 Python无监督学习的几种聚类算法包括K-Means聚类,分层聚类等详细概述
Python无监督学习的几种聚类算法包括K-Means聚类,分层聚类等详细概述
无监督学习是机器学习技术中的一类,用于发现数据中的模式。本文介绍用Python进行无监督学习的几种聚类算法,包括K-Means聚类、分层聚类、t-SNE聚类、DBSCAN聚类等。
无监督算法的数据没有标注,这意味着只提供输入变量(X),没有相应的输出变量。在无监督学习中,算法自己去发现数据中有意义的结构。
Facebook首席AI科学家Yan Lecun解释说,无监督学习——即教机器自己学习,不需要明确地告诉它们所做的每一件事情是对还是错,是“真正的”AI的关键。
监督学习 VS 无监督学习
在监督学习中,系统试图从之前给出的例子中学习。反之,在无监督学习中,系统试图从给出的例子中直接找到模式。因此,如果数据集有标记,那么它是有监督问题,如果数据集无标记,那么它是一个无监督问题。
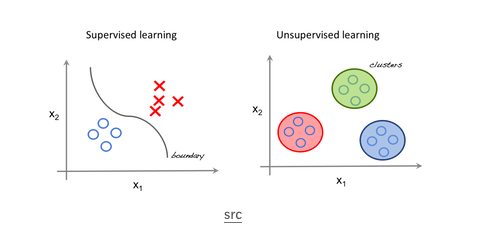
如上图,左边是监督学习的例子; 我们使用回归技术来寻找特征之间的最佳拟合线。而在无监督学习中,输入是基于特征分离的,预测则取决于它属于哪个聚类(cluster)。
重要术语
特征(Feature):用于进行预测的输入变量。
预测(Predictions):当提供一个输入示例时,模型的输出。
示例(Example):数据集的一行。一个示例包含一个或多个特征,可能有标签。
标签(Label):特征的结果。
为无监督学习做准备
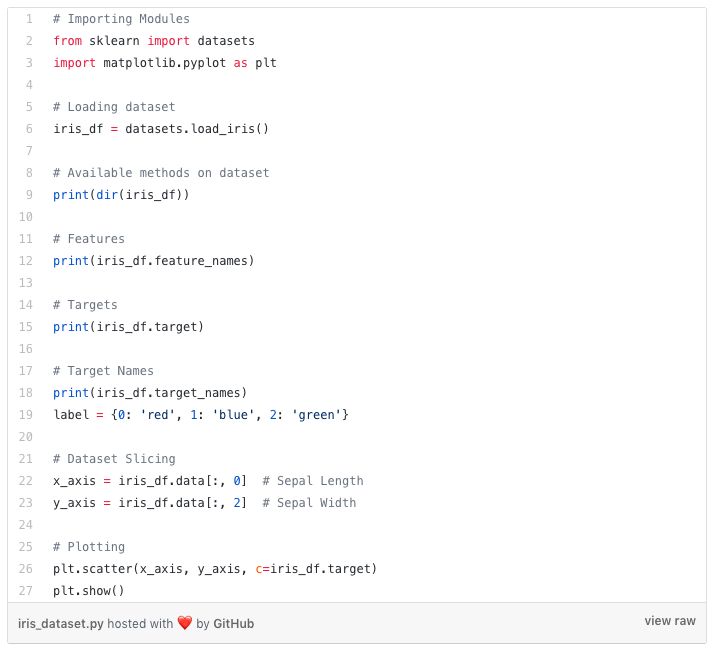
