 基于FPGA的异构计算是趋势
基于FPGA的异构计算是趋势
算起来,人工智能(AI)概念已经提出60多年了,而最近两年,得益于智能终端的普及带来的数据爆发式增长,以及深度学习、神经网络算法的发展,AI市场受到了空前的关注,但AI要得以快速普及,还缺少高算力的推动,需要提供更好的硬件加速条件。
2018年4月17日,业界领先的异构加速和业务卸载方案提供商杭州加速云信息技术有限公司在京举办了科技峰会及新产品发布会,隆重发布了四大创新产品(两个系列硬件加速产品(SC-OPS, SC-VPX)、两个IP库 (FDNN, FBLAS))及三大解决方案(深度学习解决方案、高性能计算及数字信号处理解决方案、边缘计算解决方案)。
抢先布局异构计算
杭州加速云信息技术有限公司创始人兼CEO邬刚是学习通信出身,最早跟随中国程控电话交换机之父邬江兴院士进入通信行业。两年之后,他加入了华为负责芯片设计。2007年开始创业,创办过3家公司,对CPU总线、多核处理器的发展有着清晰的理解。经过多年的积累和对未来市场的预估,2015年9月,邬刚先生创办了加速云。
杭州加速云信息技术有限公司创始人兼CEO 邬刚
加速云的解决方案可以广泛应用于深度学习、人工智能、金融、机器视觉等领域。目前已与阿里、腾讯、科大讯飞等多家企业开展深入合作。
“加速云是从技术上推导出来的一家公司,起源于2014年我们家迎来第一个小朋友,在陪产过程中形成的一个想法。” 邬刚先生提及创办加速云的心路历程,“在2014年,按照英特尔的发展,下一步一定是异构,我们当时认为异构,要么用GPU,要么用FPGA。英特尔在GPU上有一次失败尝试,加上GPU自身功耗太高等问题,FPGA会是异构计算的一个理想选择。”
事实上,在加速云诞生之初已经拥有强大的技术储备。基于FPGA来做异构计算是邬刚先生2014年4月就想出来的计划,直等到2014年10月英特尔在IDF大会上宣布x86+FPGA处理器,他认为这个机会点来了,11月份正式开始研究,到2015年4月,研发出了第一代原型机,2015年9月开始量产,加速云公司随之注册。
在深度学习中,做好算法只完成了1/3,在这个团队里面,既需要很强的实现算法的能力,还要有非常强的工程化能力,这种工程化的能力,包括接口和实现量产的能力。“我们知道做出一个东西很容易,但是做好还是挺难的。我们有一个非常小的板卡,迭代了四代,每一次迭代都要花百万人民币,因为硬件投入很大,每次迭代有可能只改了一点,我们发现未来可能存在的一些风险问题,就把它改掉,这是我们团队特别的地方。我们是一个工程化能力非常强的团队,整体技术行不行是我们最重要的考量。” 邬刚先生介绍。
基于FPGA的异构计算是趋势
目前处于AI大爆发时期,异构计算的选择主要在FPGA和GPU之间。尽管目前异构计算使用最多的是利用GPU来加速,FPGA作为一种高性能、低功耗的可编程芯片,在处理海量数据时,FPGA计算效率更高,优势更为突出,尤其在大量服务器部署时,隐形的运营成本会得到显著降低。
此外,低延迟、确定性延迟,也是FPGA天然的优势。
邬刚表示:“人工智能已经进入我们的生活,但是未来发展还存在瓶颈,需要硬件技术和算法方面的突破。异构计算是计算架构的未来趋势,而FPGA 是实现异构计算的完美选择。加速云创新的异构计算加速平台解决方案,具有高性能、高效率、低延时特性以及可编程性和远程可重构能力,非常适合云上的弹性业务的需求。我们希望能够通过我们的技术,帮助更多的企业实现深度学习,在大数据时代赢得先机。”
全球最高性能FPGA加速卡
SC-OPS是加速云推出的全球首张IntelStratix 10 FPGA加速卡,采用Intel最新14nm工艺的Stratix10 GX2800 FPGA器件,单板支持12个200维双精度线性方程求解,运算时间为466us,为x86系统60~120倍性能;单卡可以实现4500帧/S以上图像分类(采用AlexNet卷积神经网络模型,int16)。
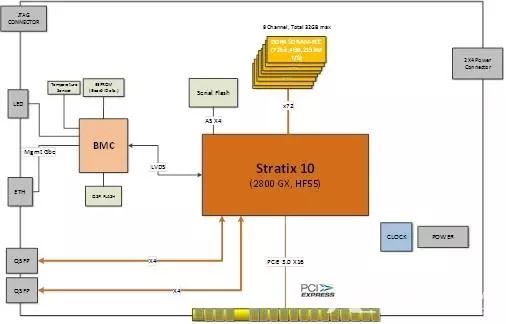
