 一文详解Arm架构Armv9.6-A中的最新功能
一文详解Arm架构Armv9.6-A中的最新功能
作者:Arm 架构与技术部产品管理总监 Martin Weidmann
Arm CPU 是当今人工智能 (AI) 赋能软件的关键,它可解释、处理和执行指令。Arm 指令集架构 (ISA) 作为硬件和软件的接口,指示处理器做什么和怎么做。Arm ISA 持续演进以满足现代计算的需求,包括 AI 的兴起、机器学习 (ML) 和芯粒 (chiplet) 技术的使用,以及应对高级安全威胁。持续创新确保了 Arm 架构的普及性、普适性能、出色能效、安全性和开发者灵活性。
为了确保开发工作能紧跟快速发展的市场步伐,Arm 投入了大量时间来审视未来的计算需求,并与其庞大且独特的生态系统明确其理解。在打造和发布更新的 ISA 时,结合专业知识与反馈意见,以确保能有针对性地满足需求。
此系列文章每年发布一次,概述了当年度 Arm A 系列架构的主要新增功能,并随附完整的指令集和系统寄存器文档,2024 年为 Armv9.6-A。
想要了解去年的架构扩展,可阅读《Arm A 系列架构 2023 扩展》。接下来,就让我们一同来了解今年的一些新增功能。
利用结构化稀疏性和
四分块操作提高 SME 效率
矩阵运算用于加权特征和计算预测值,是当今许多重要工作负载(包括 AI 和 ML)的基础。Armv9-A 中的可伸缩矩阵扩展 (SME) 大大提高了 Arm CPU 上矩阵乘法的处理速度和效率。借助 SME,可以同时对多个值进行计算,数据整理和重用的效率更高,而且还支持更多的数据类型和更有效的数据压缩。
