrorlist=https://rpms.remirepo.net/enterprise/7/php56/httpsmirror
mirrorlist=http://cdn.remirepo.net/enterprise/7/php56/mirror
# NOTICE: common dependencies are in "remi-safe"
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
[remi-test]
name=Remi's test RPM repository for Enterprise Linux 7 - $basearch
#baseurl=http://rpms.remirepo.net/enterprise/7/test/$basearch/
#mirrorlist=https://rpms.remirepo.net/enterprise/7/test/mirror
mirrorlist=http://cdn.remirepo.net/enterprise/7/test/mirror
# WARNING: If you enable this repository, you must also enable "remi"
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
[remi-debuginfo]
name=Remi's RPM repository for Enterprise Linux 7 - $basearch - debuginfo
baseurl=http://rpms.remirepo.net/enterprise/7/debug-remi/$basearch/
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
[remi-php55-debuginfo]
name=Remi's PHP 5.5 RPM repository for Enterprise Linux 7 - $basearch - debuginfo
baseurl=http://rpms.remirepo.net/enterprise/7/debug-php55/$basearch/
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
[remi-php56-debuginfo]
name=Remi's PHP 5.6 RPM repository for Enterprise Linux 7 - $basearch - debuginfo
baseurl=http://rpms.remirepo.net/enterprise/7/debug-php56/$basearch/
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
[remi-test-debuginfo]
name=Remi's test RPM repository for Enterprise Linux 7 - $basearch - debuginfo
baseurl=http://rpms.remirepo.net/enterprise/7/debug-test/$basearch/
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
::::::::::::::
/etc/yum.repos.d/remi-safe.repo
::::::::::::::
# This repository is safe to use with RHEL/CentOS base repository
# it only provides additional packages for the PHP stack
# all dependencies are in base repository or in EPEL
[remi-safe]
name=Safe Remi's RPM repository for Enterprise Linux 7 - $basearch
#baseurl=http://rpms.remirepo.net/enterprise/7/safe/$basearch/
#mirrorlist=https://rpms.remirepo.net/enterprise/7/safe/httpsmirror
mirrorlist=http://cdn.remirepo.net/enterprise/7/safe/mirror
enabled=1
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
[remi-safe-debuginfo]
name=Remi's RPM repository for Enterprise Linux 7 - $basearch - debuginfo
baseurl=http://rpms.remirepo.net/enterprise/7/debug-remi/$basearch/
enabled=0
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
[root@server3 ~]#
安装Python3
准备工作目录
[root@server3 lichao]# mkdir AIGC
[root@server3 lichao]# cd AIGC/
安装Python3
安装编译环境和依赖包
[root@server3 AIGC]# yum install wget gcc openssl-devel bzip2-devel libffi-devel
[root@server3 AIGC]# yum install openssl11 openssl11-devel openssl-devel
解压源码包
[root@server3 AIGC]# tar xvf Python-3.11.9.tar.xz
[root@server3 AIGC]# cd Python-3.11.9
[root@server3 Python-3.11.9]#
设置环境变量
[root@server3 Python-3.11.9]# export CFLAGS=$(pkg-config --cflags openssl11)
[root@server3 Python-3.11.9]# export LDFLAGS=$(pkg-config --libs openssl11)
进行编译安装
[root@server3 Python-3.11.9]# mkdir -p /home/lichao/opt/python3.11.9
[root@server3 Python-3.11.9]# ./configure --prefix=/home/lichao/opt/python3.11.9
[root@server3 Python-3.11.9]# make && make install
创建软链接,用于全局访问
[root@server3 Python-3.11.9]# cd /home/lichao/opt/python3.11.9/
[root@server3 python3.11.9]# ln -s /home/lichao/opt/python3.11.9/bin/python3 /usr/bin/python3
[root@server3 python3.11.9]# ln -s /home/lichao/opt/python3.11.9/bin/pip3 /usr/bin/pip3
[root@server3 python3.11.9]# ll /usr/bin/python3
lrwxrwxrwx 1 root root 41 5月 16 08:32 /usr/bin/python3 -> /home/lichao/opt/python3.11.9/bin/python3
[root@server3 python3.11.9]# ll /usr/bin/pip3
lrwxrwxrwx 1 root root 38 5月 16 08:32 /usr/bin/pip3 -> /home/lichao/opt/python3.11.9/bin/pip3
验证测试
[root@server3 python3.11.9]# python3
Python 3.11.9 (main, May 16 2024, 08:23:00) [GCC 4.8.5 20150623 (Red Hat 4.8.5-44)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> exit()
[root@server3 python3.11.9]#
安装MLNX网卡驱动
下文以CentOS7为例,详细介绍了Mellanox网卡MLNX_OFED的驱动安装和固件升级方法。
本次下载的驱动版本为:MLNX_OFED_LINUX-4.7-3.2.9.0-rhel7.6-x86_64.tgz。
[root@server3 ~]# tar –zxvf MLNX_OFED_LINUX-4.7-3.2.9.0-rhel7.6-x86_64.tgz
[root@server3 ~]# cd MLNX_OFED_LINUX-4.7-3.2.9.0-rhel7.6-x86_64
查看当前系统的内核版本
[root@server3 MLNX_OFED_LINUX-4.7-3.2.9.0-rhel7.6-x86_64]# uname -r
3.10.0-957.el7.x86_64
查看当前驱动所支持的内核版本
[root@server3 MLNX_OFED_LINUX-4.7-3.2.9.0-rhel7.6-x86_64]# cat .supported_kernels
3.10.0-957.el7.x86_64
注:由以上可知下载的默认驱动支持当前的内核版本
如果当前内核与支持内核不匹配,手动编译适合内核的驱动,在编译之前首先安装gcc编译环境和kernel开发包
[root@server3 MLNX_OFED_LINUX-4.7-3.2.9.0-rhel7.6-x86_64]#yum install gcc gcc-c++
libstdc++-devel kernel-default-devel
添加针对当前内核版本的驱动
[root@server3 MLNX_OFED_LINUX-4.7-3.2.9.0-rhel7.6-x86_64]#./mlnx_add_kernel_support.sh -m /root/MLNX_OFED_LINUX-4.7-3.2.9.0-rhel7.6-x86_64 -v
注:完成后生成的驱动文件在/tmp目录下
[root@server3 MLNX_OFED_LINUX-4.7-3.2.9.0-rhel7.6-x86_64]# ls -l /tmp/MLNX_OFED_LINUX-4.7-3.2.9.0-rhel7.6-x86_64-ext.tgz
-rw-r--r-- 1 root root 282193833 Dec 23 09:49 /tmp/MLNX_OFED_LINUX-4.7-3.2.9.0-rhel7.6-x86_64-ext.tgz
安装驱动
[root@server3 tmp]# tar xzvf MLNX_OFED_LINUX-4.7-3.2.9.0-rhel7.6-x86_64-ext.tgz
[root@server3 tmp]# cd MLNX_OFED_LINUX-4.7-3.2.9.0-rhel7.6-x86_64-ext
[root@server3 tmp]# ./mlnxofedinstall
最后启动openibd服务
[root@server3 ~]#/etc/init.d/openibd start
[root@server3 ~]#chkconfig openibd on
安装GPU驱动和集合通讯库安装配置
安装配置
- 安装GPU驱动和CUDA、CUDNN
安装开始前,请根据自己的GPU型号、操作系统版本去英伟达官网下载相对应的软件包。
[root@server3 AIGC]# ll
总用量 1733448
-rw-r--r-- 1 root root 1430373861 5月 16 08:55 cudnn-local-repo-rhel7-8.9.7.29-1.0-1.x86_64.rpm
drwxr-xr-x 7 root root 141 5月 17 13:45 nccl-tests
-rwxr-xr-x 1 root root 306736632 5月 16 08:43 NVIDIA-Linux-x86_64-550.67.run
drwxrwxr-x 10 1000 1000 4096 5月 17 13:21 openmpi-4.1.6
-rw-r--r-- 1 root root 17751702 9月 30 2023 openmpi-4.1.6.tar.gz
drwxr-xr-x 17 root root 4096 5月 16 08:23 Python-3.11.9
-rw-r--r-- 1 root root 20175816 4月 2 13:11 Python-3.11.9.tar.xz
[root@server3 AIGC]# ./NVIDIA-Linux-x86_64-550.67.run
Verifying archive integrity... OK
Uncompressing NVIDIA Accelerated Graphics Driver for Linux-x86_64 550.67...................