SC-OPS可以广泛应用于数据中心、云计算、机器视觉、深度学习、高性能计算、仿真、金融等领域。
全球最高集成度VPX业务卡
SC-VPX是全球计算密度最高的VPX刀片加速平台,采用Intel Stratix 10 GX2800器件,兼容GX1650,构造业界先进、灵活、高效的信号处理和深度学习架构,主要定位高校研究所等单位的雷达、通信、深度学习相关领域的产品原型快速搭建和算法开发与应用。
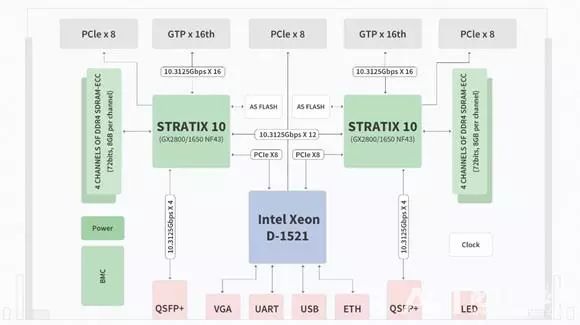
6U整机可以支持92T/50T FLOPS单精度浮点处理能力,整机可以通过交换板互联构筑更大的系统;支持OpenCL、Verilog开发,支持高性能计算库。
RTL级深度学习加速库
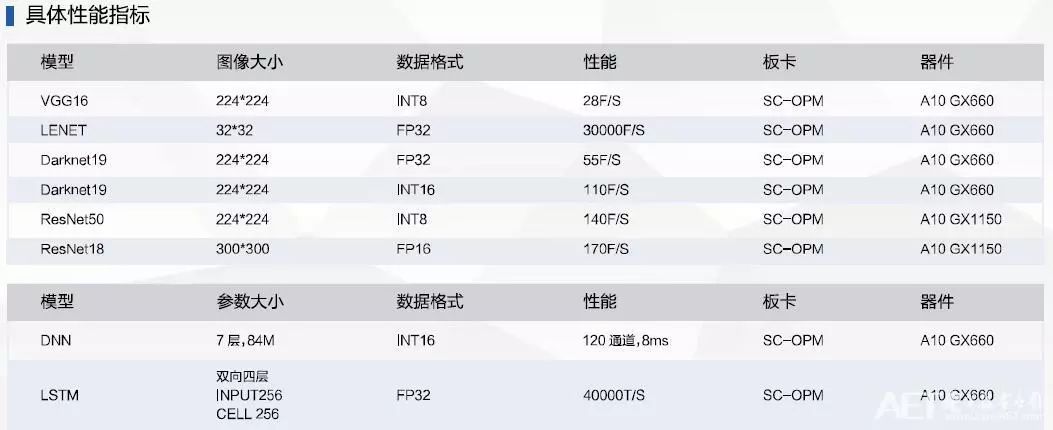
深度学习加速库FDNN是国内首个支持通用卷积神经网络的FPGA加速库,基于RTL级代码,可以提供很高的性能和灵活配置特性。
参数可配置的深度学习基础库:卷积、池化、全连接、非线性函数;兼容CAFFE/TensorFlow模型数据;常见各种模型:VGG16, Lenet, YOLO, SSD, ResNet。
RTL级高性能数学加速库
高性能计算加速库FBLAS是业界更高性能的RTL级数学加速库。参数可配的OpenBlas库Level2/3:矩阵乘、矩阵分解、矩阵求逆,线性方程求解、微分方程求解,三角函数、非线性求解、超越函数,傅里叶变换。
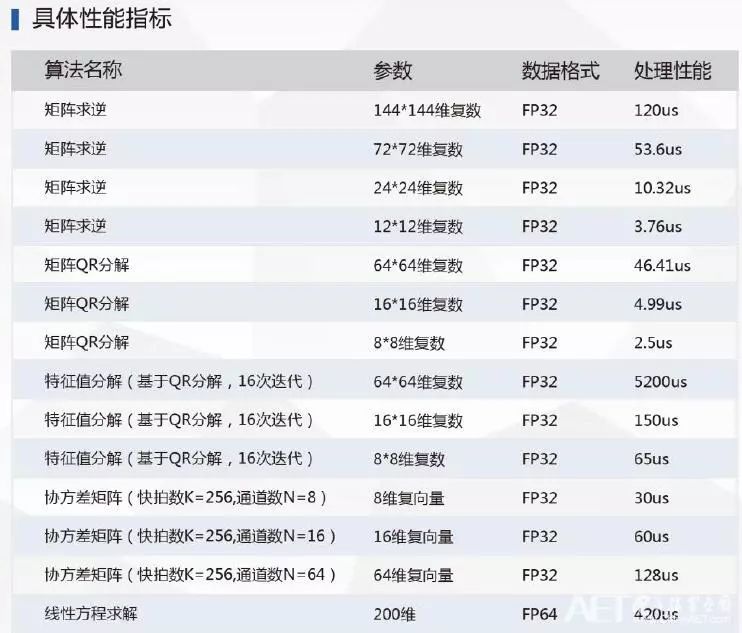
FDNN是专门为深度学习设计的,FBLAS更多是偏向于数字信号处理和高性能计算。
三大解决方案
•深度学习加速解决方案-加速云推出一整套基于FPGA的深度学习加速方案,包括SC-OPM/SC-OPF/SC-OPS加速卡及FDNN加速库,满足客户对深度学习高性能、灵活性加速要求。为了方便客户使用高层语言开发,加速云提供基于FPGA完整的OpenCL异构开发环境,快速实现用户自定义的深度学习加速方案。同时加速云也提供快速深度神经网络定制加速服务。
•数字信号处理解决方案-针对雷达、通信等数字信号处理系统的要求,结合Intel最新14nm工艺的 Stratix10 FPGA系列,加速云提供了一套完整的硬件和软件相结合的解决方案,实现了高性能矩阵运算(矩阵乘、转置、求逆、QR分解)和超高速FFT(傅立叶变换)。为了方便客户使用高层语言开发,加速云提供基于FPGA完整的OpenCL异构开发环境,快速实现用户自定义的信号处理加速方案。
•边缘计算解决方案-加速云智能工控解决方案采用高性能Intel Arria10 GX660器件, 具有模块化设计,强实时特性和高性能的算法IP加速、完整的OpenCL异构开发环境,可以实现新一代高性能边缘计算网关,应用于各种工业环境。
加速云最核心的竞争力在于其IP方面,除了用于数字信号处理和高性能计算的数学库FBLAS,以及用于深度学习的FDNN库,还具有很多接口类的IP(高速通信接口、视频接口)、协议类IP(压缩、解压缩、加解密),研发团队在FPGA方面有着十多年的经验,积累了很多相关的IP。
凭借自身在FPGA上的技术优势,加速云获得合作伙伴的大力支持,可以率先拿到英特尔第一批流片的内部测试芯片,对加速云保持技术领先非常重要。
北京站是加速云“加速新科技,驱动智未来” 科技峰会的首站,接下来加速云将在上海、成都、西安三大城市分享其最新成果。过去两年,加速云平均每年都有获得一次融资,据悉,第三轮融资正在达成。
- FPGA
+关注
关注
1620文章
21483浏览量
598159 - 人工智能
+关注
关注
1787文章
45875浏览量
234297 - 深度学习
+关注
关注
73文章
5415浏览量
120483
原文标题:【市场观察】异构看好FPGA 加速云要为AI高算力加速
文章出处:【微信号:ChinaAET,微信公众号:电子技术应用ChinaAET】欢迎添加关注!文章转载请注明出处。
发布评论请先登录
相关推荐
打造异构计算新标杆!国数集联发布首款CXL混合资源池参考设计