SME 通过使用量化技术,降低了 ML 模型的计算复杂度。这不仅减少了内存需求,降低了能耗,还使模型可适用于移动设备。SME2 在量化方面又更进一步,它为在 CPU 上运行需要以吞吐量为导向操作的各类应用引入了 Streaming 模式。2024 扩展基于 SME2 构建,新增了对 2:4 结构化稀疏性 (structured sparsity) 和四分块 (quarter tile) 操作的支持。
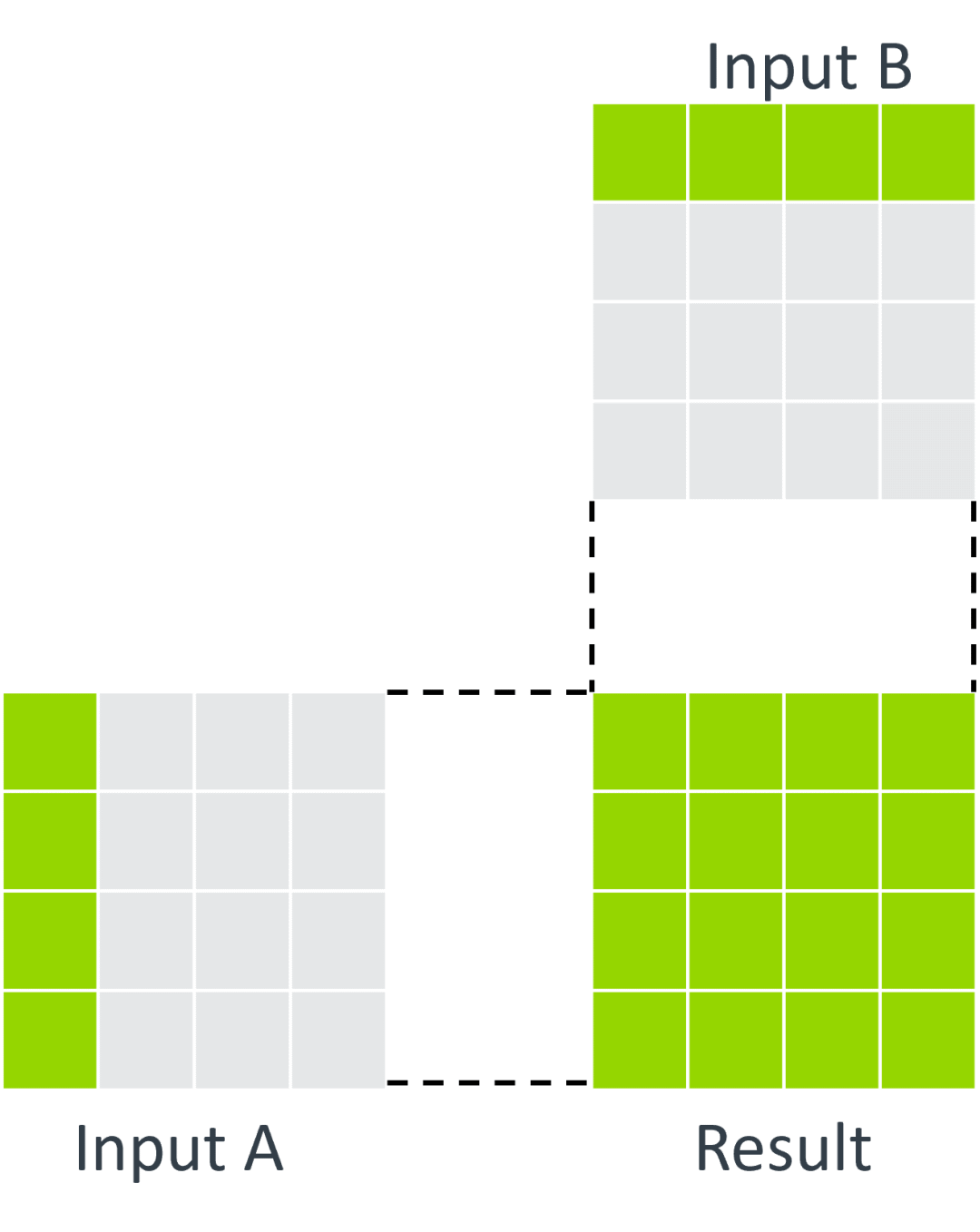
从四分块操作开始,这些操作旨在提高 SME 处理小矩阵时的效率。现有的 SME 运算支持外积运算,使用一对输入向量来计算结果矩阵:
为了更好地支持较小的矩阵,四分运算允许将输入视为来自四个不同的矩阵:
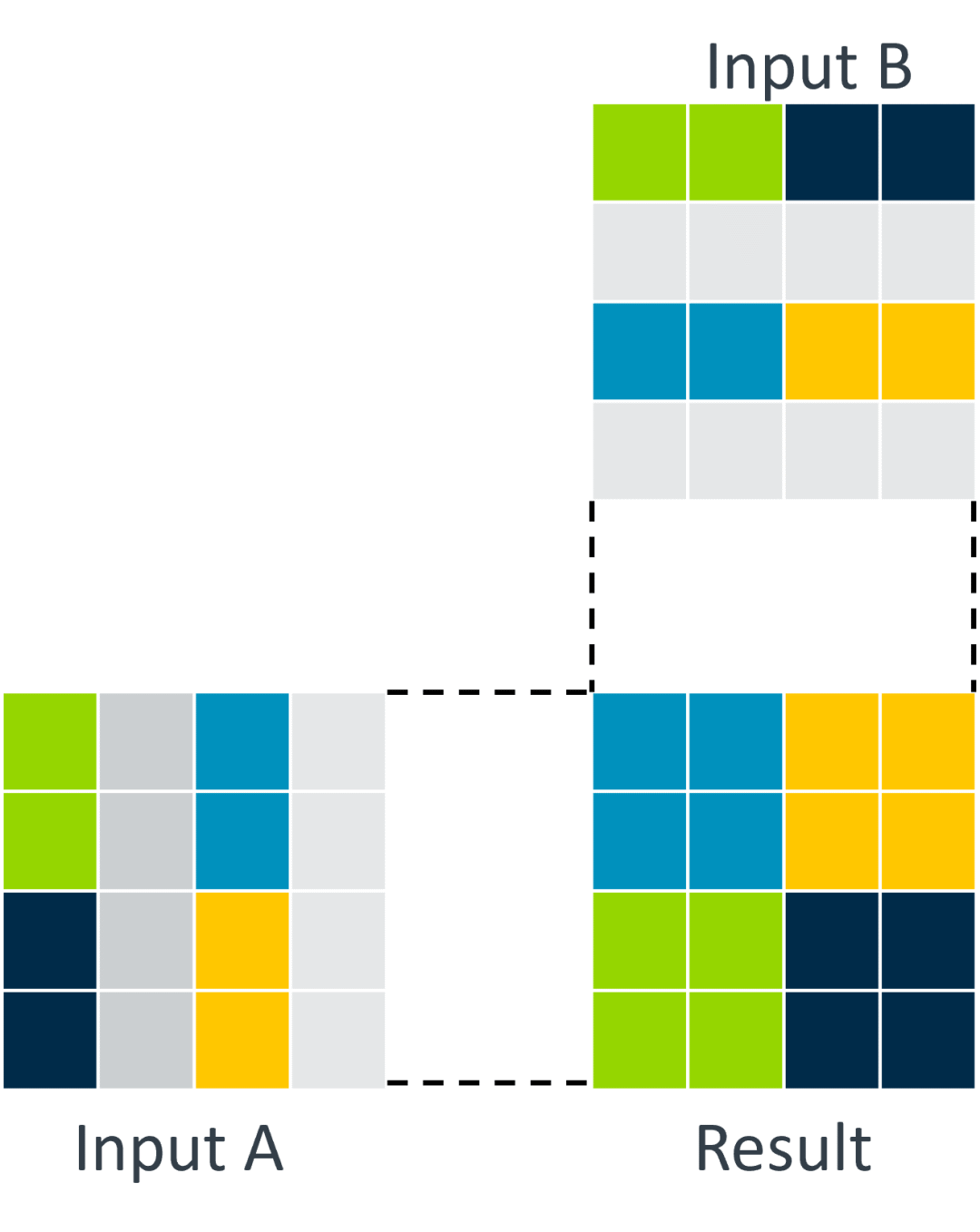
2024 扩展带来的另一项改进与稀疏性有关。在下面的示例中,一个包含激活数据的输入矩阵与另一个包含权重的矩阵相乘。权重矩阵中的一些元素是未使用的(零),不会影响输出。
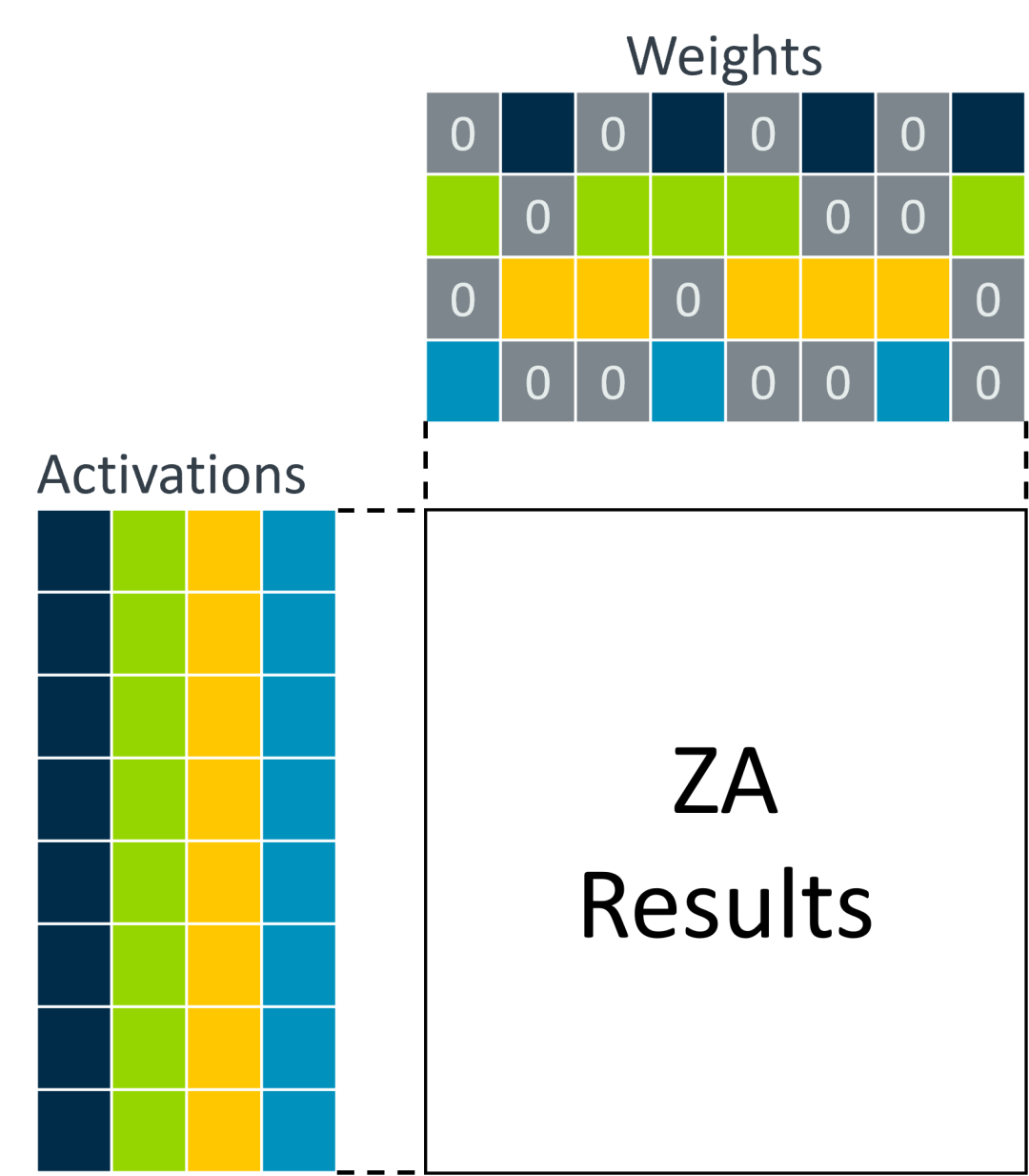
这带来了两个效率低下的问题:
获取不需要的数据
执行不改变结果的乘法累加