[root@server3 AIGC]# yum-config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/rhel7/x86_64/cuda-rhel7.repo
已加载插件:fastestmirror, nvidia
adding repo from: https://developer.download.nvidia.com/compute/cuda/repos/rhel7/x86_64/cuda-rhel7.repo
grabbing file https://developer.download.nvidia.com/compute/cuda/repos/rhel7/x86_64/cuda-rhel7.repo to /etc/yum.repos.d/cuda-rhel7.repo
repo saved to /etc/yum.repos.d/cuda-rhel7.repo
[root@server3 AIGC]# yum install libnccl-2.21.5-1+cuda12.4 libnccl-devel-2.21.5-1+cuda12.4 libnccl-static-2.21.5-1+cuda12.4
[root@server3 AIGC]# yum install cudnn-local-repo-rhel7-8.9.7.29-1.0-1.x86_64.rpm
安装完成后,可以通过nvidia-smi查看驱动和CUDA版本。如果版本不匹配,则执行此命令行会报错。
[root@server3 AIGC]# nvidia-smi
Mon Jun 3 11:59:36 2024
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.67 Driver Version: 550.67 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 4060 Ti Off | 00000000:02:00.0 Off | N/A |
| 0% 34C P0 27W / 165W | 1MiB / 16380MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
[root@server3 AIGC]#
- 编译安装OpenMPI
[root@server3 AIGC]# tar xvf openmpi-4.1.6.tar.gz
[root@server3 openmpi-4.1.6]#
[root@server3 openmpi-4.1.6]# mkdir -p /home/lichao/lib/openmpi
[root@server3 openmpi-4.1.6]# ./configure --prefix=/home/lichao/lib/openmpi -with-cuda=/usr/local/cuda-12.4 -with-nccl=/usr/lib64
Open MPI configuration:
-----------------------
Version: 4.1.6
Build MPI C bindings: yes
Build MPI C++ bindings (deprecated): no
Build MPI Fortran bindings: mpif.h, use mpi
MPI Build Java bindings (experimental): no
Build Open SHMEM support: yes
Debug build: no
Platform file: (none)
Miscellaneous
-----------------------
CUDA support: yes
HWLOC support: internal
Libevent support: internal
Open UCC: no
PMIx support: Internal
Transports
-----------------------
Cisco usNIC: no
Cray uGNI (Gemini/Aries): no
Intel Omnipath (PSM2): no
Intel TrueScale (PSM): no
Mellanox MXM: no
Open UCX: yes
OpenFabrics OFI Libfabric: no
OpenFabrics Verbs: yes
Portals4: no
Shared memory/copy in+copy out: yes
Shared memory/Linux CMA: yes
Shared memory/Linux KNEM: no
Shared memory/XPMEM: no
TCP: yes
Resource Managers
-----------------------
Cray Alps: no
Grid Engine: no
LSF: no
Moab: no
Slurm: yes
ssh/rsh: yes
Torque: no
OMPIO File Systems
-----------------------
DDN Infinite Memory Engine: no
Generic Unix FS: yes
IBM Spectrum Scale/GPFS: no
Lustre: no
PVFS2/OrangeFS: no
[root@server3 openmpi-4.1.6]#
- 编译安装NCCL-Test
[root@server3 lichao]# cd AIGC/
[root@server3 AIGC]# git clone https://github.com/NVIDIA/nccl-tests.git
[root@server3 AIGC]# cd nccl-tests/
[root@server3 nccl-tests]# make clean
[root@server3 nccl-tests]# make MPI=1 MPI_HOME=/home/lichao/opt/openmpi/ CUDA_HOME=/usr/local/cuda-12.4/ NCCL_HOME=/usr/lib64/
集合通信性能测试方法(all_reduce)
[root@server1 lichao]# cat run_nccl-test.sh
/home/lichao/opt/openmpi/bin/mpirun --allow-run-as-root
-np 3
-host "server1,server2,server3"
-mca btl ^openib
-x NCCL_DEBUG=INFO
-x NCCL_ALGO=ring
-x NCCL_IB_DISABLE=0
-x NCCL_IB_GID_INDEX=3
-x NCCL_SOCKET_IFNAME=ens11f1
-x NCCL_IB_HCA=mlx5_1:1
/home/lichao/AIGC/nccl-tests/build/all_reduce_perf -b 128 -e 8G -f 2 -g 1
[root@server1 lichao]# ./run_nccl-test.sh
# nThread 1 nGpus 1 minBytes 128 maxBytes 8589934592 step: 2(factor) warmup iters: 5 iters: 20 agg iters: 1 validation: 1 graph: 0
#
# Using devices
# Rank 0 Group 0 Pid 18697 on server1 device 0 [0x02] NVIDIA GeForce RTX 4060 Ti
# Rank 1 Group 0 Pid 20893 on server2 device 0 [0x02] NVIDIA GeForce RTX 4060 Ti
# Rank 2 Group 0 Pid 2458 on server3 device 0 [0x02] NVIDIA GeForce RTX 4060 Ti
#
# Reducing maxBytes to 5261099008 due to memory limitation
server1:18697:18697 [0] NCCL INFO NCCL_SOCKET_IFNAME set by environment to ens11f1
server1:18697:18697 [0] NCCL INFO Bootstrap : Using ens11f1:172.16.0.11< 0 >
server1:18697:18697 [0] NCCL INFO NET/Plugin: No plugin found (libnccl-net.so)
server1:18697:18697 [0] NCCL INFO NET/Plugin: Plugin load returned 2 : libnccl-net.so: cannot open shared object file: No such file or directory : when loading libnccl-net.so
server1:18697:18697 [0] NCCL INFO NET/Plugin: Using internal network plugin.
server2:20893:20893 [0] NCCL INFO cudaDriverVersion 12040
server2:20893:20893 [0] NCCL INFO NCCL_SOCKET_IFNAME set by environment to ens11f1
server2:20893:20893 [0] NCCL INFO Bootstrap : Using ens11f1:172.16.0.12< 0 >
server2:20893:20893 [0] NCCL INFO NET/Plugin: No plugin found (libnccl-net.so)
server2:20893:20893 [0] NCCL INFO NET/Plugin: Plugin load returned 2 : libnccl-net.so: cannot open shared object file: No such file or directory : when loading libnccl-net.so
server2:20893:20893 [0] NCCL INFO NET/Plugin: Using internal network plugin.
server1:18697:18697 [0] NCCL INFO cudaDriverVersion 12040
NCCL version 2.21.5+cuda12.4
server3:2458:2458 [0] NCCL INFO cudaDriverVersion 12040
server3:2458:2458 [0] NCCL INFO NCCL_SOCKET_IFNAME set by environment to ens11f1
server3:2458:2458 [0] NCCL INFO Bootstrap : Using ens11f1:172.16.0.13< 0 >
server3:2458:2458 [0] NCCL INFO NET/Plugin: No plugin found (libnccl-net.so)
server3:2458:2458 [0] NCCL INFO NET/Plugin: Plugin load returned 2 : libnccl-net.so: cannot open shared object file: No such file or directory : when loading libnccl-net.so
server3:2458:2458 [0] NCCL INFO NET/Plugin: Using internal network plugin.
server2:20893:20907 [0] NCCL INFO NCCL_IB_DISABLE set by environment to 0.
server2:20893:20907 [0] NCCL INFO NCCL_SOCKET_IFNAME set by environment to ens11f1
server2:20893:20907 [0] NCCL INFO NCCL_IB_HCA set to mlx5_1:1
server2:20893:20907 [0] NCCL INFO NET/IB : Using [0]mlx5_1:1/RoCE [RO]; OOB ens11f1:172.16.0.12< 0 >
server2:20893:20907 [0] NCCL INFO Using non-device net plugin version 0
server2:20893:20907 [0] NCCL INFO Using network IB
server3:2458:2473 [0] NCCL INFO NCCL_IB_DISABLE set by environment to 0.
server3:2458:2473 [0] NCCL INFO NCCL_SOCKET_IFNAME set by environment to ens11f1
server3:2458:2473 [0] NCCL INFO NCCL_IB_HCA set to mlx5_1:1
server1:18697:18712 [0] NCCL INFO NCCL_IB_DISABLE set by environment to 0.