在本文中,我们使用Iris数据集(鸢尾花卉数据集)来进行我们的第一次预测。该数据集包含150条记录的一组数据,有5个属性——花瓣长度,花瓣宽度,萼片长度,萼片宽度和类别。三个类别分别是Iris Setosa(山鸢尾),Iris Virginica(维吉尼亚鸢尾)和Iris Versicolor(变色鸢尾)。对于我们的无监督算法,我们给出鸢尾花的这四个特征,并预测它属于哪一类。我们在Python中使用sklearn Library来加载Iris数据集,并使用matplotlib来进行数据可视化。以下是代码片段。

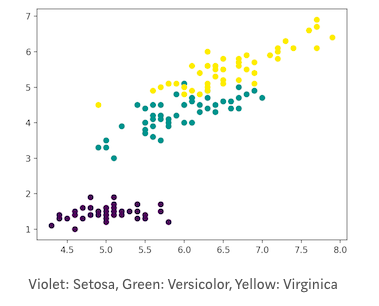
紫罗兰色:山鸢尾,绿色:维吉尼亚鸢尾,黄色:变色鸢尾
聚类(Clustering)
在聚类中,数据被分成几个组。简单地说,其目的是将具有相似特征的组分开,并将它们组成聚类。
可视化示例:
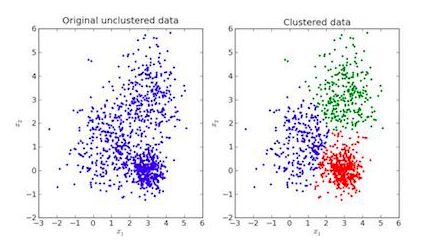
在上图中,左边的图像是未完成分类的原始数据,右边的图像是聚类的(根据数据的特征对数据进行分类)。当给出要预测的输入时,就会根据它的特征在它所属的聚类中进行检查,并做出预测。
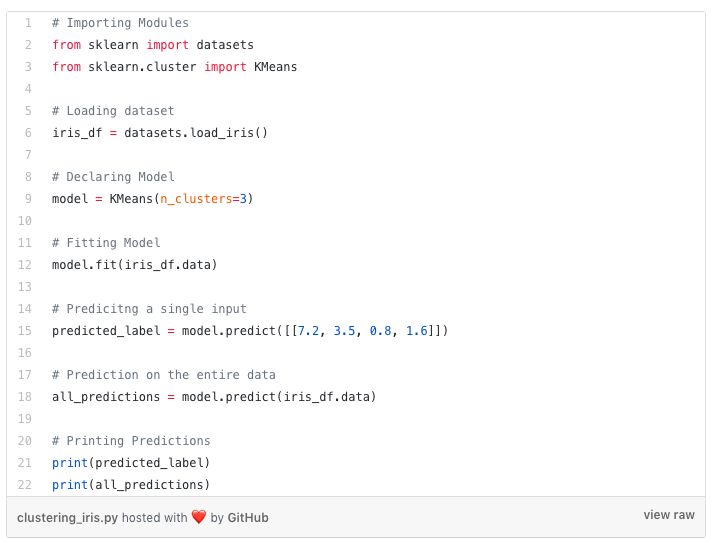
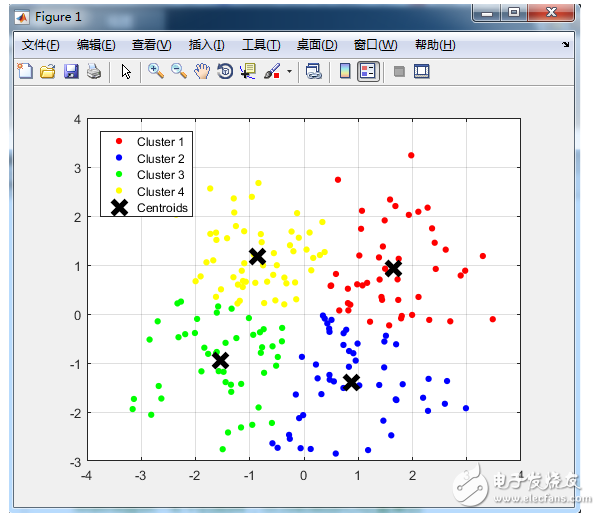
Python中的K-Means聚类
K-Means是一种迭代聚类算法,它的目的是在每次迭代中找到局部最大值。首先,选择所需数量的聚类。由于我们已经知道涉及3个类,因此我们通过将参数“n_clusters”传递到K-Means模型中,将数据分组为3个类。
现在,随机将三个点(输入)分成三个聚类。基于每个点之间的质心距离,下一个给定的输入被分为所需的聚类。然后,重新计算所有聚类的质心。
