 斯坦福提出基于目标的策略强化学习方法——SOORL
斯坦福提出基于目标的策略强化学习方法——SOORL
人类的学习能力一直是人工智能追求的目标,但就目前而言,算法的学习速度还远远不如人类。为了达到人类学习的速率,斯坦福的研究人员们提出了一种基于目标的策略强化学习方法——SOORL,把重点放在对策略的探索和模型选择上。以下是论智带来的编译。

假设让一个十二岁的孩子玩一下午雅达利游戏,就算他之前从没玩过,晚饭前也足以掌握游戏规则。Pitfall!是是雅达利2600上销量最高的游戏之一,它的难度很高,玩家控制着一个名为“哈里”的角色,他要在20分钟内穿过丛林,找到32个宝藏。一路上共有255个场景(rooms),其中会碰到许多危险,例如陷阱、流沙、滚动的枕木、火焰、蛇以及蝎子等。最近的奖励也要在起始点7个场景之外,所以奖励分布非常稀疏,即使对人类来说,没有经验也很难操控。
深度神经网络和强化学习这对cp在模仿人类打游戏方面可谓是取得了不小的进步。但是这些智能体往往需要数百万个步骤进行训练,但是人类在学习新事物时效率可要高多了。我们是如何快速学习高效的奖励的,又是怎样让智能体做到同样水平的?
有人认为,人们学习并利用能解释世界如何运行的结构化模型,以及能用目标而不是像素表示世界的模型,从而智能体也能靠同样的方法从中获得经验。
具体来说,我们假设同时具备三个要素即可:运用抽象的目标水平的表示、学习能快速学习世界动态并支持快速计划的模型、利用前瞻计划进行基于模型的策略探索。
在这一思想的启发下,我们提出了策略目标强化学习(SOORL)算法,据我们所知,这是第一个能在雅达利游戏Pitfall!中能到积极奖励的算法。重要的是,该算法在这一过程中不需要人类的示范,可以闯过50关。SOORL算法利用强大的先验知识而非传统的深度强化学习算法,对环境中的目标和潜在的动态模型有了了解。但是相比于需要人类示范的方法来说,SOORL算法所掌握的信息就少了很多。
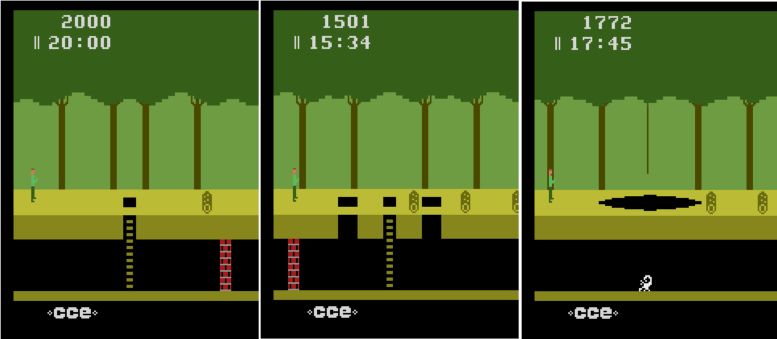
SOORL在两方面超过了之前以目标为导向的强化学习方法:
智能体在积极尝试选择一种简单模式,该模式解释了世界是如何运作的从而看起来是决定性的。
智能体用一种基于模型的积极计划方法,在做决定时假设智能体不会计算出一个完美的计划来应对即使知道世界怎样运作后会有何反应。
这两种方法都是从人类遇到的困难中受到的启发——先前经验很少,同时算力有限,人类必须快速学习做出正确的决定。为了达到这一目标,我们第一条方法发现,与复杂的、需要大量数据的深度神经网络模型不同,如果玩家按下的某一按键需要很少经验来估计,那么简单的决定性模型可以减少计划所需的计算力,尽管会经常出错,但对达到良好的效果已经足够了。第二,在奖励分散、复杂的电子游戏中,玩一场游戏可能需要成百上千个步骤,对于任何一个计算力有限的智能体来说,想在每个步骤都作出合适的计划是非常困难的,就算是12岁的小孩也是如此。我们用一种常用并且强大的方法做前瞻计划,即蒙特卡洛树搜索,将其与目标导向的方法结合,用作最优策略的探索,同时指导智能体学习它不了解的世界的环境。