server1:18697:18712 [0] NCCL INFO NCCL_SOCKET_IFNAME set by environment to ens11f1
server3:2458:2473 [0] NCCL INFO NET/IB : Using [0]mlx5_1:1/RoCE [RO]; OOB ens11f1:172.16.0.13< 0 >
server1:18697:18712 [0] NCCL INFO NCCL_IB_HCA set to mlx5_1:1
server3:2458:2473 [0] NCCL INFO Using non-device net plugin version 0
server3:2458:2473 [0] NCCL INFO Using network IB
server1:18697:18712 [0] NCCL INFO NET/IB : Using [0]mlx5_1:1/RoCE [RO]; OOB ens11f1:172.16.0.11< 0 >
server1:18697:18712 [0] NCCL INFO Using non-device net plugin version 0
server1:18697:18712 [0] NCCL INFO Using network IB
server1:18697:18712 [0] NCCL INFO ncclCommInitRank comm 0x23622c0 rank 0 nranks 3 cudaDev 0 nvmlDev 0 busId 2000 commId 0x35491327c8228dd0 - Init START
server3:2458:2473 [0] NCCL INFO ncclCommInitRank comm 0x346ffc0 rank 2 nranks 3 cudaDev 0 nvmlDev 0 busId 2000 commId 0x35491327c8228dd0 - Init START
server2:20893:20907 [0] NCCL INFO ncclCommInitRank comm 0x2a1af20 rank 1 nranks 3 cudaDev 0 nvmlDev 0 busId 2000 commId 0x35491327c8228dd0 - Init START
server3:2458:2473 [0] NCCL INFO Setting affinity for GPU 0 to 0f,ff000fff
server2:20893:20907 [0] NCCL INFO Setting affinity for GPU 0 to 0f,ff000fff
server1:18697:18712 [0] NCCL INFO Setting affinity for GPU 0 to 0f,ff000fff
server1:18697:18712 [0] NCCL INFO comm 0x23622c0 rank 0 nRanks 3 nNodes 3 localRanks 1 localRank 0 MNNVL 0
server1:18697:18712 [0] NCCL INFO Channel 00/02 : 0 1 2
server1:18697:18712 [0] NCCL INFO Channel 01/02 : 0 1 2
server1:18697:18712 [0] NCCL INFO Trees [0] 2/-1/-1->0->-1 [1] 2/-1/-1->0->1
server1:18697:18712 [0] NCCL INFO P2P Chunksize set to 131072
server3:2458:2473 [0] NCCL INFO comm 0x346ffc0 rank 2 nRanks 3 nNodes 3 localRanks 1 localRank 0 MNNVL 0
server2:20893:20907 [0] NCCL INFO comm 0x2a1af20 rank 1 nRanks 3 nNodes 3 localRanks 1 localRank 0 MNNVL 0
server3:2458:2473 [0] NCCL INFO Trees [0] 1/-1/-1->2->0 [1] -1/-1/-1->2->0
server3:2458:2473 [0] NCCL INFO P2P Chunksize set to 131072
server2:20893:20907 [0] NCCL INFO Trees [0] -1/-1/-1->1->2 [1] 0/-1/-1->1->-1
server2:20893:20907 [0] NCCL INFO P2P Chunksize set to 131072
server3:2458:2473 [0] NCCL INFO Channel 00/0 : 1[0] -> 2[0] [receive] via NET/IB/0
server3:2458:2473 [0] NCCL INFO Channel 01/0 : 1[0] -> 2[0] [receive] via NET/IB/0
server3:2458:2473 [0] NCCL INFO Channel 00/0 : 2[0] -> 0[0] [send] via NET/IB/0
server3:2458:2473 [0] NCCL INFO Channel 01/0 : 2[0] -> 0[0] [send] via NET/IB/0
server2:20893:20907 [0] NCCL INFO Channel 00/0 : 0[0] -> 1[0] [receive] via NET/IB/0
server2:20893:20907 [0] NCCL INFO Channel 01/0 : 0[0] -> 1[0] [receive] via NET/IB/0
server2:20893:20907 [0] NCCL INFO Channel 00/0 : 1[0] -> 2[0] [send] via NET/IB/0
server2:20893:20907 [0] NCCL INFO Channel 01/0 : 1[0] -> 2[0] [send] via NET/IB/0
server1:18697:18712 [0] NCCL INFO Channel 00/0 : 2[0] -> 0[0] [receive] via NET/IB/0
server1:18697:18712 [0] NCCL INFO Channel 01/0 : 2[0] -> 0[0] [receive] via NET/IB/0
server1:18697:18712 [0] NCCL INFO Channel 00/0 : 0[0] -> 1[0] [send] via NET/IB/0
server1:18697:18712 [0] NCCL INFO Channel 01/0 : 0[0] -> 1[0] [send] via NET/IB/0
server3:2458:2475 [0] NCCL INFO NCCL_IB_GID_INDEX set by environment to 3.
server1:18697:18714 [0] NCCL INFO NCCL_IB_GID_INDEX set by environment to 3.
server2:20893:20909 [0] NCCL INFO NCCL_IB_GID_INDEX set by environment to 3.
server1:18697:18712 [0] NCCL INFO Connected all rings
server1:18697:18712 [0] NCCL INFO Channel 01/0 : 1[0] -> 0[0] [receive] via NET/IB/0
server3:2458:2473 [0] NCCL INFO Connected all rings
server2:20893:20907 [0] NCCL INFO Connected all rings
server1:18697:18712 [0] NCCL INFO Channel 00/0 : 0[0] -> 2[0] [send] via NET/IB/0
server2:20893:20907 [0] NCCL INFO Channel 00/0 : 2[0] -> 1[0] [receive] via NET/IB/0
server1:18697:18712 [0] NCCL INFO Channel 01/0 : 0[0] -> 2[0] [send] via NET/IB/0
server3:2458:2473 [0] NCCL INFO Channel 00/0 : 0[0] -> 2[0] [receive] via NET/IB/0
server2:20893:20907 [0] NCCL INFO Channel 01/0 : 1[0] -> 0[0] [send] via NET/IB/0
server3:2458:2473 [0] NCCL INFO Channel 01/0 : 0[0] -> 2[0] [receive] via NET/IB/0
server3:2458:2473 [0] NCCL INFO Channel 00/0 : 2[0] -> 1[0] [send] via NET/IB/0
server3:2458:2473 [0] NCCL INFO Connected all trees
server1:18697:18712 [0] NCCL INFO Connected all trees
server1:18697:18712 [0] NCCL INFO NCCL_ALGO set by environment to ring
server3:2458:2473 [0] NCCL INFO NCCL_ALGO set by environment to ring
server3:2458:2473 [0] NCCL INFO threadThresholds 8/8/64 | 24/8/64 | 512 | 512
server3:2458:2473 [0] NCCL INFO 2 coll channels, 2 collnet channels, 0 nvls channels, 2 p2p channels, 2 p2p channels per peer
server2:20893:20907 [0] NCCL INFO Connected all trees
server2:20893:20907 [0] NCCL INFO NCCL_ALGO set by environment to ring
server2:20893:20907 [0] NCCL INFO threadThresholds 8/8/64 | 24/8/64 | 512 | 512
server2:20893:20907 [0] NCCL INFO 2 coll channels, 2 collnet channels, 0 nvls channels, 2 p2p channels, 2 p2p channels per peer
server1:18697:18712 [0] NCCL INFO threadThresholds 8/8/64 | 24/8/64 | 512 | 512
server1:18697:18712 [0] NCCL INFO 2 coll channels, 2 collnet channels, 0 nvls channels, 2 p2p channels, 2 p2p channels per peer
server2:20893:20907 [0] NCCL INFO TUNER/Plugin: Plugin load returned 11 : libnccl-net.so: cannot open shared object file: No such file or directory : when loading libnccl-tuner.so
server2:20893:20907 [0] NCCL INFO TUNER/Plugin: Using internal tuner plugin.
server2:20893:20907 [0] NCCL INFO ncclCommInitRank comm 0x2a1af20 rank 1 nranks 3 cudaDev 0 nvmlDev 0 busId 2000 commId 0x35491327c8228dd0 - Init COMPLETE
server3:2458:2473 [0] NCCL INFO TUNER/Plugin: Plugin load returned 11 : libnccl-net.so: cannot open shared object file: No such file or directory : when loading libnccl-tuner.so
server3:2458:2473 [0] NCCL INFO TUNER/Plugin: Using internal tuner plugin.
server3:2458:2473 [0] NCCL INFO ncclCommInitRank comm 0x346ffc0 rank 2 nranks 3 cudaDev 0 nvmlDev 0 busId 2000 commId 0x35491327c8228dd0 - Init COMPLETE
server1:18697:18712 [0] NCCL INFO TUNER/Plugin: Plugin load returned 11 : libnccl-net.so: cannot open shared object file: No such file or directory : when loading libnccl-tuner.so
server1:18697:18712 [0] NCCL INFO TUNER/Plugin: Using internal tuner plugin.
