 如何使用内存加速存储访问速度
如何使用内存加速存储访问速度
本篇文章是首尔大学发表在FAST 2023上的文章。随着闪存容量的增加,逻辑地址到物理地址的映射表项也相应增加。映射表项通常存放在设备控制器中的SRAM来加速访问。然而由于成本问题SRAM一直无法增长,这使得其中只能存放很少量的数据表项。而为了解决这一问题,现有工作使用部分主机端内存(high performance booster, HPB)来缓存映射表项。然而文章中发现,现有的HPB管理策略并不能够很好的提升用户体验。这是因为现有的管理策略通常可能会将前台应用的表项剔除。而为了解决这一问题,本文设计提出HPBvalve技术来尽量缓存前台应用的映射表项。通过在搭建的真实平台上的验证,该技术能够很好的提升用户体验。
背景
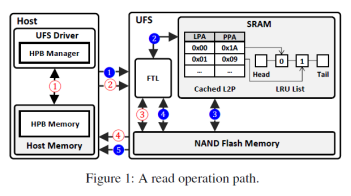
当主机下发请求时会附上逻辑地址,UFS收到请求后会在闪存转换层(FTL)进行地址转换,将逻辑地址转换为物理地址,如图1所示。记录从逻辑地址到物理地址映射信息的称之为映射表项。而为了加速这一过程,UFS中通常配备一个较小的SRAM用于缓存常用的映射表项。然而随着闪存的迅速发展,SRAM空间越发不够存储经常访问的表项。例如对于1TB的UFS设备配备512KB SRAM,则只有0.0005%的表项能够缓存在其中。显然这远远不够。而为了缓解这一问题,现有工作提出使用部分主机内存(HPB)来缓存映射表项。相较于SRAM来说,主机能够提供较大的内存,从而缓存更多的映射表项来加速访问。
动机
为了展示映射表项对用户体验的影响,文章中在搭建的平台上做了很多实验。平台将在实验部分介绍。其中设备容量为1TB,设备SRAM为512KB,HPB大小为256MB。OPTIMAL为所有映射表项都命中在设备SRAM的情况。应用启动时间和加载时间作为衡量用户体验的指标。
图2展示了映射表项访问确实对用户感知延迟的影响。从中我们可以得出三个结论:
通过对比OPTIMAL和其他两个可以看出,启动延迟和加载延迟都得到了较为明显的提升。从绝对值来看,分别是220ms和183ms,已经是用户可感知的延迟。
通过比较UFS和UFS+HPB可以发现,尽管HPB能够提供较大的容量,然而现有的管理策略并不能够利用其很好的提升用户体验。
HPB从主机端借用了较多的内存反而会使得主机内存压力增加。
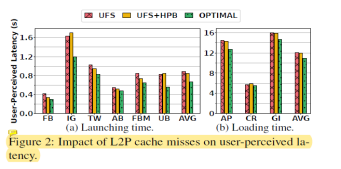
图3中进一步分析了HPB中前台应用和后台应用中映射表项的命中情况。从图中我们可以看出前台应用的映射表项缺失情况比后台应用更加严重,这是因为:1)传统HPB采用基于计数的取映射表项策略。而后台应用比前台应用会下发更多的读请求,这使得后台应用的映射表项的读取计数通常比前台应用的高。因此会更倾向于将后台应用的映射表项取到HPB中。2)传统HPB采用基于时间的映射表项剔除策略。然而当用户切换应用并使用一段时间后,刚才使用应用的映射表项也将会被剔除。这导致用户再切换回来后映射表项缺失,影响用户体验。
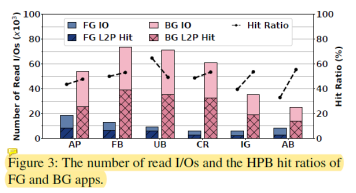
图4和图5分析了HPB无法很好预测哪些表项会被使用的原因。这是因为在应用启动的时候,会有大量随机的I/O请求,并且覆盖很大的逻辑地址空间。这使得很难提高表项命中率。
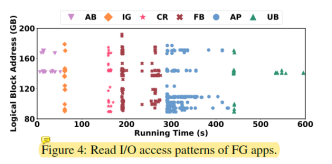
