 视频目标跟踪从0到1,概念与方法
视频目标跟踪从0到1,概念与方法
作者:ANKIT SACHAN来源:AI公园 -ronghuaiyang
导读
从目标跟踪的应用场景,底层模型,组件,类型和具体算法几个方面对目标跟踪做了全方面的介绍,非常好的入门文章。
在今天的文章中,我们将深入研究视频目标跟踪。我们从基础开始,了解目标跟踪的需求,然后了解视觉目标跟踪的挑战和算法模型,最后,我们将介绍最流行的基于深度学习的目标跟踪方法,包括MDNET, GOTURN, ROLO等。本文希望你了解目标检测。
目标跟踪是在视频中随着时间的推移定位移动目标的过程。我们可以简单地问,为什么我们不能在整个视频的每一帧中使用目标检测,然后我们可以再去跟踪目标。这会有一些问题。如果图像有多个物体,那么我们就无法将当前帧中的物体链接到前一帧中。如果你跟踪的物体有几帧不在镜头里,然后重新又出现,我们无法知道它是否是同一物体。本质上,在检测过程中,我们一次只处理一张图像,我们不知道物体的运动和过去的运动,所以我们不能在视频中唯一地跟踪物体。目标跟踪在计算机视觉中有着广泛的应用,如监视、人机交互、医学成像、交通流监测、人类活动识别等。比如FBI想用全市的监控摄像头追踪一名驾车逃跑的罪犯。或者有一个需要分析足球比赛的体育分析软件。或者你想在购物中心的入口处安装一个摄像头,然后计算每个小时有多少人进出,你不仅要对人进行跟踪,还要为每个人创建路径,如下所示。

当检测失败的时候,跟踪可以接替工作
当视频中有一个移动的物体时,在某些情况下,物体的视觉外观并不清楚。在所有这些情况下,检测都会失败而跟踪会成功,因为它也有物体的运动模型和历史记录。下面是一些例子,其中有目标跟踪在工作和目标检测失败的情况:
- 遮挡:所述目标被部分或完全遮挡
- 身份切换:两个目标交叉后,你如何知道哪个是哪个。
- 运动模糊:物体由于物体或相机的运动而被模糊。因此,从视觉上看,物体看起来不再一样了。
- 视点变化:一个物体的不同视点在视觉上可能看起来非常不同,如果没有上下文,仅使用视觉检测就很难识别该物体。
- 尺度变化:物体尺度变化过大可能导致检测失败。
- 背景杂乱:目标附近的背景与目标有相似的颜色或纹理。因此,从背景中分离物体会变得更加困难。
- 光照变化:目标物体附近的光照显著改变。因此,从视觉上识别它可能会变得更加困难。
低分辨率:当ground truth包围框内的像素点非常少时,可能会在视觉上难以检测到目标。
底层模型
目标跟踪是计算机视觉中一个古老而又困难的问题。有各种各样的技术和算法试图用各种不同的方式来解决这个问题。然而,大多数的技术依赖于两个关键的东西:
1. 运动模型
