 一个使用传统DAS和深度强化学习融合的自动驾驶框架
一个使用传统DAS和深度强化学习融合的自动驾驶框架
增强学习是最近几年中机器学习领域的最新进展。增强学习依靠与环境交互学习,在相应的观测中采取最优行为。行为的好坏可以通过环境给予的奖励来确定。不同的环境有不同的观测和奖励。例如,驾驶中环境观测是摄像头和激光雷达采集到的周围环境的图像和点云,以及其他的传感器的输出,例如行驶速度、GPS定位、行驶方向。驾驶中的环境的奖励根据任务的不同,可以通过到达终点的速度、舒适度和安全性等指标确定。增强学习和传统机器学习的最大区别是增强学习是一个闭环学习的系统,增强学习算法选取的行为会直接影响到环境,进而影响到该算法之后从环境中得到的观测。
增强学习在无人驾驶中的应用
关于安全自主驾驶的研究可以分为两种方法:一是传统的感知,规划和控制框架,另一种是基于学习的方法。基于学习的方法可以成功处理在计算机视觉领域的高维特征(如卷积神经网络(CNN))而广受欢迎[5]-[7],强化学习算法可以最大化预期奖励的总和。有越来越多的研究开始将这两种技术结合,用于自动驾驶。对于车道保持,Rausch等人[8]提出了一种训练网络的方法,该方法直接根据从前置摄像头获得的图像预测转向角。结果表明,该神经网络可以通过从前置摄像头得到的原始图像,自动学习车道等特征,来训练车辆的车道保持的转向角度。 John等人[9]提出了混合框架,通过使用长短期记忆网络(LSTM)为每个场景计算适当的转向角。每个网络都会在特定道路场景的特定分区(如直线驾驶,右转弯和左转弯)中,对驾驶行为进行建模。在考虑多种驾驶场景时,它在多个驾驶序列中运行良好。 Al-Qizwini等人[10]提出了一种回归网络,预测驾驶的可利用状态,如前置摄像机图像中的交叉错误,航向误差和障碍物距离,而不是通过使用GoogLeNet直接从前摄像机图像预测转向角[11 ] 。转向角度,油门和制动都是使用基于if-else规则的算法计算出来的。
