 CNN, RNN, GNN和Transformer模型的统一表示和泛化误差理论分析
CNN, RNN, GNN和Transformer模型的统一表示和泛化误差理论分析
背景介绍

本文是基于我们之前的 RPN(Reconciled Polynomial Network)研究的后续工作。在此前的研究中,我们提出了 RPN 这一通用模型架构,其包含三个组件函数:数据扩展函数、参数调和函数和剩余函数。
我们先前的研究表明,RPN 在构建不同复杂性、容量和完整性水平的模型方面具有很强的通用性,同时可以作为统一多种基础模型(包括 PGM、核 SVM、MLP 和 KAN)的框架。
然而,先前的 RPN 模型基于以下假设:训练批次中的数据实例是独立同分布的。此外,在每个数据实例内部,RPN 还假定所涉及的数据特征彼此独立,并在扩展函数中分别处理这些数据特征。
不过,现实数据往往存在比较强的相互依赖关系,这种依赖关系既存在于样本之间,也存在样本内部各个数据特征之间。
如上图中 (a)-(d) 所示, 对于图像、语言、时间序列和图等复杂且具有相互依赖的数据,这使得先前 RPN 模型的独立假设不成立。如果像先前的 RPN 模型那样忽略这些数据的相互依赖性,学习性能将显著下降。
RPN 2 模型结构

为了解决上面提到的问题,在本文中,我们重新设计了 RPN 架构,提出了新的RPN 2(即Reconciled Polynomial Network 2.0)模型。如上图中所示,RPN 2 引入了一个全新的组件——数据依赖函数,用于显式建模数据实例和数据特征之间的多种依赖关系。
这里需要解释一下,虽然我们在本文中将该组件称为“依赖函数(interdependence function)”,但实际上,该函数捕获了输入数据中的多种关系,包括结构性依赖、逻辑因果关系、统计相关性以及数值相似性或差异性等。
在模型架构方面,如上图所示,RPN 2由四个组成函数构成:数据扩展函数(data expansion function)、数据依赖函数(data interdependence function)、参数调和函数(parameter reconciliation function)、和余项函数(remainder function)。数据扩展函数:根据数据扩展函数的定义,RPN 2 将数据向量从输入空间投射到中间隐层(更高维度)空间,投射后的数据将由新空间中的新的基向量表示。数据依赖函数:根据数据和底层模态结构信息,RPN 2 将数据投射到依赖函数空间,投射后的数据分布能够有效地获取数据样本和特征之间的相互依赖关系。参数调和函数:为了应对数据扩展带来的“维度灾难”问题,RPN 2 中的参数调和函数将一组减少的参数合成为一个高阶参数矩阵。这些扩展的数据向量通过与这些生成的调和参数的内积进行多项式集成,从而将这些扩展的数据向量投射回所需的低维输出空间。余项函数:此外,余数函数为 RPN 2 提供了额外的补充信息,以进一步减少潜在的近似误差。
RPN 2 深度和广度的模型结构

RPN 2 提供了灵活的模型设计和结构,并且允许用户搭建不同深度和广度的模型结构。
上图展示了 RPN 2 的多层(K层)架构,每一层包含多个头部(multi-head)用于函数学习,这些头部的输出将被融合在一起。右侧子图展示了 RPN 2 头部的详细架构,包括数据变换函数、多通道参数调和函数、余项函数及其内部操作。
属性和实例的相互依赖函数会计算相互依赖矩阵,该矩阵将应用于输入数据批次,位置可以是在数据变换函数之前或之后。虚线框内黄色圆角矩形表示可选的数据处理函数(例如激活函数和归一化函数),这些函数可作用于输入、扩展以及输出数据。
多模态数据底层结构和依赖函数

本文还专门分析了几种常见数据的底层模态结构,包括图像、点云、语言、时序、和各类图结构数据。如下图所示:
grid:图像和点云表示为网格结构数据,其中节点表示像素和体素,连边表示空间位置关系;
chain:语言和时间序列数据表示为链式结构数据,其中节点表示词元和数值,连边表示顺序关系;
graph:分子化合物和在线社交网络表示为图结构数据,其中节点表示原子和用户,连边表示化学键和社交连接。
4.1 图像和点云数据几何依赖函数
对于图像和点云,每个 pixel (或者 voxel)之间的依赖关系往往存在于图像和点云数据的局部。换而言之,我们可以从输入的图像和点云数据中划分出局部的 patch 结构,用来描述 pixel 和 voxel 之间的依赖范围。
在传统模型中,这种 patch 的形状往往需要认为定义,其形状可以是cuboid shape,cylinder shape,sphere shape。而从 grid 中定义 pixel (或者 voxel)依赖范围的过程可以表示为 patch packing 这一经典几何学问题。
取决于 patch 的形状,本文提出了多中 packing 的策略用来定义依赖函数,以平衡获取输入数据信息的完整度和避免数据冗余。