一个好的跟踪器的关键部件之一是理解和建模目标的运动的能力。因此,一个运动模型被开发来捕捉一个物体的动态行为。预测物体在未来帧中的潜在位置,从而减少搜索空间。然而,只有运动模型可能会失败,因为物体可能会不在视频中,或者方向和速度发生突变。早期的一些方法试图了解物体的运动模式并预测它。然而,这些方法的问题是,他们不能预测突然的运动和方向变化。这些技术的例子有光流,卡尔曼滤波,kanad-lucas-tomashi (KLT)特征跟踪,mean shift跟踪。
2. 视觉外观模型
大多数高度精确的跟踪器需要了解他们正在跟踪的目标的外观。最重要的是,他们需要学会从背景中辨别物体。在单目标跟踪器中,仅视觉外观就足以跨帧跟踪目标,而在多目标跟踪器中,仅视觉外观是不够的。
跟踪算法的几个组件
一般来说,目标跟踪过程由四个模块组成:
1、目标初始化:在此阶段,我们需要通过在目标周围绘制一个边框来定义目标的初始状态。我们的想法是在视频的初始帧中绘制目标的边界框,跟踪器需要估计目标在视频剩余帧中的位置。
2、外观建模:现在需要使用学习技术学习目标的视觉外观。在这个阶段,我们需要建模并了解物体在运动时的视觉特征、包括在各种视点、尺度、光照的情况下。
3、运动估计:运动估计的目的是学习预测后续帧中目标最有可能出现的区域。
4、目标定位:运动估计给出了目标可能出现的区域,我们使用视觉模型扫描该区域锁定目标的确切位置。一般来说,跟踪算法不会尝试学习目标的所有变化。因此,大多数跟踪算法都比目标检测快得多。
跟踪算法的类型
1. 基于检测与不需要检测的跟踪器
1.1 基于检测的跟踪:将连续的视频帧给一个预先训练好的目标检测器,该检测器给出检测假设,然后用检测假设形成跟踪轨迹。它更受欢迎,因为可以检测到新的目标,消失的目标会自动终止。在这些方法中,跟踪器用于目标检测失败的时候。在另一种方法中,目标检测器对每n帧运行,其余的预测使用跟踪器完成。这是一种非常适合长时间跟踪的方法。1.2 不需要检测的跟踪:不需要检测的跟踪需要手动初始化第一帧中固定数量的目标。然后在后续的帧中定位这些目标。它不能处理新目标出现在中间帧中的情况。
2. 单目标和多目标跟踪器
2.1 单目标跟踪:即使环境中有多个目标,也只跟踪一个目标。要跟踪的目标由第一帧的初始化确定。2.2 多目标跟踪:对环境中存在的所有目标进行跟踪。如果使用基于检测的跟踪器,它甚至可以跟踪视频中间出现的新目标。
3. 在线和离线跟踪器
3.1 离线跟踪器:当你需要跟踪已记录流中的物体时,使用离线跟踪器。例如,如果你录制了对手球队的足球比赛视频,需要进行战略分析。在这种情况下,你不仅可以使用过去的帧,还可以使用未来的帧来进行更准确的跟踪预测。3.2 在线跟踪器:在线跟踪器用于即时预测,因此,他们不能使用未来帧来改善结果。
4. 基于学习和基于训练的策略