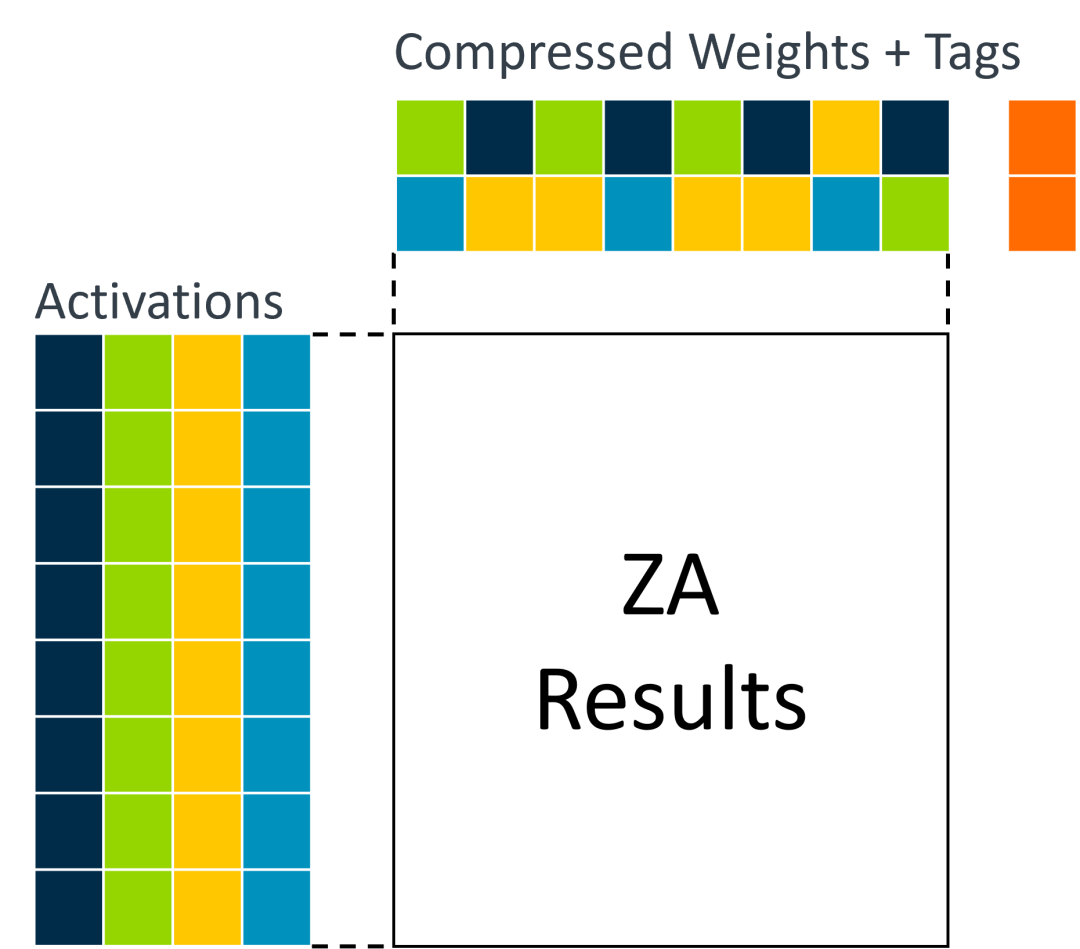
新的结构化稀疏性指令可以解决这以上两个问题。在前面的例子中,权重可以用元数据标签进行压缩,它描述如何解压缩数据。

这种方法的优点是既能优化权重的内存占用,又能优化获取权重进行处理所需的带宽。权重可以在处理器中解压缩,然后用于计算。不过,为了避免不必要的多重累积,新指令允许将压缩数据直接用作输入。
利用 MPAM Domain 支持芯粒
和多芯片 SoC 上的共享内存系统
芯粒具有更高的系统可组合性和性能扩展性,因此可适用于 AI 和加速计算。要想大规模采用芯粒技术,互操作性必不可少,这需要通过芯粒接口和协议的标准化来实现。
Arm 正在通过旨在提供通用语言和降低碎片化风险的标准,加速生态系统向基于芯粒的系统级芯片 (SoC) 演进。Arm 的芯粒系统架构 (Chiplet System Architecture, CSA)将基于 Arm 架构的系统划分为多个芯粒,包括其高级属性,以定义可标准化和复用的芯粒类型。AMBA CHI C2C 利用了现有的片上 AMBA CHI 协议,并定义了其打包方式,使其能够在芯粒间传输。
这些举措将加速向提供专用和可互操作芯粒的多供应商市场发展。开放的芯粒市场将使 OEM 能够实现更高水平的定制和集成,而无需承担开发和制造单芯片设计所带来的成本。目前,芯粒的优势是通过垂直集成设计实现的。Armv9-A 的 2024 扩展考虑了这种新的芯片方法以及如何在它们之间管理资源。
