 【干货】计算机视觉必读:目标跟踪、网络压缩、图像分类、人脸识别等
【干货】计算机视觉必读:目标跟踪、网络压缩、图像分类、人脸识别等
深度学习目前已成为发展最快、最令人兴奋的机器学习领域之一。本文以计算机视觉的重要概念为线索,介绍深度学习在计算机视觉任务中的应用,包括网络压缩、细粒度图像分类、看图说话、视觉问答、图像理解、纹理生成和风格迁移、人脸识别、图像检索、目标跟踪等。
网络压缩(network compression)
尽管深度神经网络取得了优异的性能,但巨大的计算和存储开销成为其部署在实际应用中的挑战。有研究表明,神经网络中的参数存在大量的冗余。因此,有许多工作致力于在保证准确率的同时降低网路复杂度。
低秩近似用低秩矩阵近似原有权重矩阵。例如,可以用SVD得到原矩阵的最优低秩近似,或用Toeplitz矩阵配合Krylov分解近似原矩阵。
剪枝(pruning)在训练结束后,可以将一些不重要的神经元连接(可用权重数值大小衡量配合损失函数中的稀疏约束)或整个滤波器去除,之后进行若干轮微调。实际运行中,神经元连接级别的剪枝会使结果变得稀疏,不利于缓存优化和内存访问,有的需要专门设计配套的运行库。相比之下,滤波器级别的剪枝可直接运行在现有的运行库下,而滤波器级别的剪枝的关键是如何衡量滤波器的重要程度。例如,可用卷积结果的稀疏程度、该滤波器对损失函数的影响、或卷积结果对下一层结果的影响来衡量。
量化(quantization)对权重数值进行聚类,用聚类中心数值代替原权重数值,配合Huffman编码,具体可包括标量量化或乘积量化。但如果只考虑权重自身,容易造成量化误差很低,但分类误差很高的情况。因此,Quantized CNN优化目标是重构误差最小化。此外,可以利用哈希进行编码,即被映射到同一个哈希桶中的权重共享同一个参数值。
降低数据数值范围默认情况下数据是单精度浮点数,占32位。有研究发现,改用半精度浮点数(16位)几乎不会影响性能。谷歌TPU使用8位整型来表示数据。极端情况是数值范围为二值或三值(0/1或-1/0/1),这样仅用位运算即可快速完成所有计算,但如何对二值或三值网络进行训练是一个关键。通常做法是网络前馈过程为二值或三值,梯度更新过程为实数值。此外,有研究认为,二值运算的表示能力有限,因此其使用一个额外的浮点数缩放二值卷积后的结果,以提升网络表示能力。
精简结构设计有研究工作直接设计精简的网络结构。例如,(1).瓶颈(bottleneck)结构及1×1卷积。这种设计理念已经被广泛用于Inception和ResNet系列网络设计中。(2).分组卷积。(3).扩张卷积。使用扩张卷积可以保持参数量不变的情况下扩大感受野。
知识蒸馏(knowledge distillation)训练小网络以逼近大网络,但应该如何去逼近大网络仍没有定论。
软硬件协同设计常用的硬件包括两大类:(1). 通用硬件,包括CPU(低延迟,擅长串行、复杂运算)和GPU(高吞吐率,擅长并行、简单运算)。(2). 专用硬件,包括ASIC(固定逻辑器件,例如谷歌TPU)和FPGA(可编程逻辑器件,灵活,但效率不如ASIC)。
细粒度图像分类(fine-grained image classification)