聚类的每个质心是特征值的集合,定义生成的组。检查质心特征权重可以定性地解释每个聚类代表什么类型的组。
我们从sklearn库导入K-Means模型,拟合特征并进行预测。
Python中的K Means实现:

分层聚类
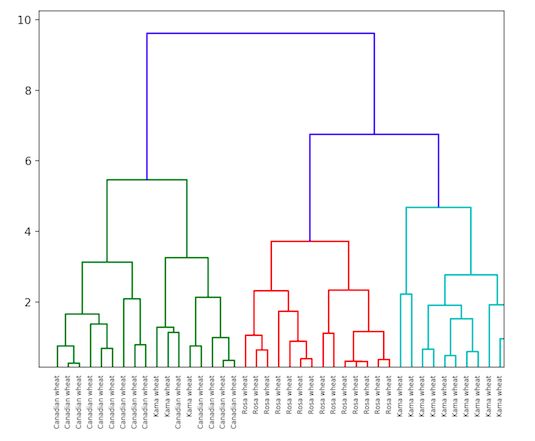
顾名思义,分层聚类是一种构建聚类层次结构的算法。该算法从分配给它们自己的一个cluster的所有数据开始,然后将最近的两个cluster加入同一个cluster。最后,当只剩下一个cluster时,算法结束。
分层聚类的完成可以使用树状图来表示。下面是一个分层聚类的例子。 数据集可以在这里找到:https://raw.githubusercontent.com/vihar/unsupervised-learning-with-python/master/seeds-less-rows.csv
Python中的分层聚类实现:

K Means聚类与分层聚类的区别
分层聚类不能很好地处理大数据,但K Means聚类可以。因为K Means的时间复杂度是线性的,即O(n),而分层聚类的时间复杂度是二次的,即O(n2)。
在K Means聚类中,当我们从聚类的任意选择开始时,多次运行算法产生的结果可能会有所不同。不过结果可以在分层聚类中重现。
当聚类的形状是超球形时(如2D中的圆形,3D中的球形),K Means聚类更好。
K-Means聚类不允许嘈杂的数据,而在分层聚类中,可以直接使用嘈杂的数据集进行聚类。
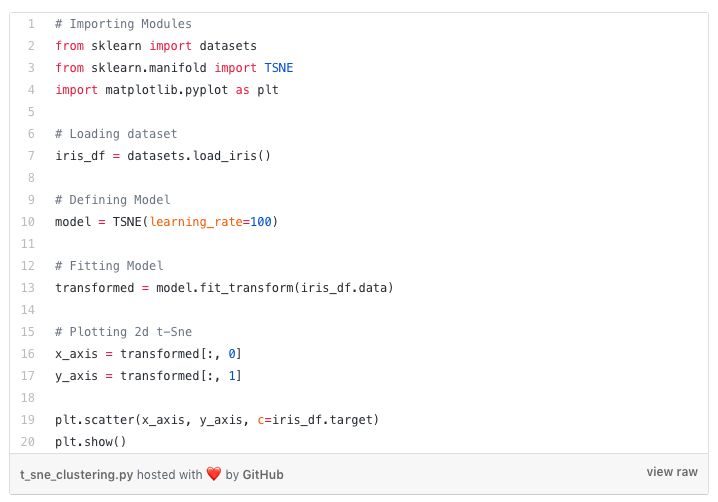
t-SNE聚类
t-SNE聚类是用于可视化的无监督学习方法之一。t-SNE表示t分布的随机近邻嵌入。它将高维空间映射到可以可视化的2或3维空间。具体而言,它通过二维点或三维点对每个高维对象进行建模,使得相似的对象由附近的点建模,而不相似的对象很大概率由远离的点建模。