server1:18697:18712 [0] NCCL INFO ncclCommInitRank comm 0x23622c0 rank 0 nranks 3 cudaDev 0 nvmlDev 0 busId 2000 commId 0x35491327c8228dd0 - Init COMPLETE
#
# out-of-place in-place
# size count type redop root time algbw busbw #wrong time algbw busbw #wrong
# (B) (elements) (us) (GB/s) (GB/s) (us) (GB/s) (GB/s)
128 32 float sum -1 28.39 0.00 0.01 0 27.35 0.00 0.01 0
256 64 float sum -1 29.44 0.01 0.01 0 28.54 0.01 0.01 0
512 128 float sum -1 29.99 0.02 0.02 0 29.66 0.02 0.02 0
1024 256 float sum -1 32.89 0.03 0.04 0 30.64 0.03 0.04 0
2048 512 float sum -1 34.81 0.06 0.08 0 31.87 0.06 0.09 0
4096 1024 float sum -1 37.32 0.11 0.15 0 36.09 0.11 0.15 0
8192 2048 float sum -1 45.11 0.18 0.24 0 43.12 0.19 0.25 0
16384 4096 float sum -1 57.92 0.28 0.38 0 56.98 0.29 0.38 0
32768 8192 float sum -1 72.68 0.45 0.60 0 70.79 0.46 0.62 0
65536 16384 float sum -1 95.77 0.68 0.91 0 93.73 0.70 0.93 0
131072 32768 float sum -1 162.7 0.81 1.07 0 161.5 0.81 1.08 0
262144 65536 float sum -1 177.3 1.48 1.97 0 177.4 1.48 1.97 0
524288 131072 float sum -1 301.4 1.74 2.32 0 302.0 1.74 2.31 0
1048576 262144 float sum -1 557.9 1.88 2.51 0 559.2 1.88 2.50 0
2097152 524288 float sum -1 1089.8 1.92 2.57 0 1092.2 1.92 2.56 0
4194304 1048576 float sum -1 2165.7 1.94 2.58 0 2166.6 1.94 2.58 0
8388608 2097152 float sum -1 4315.7 1.94 2.59 0 4316.1 1.94 2.59 0
16777216 4194304 float sum -1 8528.8 1.97 2.62 0 8529.3 1.97 2.62 0
33554432 8388608 float sum -1 16622 2.02 2.69 0 16610 2.02 2.69 0
67108864 16777216 float sum -1 32602 2.06 2.74 0 32542 2.06 2.75 0
134217728 33554432 float sum -1 63946 2.10 2.80 0 63831 2.10 2.80 0
268435456 67108864 float sum -1 126529 2.12 2.83 0 126412 2.12 2.83 0
536870912 134217728 float sum -1 251599 2.13 2.85 0 251327 2.14 2.85 0
1073741824 268435456 float sum -1 500664 2.14 2.86 0 501911 2.14 2.85 0
2147483648 536870912 float sum -1 1001415 2.14 2.86 0 1000178 2.15 2.86 0
4294967296 1073741824 float sum -1 1999361 2.15 2.86 0 1997380 2.15 2.87 0
server1:18697:18697 [0] NCCL INFO comm 0x23622c0 rank 0 nranks 3 cudaDev 0 busId 2000 - Destroy COMPLETE
server2:20893:20893 [0] NCCL INFO comm 0x2a1af20 rank 1 nranks 3 cudaDev 0 busId 2000 - Destroy COMPLETE
server3:2458:2458 [0] NCCL INFO comm 0x346ffc0 rank 2 nranks 3 cudaDev 0 busId 2000 - Destroy COMPLETE
# Out of bounds values : 0 OK
# Avg bus bandwidth : 1.66163
#
[root@server1 lichao]#
结果详解
- size (B):操作处理的数据的大小,以字节为单位;
- count (elements):操作处理的元素的数量;
- type:元素的数据类型;
- redop:使用的归约操作;
- root:对于某些操作(如 reduce 和 broadcast),这列指定了根节点的编号,值是 -1 表示这个操作没有根节点(all-reduce 操作涉及到所有的节点);
- time (us):操作的执行时间,以微秒为单位;
- algbw (GB/s):算法带宽,以每秒吉字节(GB/s)为单位;
- busbw (GB/s):总线带宽,以每秒吉字节(GB/s)为单位;
- wrong:错误的数量,如果这个值不是 0,那可能表示有一些错误发生。
在这个例子中,你可以看到,当处理的数据量增大时,算法带宽和总线带宽都有所提高,这可能表示 NCCL 能够有效地利用大量的数据。
查看结果时,需要关注如下几点:
1. 数据量增加时,带宽是否会下降(下降明显不符合预期);
2. 更关注带宽的峰值,每次算到的带宽峰值,可以只关注 in 或者 out;
3. 平均值,在数据量递增的情况下,可能无法体现最终的结果;
4. 请确保数据量足够大,可以压到带宽上限(通过调整 b、e 或者 n 选项)。
常用参数及解释
- GPU 数量
- -t,--nthreads 每个进程的线程数量配置, 默认 1;
- -g,--ngpus 每个线程的 GPU 数量,默认 1;
- 数据大小配置
- -b,--minbytes 开始的最小数据量,默认 32M;
- -e,--maxbytes 结束的最大数据量,默认 32M;
- 数据步长设置
- -i,--stepbytes 每次增加的数据量,默认: 1M;
- -f,--stepfactor 每次增加的倍数,默认禁用;
- NCCL 操作相关配置
- -o,--op 指定那种操作为reduce,仅适用于Allreduce、Reduce或ReduceScatter等缩减操作。默认值为:求和(Sum);
- -d,--datatype 指定使用哪种数据类型,默认 : Float;
- 性能相关配置
- -n,--iters 每次操作(一次发送)循环多少次,默认 : 20;
- -w,--warmup_iters 预热迭代次数(不计时),默认:5;
- -m,--agg_iters 每次迭代中要聚合在一起的操作数,默认:1;
- -a,--average <0/1/2/3> 在所有 ranks 计算均值作为最终结果 (MPI=1 only). <0=Rank0,1=Avg,2=Min,3=Max>,默认:1;
- 测试相关配置
- -p,--parallel_init <0/1> 使用线程并行初始化 NCCL,默认: 0;
- -c,--check <0/1> 检查结果的正确性。在大量GPU上可能会非常慢,默认:1;
- -z,--blocking <0/1> 使NCCL集合阻塞,即在每个集合之后让CPU等待和同步,默认:0;
- -G,--cudagraph 将迭代作为CUDA图形捕获,然后重复指定的次数,默认:0;
实验测试
完成硬件、软件的选型和配置后,下一步将进行实践测试。
获取LLaMA-Factory源码包
因为网络问题很难直接通过git clone命令行拉取,建议通过打包下载后自己上传的方式进行:
noone@MacBook-Air Downloads % scp LLaMA-Factory-0.8.3.zip root@10.230.1.13:/tmp
[root@server3 AIGC]# pwd
/home/lichao/AIGC
[root@server3 AIGC]# cp /tmp/LLaMA-Factory-0.8.3.zip ./
[root@server3 AIGC]# unzip LLaMA-Factory-0.8.3.zip
[root@server3 AIGC]# cd LLaMA-Factory-0.8.3
[root@server3 LLaMA-Factory-0.8.3]# ll
总用量 128
drwxr-xr-x 2 root root 83 9月 13 05:04 assets
drwxr-xr-x 2 root root 122 9月 6 08:26 cache
-rw-r--r-- 1 root root 1378 7月 18 19:36 CITATION.cff
drwxr-xr-x 6 root root 4096 9月 13 05:03 data
drwxr-xr-x 4 root root 43 7月 18 19:36 docker
drwxr-xr-x 5 root root 44 7月 18 19:36 evaluation
drwxr-xr-x 10 root root 182 7月 18 19:36 examples
-rw-r--r-- 1 root root 11324 7月 18 19:36 LICENSE
-rw-r--r-- 1 root root 242 7月 18 19:36 Makefile
-rw-r--r-- 1 root root 33 7月 18 19:36 MANIFEST.in
-rw-r--r-- 1 root root 645 7月 18 19:36 pyproject.toml
-rw-r--r-- 1 root root 44424 7月 18 19:36 README.md
-rw-r--r-- 1 root root 44093 7月 18 19:36 README_zh.md
-rw-r--r-- 1 root root 245 7月 18 19:36 requirements.txt
drwxr-xr-x 3 root root 16 9月 6 18:48 saves
drwxr-xr-x 2 root root 219 7月 18 19:36 scripts
-rw-r--r-- 1 root root 3361 7月 18 19:36 setup.py
drwxr-xr-x 4 root root 101 9月 6 08:22 src
drwxr-xr-x 5 root root 43 7月 18 19:36 tests
[root@server3 LLaMA-Factory-0.8.3]#
安装LLaMA-Factory,并进行验证
[root@server3 LLaMA-Factory-0.8.3]# pip install -e ".[torch,metrics]"
[root@server3 LLaMA-Factory-0.8.3]# llamafactory-cli version
[2024-09-23 08:51:28,722] [INFO] [real_accelerator.py:203:get_accelerator] Setting ds_accelerator to cuda (auto detect)
----------------------------------------------------------
| Welcome to LLaMA Factory, version 0.8.3 |
| |
| Project page: https://github.com/hiyouga/LLaMA-Factory |
----------------------------------------------------------
[root@server3 LLaMA-Factory-0.8.3]#
下载训练时所需的预训练模型和数据集
根据当前GPU服务器所配置的GPU硬件规格,选择适合的训练方法、模型和数据集。
GPU型号:NVIDIA GeForce RTX 4060 Ti 16GB
预训练模型:Qwen/Qwen1.5-0.5B-Chat
数据集:identity、alpaca_zh_demo
# Make sure you have git-lfs installed (https://git-lfs.com)
git lfs install
git clone https://hf-mirror.com/Qwen/Qwen1.5-0.5B-Chat
# If you want to clone without large files - just their pointers
GIT_LFS_SKIP_SMUDGE=1 git clone https://hf-mirror.com/Qwen/Qwen1.5-0.5B-Chat
因为网络问题通过命令行很难直接下载,这里使用huggingface的国内镜像站拉取预训练模型数据,并使用“GIT_LFS_SKIP_SMUDGE=1”变量跳过大文件,随后手工下载后再上传。
如果觉得麻烦,也可以安装使用huggingface的命令行工具,下载预训练模型和数据集。同样地,安装完成后,需要配置一些环境变量(使用镜像站hf-mirror.com)来解决网络问题。
1. 安装依赖
[root@server3 LLaMA-Factory-0.8.3]# pip3 install -U huggingface_hub
2. 设置环境变量
[root@server3 LLaMA-Factory-0.8.3]# export HF_ENDPOINT=https://hf-mirror.com
可以写入 ~/.bashrc 永久生效。
3. 确认环境变量生效
[root@server3 LLaMA-Factory-0.8.3]# huggingface-cli env
Copy-and-paste the text below in your GitHub issue.