AvaotaA1全志T527开发板AMP异构计算简介
异构计算:解锁算力潜能的新途径

AI服务器异构计算深度解读

FPGA异构计算架构的深度对比研究

高通NPU和异构计算提升生成式AI性能
LTM4620给fpga提供1.0V内核电源,4620输出电容量计算是否应该包含布局在fpga芯片附近的bulk电容?
燧原科技与青云科技达成战略合作,创新异构算力调度
科学计算与Julia技术研讨会 | 张先轶:从OpenBLAS到异构计算软件栈

什么是异构集成?什么是异构计算?异构集成、异构计算的关系?
国产FPGA简介
异构计算为什么会异军突起?基于FPGA的异构计算讨论
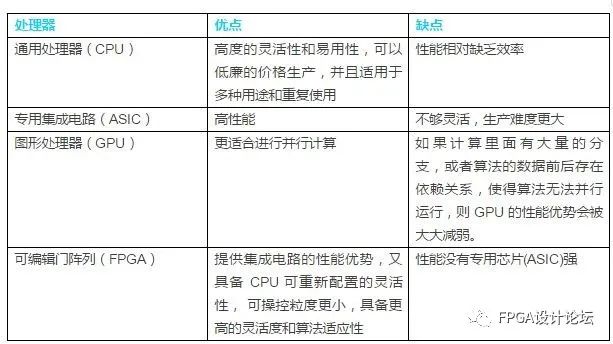
异构时代:CPU与GPU的发展演变
SOLIDWORKS仿真计算是什么意思?





 工商网监
工商网监
评论