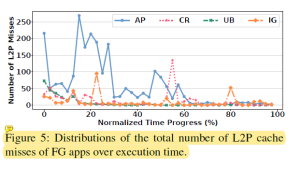
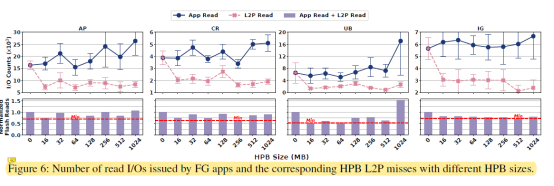
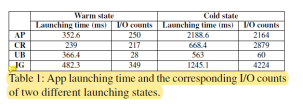
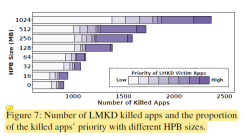
图6探索了HPB大小对用户体验的影响。从中我们可以发现最佳的HPB大小随着应用不同而不同。同时随着HPB的大小增加,前台应用下发的读取请求也在增加。这是因为HPB分配过多内存导致内存压力过大,会杀掉一些应用。当这些应用(cold state)之后再被访问的时候不仅启动时间增加,而且需要下发更多的读取请求,如表1所示。图7展示的是随着HPB大小的增加,越来越多的应用会被杀掉。
设计
为了解决上述问题,文章中提出了HPBvalve(Hvalve),如图8所示。Hvalve包含了五个部分。其中app-detector和mem-detector分别用于判断应用是否为前台应用、应用状态变化和内存压力情况。FG profiler维护了近期使用应用会访问的映射表项,用于预取映射表项。L2P manager用于单独管理前台应用的映射表项。HPB regulator用于根据内存压力情况调整HPB大小,避免过多应用被杀掉。
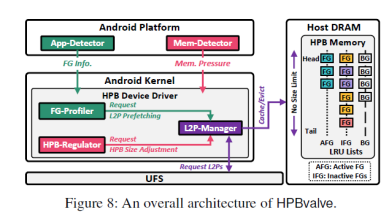
1. 前台/后台应用识别:Hvalve在bio结构体中创建新的变量UID,用于记录下发请求所属的应用。当bio创建请求的时候,UID也会集成在请求中。同时app detector会通过安卓活动任务管理器(android activity task manager)来检测是否有新的前台应用启动。如果有一个新的前台应用启动时,将该应用的UID传递给HPB。这样HPB可以将该UID与请求中携带的UID进行比较,从而判断应用是否为前台应用。
2. L2P management:Hvalve维护了三个LRU链表,分别用户记录活跃前台应用、非活跃前台应用和后台应用的映射表项。当新的前台应用启动时,会将之前的前台应用表项降级到非活跃前台应用链表中。当需要剔除表项的时候优先提出后台应用表项,然后是非活跃前台应用表项。而前台应用表项不会被剔除。
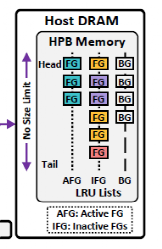
3. Hvalve缓存策略:1)其中依旧延续传统的基于访问计数的方式来缓存经常被访问的表项。2)对于前台应用缓存表项未命中时,立即将该表项取到HPB中。3)根据FG profiler预取表项。
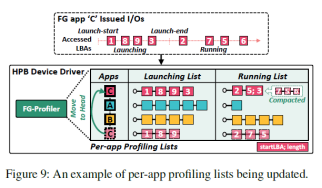
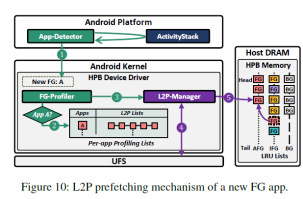
4. 前台应用分析和预取:图9展示了FG-profiler中记录的信息。FG-profiler记录近期访问应用的映射表项。同时根据app detector基于安卓活跃任务管理器发出的应用启动开始和启动结束信号,可以将映射表项分为启动表项和运行表项。当一个应用被切换为前台应用的时候,hvalve会先判断该应用对应的映射表项是否记录在FG-profiler中。如果在,则将记录的映射表项预取到HPB中,以加速访问,如图10所示。
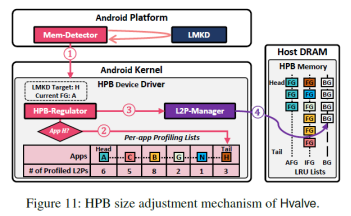