- huggingface_hub version: 0.24.5
- Platform: Linux-3.10.0-1160.118.1.el7.x86_64-x86_64-with-glibc2.17
- Python version: 3.11.9
- Running in iPython ?: No
- Running in notebook ?: No
- Running in Google Colab ?: No
- Token path ?: /root/.cache/huggingface/token
- Has saved token ?: True
- Who am I ?: richard-open-source
- Configured git credential helpers:
- FastAI: N/A
- Tensorflow: N/A
- Torch: 2.4.0
- Jinja2: 3.1.4
- Graphviz: N/A
- keras: N/A
- Pydot: N/A
- Pillow: 10.4.0
- hf_transfer: N/A
- gradio: 4.43.0
- tensorboard: N/A
- numpy: 1.26.4
- pydantic: 2.9.0
- aiohttp: 3.10.3
- ENDPOINT: https://hf-mirror.com
- HF_HUB_CACHE: /root/.cache/huggingface/hub
- HF_ASSETS_CACHE: /root/.cache/huggingface/assets
- HF_TOKEN_PATH: /root/.cache/huggingface/token
- HF_HUB_OFFLINE: False
- HF_HUB_DISABLE_TELEMETRY: False
- HF_HUB_DISABLE_PROGRESS_BARS: None
- HF_HUB_DISABLE_SYMLINKS_WARNING: False
- HF_HUB_DISABLE_EXPERIMENTAL_WARNING: False
- HF_HUB_DISABLE_IMPLICIT_TOKEN: False
- HF_HUB_ENABLE_HF_TRANSFER: False
- HF_HUB_ETAG_TIMEOUT: 10
- HF_HUB_DOWNLOAD_TIMEOUT: 10
[root@server3 LLaMA-Factory-0.8.3]#
4.1 下载模型
[root@server3 LLaMA-Factory-0.8.3]# huggingface-cli download --resume-download Qwen/Qwen1.5-0.5B-Chat --local-dir ./models/Qwen1.5-0.5B-Chat
4.2 下载数据集
[root@server3 LLaMA-Factory-0.8.3]# huggingface-cli download --repo-type dataset --resume-download alpaca_zh_demo --local-dir ./datasets/alpaca_zh_demo
下载预训练模型
[root@server3 AIGC]# mkdir models
[root@server3 AIGC]# cd models/
[root@server3 models]# GIT_LFS_SKIP_SMUDGE=1 git clone https://hf-mirror.com/Qwen/Qwen1.5-0.5B-Chat
[root@server3 models]# tree -h Qwen1.5-0.5B-Chat/
Qwen1.5-0.5B-Chat/
├── [ 656] config.json
├── [ 661] config.json.raw
├── [ 206] generation_config.json
├── [7.1K] LICENSE
├── [1.6M] merges.txt
├── [1.2G] model.safetensors
├── [4.2K] README.md
├── [1.3K] tokenizer_config.json
├── [6.7M] tokenizer.json
└── [2.6M] vocab.json
0 directories, 10 files
[root@server3 models]#
下载数据集
默认情况下,LLaMA-Factory项目文件下的data目录,自带了一些本地数据集可直接使用。
[root@server3 LLaMA-Factory-0.8.3]# tree -h data/
data/
├── [841K] alpaca_en_demo.json
├── [621K] alpaca_zh_demo.json
├── [ 32] belle_multiturn
│ └── [2.7K] belle_multiturn.py
├── [733K] c4_demo.json
├── [ 13K] dataset_info.json
├── [1.5M] dpo_en_demo.json
├── [833K] dpo_zh_demo.json
├── [722K] glaive_toolcall_en_demo.json
├── [665K] glaive_toolcall_zh_demo.json
├── [ 27] hh_rlhf_en
│ └── [3.3K] hh_rlhf_en.py
├── [ 20K] identity.json
├── [892K] kto_en_demo.json
├── [ 45] mllm_demo_data
│ ├── [ 12K] 1.jpg
│ ├── [ 22K] 2.jpg
│ └── [ 16K] 3.jpg
├── [3.1K] mllm_demo.json
├── [9.8K] README.md
├── [9.2K] README_zh.md
├── [ 27] ultra_chat
│ └── [2.3K] ultra_chat.py
└── [1004K] wiki_demo.txt
4 directories, 20 files
[root@server3 LLaMA-Factory-0.8.3]#
使用准备好的模型与数据集,在单机上进行训练测试
LLaMA-Factory支持通过WebUI微调大语言模型。在完成安装后,我们可以使用WebUI进行快速调测验证,没问题后可使用命令行工具进行多机分布式训练。
[root@server3 LLaMA-Factory-0.8.3]# llamafactory-cli webui
[2024-09-23 17:54:45,786] [INFO] [real_accelerator.py:203:get_accelerator] Setting ds_accelerator to cuda (auto detect)
Running on local URL: http://0.0.0.0:7861
To create a public link, set `share=True` in `launch()`.