相比(通用)图像分类,细粒度图像分类需要判断的图像类别更加精细。比如,我们需要判断该目标具体是哪一种鸟、哪一款的车、或哪一个型号的飞机。通常,这些子类之间的差异十分微小。比如,波音737-300和波音737-400的外观可见的区别只是窗户的个数不同。因此,细粒度图像分类是比(通用)图像分类更具有挑战性的任务。
细粒度图像分类的经典做法是先定位出目标的不同部位,例如鸟的头、脚、翅膀等,之后分别对这些部位提取特征,最后融合这些特征进行分类。这类方法的准确率较高,但这需要对数据集人工标注部位信息。目前细粒度分类的一大研究趋势是不借助额外监督信息,只利用图像标记进行学习,其以基于双线性CNN的方法为代表。
双线性CNN (bilinear CNN)其通过计算卷积描述向量(descriptor)的外积来考察不同维度之间的交互关系。由于描述向量的不同维度对应卷积特征的不同通道,而不同通道提取了不同的语义特征,因此,通过双线性操作,可以同时捕获输入图像的不同语义特征之间的关系。
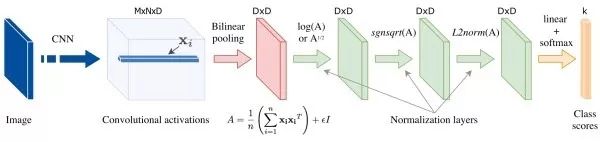
精简双线性汇合双线性汇合的结果十分高维,这会占用大量的计算和存储资源,同时使后续的全连接层的参数量大大增加。许多后续研究工作旨在设计更精简的双线性汇合策略,大致包括以下三大类:(1).PCA降维。在双线性汇合前,对深度描述向量进行PCA投影降维,但这会使各维不再相关,进而影响性能。一个折中的方案是只对一支进行PCA降维。(2).近似核估计。可以证明,在双线性汇合结果后使用线性SVM分类等价于在描述向量间使用了多项式核。由于两个向量外积的映射等于两个向量分别映射之后再卷积,有研究工作使用随机矩阵近似向量的映射。此外,通过近似核估计,我们可以捕获超过二阶的信息(如下图)。(3).低秩近似。对后续用于分类的全连接层的参数矩阵进行低秩近似,进而使我们不用显式计算双线性汇合结果。
“看图说话”(image captioning)
“看图说话”旨在对一张图像产生对其内容一两句话的文字描述。这是视觉和自然语言处理两个领域的交叉任务。
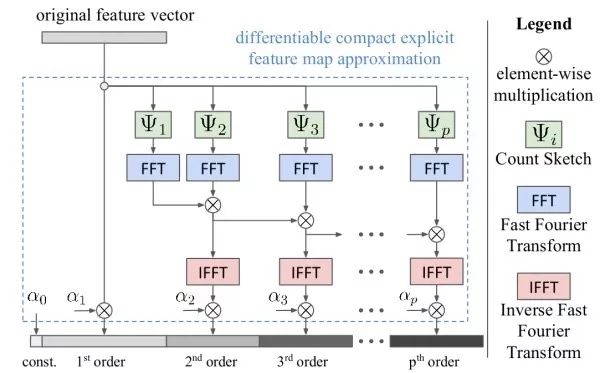
编码-解码网络(encoder-decoder networks)看图说话网络设计的基本思想,其借鉴于自然语言处理中的机器翻译思路。将机器翻译中的源语言编码网络替换为图像的CNN编码网络以提取图像的特征,之后用目标语言解码网络生成文字描述。
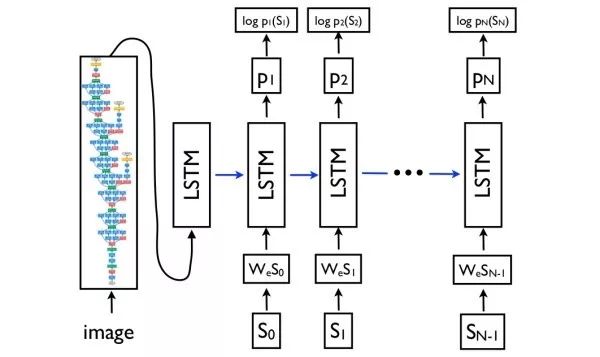
Show, attend, and tell注意力(attention)机制是机器翻译中用于捕获长距离依赖的常用技巧,也可以用于看图说话。在解码网络中,每个时刻,除了预测下一个词外,还需要输出一个二维注意力图,用于对深度卷积特征进行加权汇合。使用注意力机制的一个额外的好处是可以对网络进行可视化,以观察在生成每个词的时候网络注意到图像中的哪些部分。
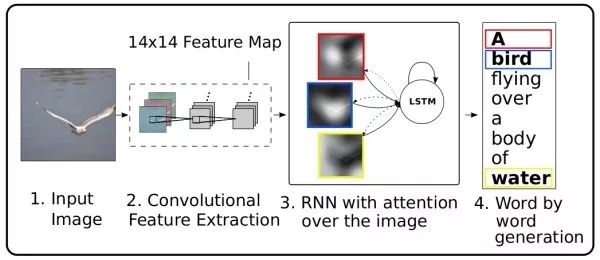
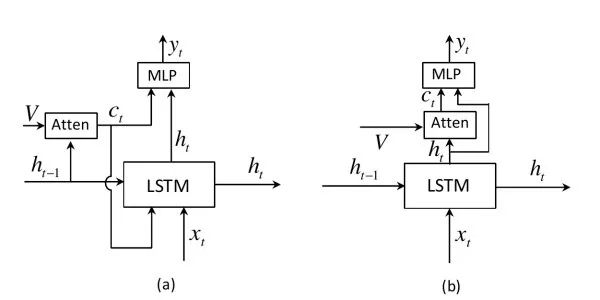
Adaptive attention之前的注意力机制会对每个待预测词生成一个二维注意力图(图(a)),但对于像the、of这样的词实际上并不需要借助来自图像的线索,并且有的词可以根据上文推测出也不需要图像信息。该工作扩展了LSTM,以提出“视觉哨兵”机制以判断预测当前词时应更关注上文语言信息还是更关注图像信息(图(b))。此外,和之前工作利用上一时刻的隐层状态计算注意力图不同,该工作使用当前隐层状态。
