 用深度学习分析电子病历 进行临床预测
用深度学习分析电子病历 进行临床预测
如今利用机器学习预测事态发展已经非常普遍。我们可以用它预测通勤途中的交通状况,以及将英文翻译成西班牙语时需要用到的词汇。那么,我们是否可以用相同类型的机器学习进行临床预测呢?我们认为,要做到实用,预测模型必须具备以下两点特征:
可扩展:该预测模型要能进行多项预测,得出所有我们想要的信息,并且适用于不同医院的系统。鉴于医疗保健数据十分复杂,需要进行大量数据处理,这一要求并不容易满足。
精度高:预测结果需能帮助医生关注真正的问题所在,而不是用误报警分散医生的注意力。随着电子病历逐渐普及,我们正尝试用其中的数据建立更加精准的预测模型。
我们联合加州大学旧金山分校、斯坦福大学医学院和芝加哥大学医学院的同事,在《自然》杂志的兄弟期刊——《数字医学》上发表了题为《可扩展且精准的深度学习与电子健康记录》的论文。这篇论文对实现前文所述的两个目标有所帮助。
基于脱敏的电子病历数据,我们用深度学习模型对住院患者进行了广泛预测。值得一提的是,该模型可以直接使用原始数据,无需人工对相关变量进行提取、清洗、整理、转换等一系列费时费力的操作。合作伙伴在将电子病历数据交给我们之前,先对其进行了脱敏处理。我们也采用了最先进的措施保障数据安全,包括逻辑分隔、严格的访问控制,以及静态和传输中的数据加密。
可扩展性
电子病历非常复杂。以体温为例,因测量位置不同(舌头下方、耳膜或额头),其往往具有不同含义。而体温不过是电子病历众多参数中最简单的之一。此外,各个卫生系统都有一套自己定制的电子病例系统,导致各个医院的采集的数据大不相同。用机器学习处理这些数据之前,需要先将其统一格式。基于开放的FHIR标准,我们构建了一套标准格式。
格式统一后,我们就不需要手动选择或调整相关变量了。进行各项预测时,深度学习模型会自动扫描过去到现在的所有数据点,并分析其中哪些数据对预测是有价值的。由于这一过程涉及数千个数据点,我们不得不开发了一些基于递归神经网络(RNN)和前馈网络的新型深度学习建模方法。
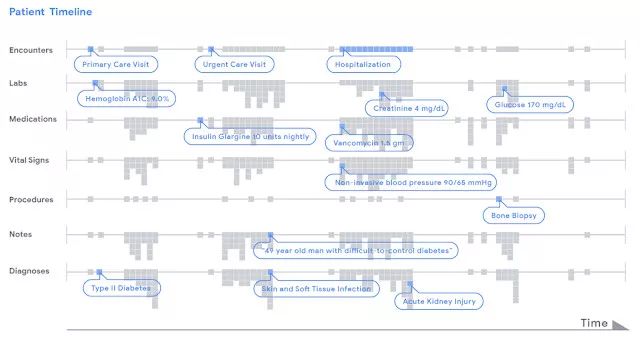
*我们用时间线来展示患者电子病历中的数据。为方便说明,我们按行显示各种类型的临床数据,其中每个数据片段都用灰点表示,它们被存储在FHIR中。FHIR是一种可供任何医疗机构使用的开放式数据标准。深度学习模型通过从左往右扫描时间表,分析患者从图标开头到现在的住院信息,并据此进行不同类型的预测。
就这样我们设计了一个计算机系统,以可扩展的方式进行预测,而无需为每项预测任务手动制作新的数据集。设置数据只是全部工作中的一部分,保证预测的准确性也十分重要。
准确性
评估准确性的最常见方法是受试者工作曲线下面积,它可以有效评估模型区分特定未来结果患者和非特定未来结果患者的效果。 在这个度量标准中,1.00代表完美,0.50代表不比随机结果更准确,也就是说得分越高代表模型越准确。通过测试,我们的模型在预测患者是否会在医院停留很久时,得分为0.86(传统逻辑回归模型的评分为0.76);预测住院病死率时的得分为0.95(传统模型的得分为0.86);预测出院后意外再住院率时得分为0.77(传统模型得分为0.70)。从得分上看,新方法的准确率提升非常显著。
我们还用这些模型来确定患者接受的治疗,比如医生为发烧、咳嗽的患者开具头孢曲松和强力霉素,该模型就会判定患者正在接受肺炎治疗。必须强调,该模型并不会给患者做诊断,它只是收集患者的相关信号,以及临床医生编写的治疗方案和笔记。因此,它更像是一位优秀的听众而不是主诊医生。
深度学习模型的可解释性是我们工作重点之一。每项预测的“注意图”会展示模型在进行该项预测时认为重要的那些数据点。我将展示一个例子作为概念验证,并将其视为让预测对临床医生产生价值的重要部分。
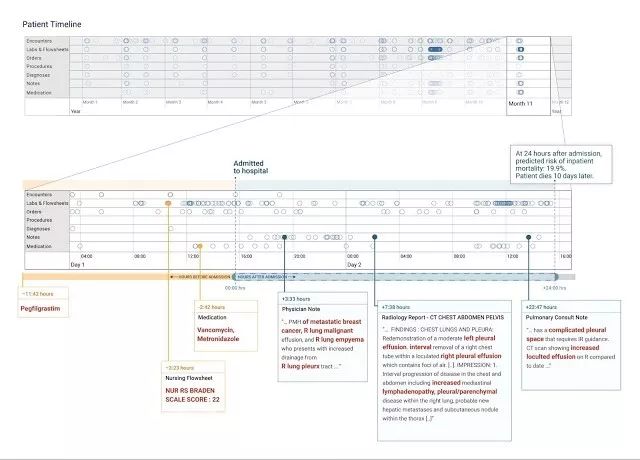
*患者入院24小时后,我们使用深度学习进行预测。上图顶部的时间表包含了患者几个月时间的历史数据,我们将最近的数据做了放大显示。模型用红色标识了患者信息图表中用于“解释”其预测的信息。在这个研究案例中,模型标注了临床上有意义的信息片段。
这对患者和临床医生意味着什么?
这项研究成果还处于早期阶段,而且是基于回顾性数据得出的。事实上,证明机器学习可用于改善医疗保健这一假设还有做很多工作要做,本文不过是个开始。医生们正穷于应付各种警报和需求,机器学习模型是否能帮助处理繁琐的管理任务,让他们更专注于护理有需要的患者?我们是否可以帮助患者获得高质量的护理,无论他们在哪里寻求治疗?我们期待着与医生和患者合作,找出这些问题的答案。
-
深度学习
+关注
关注
73文章
5500浏览量
121111
原文标题:GGAI 前沿 | Google医疗AI新成果:用深度学习分析电子病历 预测患者病情发展
文章出处:【微信号:ggservicerobot,微信公众号:高工智能未来】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
NPU在深度学习中的应用

FPGA加速深度学习模型的案例
AI大模型与深度学习的关系
FPGA做深度学习能走多远?
电磁轨迹预测分析系统设计方案
利用Matlab函数实现深度学习算法
深度学习中的时间序列分类方法
深度学习中的无监督学习方法综述
深度学习常用的Python库
深度学习模型训练过程详解
深度学习与传统机器学习的对比
电磁轨迹预测分析系统
【技术科普】主流的深度学习模型有哪些?AI开发工程师必备!






 工商网监
工商网监
评论