当今的许多计算需求都是通过共享内存计算机系统来获得满足的,在这些系统中,多个应用或多个虚拟机 (VM) 同时运行。为支持此类系统,Armv8.4-A 引入了内存系统资源分区和监控 (Memory System Resource Partitioning and Monitoring, MPAM) 扩展。MPAM 可以控制对共享资源使用情况进行监控和分区。
MPAM 使用分区编号 (PARTID) 来识别每次内存访问与哪个软件实体相关联。该 PARTID 与内存访问一起传输,以便下游内存系统组件 (MSC) 实施分区策略。
2024 年增加了 MPAM Domain,以更好地支持多芯粒和多芯片系统上的共享内存计算机系统。MPAM Domain 允许系统的不同部分使用不同的 PARTID 命名空间,并在访问跨越域边界时进行 PARTID 转换。
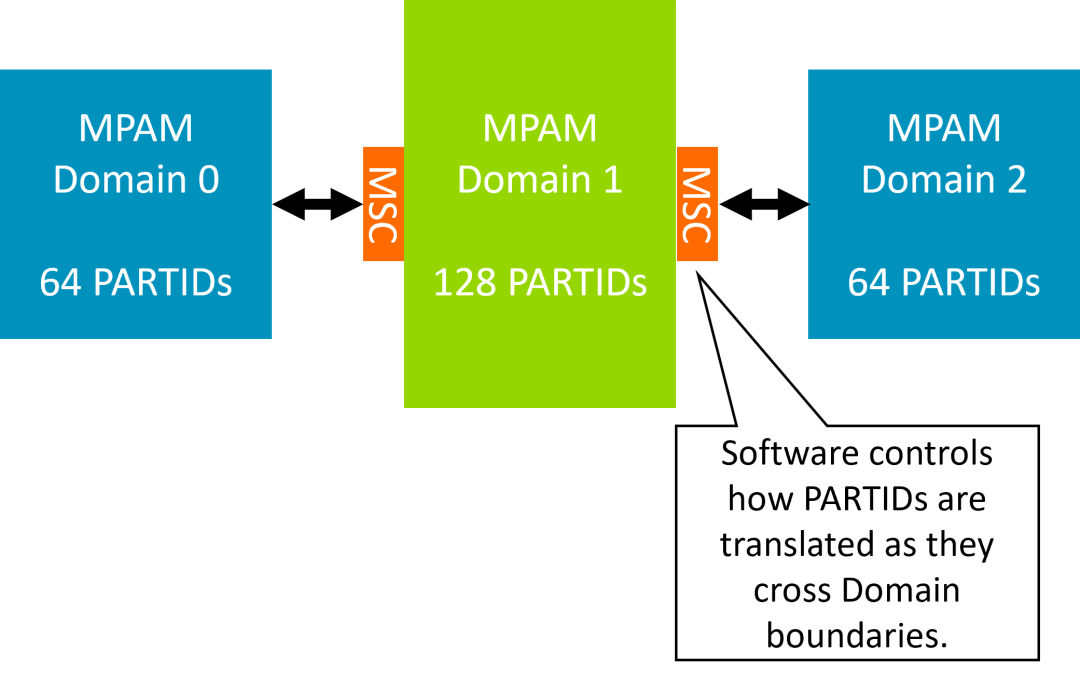
整个系统无需具有统一的 PARTID 宽度,系统因而更容易组成。由于系统的每个部分都可以只支持所需数量的 PARTID,MPAM Domain 还有助于降低成本。
虚拟机上用于 Trace 和统计分析的
虚拟机管理程序内存控制
Armv9-A 的 Trace(ETE 和 TRBE)和统计分析扩展 (Statistical Profiling Extensions, SPE) 为开发者提供了了解软件性能所需的信息,使其能最大限度地利用硬件平台。