视觉问答(visual question answering)
给定一张图像和一个关于该图像内容的文字问题,视觉问答旨在从若干候选文字回答中选出正确的答案。其本质是分类任务,也有工作是用RNN解码来生成文字回答。视觉问答也是视觉和自然语言处理两个领域的交叉任务。
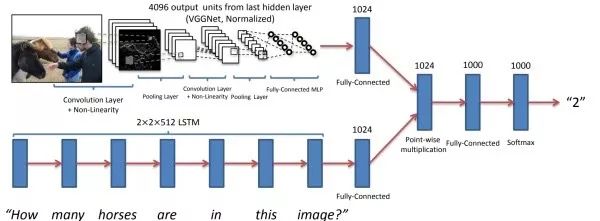
基本思路使用CNN从图像中提取图像特征,用RNN从文字问题中提取文本特征,之后设法融合视觉和文本特征,最后通过全连接层进行分类。该任务的关键是如何融合这两个模态的特征。直接的融合方案是将视觉和文本特征拼成一个向量、或者让视觉和文本特征向量逐元素相加或相乘。
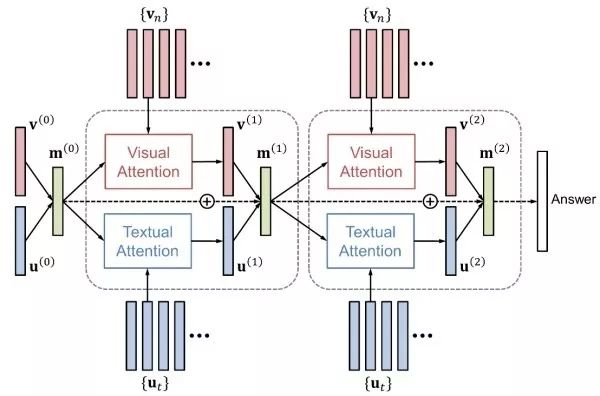
注意力机制和“看图说话”相似,使用注意力机制也会提升视觉问答的性能。注意力机制包括视觉注意力(“看哪里”)和文本注意力(“关注哪个词”)两者。HieCoAtten可同时或交替产生视觉和文本注意力。DAN将视觉和文本的注意力结果映射到一个相同的空间,并据此同时产生下一步的视觉和文本注意力。
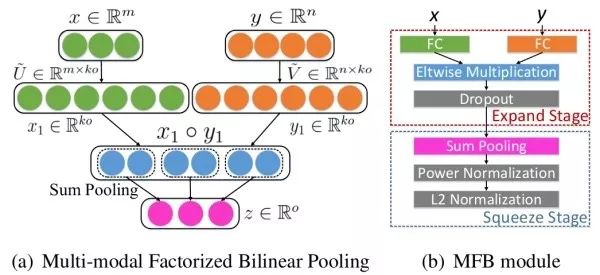
双线性融合通过视觉特征向量和文本特征向量的外积,可以捕获这两个模态特征各维之间的交互关系。为避免显式计算高维双线性汇合结果,细粒度识别中的精简双线性汇合思想也可用于视觉问答。例如,MFB采用了低秩近似思路,并同时使用了视觉和文本注意力机制。
网络可视化(visualizing)和网络理解(understanding)
这些方法旨在提供一些可视化的手段以理解深度卷积神经网络。
直接可视化第一层滤波器由于第一层卷积层的滤波器直接在输入图像中滑动,我们可以直接对第一层滤波器进行可视化。可以看出,第一层权重关注于特定朝向的边缘以及特定色彩组合。这和生物的视觉机制是符合的。但由于高层滤波器并不直接作用于输入图像,直接可视化只对第一层滤波器有效。

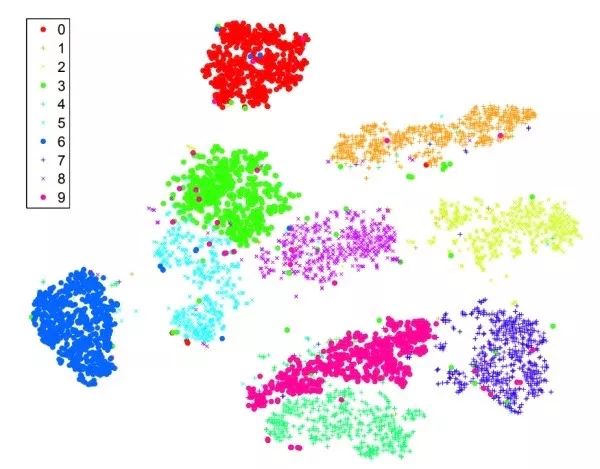
t-SNE对图像的fc7或pool5特征进行低维嵌入,比如降维到2维使得可以在二维平面画出。具有相近语义信息的图像应该在t-SNE结果中距离相近。和PCA不同的是,t-SNE是一种非线性降维方法,保留了局部之间的距离。下图是直接对MNIST原始图像进行t-SNE的结果。可以看出,MNIST是比较容易的数据集,属于不同类别的图像聚类十分明显。
可视化中间层激活值对特定输入图像,画出不同特征图的响应。观察发现,即使ImageNet中没有人脸或文字相关的类别,网络会学习识别这些语义信息,以辅助后续的分类。
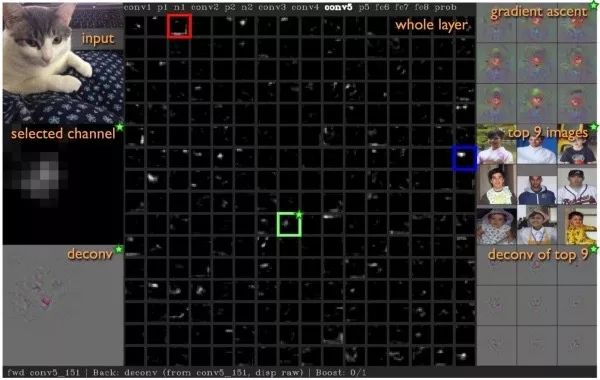
最大响应图像区域选择某一特定的中间层神经元,向网络输入许多不同的图像,找出使该神经元响应最大的图像区域,以观察该神经元用于响应哪种语义特征。是“图像区域”而不是“完整图像”的原因是中间层神经元的感受野是有限的,没有覆盖到全部图像。