使用命令行运行多机分布式训练任务
1. 准备目录
[root@server3 LLaMA-Factory-0.8.3]# mkdir asterun
[root@server3 LLaMA-Factory-0.8.3]# mkdir -p asterun/saves/qwen/full/sft
2. 根据集群环境和训练任务,准备分布式训练的配置文件
[root@server3 LLaMA-Factory-0.8.3]# cat asterun/qwen_full_sft_ds2.yaml
### model
model_name_or_path: /home/lichao/AIGC/models/Qwen1.5-0.5B-Chat
### method
stage: sft
do_train: true
finetuning_type: full
deepspeed: examples/deepspeed/ds_z2_config.json
### dataset
dataset: identity,alpaca_zh_demo
template: llama3
cutoff_len: 1024
max_samples: 1000
overwrite_cache: true
preprocessing_num_workers: 16
### output
output_dir: asterun/saves/qwen/full/sft
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
report_to: tensorboard
logging_dir: asterun/saves/qwen/full/sft/runs
### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 2
learning_rate: 1.0e-4
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
### eval
val_size: 0.1
per_device_eval_batch_size: 1
eval_strategy: steps
eval_steps: 500
[root@server3 LLaMA-Factory-0.8.3]#
3. 用同样的方式,在Server1和Server2上准备运行环境
步骤略。
4. 依次在集群中的3个GPU节点上启动分布式训练任务
主节点rank0:
[root@server3 LLaMA-Factory-0.8.3]# FORCE_TORCHRUN=1 NNODES=3 RANK=0 MASTER_ADDR=172.16.0.13 MASTER_PORT=29500 llamafactory-cli train asterun/qwen_full_sft_ds2.yaml
从节点rank1:
[root@server2 LLaMA-Factory-0.8.3]# FORCE_TORCHRUN=1 NNODES=3 RANK=1 MASTER_ADDR=172.16.0.13 MASTER_PORT=29500 llamafactory-cli train asterun/qwen_full_sft_ds2.yaml
从节点rank2:
[root@server1 LLaMA-Factory-0.8.3]# FORCE_TORCHRUN=1 NNODES=3 RANK=2 MASTER_ADDR=172.16.0.13 MASTER_PORT=29500 llamafactory-cli train asterun/qwen_full_sft_ds2.yaml
推理测试
安装GGUF库
下载llama.cpp源码包到服务器,解压到工作目录
[root@server3 AIGC]# unzip llama.cpp-master.zip
[root@server3 AIGC]# cd llama.cpp-master
[root@server3 llama.cpp-master]# ll
总用量 576
-rw-r--r-- 1 root root 33717 9月 26 11:38 AUTHORS
drwxr-xr-x 2 root root 37 9月 26 11:38 ci
drwxr-xr-x 2 root root 164 9月 26 11:38 cmake
-rw-r--r-- 1 root root 6591 9月 26 11:38 CMakeLists.txt
-rw-r--r-- 1 root root 3164 9月 26 11:38 CMakePresets.json
drwxr-xr-x 3 root root 4096 9月 26 11:38 common
-rw-r--r-- 1 root root 2256 9月 26 11:38 CONTRIBUTING.md
-rwxr-xr-x 1 root root 199470 9月 26 11:38 convert_hf_to_gguf.py
-rwxr-xr-x 1 root root 15993 9月 26 11:38 convert_hf_to_gguf_update.py
-rwxr-xr-x 1 root root 19106 9月 26 11:38 convert_llama_ggml_to_gguf.py
-rwxr-xr-x 1 root root 14901 9月 26 11:38 convert_lora_to_gguf.py
drwxr-xr-x 4 root root 109 9月 26 11:38 docs
drwxr-xr-x 43 root root 4096 9月 26 11:38 examples
-rw-r--r-- 1 root root 1556 9月 26 11:38 flake.lock
-rw-r--r-- 1 root root 7469 9月 26 11:38 flake.nix
drwxr-xr-x 5 root root 85 9月 26 11:38 ggml
drwxr-xr-x 6 root root 116 9月 26 11:38 gguf-py
drwxr-xr-x 2 root root 154 9月 26 11:38 grammars
drwxr-xr-x 2 root root 21 9月 26 11:38 include
-rw-r--r-- 1 root root 1078 9月 26 11:38 LICENSE
-rw-r--r-- 1 root root 50865 9月 26 11:38 Makefile
drwxr-xr-x 2 root root 163 9月 26 11:38 media
drwxr-xr-x 2 root root 4096 9月 26 11:38 models
-rw-r--r-- 1 root root 163 9月 26 11:38 mypy.ini
-rw-r--r-- 1 root root 2044 9月 26 11:38 Package.swift
drwxr-xr-x 3 root root 40 9月 26 11:38 pocs
-rw-r--r-- 1 root root 124786 9月 26 11:38 poetry.lock
drwxr-xr-x 2 root root 4096 9月 26 11:38 prompts
-rw-r--r-- 1 root root 1280 9月 26 11:38 pyproject.toml
-rw-r--r-- 1 root root 528 9月 26 11:38 pyrightconfig.json
-rw-r--r-- 1 root root 28481 9月 26 11:38 README.md
drwxr-xr-x 2 root root 4096 9月 26 11:38 requirements
-rw-r--r-- 1 root root 505 9月 26 11:38 requirements.txt
drwxr-xr-x 2 root root 4096 9月 26 11:38 scripts
-rw-r--r-- 1 root root 5090 9月 26 11:38 SECURITY.md
drwxr-xr-x 2 root root 97 9月 26 11:38 spm-headers
drwxr-xr-x 2 root root 289 9月 26 11:38 src
drwxr-xr-x 2 root root 4096 9月 26 11:38 tests
[root@server3 llama.cpp-master]#
进入gguf-py子目录,安装GGUF库
[root@server3 llama.cpp-master]# cd gguf-py
[root@server3 gguf-py]# ll
总用量 12
drwxr-xr-x 2 root root 40 9月 26 11:38 examples
drwxr-xr-x 2 root root 230 9月 26 11:38 gguf
-rw-r--r-- 1 root root 1072 9月 26 11:38 LICENSE
-rw-r--r-- 1 root root 1049 9月 26 11:38 pyproject.toml
-rw-r--r-- 1 root root 2719 9月 26 11:38 README.md
drwxr-xr-x 2 root root 151 9月 26 11:38 scripts
drwxr-xr-x 2 root root 71 9月 26 11:38 tests
[root@server3 gguf-py]# pip install --editable .
Looking in indexes: https://mirrors.aliyun.com/pypi/simple/
Obtaining file:///home/lichao/AIGC/llama.cpp-master/gguf-py
Installing build dependencies ... done
Checking if build backend supports build_editable ... done
Getting requirements to build editable ... done
Preparing editable metadata (pyproject.toml) ... done
Requirement already satisfied: numpy>=1.17 in /home/lichao/opt/python3.11.9/lib/python3.11/site-packages (from gguf==0.10.0) (1.26.4)
Requirement already satisfied: pyyaml>=5.1 in /home/lichao/opt/python3.11.9/lib/python3.11/site-packages (from gguf==0.10.0) (6.0.2)
Requirement already satisfied: sentencepiece<=0.2.0, >=0.1.98 in /home/lichao/opt/python3.11.9/lib/python3.11/site-packages (from gguf==0.10.0) (0.2.0)
Requirement already satisfied: tqdm>=4.27 in /home/lichao/opt/python3.11.9/lib/python3.11/site-packages (from gguf==0.10.0) (4.66.5)
Building wheels for collected packages: gguf
Building editable for gguf (pyproject.toml) ... done
Created wheel for gguf: filename=gguf-0.10.0-py3-none-any.whl size=3403 sha256=4a0851426e263076c64c9854be9dfe95493844062484d001fddb08c1be5fa2ca
Stored in directory: /tmp/pip-ephem-wheel-cache-iiq8ofh3/wheels/80/80/9b/c6c23d750f4bd20fc0c2c75e51253d89c61a2369247fb694db
Successfully built gguf
Installing collected packages: gguf
Successfully installed gguf-0.10.0
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager, possibly rendering your system unusable.It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv. Use the --root-user-action option if you know what you are doing and want to suppress this warning.
[root@server3 gguf-py]#
模型格式转换
将之前微调训练生成的safetensors格式的模型,转换为gguf格式
[root@server3 gguf-py]# cd ..
[root@server3 llama.cpp-master]# python3 convert_hf_to_gguf.py /home/lichao/AIGC/LLaMA-Factory-0.8.3/asterun/saves/qwen/full/sft
INFO:hf-to-gguf:Loading model: sft
INFO:gguf.gguf_writer:gguf: This GGUF file is for Little Endian only
INFO:hf-to-gguf:Exporting model...
