 12行简单的Python代码,初窥爬虫的秘境
12行简单的Python代码,初窥爬虫的秘境
往往不少童鞋写论文苦于数据获取艰难,辗转走上爬虫之路;
许多分析师做舆情监控或者竞品分析的时候,也常常使用到爬虫。
今天,本文将带领小伙伴们通过12行简单的Python代码,初窥爬虫的秘境。
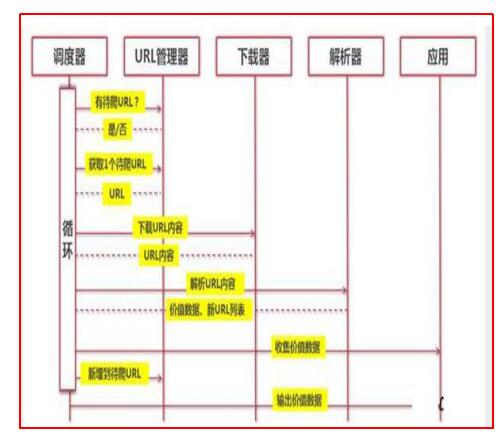
爬虫目标
本文采用requests + Xpath,爬取豆瓣电影《黑豹》部分短评内容。
运行以上的爬虫脚本,我们得以见证奇迹
爬虫结果与原网页内容的对比,完全一致
通过tqdm模块实现了良好的交互
工具准备
chrome浏览器(分析HTTP请求、抓包)
安装Python 3及相关模块(requests、lxml、pandas、time、random、tqdm)requests:用来简单请求数据lxml:比Beautiful Soup更快更强的解析库pandas:数据处理神器time:设置爬虫访问间隔防止被抓random:随机数生成工具,配合time使用tqdm:交互好工具,显示程序运行进度
基本步骤
网络请求分析
网页内容解析
数据读取存储
涉及知识点
爬虫协议
http请求分析
requests请求
Xpath语法
Python基础语法
Pandas数据处理
爬虫协议
爬虫协议即网站根目录之下的robots.txt文件,用来告知爬虫者哪些可以拿哪些不能偷,其中Crawl-delay告知了网站期望的被访问的间隔。(为了对方服务器端同学的饭碗,文明拿数据,本文将爬虫访问间隔设置为6-9秒的随机数)
豆瓣网站的爬虫协议
HTTP请求分析
使用chrome浏览器访问《黑豹》短评页面https://movie.douban.com/subject/6390825/comments?sort=new_score&status=P,按下F12,进入network面板进行网络请求的分析,通过刷新网页重新获得请求,借助chrome浏览器对请求进行筛选、分析,找到那个Ta
豆瓣短评页面请求分析
通过请求分析,我们找到了目标url为'https://movie.douban.com/subject/6390825/comments?start=0&limit=20&sort=new_score&status=P&percent_type=',并且每次翻页,参数start将往上增加20(通过多次翻页尝试,我们发现第11页以后需要登录才能查看,且登录状态也仅展示前500条短评。作为简单demo,本文仅对前11页内容进行爬取)
requests请求
通过requests模块发送一个get请求,用content方法获取byte型数据,并以utf-8重新编码;然后添加一个交互,判断是否成功获取到资源(状态码为200),输出获取状态
请求详情分析
(除了content,还有text方法,其返回unicode字符集,直接使用text方法遇到中文的话容易出现乱码)
Xpath语法解析
获取到数据之后,需要对网页内容进行解析,常用的工具有正则表达式、Beautiful Soup、Xpath等等;其中Xpath又快又方便。此处我们通过Xpath解析资源获取到了前220条短评的用户名、短评分数、短评内容等数据。(可借助chrome的强大功能直接复制Xpath,Xpath语法学习http://www.runoob.com/xpath/xpath-tutorial.html)
数据处理
获取到数据之后,我们通过list构造dictionary,然后通过dictionary构造dataframe,并通过pandas模块将数据输出为csv文件
结语与彩蛋
本例通过requests+Xpath的方案,成功爬取了电影《黑豹》的部分豆瓣短评数据,为文本分析或其他数据挖掘工作打好了数据地基。本文作为demo,仅展示了简单的爬虫流程,更多彩蛋如请求头、请求体信息获取、cookie、vwin 登录、分布式爬虫等请关注后期文章更新哟。
-
代码
+关注
关注
30文章
4779浏览量
68518 -
python
+关注
关注
56文章
4792浏览量
84624 -
爬虫
+关注
关注
0文章
82浏览量
6867
原文标题:12行Python暴力爬《黑豹》豆瓣短评
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Python数据爬虫学习内容
Python爬虫与Web开发库盘点
Python 爬虫:8 个常用的爬虫技巧总结!
0基础入门Python爬虫实战课
Python爬虫简介与软件配置

python爬虫入门教程之python爬虫视频教程分布式爬虫打造搜索引擎
python为什么叫爬虫






 工商网监
工商网监
评论