5. HPB大小动态调整:mem-detector时刻监测LMKD。当内存不足激活LMKD杀进程时,mem-detector会将将要杀掉的进程UID传送给HPB-regulator。HPB-regulator会判断该应用在FG-profiler中是否有记录,如果没有说明不是近期访问过的应用,则直接杀掉。如果有,则会根据LMKD需要释放内存的大小剔除HPB中的表项。优先提出后台应用表项,然后是非活跃应用表项。如果剔除之后内存仍然不足,则需要重新唤醒LMKD选取应用杀掉。该过程如图11所示。
实验
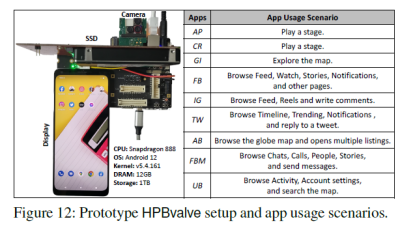
该文章为了探寻HPB不同方面的影响,自己搭建了一个平台,如图12所示。其中使用高性能SSD作为主要存储,同时简单实现了HPB的管理策略,来进行映射表项的存取。应用场景也如图12所示。
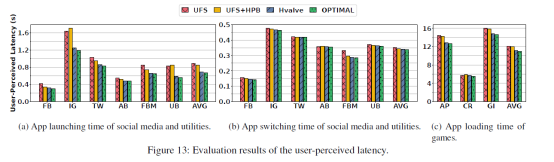
性能:性能提升如图13所示。Hvalve相较于UFS和UFS+HPB均有所改善,并且接近OPTIMAL的场景。
表项未命中模式:图14展示了前台应用表项缺失随着运行时间的分布。可以看出Hvalve很好的控制住了在应用刚运行时候的缺失率高的问题。

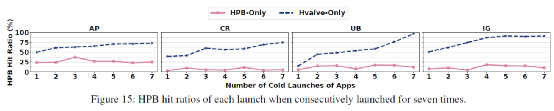
命中率:图15展示了Hvalve的命中率情况。相较于HPB-only,Hvalve很好的提升了应用冷启动时的映射表项命中率。
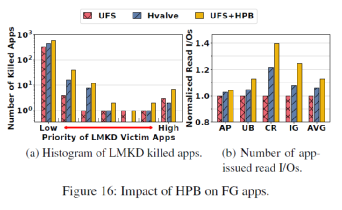
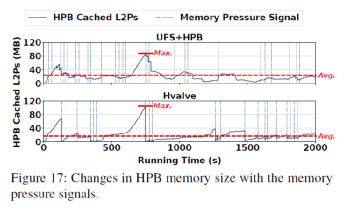
HPB大小动态调整效果:图16展示了Hvalve动态调整对前台应用的影响。可以看出Hvalve相较于传统的HPB管理策略减少了被杀掉的应用,同时很好的保护了高优先级的应用,减少了应用下发的读请求数量。图17可以观察到HPB大小动态调整的过程。
总结
为了提高HPB的使用效率从而提升用户体验,本文在自己搭建的平台上深入的分析了当前HPB管理策略存在的问题,并在此基础上设计了Hvalve。Hvalve通过对前台应用映射表项的识别和管理,提高了前台应用的访问速度,提升用户体验。同时根据内存压力动态调整HPB大小,避免导致内存压力过大而杀掉过多的应用,影响用户体验。实验结果显示,Hvalve提升了用户前台应用表项的命中率,减少了被杀掉的应用,提升了用户体验。
-
存储
+关注
关注
13文章
4296浏览量
85794 -
sram
+关注
关注
6文章
767浏览量
114671 -
内存
+关注
关注
8文章
3019浏览量
73998
原文标题:手机访问卡顿,看如何使用内存加速存储访问速度!
文章出处:【微信号:SSDFans,微信公众号:SSDFans】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
内存扩展CXL加速发展,繁荣AI存储

内存储器的特点是速度快成本低容量小对吗
内存储器由什么组成
内存储器主要用来存储什么
内存储器分为随机存储器和什么
恒讯科技分析:香港服务器网站访问速度如何才能达到最快?
Jtti:新加坡云服务器运行内存和存储内存有何区别?
集成32GB HBM2e内存,AMD Alveo V80加速卡助力传感器处理、存储压缩等

加速度传感器原理及其应用






 工商网监
工商网监
评论