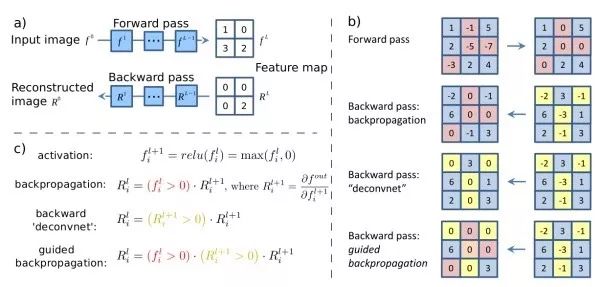
输入显著性图对给定输入图像,计算某一特定神经元对输入图像的偏导数。其表达了输入图像不同像素对该神经元响应的影响,即输入图像的不同像素的变化会带来怎样的神经元响应值的变化。Guided backprop只反向传播正的梯度值,即只关注对神经元正向的影响,这会产生比标准反向传播更好的可视化效果。
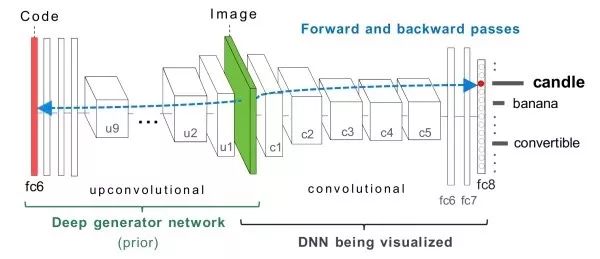
梯度上升优化选择某一特定的神经元,计算某一特定神经元对输入图像的偏导数,对输入图像使用梯度上升进行优化,直到收敛。此外,我们需要一些正则化项使得产生的图像更接近自然图像。此外,除了在输入图像上进行优化外,我们也可以对fc6特征进行优化并从其生成需要的图像。
DeepVisToolbox该工具包同时提供了以上四种可视化结果。该链接中提供了一个演示视频:Jason Yosinski(yosinski.com/deepvis#toolbox)
遮挡实验(occlusion experiment)用一个灰色方块遮挡住图像的不同区域,之后前馈网络,观察其对输出的影响。对输出影响最大的区域即是对判断该类别最重要的区域。从下图可以看出,遮挡住狗的脸对结果影响最大。
Deep dream选择一张图像和某一特定层,优化目标是通过对图像的梯度上升,最大化该层激活值的平方。实际上,这是在通过正反馈放大该层神经元捕获到的语义特征。可以看出,生成的图像中出现了很多狗的图案,这是因为ImageNet数据集1000类别中有200类关于狗,因此,神经网络中有很多神经元致力于识别图像中的狗。
对抗样本(adversarial examples)选择一张图像和一个不是它真实标记的类别,计算该类别对输入图像的偏导数,对图像进行梯度上升优化。实验发现,在对图像进行难以察觉的微小改变后,就可以使网络以相当大的信心认为该图像属于那个错误的类别。实际应用中,对抗样本会将会对金融、安防等领域产生威胁。有研究认为,这是由于图像空间非常高维,即使有非常多的训练数据,也只能覆盖该空间的很小一部分。只要输入稍微偏离该流形空间,网络就难以得到正常的判断。
纹理生成(texture synthesis)和风格迁移(style transform)
给定一小张包含特定纹理的图像,纹理合成旨在生成更大的包含相同纹理的图像。给定一张普通图像和一张包含特定绘画风格的图像,风格迁移旨在保留原图内容的同时,将给定风格迁移到该图中。
特征逆向工程(feature inversion)这两类问题的基本思路。给定一个中间层特征,我们希望通过迭代优化,产生一个特征和给定特征接近的图像。此外,特征逆向工程也可以告诉我们中间层特征中蕴含了多少图像中信息。可以看出,低层的特征中几乎没有损失图像信息,而高层尤其是全连接特征会丢失大部分的细节信息。从另一方面讲,高层特征对图像的颜色和纹理变化更不敏感。
Gram矩阵给定D×H×W的深度卷积特征,我们将其转换为D×(HW)的矩阵X,则该层特征对应的Gram矩阵定义为
G=XX^T
通过外积,Gram矩阵捕获了不同特征之间的共现关系。
纹理生成基本思路对给定纹理图案的Gram矩阵进行特征逆向工程。使生成图像的各层特征的Gram矩阵接近给定纹理图像的各层Gram。低层特征倾向于捕获细节信息,而高层特征可以捕获更大面积的特征。