INFO:hf-to-gguf:gguf: loading model part 'model.safetensors'
INFO:hf-to-gguf:output.weight, torch.bfloat16 --> F16, shape = {1024, 151936}
INFO:hf-to-gguf:token_embd.weight, torch.bfloat16 --> F16, shape = {1024, 151936}
INFO:hf-to-gguf:blk.0.attn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.0.ffn_down.weight, torch.bfloat16 --> F16, shape = {2816, 1024}
INFO:hf-to-gguf:blk.0.ffn_gate.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.0.ffn_up.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.0.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.0.attn_k.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.0.attn_k.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.0.attn_output.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.0.attn_q.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.0.attn_q.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.0.attn_v.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.0.attn_v.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.1.attn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.1.ffn_down.weight, torch.bfloat16 --> F16, shape = {2816, 1024}
INFO:hf-to-gguf:blk.1.ffn_gate.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.1.ffn_up.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.1.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.1.attn_k.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.1.attn_k.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.1.attn_output.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.1.attn_q.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.1.attn_q.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.1.attn_v.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.1.attn_v.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.10.attn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.10.ffn_down.weight, torch.bfloat16 --> F16, shape = {2816, 1024}
INFO:hf-to-gguf:blk.10.ffn_gate.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.10.ffn_up.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.10.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.10.attn_k.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.10.attn_k.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.10.attn_output.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.10.attn_q.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.10.attn_q.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.10.attn_v.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.10.attn_v.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.11.attn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.11.ffn_down.weight, torch.bfloat16 --> F16, shape = {2816, 1024}
INFO:hf-to-gguf:blk.11.ffn_gate.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.11.ffn_up.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.11.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.11.attn_k.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.11.attn_k.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.11.attn_output.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.11.attn_q.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.11.attn_q.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.11.attn_v.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.11.attn_v.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.12.attn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.12.ffn_down.weight, torch.bfloat16 --> F16, shape = {2816, 1024}
INFO:hf-to-gguf:blk.12.ffn_gate.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.12.ffn_up.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.12.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.12.attn_k.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.12.attn_k.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.12.attn_output.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.12.attn_q.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.12.attn_q.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.12.attn_v.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.12.attn_v.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.13.attn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.13.ffn_down.weight, torch.bfloat16 --> F16, shape = {2816, 1024}
INFO:hf-to-gguf:blk.13.ffn_gate.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.13.ffn_up.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.13.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.13.attn_k.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.13.attn_k.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.13.attn_output.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.13.attn_q.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.13.attn_q.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.13.attn_v.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.13.attn_v.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.14.attn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.14.ffn_down.weight, torch.bfloat16 --> F16, shape = {2816, 1024}
INFO:hf-to-gguf:blk.14.ffn_gate.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.14.ffn_up.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.14.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.14.attn_k.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.14.attn_k.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.14.attn_output.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.14.attn_q.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.14.attn_q.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.14.attn_v.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.14.attn_v.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.15.attn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.15.ffn_down.weight, torch.bfloat16 --> F16, shape = {2816, 1024}
INFO:hf-to-gguf:blk.15.ffn_gate.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.15.ffn_up.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.15.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.15.attn_k.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.15.attn_k.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.15.attn_output.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.15.attn_q.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.15.attn_q.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.15.attn_v.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.15.attn_v.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.16.attn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.16.ffn_down.weight, torch.bfloat16 --> F16, shape = {2816, 1024}
INFO:hf-to-gguf:blk.16.ffn_gate.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.16.ffn_up.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.16.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.16.attn_k.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.16.attn_k.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.16.attn_output.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.16.attn_q.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.16.attn_q.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.16.attn_v.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.16.attn_v.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.17.attn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.17.ffn_down.weight, torch.bfloat16 --> F16, shape = {2816, 1024}
INFO:hf-to-gguf:blk.17.ffn_gate.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.17.ffn_up.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.17.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.17.attn_k.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.17.attn_k.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.17.attn_output.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.17.attn_q.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.17.attn_q.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.17.attn_v.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.17.attn_v.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.18.attn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.18.ffn_down.weight, torch.bfloat16 --> F16, shape = {2816, 1024}
INFO:hf-to-gguf:blk.18.ffn_gate.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.18.ffn_up.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.18.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.18.attn_k.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.18.attn_k.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.18.attn_output.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.18.attn_q.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.18.attn_q.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.18.attn_v.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.18.attn_v.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.19.attn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.19.ffn_down.weight, torch.bfloat16 --> F16, shape = {2816, 1024}
INFO:hf-to-gguf:blk.19.ffn_gate.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.19.ffn_up.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.19.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.19.attn_k.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.19.attn_k.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.19.attn_output.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.19.attn_q.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.19.attn_q.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.19.attn_v.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.19.attn_v.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.2.attn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.2.ffn_down.weight, torch.bfloat16 --> F16, shape = {2816, 1024}
INFO:hf-to-gguf:blk.2.ffn_gate.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.2.ffn_up.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.2.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.2.attn_k.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.2.attn_k.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.2.attn_output.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.2.attn_q.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.2.attn_q.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.2.attn_v.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.2.attn_v.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.20.attn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.20.ffn_down.weight, torch.bfloat16 --> F16, shape = {2816, 1024}
INFO:hf-to-gguf:blk.20.ffn_gate.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.20.ffn_up.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.20.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.20.attn_k.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.20.attn_k.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.20.attn_output.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.20.attn_q.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.20.attn_q.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.20.attn_v.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.20.attn_v.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.21.attn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.21.ffn_down.weight, torch.bfloat16 --> F16, shape = {2816, 1024}
INFO:hf-to-gguf:blk.21.ffn_gate.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.21.ffn_up.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.21.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.21.attn_k.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.21.attn_k.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.21.attn_output.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.21.attn_q.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.21.attn_q.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.21.attn_v.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.21.attn_v.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.22.attn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.22.ffn_down.weight, torch.bfloat16 --> F16, shape = {2816, 1024}
INFO:hf-to-gguf:blk.22.ffn_gate.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.22.ffn_up.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.22.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.22.attn_k.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.22.attn_k.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.22.attn_output.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.22.attn_q.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.22.attn_q.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.22.attn_v.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.22.attn_v.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.23.attn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.23.ffn_down.weight, torch.bfloat16 --> F16, shape = {2816, 1024}
INFO:hf-to-gguf:blk.23.ffn_gate.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.23.ffn_up.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.23.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.23.attn_k.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.23.attn_k.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.23.attn_output.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.23.attn_q.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.23.attn_q.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.23.attn_v.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.23.attn_v.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.3.attn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.3.ffn_down.weight, torch.bfloat16 --> F16, shape = {2816, 1024}
INFO:hf-to-gguf:blk.3.ffn_gate.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.3.ffn_up.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.3.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.3.attn_k.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.3.attn_k.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.3.attn_output.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.3.attn_q.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.3.attn_q.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.3.attn_v.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.3.attn_v.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.4.attn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.4.ffn_down.weight, torch.bfloat16 --> F16, shape = {2816, 1024}
INFO:hf-to-gguf:blk.4.ffn_gate.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.4.ffn_up.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.4.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.4.attn_k.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.4.attn_k.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.4.attn_output.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.4.attn_q.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.4.attn_q.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.4.attn_v.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.4.attn_v.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.5.attn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.5.ffn_down.weight, torch.bfloat16 --> F16, shape = {2816, 1024}
INFO:hf-to-gguf:blk.5.ffn_gate.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.5.ffn_up.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.5.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.5.attn_k.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.5.attn_k.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.5.attn_output.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.5.attn_q.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.5.attn_q.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.5.attn_v.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.5.attn_v.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.6.attn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.6.ffn_down.weight, torch.bfloat16 --> F16, shape = {2816, 1024}
INFO:hf-to-gguf:blk.6.ffn_gate.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.6.ffn_up.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.6.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.6.attn_k.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.6.attn_k.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.6.attn_output.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.6.attn_q.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.6.attn_q.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.6.attn_v.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.6.attn_v.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.7.attn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.7.ffn_down.weight, torch.bfloat16 --> F16, shape = {2816, 1024}
INFO:hf-to-gguf:blk.7.ffn_gate.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.7.ffn_up.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.7.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.7.attn_k.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.7.attn_k.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.7.attn_output.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.7.attn_q.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.7.attn_q.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.7.attn_v.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.7.attn_v.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.8.attn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.8.ffn_down.weight, torch.bfloat16 --> F16, shape = {2816, 1024}
INFO:hf-to-gguf:blk.8.ffn_gate.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.8.ffn_up.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.8.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.8.attn_k.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.8.attn_k.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.8.attn_output.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.8.attn_q.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.8.attn_q.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.8.attn_v.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.8.attn_v.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.9.attn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.9.ffn_down.weight, torch.bfloat16 --> F16, shape = {2816, 1024}
INFO:hf-to-gguf:blk.9.ffn_gate.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.9.ffn_up.weight, torch.bfloat16 --> F16, shape = {1024, 2816}
INFO:hf-to-gguf:blk.9.ffn_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.9.attn_k.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.9.attn_k.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.9.attn_output.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.9.attn_q.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.9.attn_q.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:blk.9.attn_v.bias, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:blk.9.attn_v.weight, torch.bfloat16 --> F16, shape = {1024, 1024}
INFO:hf-to-gguf:output_norm.weight, torch.bfloat16 --> F32, shape = {1024}
INFO:hf-to-gguf:Set meta model
INFO:hf-to-gguf:Set model parameters
INFO:hf-to-gguf:gguf: context length = 32768
INFO:hf-to-gguf:gguf: embedding length = 1024
INFO:hf-to-gguf:gguf: feed forward length = 2816
INFO:hf-to-gguf:gguf: head count = 16
INFO:hf-to-gguf:gguf: key-value head count = 16
INFO:hf-to-gguf:gguf: rope theta = 1000000.0
INFO:hf-to-gguf:gguf: rms norm epsilon = 1e-06
INFO:hf-to-gguf:gguf: file type = 1
INFO:hf-to-gguf:Set model tokenizer
INFO:gguf.vocab:Adding 151387 merge(s).
