 一种神经语音克隆系统两种方法在自然性和相似性方面表现良好
一种神经语音克隆系统两种方法在自然性和相似性方面表现良好
近日,百度研究者发表论文,利用两种方法,只需少量样本就能在几秒钟内合成自然且相似度极高的语音。近些年关于高质量的语音合成方法确实不少,但能在如此短时间内完成的却实属罕见。
声音克隆是个性化语音交互领域高度理想化的功能,基于神经网络的语音合成系统已经可以为大量发言者生成高质量语音了。在这篇论文中,百度的研究人员向我们介绍了一种神经语音克隆系统,只需要输入少量的语音样本,就能合成逼真的语音。这里研究了两种方法:说话者适应(speaker adaptation)和说话者编码(speaker encoding),最终结果表明两种方法在语音的自然性和相似性方面都表现良好。
由于研究者要从有限且陌生的语音样本中进行语音克隆,这就相当于一个“语音在特定语境下的few-shot生成建模”问题。若样本充足,为任何目标说话者训练生成模型都不在话下。不过,few-shot生成模型虽然听起来很吸引人,但却是个挑战。生成模型需要通过少量的信息学习说话者的特征,然后还要生成全新的语音。
语音克隆
我们计划设计一个多说话者生成模型(multi-speaker generative model):f(ti,j,si; W,esi),ti表示文本,si表示说话者。模型以W进行参数化,作为编码器和解码器的训练参数。esi是对应到si的可训练说话者嵌入。W和esi均通过最小化损失函数L进行优化,损失函数L对生成音频和真视音频之间的差异进行惩罚。
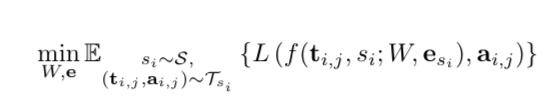
这里S是一组说话者,Tsi是为si准备的文字-音频训练集,ai和j是ti和j的真实音频。期望值是通过所有训练说话者的文本-音频对来估计的。
在语音克隆中,实验的目的是从一组克隆音频Ask中提取出sk的声音特征,并且用该声音生成不一样的音频。衡量生成结果的标准有二:
看语音是否自然;
看生成的语音与原音频是否相似。