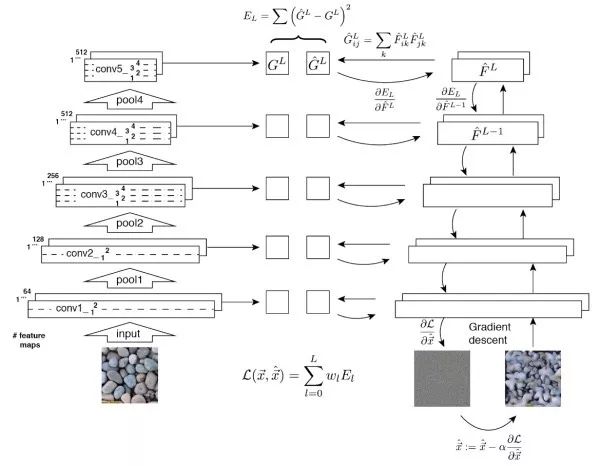
风格迁移基本思路优化目标包括两项,使生成图像的内容接近原始图像内容,及使生成图像风格接近给定风格。风格通过Gram矩阵体现,而内容则直接通过神经元激活值体现。
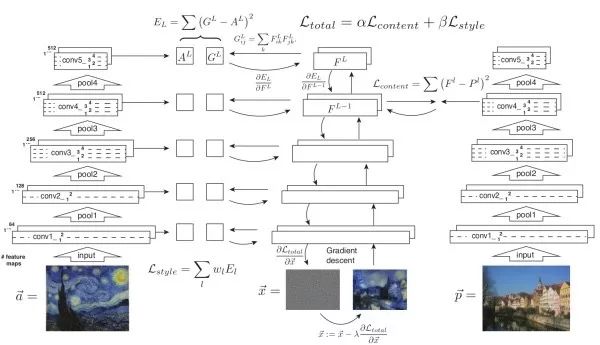
直接生成风格迁移的图像上述方法的缺点是需要多次迭代才能收敛。该工作提出的解决方案是训练一个神经网络来直接生成风格迁移的图像。一旦训练结束,进行风格迁移只需前馈网络一次,十分高效。在训练时,将生成图像、原始图像、风格图像三者前馈一固定网络以提取不同层特征用于计算损失函数。
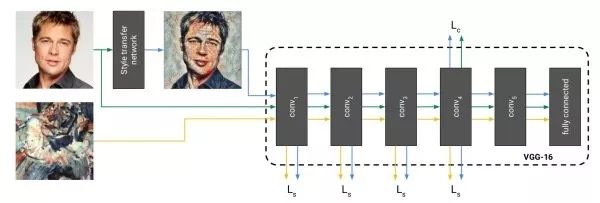
示例归一化(instance normalization)和批量归一化(batch normalization)作用于一个批量不同,示例归一化的均值和方差只由图像自身决定。实验中发现,在风格迁移网络中使用示例归一化可以从图像中去除和示例有关的对比度信息以简化生成过程。
条件示例归一化(conditional instance normalization)上述方法的一个问题是对每种不同的风格,我们需要分别训练一个模型。由于不同风格之间存在共性,该工作旨在让对应于不同风格的风格迁移网络共享参数。具体来说,其修改了风格迁移网络中的示例归一化,使其具有N组缩放和平移参数,每组对应一个不同的风格。这样,我们可以通过一次前馈过程同时获得N张风格迁移图像。
人脸验证/识别(face verification/recognition)
人脸验证/识别可以认为是一种更加精细的细粒度图像识别任务。人脸验证是给定两张图像、判断其是否属于同一个人,而人脸识别是回答图像中的人是谁。一个人脸验证/识别系统通常包括三大步:检测图像中的人脸,特征点定位、及对人脸进行验证/识别。人脸验证/识别的难题在于需要进行小样本学习。通常情况下,数据集中每人只有对应的一张图像,这称为一次学习(one-shot learning)。
两种基本思路当作分类问题(需要面对非常多的类别数),或者当作度量学习问题。如果两张图像属于同一个人,我们希望它们的深度特征比较接近,否则,我们希望它们不接近。之后,根据深度特征之间的距离进行验证(对特征距离设定阈值以判断是否属于同一个人),或识别(k近邻分类)。

DeepFace第一个将深度神经网络成功用于人脸验证/识别的模型。DeepFace使用了非共享参数的局部连接。这是由于人脸不同区域存在不同的特征(例如眼睛和嘴巴具有不同的特征),经典卷积层的“共享参数”性质在人脸识别中不再适用。因此,人脸识别网络中会采用不共享参数的局部连接。其使用孪生网络(siamese network)进行人脸验证。当两张图像的深度特征小于给定阈值时,认为其来自同一个人。

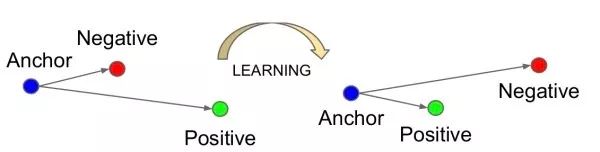
FaceNet三元输入,希望和负样本之间的距离以一定间隔(如0.2)大于和正样本之间的距离。此外,输入三元的选择不是随机的,否则由于和负样本之间的差异很大,网络学不到什么东西。选择最困难的三元组(即最远的正样本和最近的负样本)会使网络陷入局部最优。FaceNet采用半困难策略,选择比正样本远的负样本。