4.1 在线学习跟踪器:这些跟踪器通常使用初始化帧和少量后续帧来了解要跟踪的目标。这些跟踪器更通用因为你可以在任何目标周围画一个框并跟踪它。例如,如果你想在机场跟踪一个穿红衬衫的人,你可以在一个或几个帧内,在这个人周围画一个边界框,跟踪器通过这些框架了解目标物体,并继续跟踪那个人。
在线学习跟踪器的核心思想是:中心的红色方框由用户指定,以它为正样本,所有围绕着目标的方框作为负样本,训练一个分类器,学习如何将目标从背景中区分出来。
4.2 离线学习跟踪器:这些跟踪器的训练只在离线进行。与在线学习跟踪器不同,这些跟踪器在运行时不学习任何东西。这些跟踪器在线下学习完整的概念,也就是说,我们可以训练跟踪器来识别人。然后这些跟踪器可以用来连续跟踪视频流中的所有人。
流行的跟踪算法
OpenCV的跟踪API中集成了很多传统的(非深度学习的)跟踪算法。相对而言,大多数跟踪器都不是很准确。但是,有时它们在资源有限的环境(如嵌入式系统)中运行会很有用。如果你不得不使用一个,我建议使用核相关过滤器(KCF)跟踪器。然而,在实践中,基于深度学习的跟踪器在准确性方面远远领先于传统跟踪器。因此,在这篇文章中,我将讨论用于构建基于AI的跟踪器的三种关键方法。
1. 基于卷积神经网络的离线训练跟踪器
这是早期的一系列跟踪器之一,它将卷积神经网络的识别能力应用于视觉目标跟踪任务。GOTURN就是一种基于卷积神经网络的离线学习跟踪器,它根本不用在线学习。首先,跟踪器使用成千上万的视频训练一般目标的跟踪。现在,这个跟踪器可以用来毫无问题地跟踪大多数目标即使这些目标不属于训练集。
GOTURN可以在GPU驱动的机器上运行非常快,即100fps。GOTURN已经集成到OpenCV跟踪API(contrib部分)中。在下面的视频链接中,原作者展示了GOTURN的能力。
2. 基于卷积神经网络的在线训练跟踪器
这些是使用卷积神经网络的在线训练跟踪器。其中一个例子就是多域网络(MDNet),它是VOT2015挑战赛的获胜者。由于卷积神经网络的训练在计算上非常昂贵,所以这些方法在部署期间必须使用较小的网络以快速训练。然而,较小的网络并没有太多的区分能力。一种选择是我们训练整个网络,但在推理过程中,我们使用前几层作为特征提取器,也就是说,我们只改变在线训练的最后几层的权值。因此,我们用CNN作为特征提取器,最后几层可以快速在线训练。本质上,我们的目标是训练一个能区分目标和背景的通用多域CNN。然而,这在训练中带来了一个问题,一个视频的目标可能是另一个视频的背景,这只会让我们的卷积神经网络混淆。因此,MDNet做了一些聪明的事情。它将网络重新安排为两部分:第一部分是共享部分,然后有一部分是独立于每个域的。每个域意味着一个独立的训练视频。首先在k个域上迭代训练网络,每个域都在目标和背景之间进行分类。这有助于我们提取独立于视频的信息,以便更好地学习跟踪器的通用表示。