下图总结了说话者适应和说话者编码两种方法的语音克隆方法:
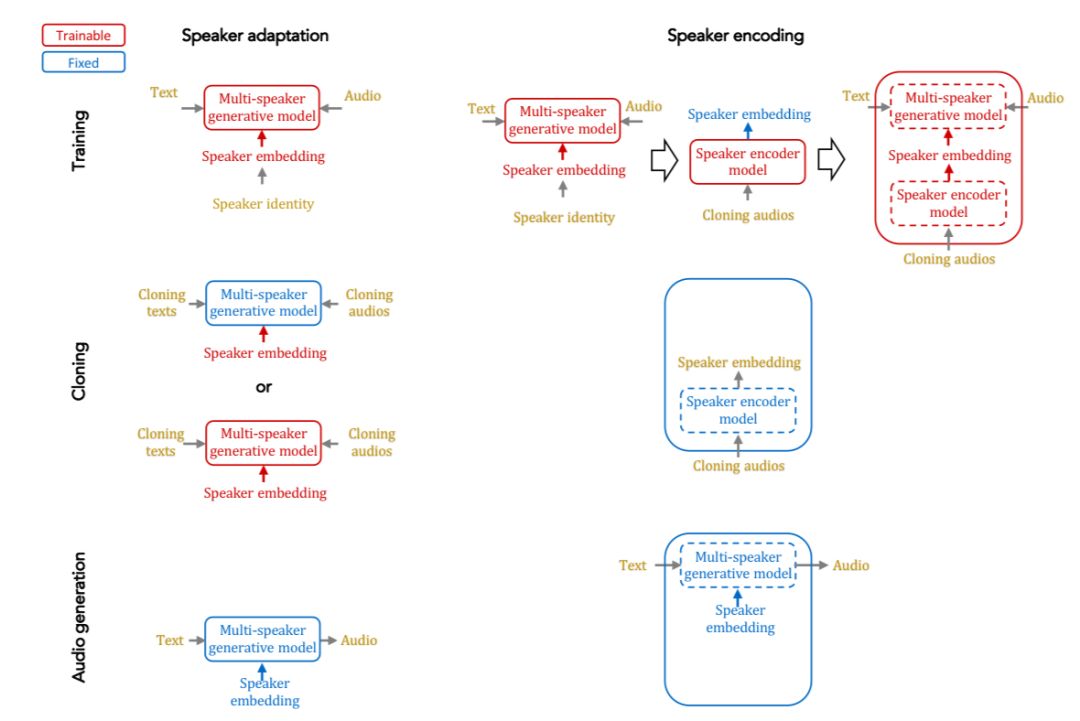
说话者适应运用的是梯度下降原理,利用少数音频和对应的文本对多语音模型进行微调,微调可以用于说话者嵌入或整个模型。
而说话者编码的方法是从说话者的音频样本中估计说话者嵌入。这种模式并不需要在语音克隆的过程中进行微调,因此它可以用于任何未知的说话者。
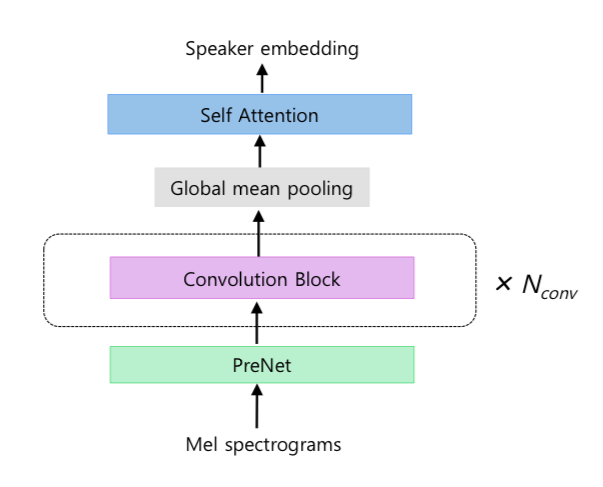
说话者编码器结构
语音克隆评估
语音克隆的结果可以通过众包平台经过人类进行评估,但是这样的模型开发过程是非常缓慢且昂贵的。研究人员利用判别模型提出了两种评估方法。
1.说话者分类(Speaker Classification)
说话者分类器决定音频样本的来源。对于语音克隆评估,说话者分类器可以在用于克隆的语音上进行训练。高质量的语音克隆有助于提高分类器的精确度。
2.说话者验证(Speaker Verification)
说话者验证是用来检测语音的相似性,具体来说,它利用二元分类识别测试音频和生成音频是否来自同一说话者。
实验过程
我们对比了两种方法(说话者适应和说话者编码)在语音克隆上的表现。对说话者适应,我们训练了一个生成模型,让其通过微调达到目标说话者的水平。对说话者编码,我们训练了一个多说话者生成模型和一个说话者编码器,将嵌入输入到多说话者生成模型中生成目标语音。
两种方法训练的数据集是LibriSpeech,该数据集包含2484个样本音频,总时长约820小时,16KHz。LibriSpeech是一个用于自动语音识别的数据集,它的音频质量比语音合成的数据集低。语音克隆是在VCTK数据集上进行的,其中包括了108种不同口音、以英语为母语的音频。为了与LibriSpeech保持一致,VCTK中的音频样本被压缩为16KHz。
下图总结了不同的方法在语音克隆上的表现:
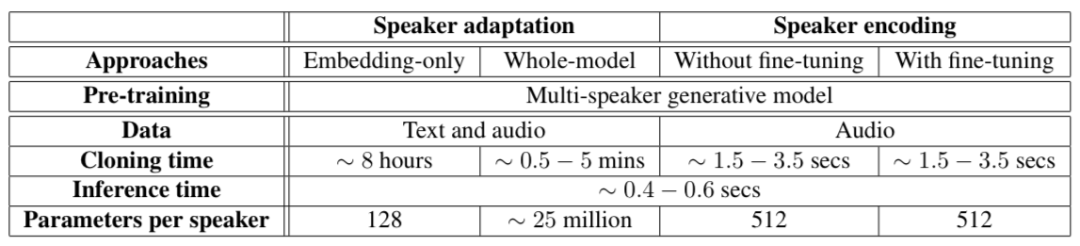
说话者适应和说话者编码在语音克隆上的不同需求。假设都在Titan X上进行