大间隔交叉熵损失近几年的一大研究热点。由于类内波动大而类间相似度高,有研究工作旨在提升经典的交叉熵损失对深度特征的判断能力。例如,L-Softmax加强优化目标,使对应类别的参数向量和深度特征夹角增大。 A-Softmax进一步约束L-Softmax的参数向量长度为1,使训练更集中到优化深度特征和夹角上。实际中,L-Softmax和A-Softmax都很难收敛,训练时采用了退火方法,从标准softmax逐渐退火至L-Softmax或A-Softmax。
活体检测(liveness detection)判断人脸是来自真人或是来自照片等,这是人脸验证/识别需要解决的关键问题。在产业界目前主流的做法是利用人的表情变化、纹理信息、眨眼、或让用户完成一系列动作等。
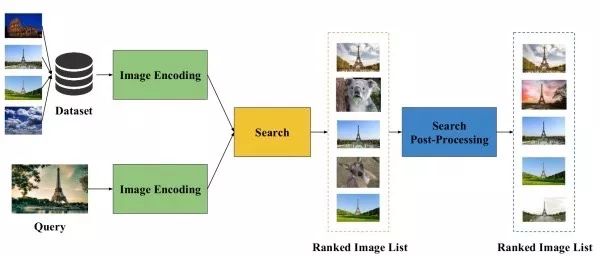
图像检索(image retrieval)
给定一个包含特定实例(例如特定目标、场景、建筑等)的查询图像,图像检索旨在从数据库图像中找到包含相同实例的图像。但由于不同图像的拍摄视角、光照、或遮挡情况不同,如何设计出能应对这些类内差异的有效且高效的图像检索算法仍是一项研究难题。
图像检索的典型流程首先,设法从图像中提取一个合适的图像的表示向量。其次,对这些表示向量用欧式距离或余弦距离进行最近邻搜索以找到相似的图像。最后,可以使用一些后处理技术对检索结果进行微调。可以看出,决定一个图像检索算法性能的关键在于提取的图像表示的好坏。
(1)无监督图像检索
无监督图像检索旨在不借助其他监督信息,只利用ImageNet预训练模型作为固定的特征提取器来提取图像表示。
直觉思路由于深度全连接特征提供了对图像内容高层级的描述,且是“天然”的向量形式,一个直觉的思路是直接提取深度全连接特征作为图像的表示向量。但是,由于全连接特征旨在进行图像分类,缺乏对图像细节的描述,该思路的检索准确率一般。
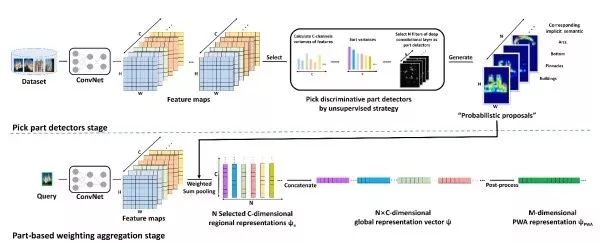
利用深度卷积特征由于深度卷积特征具有更好的细节信息,并且可以处理任意大小的图像输入,目前的主流方法是提取深度卷积特征,并通过加权全局求和汇合(sum-pooling)得到图像的表示向量。其中,权重体现了不同位置特征的重要性,可以有空间方向权重和通道方向权重两种形式。
CroW深度卷积特征是一个分布式的表示。虽然一个神经元的响应值对判断对应区域是否包含目标用处不大,但如果多个神经元同时有很大的响应值,那么该区域很有可能包含该目标。因此,CroW把特征图沿通道方向相加,得到一张二维聚合图,并将其归一化并根号规范化的结果作为空间权重。CroW的通道权重根据特征图的稀疏性定义,其类似于自然语言处理中TF-IDF特征中的IDF特征,用于提升不常出现但具有判别能力的特征。
Class weighted features该方法试图结合网络的类别预测信息来使空间权重更具判别能力。具体来说,其利用CAM来获取预训练网络中对应各类别的最具代表性区域的语义信息,进而将归一化的CAM结果作为空间权重。
PWAPWA发现,深度卷积特征的不同通道对应于目标不同部位的响应。因此,PWA选取一系列有判别能力的特征图,将其归一化之后的结果作为空间权重进行汇合,并将其结果级联起来作为最终图像表示。
