 基于内容推荐(CB)的推荐算法
基于内容推荐(CB)的推荐算法
基于内容推荐概要
基于内容的信息推荐方法的理论依据主要来自于信息检索和信息过滤,所谓的基于内容的推荐方法就是根据用户过去的浏览记录来向用户推荐用户没有接触过的推荐项。主要是从两个方法来描述基于内容的推荐方法:启发式的方法和基于模型的方法。启发式的方法就是用户凭借经验来定义相关的计算公式,然后再根据公式的计算结果和实际的结果进行验证,然后再不断修改公式以达到最终目的。而对于模型的方法就是根据以往的数据作为数据集,然后根据这个数据集来学习出一个模型。一般的推荐系统中运用到的启发式的方法就是使用tf-idf的方法来计算,跟还有tf-idf的方法计算出这个文档中出现权重比较高的关键字作为描述用户特征,并使用这些关键字作为描述用户特征的向量;然后再根据被推荐项中的权重高的关键字来作为推荐项的属性特征,然后再将这个两个向量最相近的(与用户特征的向量计算得分最高)的项推荐给用户。在计算用户特征向量和被推荐项的特征向量的相似性时,一般使用的是cosine方法,计算两个向量之间夹角的cosine值。
基于内容推荐的步骤
1、对数据内容分析,得到物品的结构化描述
2、分析用户过去的评分或评论过的物品的,作为用户的训练样本
3、生成用户画像
a.可以是统计的结果(后面使用相似度计算)
b.也可以是一个预测模型(后面使用分类预测计算)
4、新的物品到来,分析新物品的物品画像
5、利用用户画像构建的预测模型,预测是否应该推荐给用户U
a.策略1:相似度计算
b.策略2:分类器做预测
6、进一步,预测模型可以计算出用户对新物品的兴趣度,进而排序
7、进一步,用户模型在变化,通过反馈更新用户画像(用户画像在这里就是预测模型)
反馈-学习,构成了用户画像的动态变化
基于内容推荐的层次结构
* 内容分析器
文档的数据处理
得到结构化的数据,存储在物品库中
* 信息学习器
收集有关用户偏好的数据特征,泛华这些数据,构建用户特征信息(机器学习)
通过历史数据构建用户兴趣模型(通过分类的方法,提取特征,特征就是组建用户画像的基础)
生成兴趣特征(正样本)和无兴趣特征(负样本)
* 过滤组件
将用户的个人信息和物品匹配
生成二元或连续性的相关判断(原型向量和物品向量的余弦相似度)
基于内容推荐(CB)的推荐算法
就目前看,Collaborative Filtering Recommendations (协同过滤,简称CF) 还是目前最流行的推荐方法,在研究界和工业界得到大量使用。但是,工业界真正使用的系统一般都不会只有CF推荐算法,Content-based Recommendations (基于内容推荐,CB) 基本也会是其中的一部分。
CB根据用户过去喜欢的产品(items),为用户推荐和他过去喜欢的产品相似的产品。例如,一个推荐饭店的系统可以依据某个用户之前喜欢很多的烤肉店而为他推荐烤肉店。 CB最早主要是应用在信息检索系统当中,所以很多信息检索及信息过滤里的方法都能用于CB中。
推荐过程:
CB的推荐过程一般包括下面三步:
Item Representation:即对items做特征工程,通俗来说即对items的属性表达出来,如item = 农夫山泉(品类:矿泉水,价格:1-5,etc);
Profile Learning:利用一个用户(id)过去喜欢(以及不喜欢)的item的特征数据,来学习出此用户的喜好特征(profile),如id=我,喜欢=(农夫山泉,麦当劳),不喜欢=(槟榔,香烟),etc。
Recommendation Generation:通过比较上一步得到的用户profile与候选item的特征,为此用户推荐一组相关性最大的item。