Trace 和 SPE 数据可以在系统运行时以非侵入方式收集,数据写入虚拟内存中软件分配的缓冲区。运行虚拟机时,重要的是这些缓冲区的内存页不能被虚拟机管理程序换出去,否则会丢失分析数据。同时,通常也不希望虚拟机管理程序将虚拟机的所有内存都 Pin 进来。
2024 扩展为 TRBE 和 SPE 引入了虚拟机接口。这些接口允许虚拟机和虚拟机管理程序就分析缓冲区的大小和位置达成一致。这确保了虚拟机的分析数据不会丢失,同时允许虚拟机管理程序控制虚拟机内存中需要 Pin 的内存大小。
改进缓存和数据放置
2024 的 A 系列扩展引入了两项增强功能,以提高缓存效率。第一个功能是生产者-消费者数据放置提示。新的写提示指令允许生产线程向处理器提示写或原子操作的数据将被不同的线程使用。而对于消费线程,则有一条新的预取指令,提示数据是由另一个线程生成的,可能还不存在。这些提示共同显著提高了并行软件的可扩展性,增强了消息传递、锁传递和线程 barrier 的性能。例如:

系统可能包括连接到不同高速缓存层次结构级别的设备或加速器。例如,在下面的系统中,设备 A 可以访问系统级高速缓存 (System Level Cache, SLC),而设备 B 则绕过 SLC。
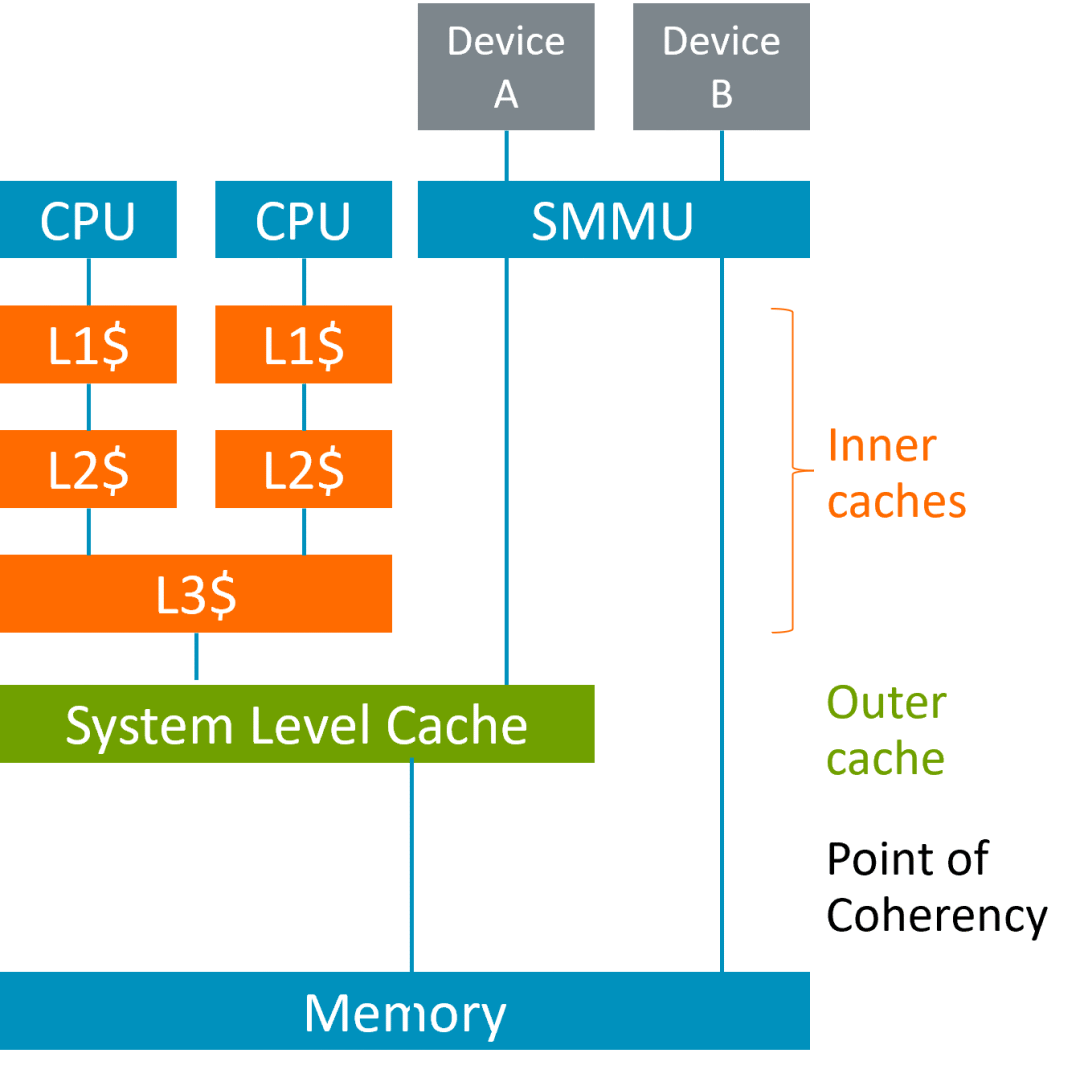