(2)有监督图像检索
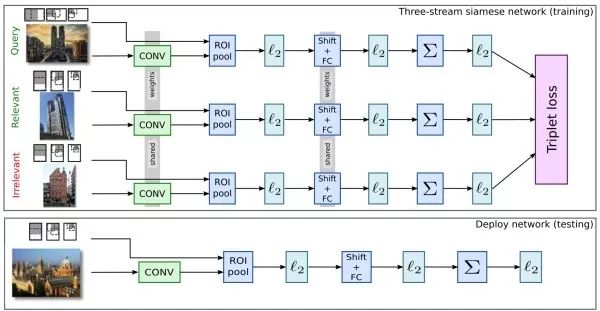
有监督图像检索首先将ImageNet预训练模型在一个额外的训练数据集上进行微调,之后再从这个微调过的模型中提取图像表示。为了取得更好的效果,用于微调的训练数据集通常和要用于检索的数据集比较相似。此外,可以用候选区域网络提取图像中可能包含目标的前景区域。
孪生网络(siamese network)和人脸识别的思路类似,使用二元或三元(++-)输入,训练模型使相似样本之间的距离尽可能小,而不相似样本之间的距离尽可能大。
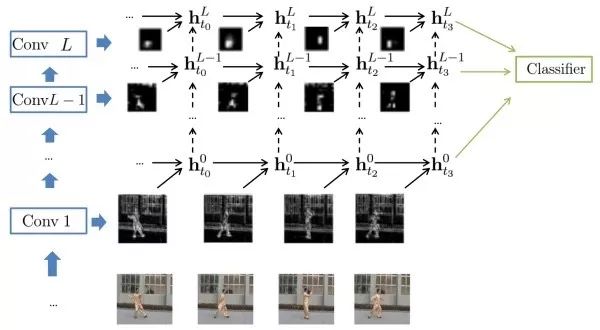
目标跟踪(object tracking)
目标跟踪旨在跟踪一段视频中的目标的运动情况。通常,视频第一帧中目标的位置会以包围盒的形式给出,我们需要预测其他帧中该目标的包围盒。目标跟踪类似于目标检测,但目标跟踪的难点在于事先不知道要跟踪的目标具体是什么,因此无法事先收集足够的训练数据以训练一个专门的检测器。
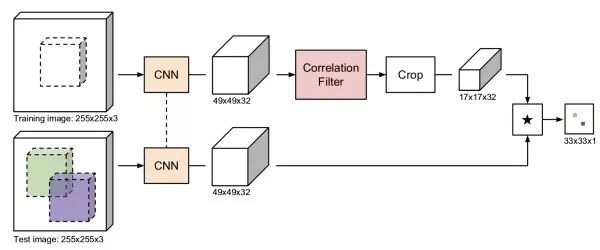
孪生网络类似于人脸验证的思路,利用孪生网络,一支输入第一帧包围盒内图像,另一支输入其他帧的候选图像区域,输出两张图的相似度。我们不需要遍历其他帧的所有可能的候选区域,利用全卷积网络,我们只需要前馈整张图像一次。通过互相关操作(卷积),得到二维的响应图,其中最大响应位置确定了需要预测的包围盒位置。基于孪生网络的方法速度快,能处理任意大小的图像。
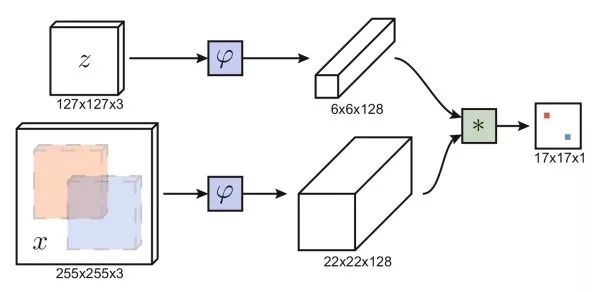
CFNet相关滤波通过训练一个线性模板来区分图像区域和它周围区域,利用傅里叶变换,相关滤波有十分高效的实现。CFNet结合离线训练的孪生网络和在线更新的相关滤波模块,提升轻量级网络的跟踪性能。
生成式模型(generative models)
这类模型旨在学得数据(图像)的分布,或从该分布中采样得到新的图像。生成式模型可以用于超分辨率重建、图像着色、图像转换、从文字生成图像、学习图像潜在表示、半监督学习等。此外,生成式模型可以和强化学习结合,用于仿真和逆强化学习。
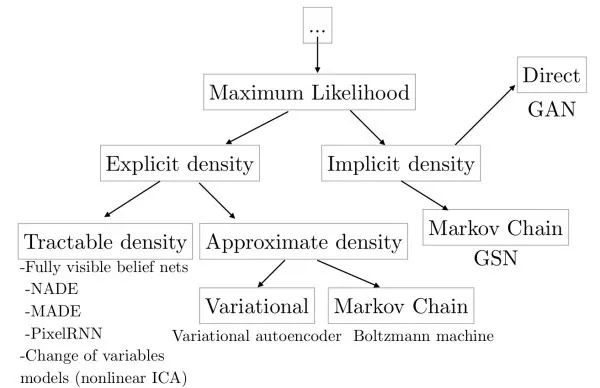
显式建模根据条件概率公式,直接进行最大似然估计对图像的分布进行学习。该方法的弊端是,由于每个像素依赖于之前的像素,生成图像时由于需要从一角开始序列地进行,所以会比较慢。例如,WaveNet可以生成类似人类说话的语音,但由于无法并行生成,得到1秒的语音需要2分钟的计算,无法达到实时。
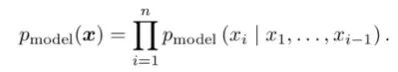
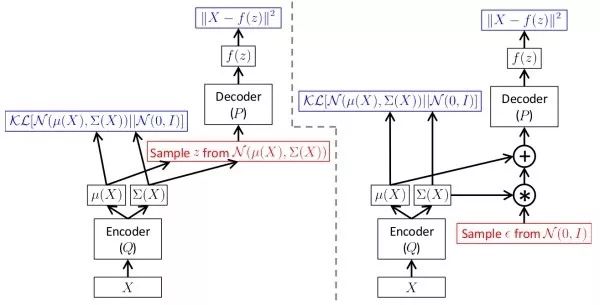
变分自编码器(variational auto-encoder, VAE)为避免显式建模的弊端,变分自编码器对数据分布进行隐式建模。其认为图像的生成受一个隐变量控制,并假设该隐变量服从对角高斯分布。变分自编码器通过一个解码网络从隐变量生成图像。由于无法直接进行最大似然估计,在训练时,类似于EM算法,变分自编码器会构造似然函数的下界函数,并对这个下界函数进行优化。变分自编码器的好处是,由于各维独立,我们可以通过控制隐变量来控制输出图像的变化因素。