Python中的t-SNE聚类实现,数据集是Iris数据集:
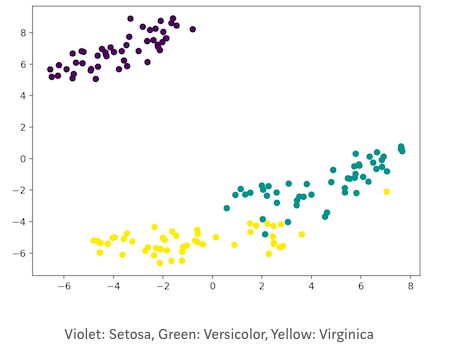
这里Iris数据集具有四个特征(4d),它被变换并以二维图形表示。类似地,t-SNE模型可以应用于具有n个特征的数据集。
DBSCAN聚类
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种流行的聚类算法,用作预测分析中 K-means的替代。它不要求输入聚类的数值才能运行。但作为交换,你必须调整其他两个参数。
scikit-learn实现提供了eps和min_samples参数的默认值,但这些参数通常需要调整。eps参数是在同一邻域中考虑的两个数据点之间的最大距离。min_samples参数是被认为是聚类的邻域中的数据点的最小量。
Python中的DBSCAN聚类:
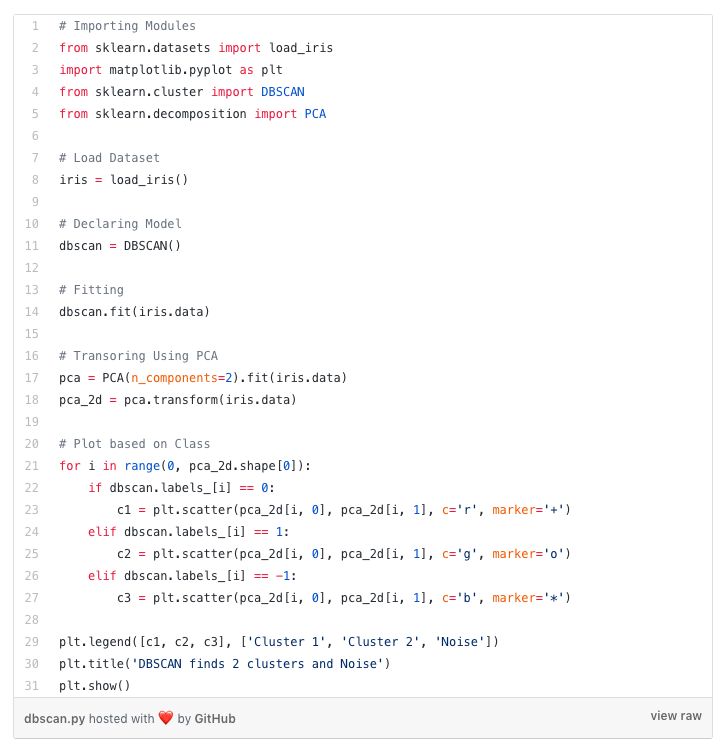
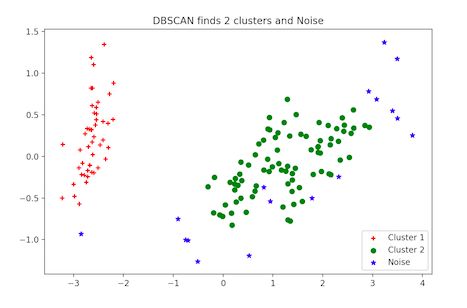
-
聚类算法
+关注
关注
2文章
118浏览量
12126 -
机器学习
+关注
关注
66文章
8406浏览量
132553 -
python
+关注
关注
56文章
4792浏览量
84623 -
无监督学习
+关注
关注
1文章
16浏览量
2754
原文标题:【干货】Python无监督学习的4大聚类算法
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐







 工商网监
工商网监
评论