INFO:gguf.vocab:Setting special token type eos to 151646
INFO:gguf.vocab:Setting special token type pad to 151643
INFO:gguf.vocab:Setting special token type bos to 151643
INFO:gguf.vocab:Setting chat_template to {% if messages[0]['role'] == 'system' %}{% set system_message = messages[0]['content'] %}{% endif %}{% if system_message is defined %}{{ '<|start_header_id| >system<|end_header_id| >
' + system_message + '<|eot_id| >' }}{% endif %}{% for message in messages %}{% set content = message['content'] %}{% if message['role'] == 'user' %}{{ '<|start_header_id| >user<|end_header_id| >
' + content + '<|eot_id| ><|start_header_id| >assistant<|end_header_id| >
' }}{% elif message['role'] == 'assistant' %}{{ content + '<|eot_id| >' }}{% endif %}{% endfor %}
INFO:hf-to-gguf:Set model quantization version
INFO:gguf.gguf_writer:Writing the following files:
INFO:gguf.gguf_writer:/home/lichao/AIGC/LLaMA-Factory-0.8.3/asterun/saves/qwen/full/sft/Sft-620M-F16.gguf: n_tensors = 291, total_size = 1.2G
Writing: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1.24G/1.24G [00:03< 00:00, 338Mbyte/s]
INFO:hf-to-gguf:Model successfully exported to /home/lichao/AIGC/LLaMA-Factory-0.8.3/asterun/saves/qwen/full/sft/Sft-620M-F16.gguf
[root@server3 llama.cpp-master]# cd /home/lichao/AIGC/LLaMA-Factory-0.8.3/asterun/saves/qwen/full/sft
转换成功后,修改gguf格式的模型名称,方便后需使用辨认
[root@server3 sft]# ll
总用量 2883588
-rw-r--r-- 1 root root 104 9月 23 10:29 added_tokens.json
-rw-r--r-- 1 root root 358 9月 23 10:29 all_results.json
drwxr-xr-x 3 root root 4096 9月 19 09:59 checkpoint-1000
drwxr-xr-x 3 root root 4096 9月 19 10:05 checkpoint-1470
drwxr-xr-x 3 root root 4096 9月 13 11:02 checkpoint-489
drwxr-xr-x 3 root root 4096 9月 19 09:51 checkpoint-500
-rw-r--r-- 1 root root 731 9月 23 10:28 config.json
-rw-r--r-- 1 root root 175 9月 23 10:29 eval_results.json
-rw-r--r-- 1 root root 210 9月 23 10:28 generation_config.json
-rw-r--r-- 1 root root 1671853 9月 23 10:29 merges.txt
-rw-r--r-- 1 root root 1239173352 9月 23 10:28 model.safetensors
-rw-r--r-- 1 root root 1398 9月 23 10:29 README.md
drwxr-xr-x 2 root root 222 9月 23 10:29 runs
-rw-r--r-- 1 root root 1245334112 9月 26 11:58 Sft-620M-F16.gguf
-rw-r--r-- 1 root root 367 9月 23 10:29 special_tokens_map.json
-rw-r--r-- 1 root root 1720 9月 23 10:29 tokenizer_config.json
-rw-r--r-- 1 root root 7028230 9月 23 10:29 tokenizer.json
-rw-r--r-- 1 root root 11984 9月 23 10:28 trainer_log.jsonl
-rw-r--r-- 1 root root 9284 9月 23 10:29 trainer_state.json
-rw-r--r-- 1 root root 6584 9月 23 10:29 training_args.bin
-rw-r--r-- 1 root root 38333 9月 19 10:06 training_eval_loss.png
-rw-r--r-- 1 root root 37022 9月 23 10:29 training_loss.png
-rw-r--r-- 1 root root 218 9月 23 10:29 train_results.json
-rw-r--r-- 1 root root 2776833 9月 23 10:29 vocab.json
[root@server3 sft]# mv Sft-620M-F16.gguf qwen-sft-620M-F16.gguf
安装Ollama
OLLAMA_GPU_OVERHEAD:0 OLLAMA_HOST:http://127.0.0.1:11434 OLLAMA_INTEL_GPU:false OLLAMA_KEEP_ALIVE:5m0s OLLAMA_LLM_LIBRARY: OLLAMA_LOAD_TIMEOUT:5m0s OLLAMA_MAX_LOADED_MODELS:0 OLLAMA_MAX_QUEUE:512 OLLAMA_MODELS:/root/.ollama/models OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:0 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://*] OLLAMA_SCHED_SPREAD:false OLLAMA_TMPDIR: ROCR_VISIBLE_DEVICES: http_proxy: https_proxy: no_proxy:]"
time=2024-09-26T12:04:20.753+02:00 level=INFO source=images.go:753 msg="total blobs: 0"
time=2024-09-26T12:04:20.754+02:00 level=INFO source=images.go:760 msg="total unused blobs removed: 0"
time=2024-09-26T12:04:20.754+02:00 level=INFO source=routes.go:1200 msg="Listening on 127.0.0.1:11434 (version 0.3.12)"
time=2024-09-26T12:04:20.755+02:00 level=INFO source=common.go:135 msg="extracting embedded files" dir=/tmp/ollama316805737/runners
time=2024-09-26T12:04:39.145+02:00 level=INFO source=common.go:49 msg="Dynamic LLM libraries" runners="[cpu cpu_avx cpu_avx2 cuda_v11 cuda_v12 rocm_v60102]"
time=2024-09-26T12:04:39.145+02:00 level=INFO source=gpu.go:199 msg="looking for compatible GPUs"
time=2024-09-26T12:04:39.283+02:00 level=INFO source=types.go:107 msg="inference compute" id=GPU-2d337ad0-020d-0464-2d00-715b0d00c7ba library=cuda variant=v12 compute=8.9 driver=12.4 name="NVIDIA GeForce RTX 4060 Ti" total="15.7 GiB" available="15.6 GiB"
注册模型
打开一个新的terminal
[root@server3 AIGC]# cd LLaMA-Factory-0.8.3/asterun/
[root@server3 asterun]# ll
总用量 4
-rw-r--r-- 1 root root 817 9月 19 09:33 qwen_full_sft_ds2.yaml
drwxr-xr-x 3 root root 18 9月 13 10:28 saves
创建模型的Modelfile文件
[root@server3 asterun]# touch qwen_full_sft_ds2.ollama.Modelfile
[root@server3 asterun]# vim qwen_full_sft_ds2.ollama.Modelfile
[root@server3 asterun]# cat qwen_full_sft_ds2.ollama.Modelfile
FROM /home/lichao/AIGC/LLaMA-Factory-0.8.3/asterun/saves/qwen/full/sft/qwen-sft-620M-F16.gguf
[root@server3 asterun]# cd ../..
使用Modelfile注册模型
[root@server3 AIGC]# ollama create qwen-full-sft -f ./LLaMA-Factory-0.8.3/asterun/qwen_full_sft_ds2.ollama.Modelfile
transferring model data 100%
using existing layer sha256:19d794be57081c1a5aa7e03c4045a0fdc5b8a40f080f0c550ab38033cf0d5d58
creating new layer sha256:c33681b055686143e7d6e0bb0f1054c9910c05c3f4ab16932fbc567a8961929a
writing manifest
success
[root@server3 AIGC]#
使用注册好的模型运行推理服务
[root@server3 AIGC]# ollama run qwen-full-sft
>>> who are you?
<|im_end| >
我是 {{name}},一个由 {{author}} 开发的人工智能助手,我可以帮助用户查询信息、安排日程、提供建议等。
>>> can you speak english?
I am an AI assistant developed by {{author}}.
>>> 好吧,用中文交流吧。
没问题。
>>> 你喜欢中国哪个城市?
每个城市都有其独特的魅力,各具特色,比如:
成都:美食之都,生活悠闲。
北京:历史悠久,文化丰富。
杭州:风景优美,以西湖闻名。
上海:现代化大都市,经济繁荣。
>>> 感谢,再见
好的,我是个人工智能助手,很高兴见到您。
>>> exit
[root@server3 AIGC]#
至此,已完成分布式计算环境的搭建与测试
审核编辑 黄宇
-
gpu
+关注
关注
28文章
4729浏览量
128880 -
AI
+关注
关注
87文章
30725浏览量
268870 -
分布式计算
+关注
关注
0文章
28浏览量
4464 -
大模型
+关注
关注
2文章
2423浏览量
2637
发布评论请先 登录
相关推荐
基于分布式调用链监控技术的全息排查功能
分布式系统的优势是什么?
HarmonyOS应用开发-分布式任务调度
各种分布式电源的电气特性
HDC2021技术分论坛:跨端分布式计算技术初探
HDC2021技术分论坛:跨端分布式计算技术初探
如何高效完成HarmonyOS分布式应用测试?
基于润和DAYU200开发套件的OpenHarmony分布式音乐播放器
满满干货!手把手教你实现基于eTS的分布式计算器
基于分布式电源接入对电网运行的影响
如何借助分布式GPU环境来提升神经网络训练系统的浮点计算能力
openEuler Summit2021之构建欧拉openEuler的分布式能力






 工商网监
工商网监
评论