对于说话者适应的方法,下图表现了分类精确度与迭代时间的结果:
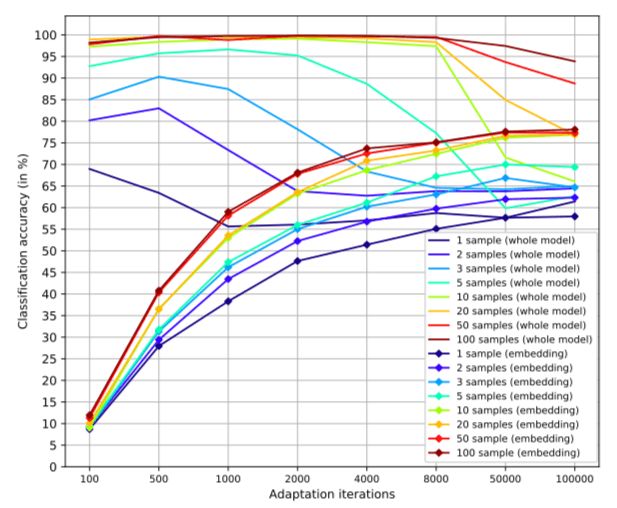
不同克隆样本数量和微调次数的关系图
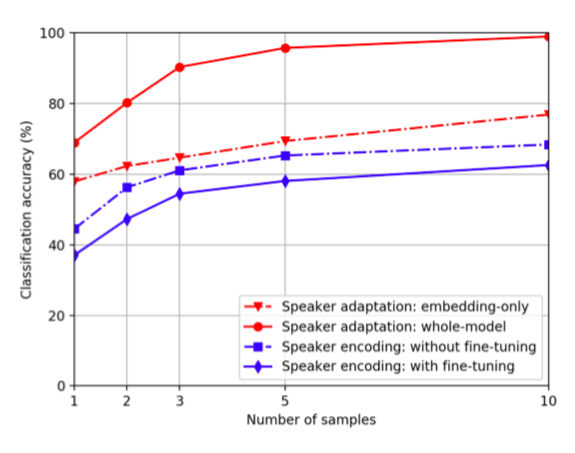
说话者适应和说话者编码在不同克隆样本下的分类精度对比
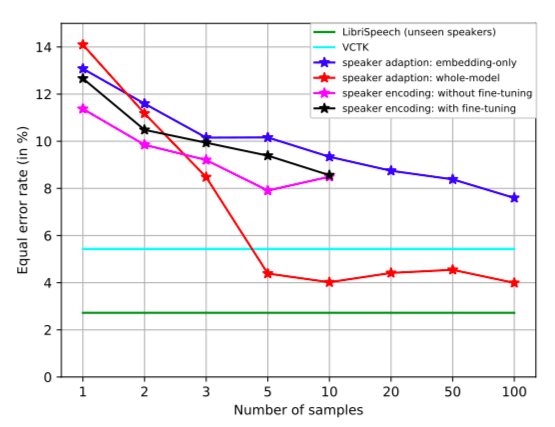
不同克隆样本数量下,说话者验证上的同等错误率(EER)
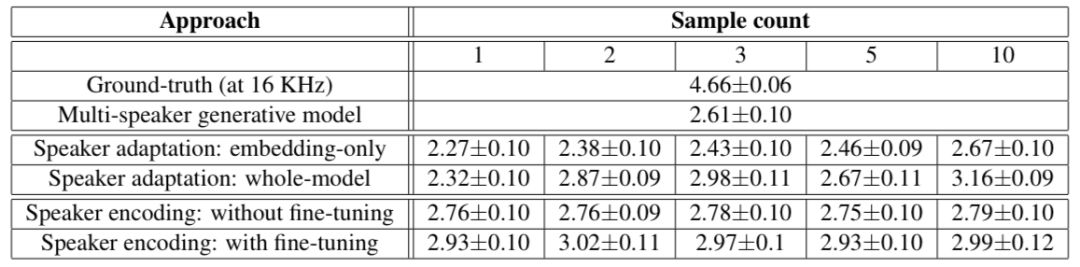
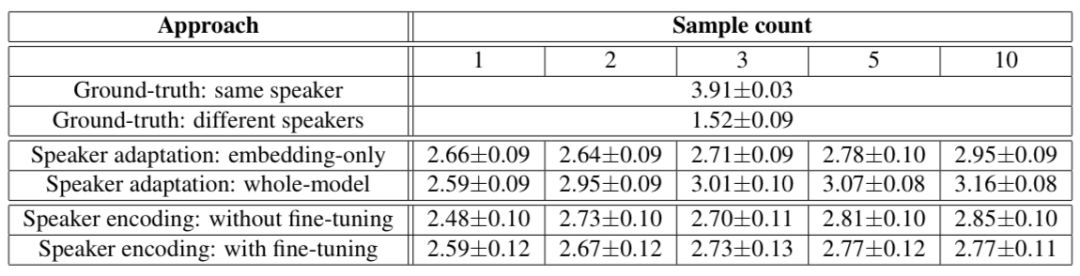
下面两个表显示了人类评估的结果,这两个结果都表明克隆音频越多,说话者适应的方法越好。
结语
研究人员通过两种方法,证明了他们可以用较少的声音样本生成自然、相似的新音频。他们相信,语音克隆在未来依然有改善的前景。随着元学习的进展,这一领域将得到有效的提高,例如,可以通过将说话者适应或编码这两种方法整合到训练中,或者通过比说话者嵌入更灵活的方式来推断模型权重。
-
编码器
+关注
关注
45文章
3638浏览量
134415 -
音频
+关注
关注
29文章
2868浏览量
81489
原文标题:百度研究者利用少量样本实现语音克隆
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于序贯相似性测算法的图像模板配准算法
基于相似性的图像融合质量的客观评估方法
基于相似性度量的高维聚类算法的研究
基于项目相似性度量方法的项目协同过滤推荐算法
基于网络本体语言OWL表示模型语义的相似性计算方法
一种基于SQL的图相似性查询方法
一种新的混合相似性权重的非局部均值去躁算法
基于划分思想的文件结构化相似性比较方法
云模型重叠度的相似性度量算法
基于节点相似性社团结构划分
一种基于程序向量树的代码克隆检测方法








 工商网监
工商网监
评论