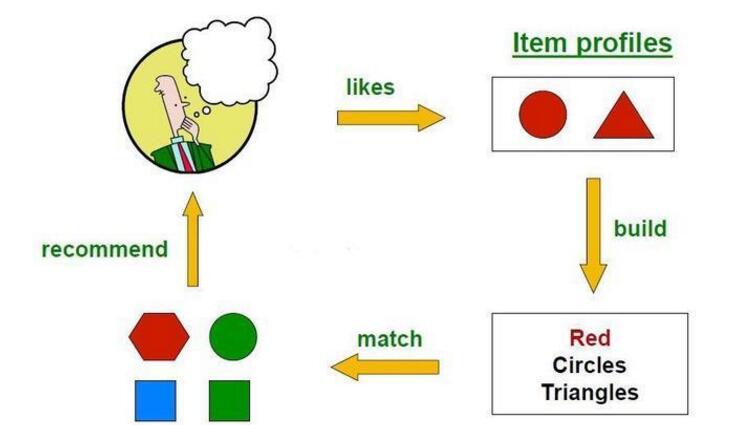
例子:
对于个性化阅读来说,一个item就是一篇文章,第一步我们要提取文章中的关键词组来表示文章的主题,可以采用的方法例如TF-IDF找文章中词的权重,例如在python文章中“python”是主要被提及的字眼,那么该词是关键字,利用这种方法,我们就可以把文章向量化。第二步是找出用户之前喜欢的文章,通过上述TF-IDF方法,将其向量化,然后求平均值,来代表用户大致喜欢的文章。如果用户喜欢python语言,那么该用户的profile中[‘python’]的权重占比较大。第三步就是通过以上二步得到的所有item和该用户的profile进行匹配,计算方式一般用余弦相似度。
详细过程
1.Item Representation
Item一般都会有一些描述它的属性。这些属性通常可以分为两种:结构化(structured)和非结构化(unstructured)属性。所谓结构化属性就是可以被量化,可直接使用的属性,如人有性别、学历、地域等属性。而非结构化属性就是需要再进行二次解析,无法直接利用的属性,如人的购买记录,一篇文章的内容等。像文章这种非结构化数据可以利用TF-IDF和word2vec等算法把文章中的关键词向量化表示出来。
如果用TF-IDF表示文章对应关键词的权重,那么可以得到以下矩阵:
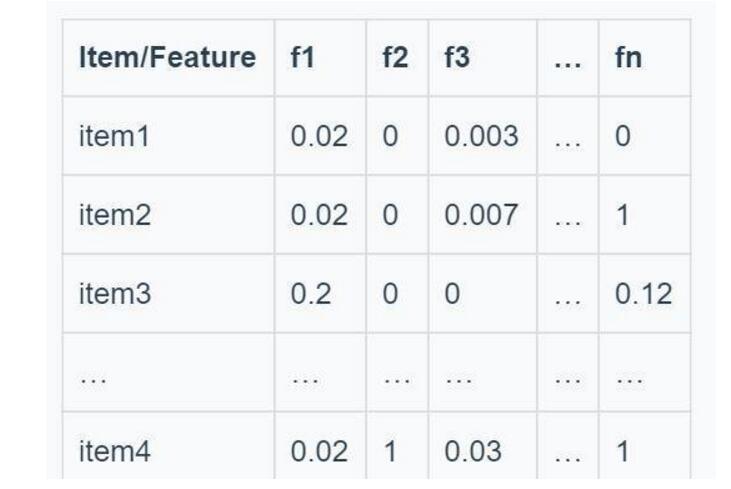
2.Profile Learning
假设用户(id)已经对一些item做出了喜欢的判断,对另一部分item做出了不喜欢的判断,且这些item我们已经有了对应的向量化表示,那么这就是用户的profile,如何简单计算用户的profile呢?公式如下:
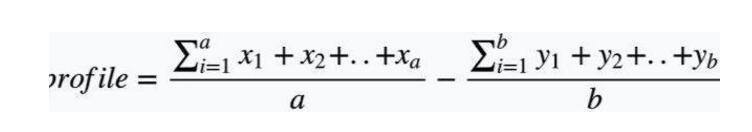
其中x是用户喜欢的item,a是喜欢item的总数,y是用户不喜欢的item,b是不喜欢item的总数。这时我们得到另一个用户矩阵:(当然这里不是协同过滤,无需把全部用户列成矩阵项,实际应用单个用户id即可)
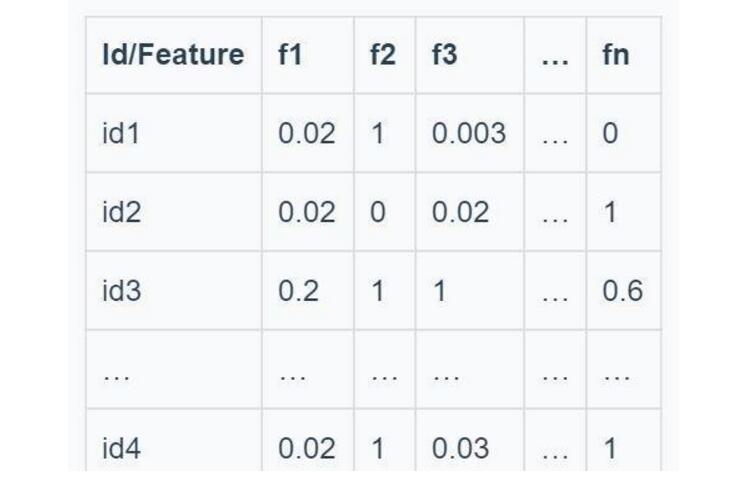
3.Recommendation Generation
通过以上二步得到的所有item和所有用户的profile,那么要对一个用户的profile和所有item进行匹配,此时我们计算的方式一般用余弦相似度。余弦相似度的计算方法如下,假设向量a、b的坐标分别为(x1,y1)、(x2,y2) 。则:
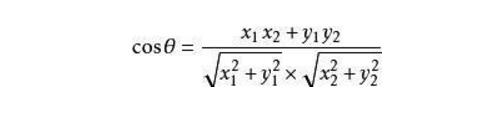
余弦值的范围在[-1,1]之间,值越趋近于1,代表两个向量的方向越接近;越趋近于-1,他们的方向越相反。如上述例子我们可以计算以下结果:
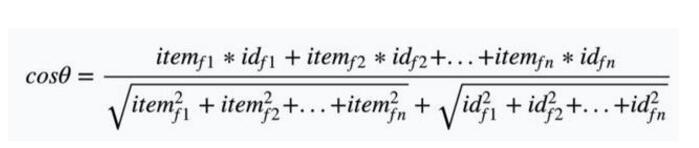
所以最终会把余弦值最大(跟用户最相关的文章)的前N篇推荐给用户。
优缺点
优点:可以使用当前的用户评价来构建用户的个人信息;由于过程简单解释性强,推荐的结果容易被人接受;对于新物品来没有任何用户评分的也可以推荐给用户。
缺点:可分析的内容有限,且新颖度较差,新用户需要用户的偏好信息,无法解决冷启动问题。
-
推荐算法
+关注
关注
0文章
47浏览量
9992
发布评论请先 登录
相关推荐
【「从算法到电路—数字芯片算法的电路实现」阅读体验】+内容简介

基于BitTorrent种子的内容分发算法
基于内容的推荐算法概览

基于位串内容感知的数据分块算法

ASMT-CB00 直角ChipLED







 工商网监
工商网监
评论