为了让设备 A 或设备 B 能够看到数据,CPU 上运行的软件需要将数据推送到内存系统中。当前,软件会使用缓存操作将数据推送到一致性点 (Point of Coherency, PoC),在示例系统中,一致性点位于 SLC 之外。这对设备 B 来说是正确的,但对设备 A 来说,将数据推送到 SLC 就足够了。
2024 扩展增加了针对 outer cache 的高速缓存维护操作。这为知道高速缓存拓扑结构的软件提供了更大的灵活性,使开发者能够根据使用该数据的设备的需求,将数据推送到系统的合适位置。
利用粒度数据隔离基于机密计算进行构建
Armv9-A 为开发者提供了编程工具和环境,使他们能够在快速发展的 AI 市场中加快创新步伐。此类应用所使用的模型和数据尤为宝贵,因此安全性至关重要。Arm 机密计算架构 (Confidential Compute Architecture, CCA) 利用硬件和软件来保护使用中的数据和应用。
Armv9.1-A 引入了机密领域管理扩展 (Realm Management Extension, RME),在设备上创建了一个独立的计算世界,用于运行和保护应用和数据。使用机密领域可以防止来自以更高权限级别运行的软件的攻击。机密领域的内容或进程无法访问。数据在使用、传输和复位时均保持加密。Armv9.4-A 引入了一项更新,使机密领域可以与加速器交互并保持其完整性。