Pitfall!也许是智能体最后一个尚未攻破的雅达利游戏。如文章开头所说,Pitfall!中的第一个积极奖励出现多个场景之后,玩家需要非常小心地操作才能得到,这就需要智能体在闯关时具备策划能力和对未来的预见能力。
我们的SOORL智能体在50回中的平均可以解锁17个场景,而之前的用像素作为输入、同时又没有策略探索的DDQN标准在2000回之后的平均只能解锁6个场景。
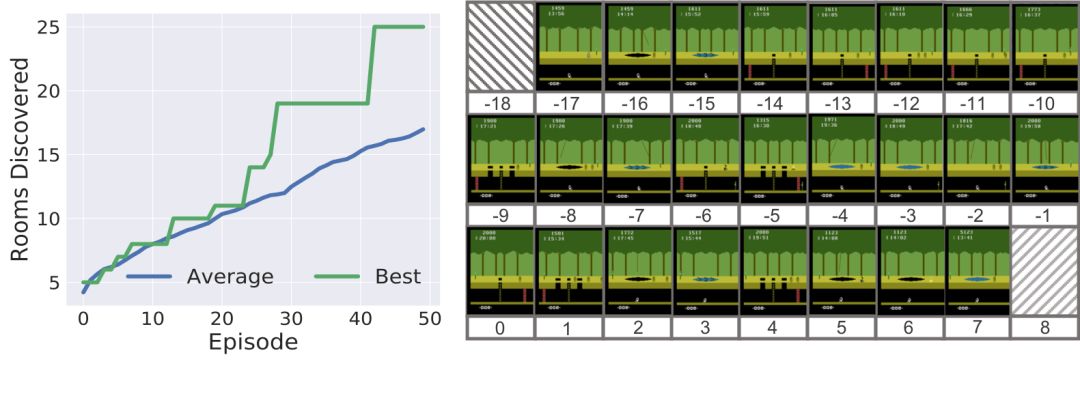
SOORL最多解锁了25个场景
下面的直方图显示出在不同的随机种子下,SOORL算法在训练时的100次游戏中最佳的表现分布。
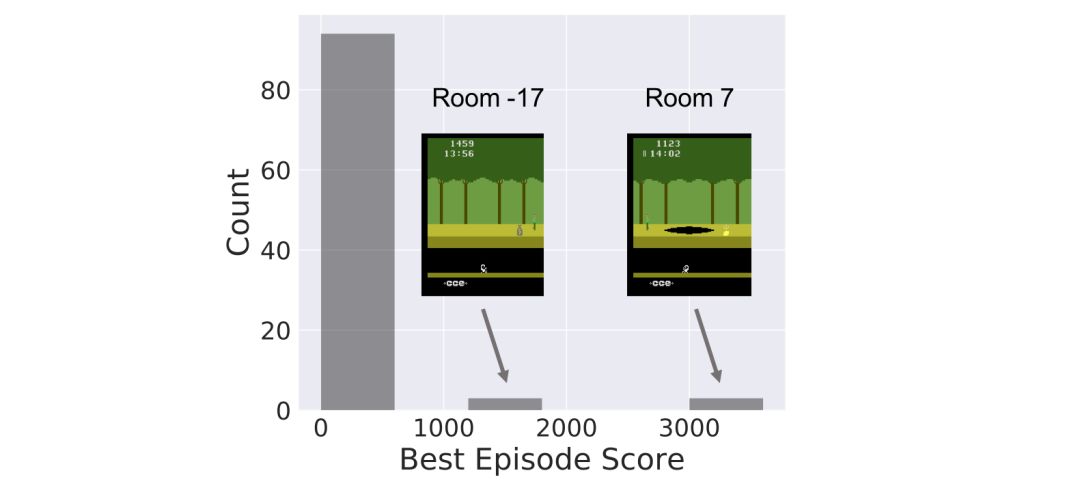
可以看到,SOORL在大多数情况下并不比之前所有深度强化学习的方法好,之前的方法得到最佳的奖励为0(虽然这种方法都是在500甚至5000次游戏之后才得到的,而我们的方法只要50次就可以得到最佳奖励)。在这种情况下,SOORL经常可以比其他方法解锁更多房间,但是并没有达到更高的最佳成绩。但是,在几次游戏中,SOORL得到了2000分甚至4000分的奖励,这是没有人类示范的情况下获得的最好分数。在有人示范的情况下目前最好的分数是60000分,尽管分数很高,但是这种方法仍需要大量的先验知识,并且还需要一个可靠的模型减少探索过程中遇到的挑战。
下面是SOORL智能体掌握的几种有趣的小技巧:
飞渡深坑
鳄鱼口脱险
躲避沙坑
SOORL仍然还有很多限制。也许其中最重要的缺点就是它需要一种合理的潜在动态模型进行具体化,使得SOORL可以在这个子集上进行模型选择。另外在蒙特卡洛树搜索期间,它没有学习并利用价值函数,这在早期的AlphaGo版本上是很重要的一部分。我们希望加入一个价值函数能大大改善其性能。
但是除了这些弱点,这些结果还是非常令人激动的。因为这个基于模型的强化学习智能体能在类似Pitfall!这样奖励非常稀疏的电子游戏中快速地学习,通过各种策略学习如何在简单模式下做出正确决策。
-
斯坦福
+关注
关注
0文章
28浏览量
9229 -
强化学习
+关注
关注
4文章
266浏览量
11245
原文标题:斯坦福提出无需人类示范的强化学习算法SOORL
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
斯坦福开发过热自动断电电池
关于斯坦福的CNTFET的问题
深度强化学习实战
回收新旧 斯坦福SRS DG645 延迟发生器
DG645 斯坦福 SRS DG645 延迟发生器 现金回收
深度学习技术的开发与应用
基于LCS和LS-SVM的多机器人强化学习
解析图像分类器结构搜索的正则化异步进化方法 并和强化学习方法进行对比






 工商网监
工商网监
评论