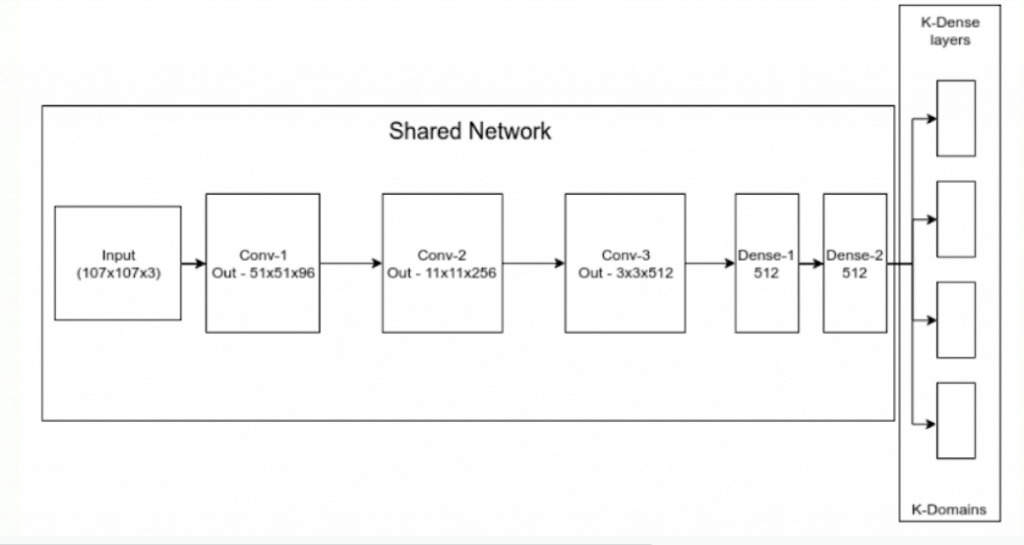
经过训练,去除领域特定的二分类层,我们得到了一个特征提取器(上文共享网络),它可以以通用的方式区分任何目标和背景。在推理(生产)过程中,最初的共享部分被用作特征提取器,删除特定的领域层,并在特征提取器之上添加二分类层。这个二分类层是在线训练的。在每一步中,通过随机抽样的方式搜索前一个目标状态周围的区域来寻找目标。MDNet是一种最精确的基于深度学习的在线训练,不需要检测,单目标跟踪。
3. 基于LSTM+ CNN的基于视频的目标跟踪器
另一类目标跟踪器非常流行,因为它们使用长短期记忆(LSTM)网络和卷积神经网络来完成视觉目标跟踪的任。循环YOLO (ROLO)就是这样一种单目标、在线、基于检测的跟踪算法。该算法使用YOLO网络进行目标检测,使用LSTM网络进行目标轨迹检测。LSTM与CNN的结合是厉害的,原因有二。a) LSTM网络特别擅长历史模式的学习,特别适合于视觉目标跟踪。b) LSTM网络的计算成本不是很高,因此可以构建非常快速的真实世界跟踪器。
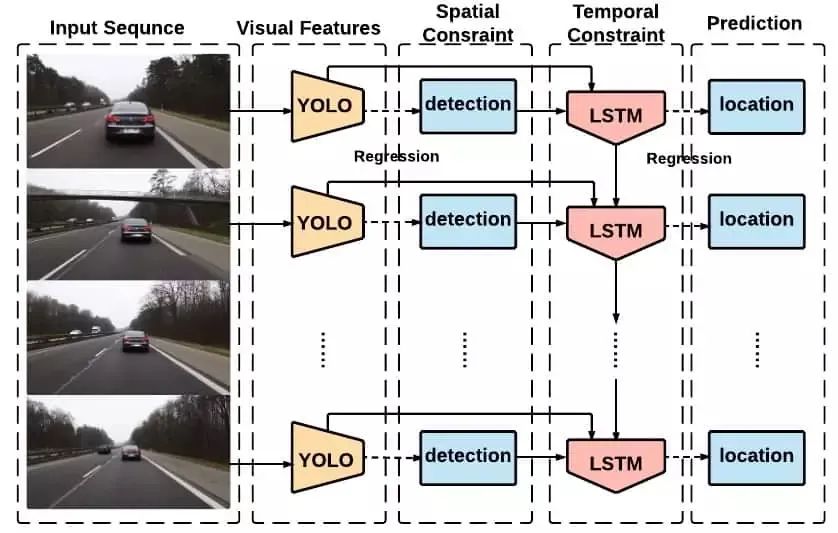
YOLO INPUT – 原始输入帧
YOLO OUTPUT– 输入帧中包围框坐标的特征向量
LSTM INPUT – 拼接(图像特征,包围框坐标)
LSTM OUTPUT– 被跟踪目标的包围框坐标上面的图我们这样理解:
- 输入帧通过YOLO网络。
- 从YOLO网络得到两个不同的输出(图像特征和边界框坐标)
- 这两个输出送到LSTM网络
LSTM输出被跟踪目标的轨迹,即包围框
初步的位置推断(来自YOLO)帮助LSTM注意某些视觉元素。ROLO探索了时空上的历史,即除了地理位置的历史,ROLO还探索了视觉特征的历史。即使当YOLO的检测是有缺陷的,比如运动模糊,ROLO也能保持稳定跟踪。此外,当目标物体被遮挡时,这样的跟踪器不太会失败。最近,有更多基于LSTM的目标跟踪器,它们通过许多改进比ROLO好得多。但是,我们在这里选择了ROLO,因为它简单且容易理解。希望这篇文章能让你对视觉目标跟踪有一个很好的理解,并对一些成功的关键目标跟踪方法有一些见解。
英文原文:https://cv-tricks.com/object-tracking/quick-guide-mdnet-goturn-rolo/
-
视频
+关注
关注
6文章
1942浏览量
72883 -
目标跟踪
+关注
关注
2文章
88浏览量
14881 -
深度学习
+关注
关注
73文章
5500浏览量
121107
发布评论请先 登录
相关推荐
基于OPENCV的运动目标跟踪实现
视频运动目标跟踪系统设计

视频序列中运动目标检测与跟踪的方法有哪些详细资料说明






 工商网监
工商网监
评论