粒度数据隔离 (Granular Data Isolation, GDI) 建立在 Armv9-A 的 RME 基础之上,并增加了两个新的物理地址空间 (Physical Address Space, PAS),可将内存位置分配到这些空间:
非安全保护 (Non-Secure Protected, NSP)
系统代理 (System Agent, SA)
这两个新的 PAS 与现有选项的不同之处在于,处理器无法访问它们。如此一来,软件就可以将内存缓冲区分配给其他设备,而硬件则维护这些缓冲区内数据的机密性。例如,可信加速器可以使用 NSP PAS 来处理数据,同时保证软件无法访问这些数据。
其他功能
2024 扩展中引入的其他增强功能包括:
对 EL1 系统寄存器进行位锁定 (Bitwise Locking)。
针对大型内存系统改进了粒度保护表 (Granular Protect Tables, GPT) 的可伸缩性。
用于扩展/压缩和查找第一个/最后一个 active 元素的新 SVE 指令。
新增非特权读取和存储指令,使操作系统能与应用内存交互。
新的比较和分支指令。
从 EL3 注入 Undefined 指令异常。
新一代中断控制器即将推出
通用中断控制器 (Generic Interrupt Controller, GIC) 是 Arm A 系列系统的标准解决方案,在整个 Arm 生态系统中被广泛使用。当前版本 GICv3 和 GICv4 于 2013 年与 Armv8-A 一起推出。从那时起,系统的结构和运行工作负载都发生了变化。Arm 正在开发新版本的 GIC 架构,我们期待在 2025 年初分享预览版。
总结
本文简要介绍了 Arm 架构 Armv9.6-A 中的最新功能。在接下来的几个月中,Arm 将与合作伙伴共同致力于确保软件生态系统能够在未来处理器上市后尽快利用这些功能。
-
处理器
+关注
关注
68文章
19257浏览量
229632 -
ARM
+关注
关注
134文章
9083浏览量
367357 -
寄存器
+关注
关注
31文章
5334浏览量
120223 -
AI
+关注
关注
87文章
30725浏览量
268869 -
人工智能
+关注
关注
1791文章
47182浏览量
238187
原文标题:Armv9 技术讲堂 | Arm A 系列架构 2024 进展
文章出处:【微信号:Arm社区,微信公众号:Arm社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
ARM发布全新Cortex-A35处理器,ARMv8-A架构全面进军移动和嵌入式市场
Armv8-A构架中Armv8.6-A引进的最新功能介绍
一文详解SIMD架构与SVE2的演进
ARM体系结构参考手册ARMv7-A和ARMv7-R版本
ARM Cortex-A系列ARMv8-A程序员指南
重磅!Arm正式推出Armv9架构







 工商网监
工商网监
评论