4.2 语言和时序数据拓扑依赖函数
除了基于 grid 的几何依赖函数之外,本文还介绍了基于 chain 和 graph 的拓扑依赖函数。链式结构依赖函数和多跳链式依赖函数主要用于建模数据中的顺序依赖关系,这种关系广泛存在于自然语言、基因序列、音频记录和股票价格等数据中。
基于序列数据,本文定义了多种基于 chain 结构的拓扑 single-hop 和 multi-hop 的依赖函数。其中 single-hop chain 结构的拓扑依赖函数分为单向和双向两种。如下图所示,单向依赖强调元素仅依赖于前一个,而双向依赖则考虑元素同时依赖于前后邻居,从而捕捉更全面的上下文信息。
为了高效建模长链数据中的多跳依赖关系,multi-hop chain 结构的拓扑依赖函数引入了跳数(hop)参数,直接描述链中某一元素与多跳范围内其他元素的信息交互。同时,通过累积多跳函数聚合多个跳数的信息,进一步扩展了特征捕获范围。

4.3 图结构数据拓扑依赖函数
不仅如此,如下图所示,本文还提出了基于 graph 结构的拓扑依赖函数。图结构依赖函数和基于 PageRank 的图结构依赖函数旨在建模复杂数据之间的广泛依赖关系,特别是以图为基础的数据,如社交网络、基因互动网络等。
在图结构依赖函数中,数据的依赖关系被表示为一个图 G=(V,E),其中节点表示属性或数据实例,边表示它们之间的依赖关系,对应的依赖矩阵 A 则是图的邻接矩阵。基于该图结构,函数通过矩阵运算建模节点之间的多跳依赖关系,并引入累积多跳函数以整合多层次的信息交互。
进一步地,基于 PageRank 的图依赖函数利用图的随机游走思想,通过收敛矩阵高效地建模全局的长距离依赖关系,并支持多种矩阵归一化策略以增强计算的稳定性和灵活性。

RPN 2 依赖函数列表
除了上述提到的依赖函数之外,本文还提出了多中依赖函数用来建模多种类型数据之间的依赖关系。通过有效地使用这些依赖函数和其他函数,我们可以构建更加有效的模型架构,使 RPN 2 能够应对广泛的学习挑战。
在本文中,我们总共提出了 9 大类,50 多种的数据依赖函数,部分依赖函数的表示和基本信息都总结在了上面的列表中。

深度学习模型的统一表示:CNN, RNN, GNN 和 Transformer
RPN 实现了丰富的功能函数,具体列表如上图所示。通过组合使用上述功能函数,RPN 2 不仅可以构建功能强大的模型结构,并且可以统一现有基础模型的表示,包括 CNN,RNN,GNN 和 Transformer 模型。


实验验证
为了验证提出的 RPN 2 模型的有效性,本文通过大量的实验结果和分析,证明了 RPN 2 在多种 Function Learning Task 上的有效性。
在本文中,具体的实验任务包括:离散图片和文本分类,时序数据预测,和图结构数据学习等。7.1 离散图片和文本分类在本文中,我们在离散图片和文本数据集上测试了 RPN 2 的实验效果,包括:
MNIST 图片数据集
CIFAR10 图片数据集
IMDB 文本数据集
SST2 文本数据集
AGNews 文本数据集
我们不仅跟先前的 RPN 1 模型进行了对比,也和传统的 MLP 和 CNN/RNN 模型进行了对比,具体结果如下表所示:

Note: 本文实验所使用的数据集,都没有使用基于 flipping,rotation 等技术进行数据增强。上表展示了各个方法在多个数据集上分类的 Accuracy score。
7.2 图片数据依赖扩展
对于图片数据,RPN 2 使用了基于 cylinder patch shape 的依赖函数。下图也展示了部分图片基于 RPN 2 所学得的数据表示,其中图片中的每个 pixel 都被扩展成了一个 cylinder patch shape,每个 cylinder patch 包含了每个 pixel 周围的有效的 context 信息。

7.3 时序数据预测
RPN 2 也可以有效地拟合时序数据,本文使用了四个时序数据集来验证 RPN 2 在时序数据拟合和预测的有效性,包括:
Stock market dataset
ETF market dataset
LA traffic record
Bay traffic record
如下表所示,通过使用 chain 结构的依赖函数,RPN 2 可以有效的获取时序数据之间的依赖关系,并且在各个数据集上都获得有效的学习结果。

Note: 上表中的结果是各个方法在几个时序数据集上预测结果的 MSE。
图结构数据学习
为了验证 RPN 2 在图结构数据上的有效性,本文也提供了各个方法在 graph 结构数据上的学习结果,包括:
Cora graph
Citeseer graph
Pubmed graph
如下表所示,基于 graph 依赖函数和复合依赖函数(包括 graph 和 bilinear 依赖函数),RPN 2 在多个 graph 数据集上都可以获得比 GCN 都优的节点分类的结果。