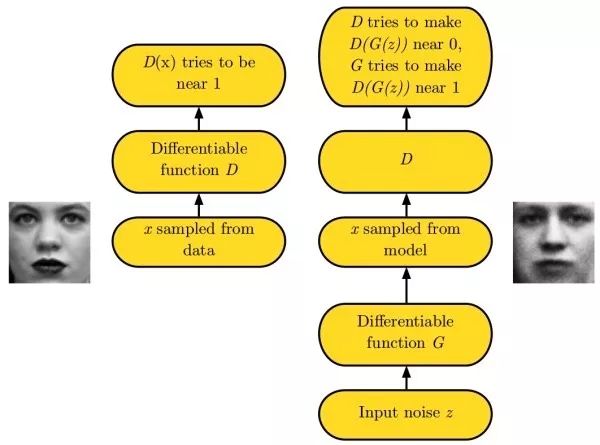
生成式对抗网络(generative adversarial networks, GAN)由于学习数据分布十分困难,生成式对抗网络绕开这一步骤,直接生成新的图像。生成式对抗网络使用一个生成网络G从随机噪声中生成图像,以及一个判别网络D判断其输入图像是真实/伪造图像。在训练时,判别网络D的目标是能判断真实/伪造图像,而生成网络G的目标是使得判别网络D倾向于判断其输出是真实图像。实际中,直接训练生成式对抗网络会遇到mode collapse问题,即生成式对抗网络无法学到完整的数据分布。随后,出现了LS-GAN和W-GAN的改进。和变分自编码器相比,生成式对抗网络的细节信息更好。以下链接整理了许多和生成式对抗网络有关的论文:hindupuravinash/the-gan-zoo。以下链接整理了许多训练生成式对抗网络的其技巧:soumith/ganhacks。
视频分类(video classification)
前面介绍的大部分任务也可以用于视频数据,这里仅以视频分类任务为例,简要介绍处理视频数据的基本方法。
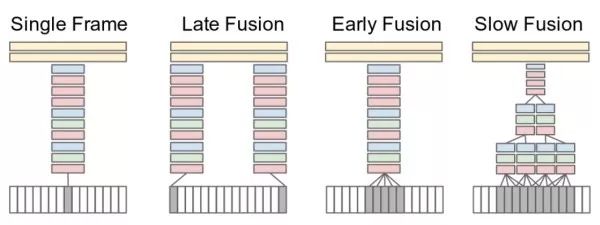
多帧图像特征汇合这类方法将视频看成一系列帧的图像组合。网络同时接收属于一个视频片段的若干帧图像(例如15帧),并分别提取其深度特征,之后融合这些图像特征得到该视频片段的特征,最后进行分类。实验发现,使用"slow fusion"效果最好。此外,独立使用单帧图像进行分类即可得到很有竞争力的结果,这说明单帧图像已经包含很多的信息。
三维卷积将经典的二维卷积扩展到三维卷积,使之在时间维度也局部连接。例如,可以将VGG的3×3卷积扩展为3×3×3卷积,2×2汇合扩展为2×2×2汇合。

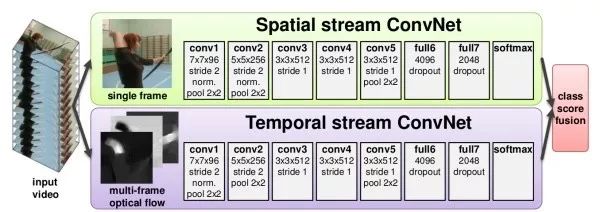
图像+时序两分支结构这类方法用两个独立的网络分别捕获视频中的图像信息和随时间运动信息。其中,图像信息从单帧静止图像中得到,是经典的图像分类问题。运动信息则通过光流(optical flow)得到,其捕获了目标在相邻帧之间的运动情况。
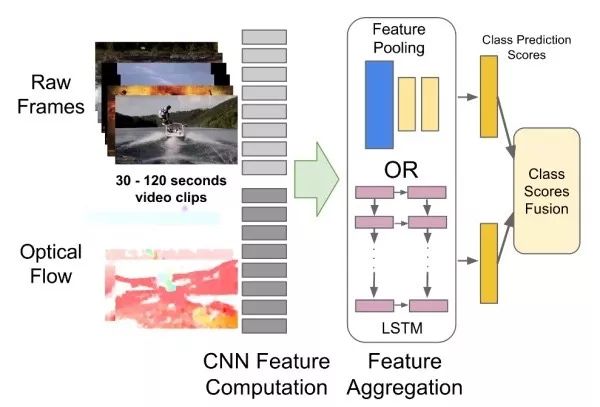
CNN+RNN捕获远距离依赖之前的方法只能捕获几帧图像之间的依赖关系,这类方法旨在用CNN提取单帧图像特征,之后用RNN捕获帧之间的依赖。
此外,有研究工作试图将CNN和RNN合二为一,使每个卷积层都能捕获远距离依赖。
-
目标跟踪
+关注
关注
2文章
88浏览量
14881 -
人脸识别
+关注
关注
76文章
4011浏览量
81859
原文标题:【新智元干货】计算机视觉必读:目标跟踪、网络压缩、图像分类、人脸识别等
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
目标检测与识别技术的关系是什么
计算机视觉的五大技术
计算机视觉的工作原理和应用
深度学习在计算机视觉领域的应用
计算机视觉的十大算法

计算机视觉与图像处理、模式识别、机器学习学科之间的关系
计算机视觉:AI如何识别与理解图像





 工商网监
工商网监
评论