Note: 上表中的结果是各个方法在几个 graph 数据集上 node 分类结果的 Accuracy。
于RPN 2的模型泛化误差分析
除了实验验证之外, 本文还提供了基于 RPN 2 的模型泛化误差的理论分析,其分析结果对目前主流的深度模型(例如 CNN, RNN, GNN 和 Transformer)都适用。
本文的模型泛化误差是基于给定的数据集 D 来进行分析,其中 D 的一部分可以作为训练集用来进行模型训练,我们可以定义模型产生的误差项如下图所示:

本文中,模型泛化误差是指 ,即模型在未见到的数据样本上所产生的误差和在训练数据样本上产生的误差的差别:

9.1 基于VC-Dimension泛化误差分析基于 RPN 2 的模型结构,我们定义了模型的 VC-Dimension 如下图所示:
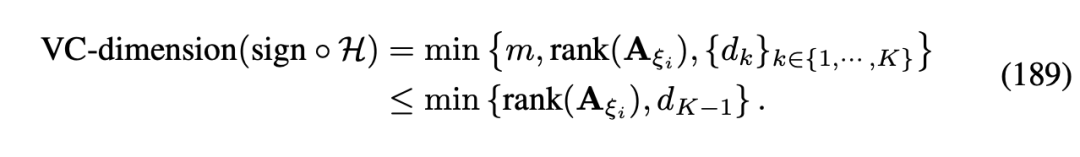
根据所获得的 VC-Dimension 我们定义了 RPN 2 模型的泛化误差如下图所示:
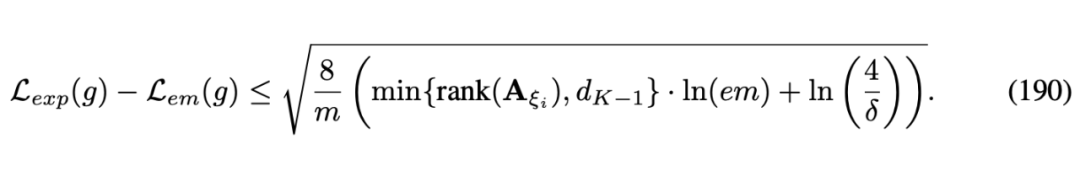
9.2 基于Rademacher Complexity泛化误差分析
除了 VC-dimension 之外,我们还基于 Rademacher Complexity 理论分析了模型的泛化误差。相比 VC-dimension,Rademacher Complexity 不仅仅考虑了 RPN 2 模型结构,还考虑了输入数据对泛化误差的影响。
基于提供的 RPN 2 模型,我们定义了模型 Rademacher Complexity 如下图所示:

根据定义的 Rademacher Complexity,我们进一步分析了 RPN 2 泛化误差如下图所示:

上述模型泛化误差分析不仅仅可以从理论上解释现有模型表现的区别,也为将来模型的设计提供了一下启示,特别是针对依赖函数的设计。
RPN 2讨论:优点,局限性,以及后续工作10.1 RPN 2优点
本文通过引入建模属性和实例间关系的数据依赖函数,对 RPN 2 模型架构进行了重新设计。基于实验结果和理论分析,所提出的依赖函数显著提升了 RPN 2 模型在处理复杂依赖数据时的学习能力,具体贡献包括以下三方面:
理论贡献:与假设数据独立同分布的旧版模型不同,新设计的 RPN 2 模型通过一组基于输入数据批次的依赖函数,能够有效捕捉属性与实例之间的依赖关系,从而大幅扩展模型的建模能力。
此外,本文提供的理论分析(基于 VC 维和 Rademacher 复杂度)展示了如何定义最优依赖函数以减少泛化误差。这些依赖函数还从生物神经科学角度vwin 了神经系统的某些补偿功能,为功能学习任务提供新的启发。
-
函数
+关注
关注
3文章
4327浏览量
62567 -
模型
+关注
关注
1文章
3226浏览量
48804
原文标题:大一统2.0!CNN, RNN, GNN和Transformer模型的统一表示和泛化误差理论分析
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
RNN与LSTM模型的比较分析
Transformer能代替图神经网络吗
CNN与RNN的关系
rnn是什么神经网络模型
NLP模型中RNN与CNN的选择
CNN模型的基本原理、结构、训练过程及应用领域
深度神经网络模型cnn的基本概念、结构及原理
【大规模语言模型:从理论到实践】- 阅读体验
【大规模语言模型:从理论到实践】- 每日进步一点点
大语言模型:原理与工程时间+小白初识大语言模型
【大语言模型:原理与工程实践】大语言模型的基础技术
大语言模型背后的Transformer,与CNN和RNN有何不同






 工商网监
工商网监
评论