Sallab等[12]提出了一种在没有障碍物的情况下,使用DQN(Deep Q Network)和DDAC(Deep Deterministic Actor Critic)学习车道保持驾驶策略的方法。他们直接掌握转向,加速和减速,根据低维特征(如速度,轨道边界位置)最大限度地提高预期的未来回报。因此,使用可应用于连续作用的DDAC而非离散作用空间的DQN可以提高车道保持性能。 Zong等[13]提出了一种应用DDPG [14]来躲避障碍物,学习转向角和加速度值的方法。上述方法可以直接获得控制车辆所需的合适的转向角度、油门和制动量。然而,在这些情况下,每当车辆的参数改变时,最佳策略就会改变。因此存在很大限制,即为了最佳策略要不断进行学习。
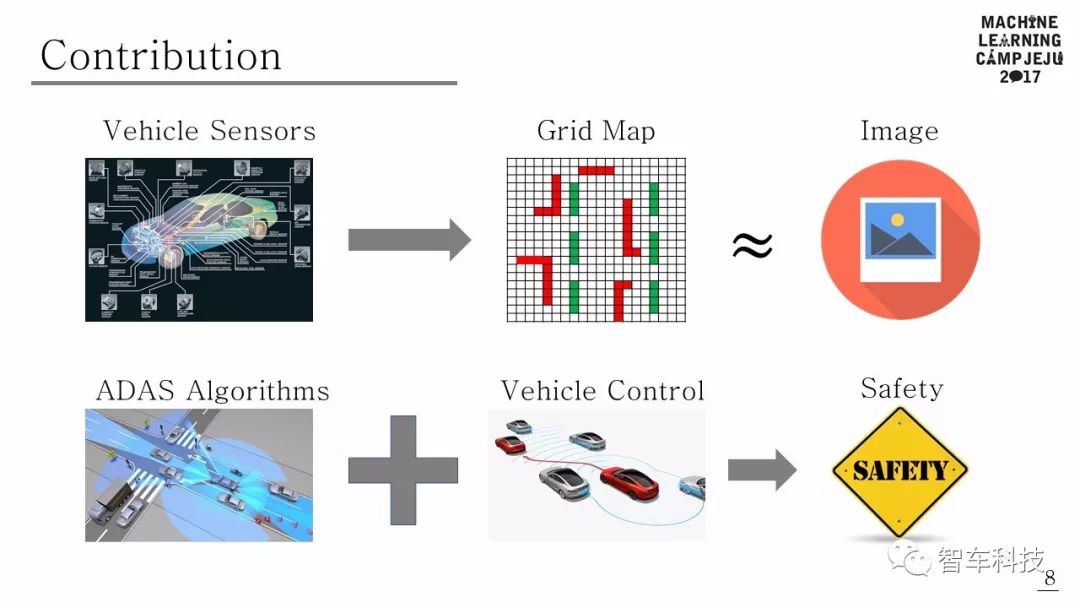
本文提出了一个使用传统DAS和深度强化学习融合的自动驾驶框架。该框架在DAS功能(例如车道变换,巡航控制和车道保持等)下,以最大限度地提高平均速度和最少车道变化为规则,来确定超车次数。可行驶空间是根据行为水平定义的,利用驾驶策略可以学习车道保持,车道变更和巡航控制等行为。为了验证所提出的算法,该算法在密集交通状况的vwin 中进行了测试,并证明了随着驾驶期间的学习进展,平均速度,超车次数和车道变换次数方面性能得到改善。
Deep Q Learning Based High Level Driving Policy Determination
Kyushik Min,
Hayoung Kim and Kunsoo Huh, Member, IEEE
作者Kyushik Min,韩国汉阳大学机器监测和控制实验室博士生,研究方向为高级驾驶辅助系统(ADAS)和自动驾驶。
项目概述
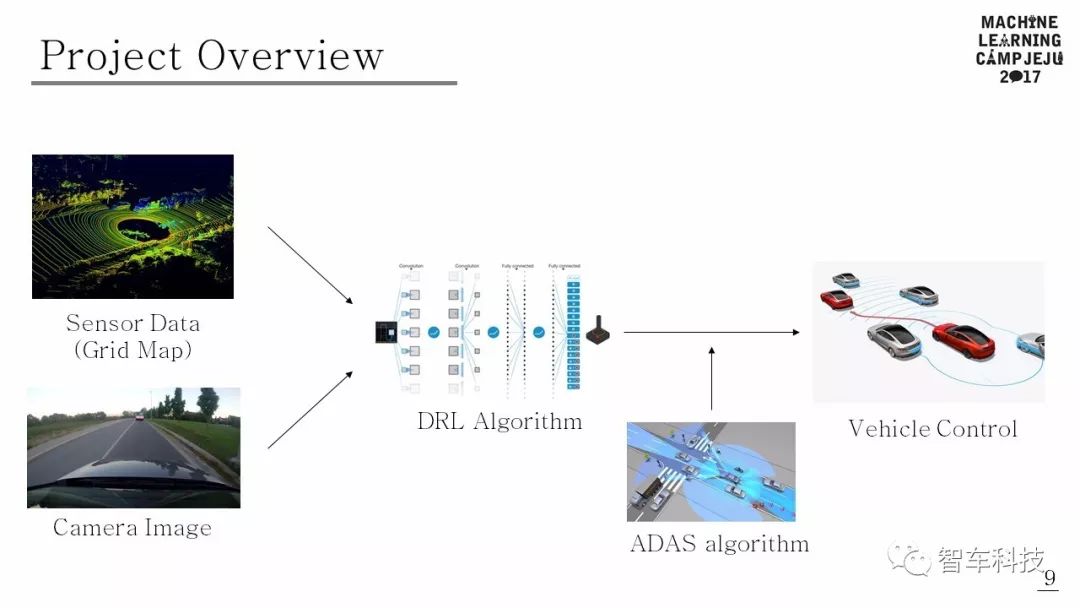
该项目为Tensorflow Korea 主办的2017济州学习营项目。使用传感器数据和相机图像作为DRL算法的输入。DRL算法根据输入决定行驶动作。如果行动可能导致危险情况,ADAS可以控制车辆以避免碰撞。
高层自动驾驶决策的实现
1.马尔科夫决策过程(MDP)
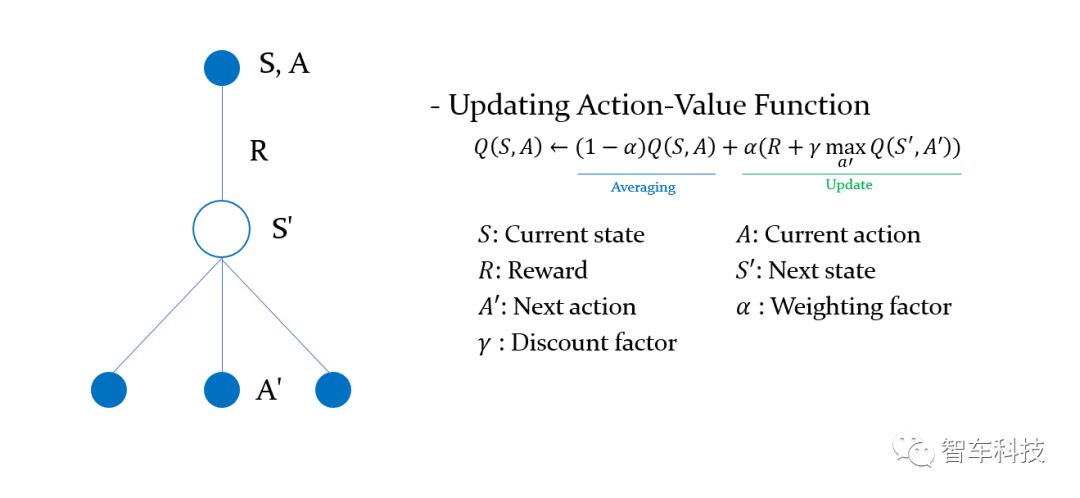
马尔可夫决策过程(MDP)是决策的数学框架,它由元组
2.感知
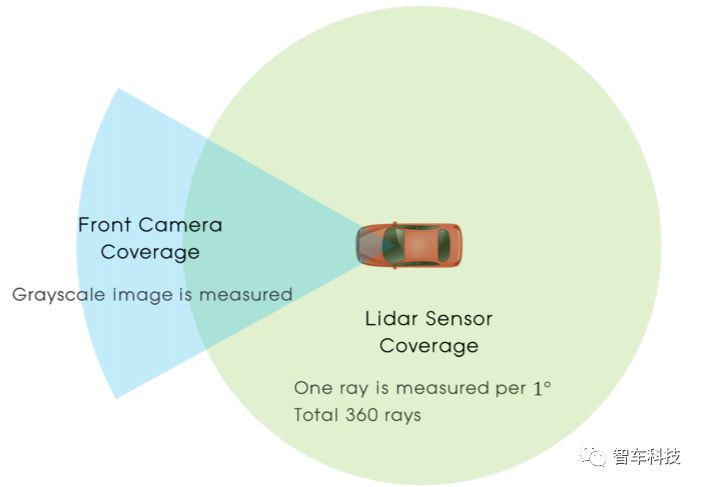
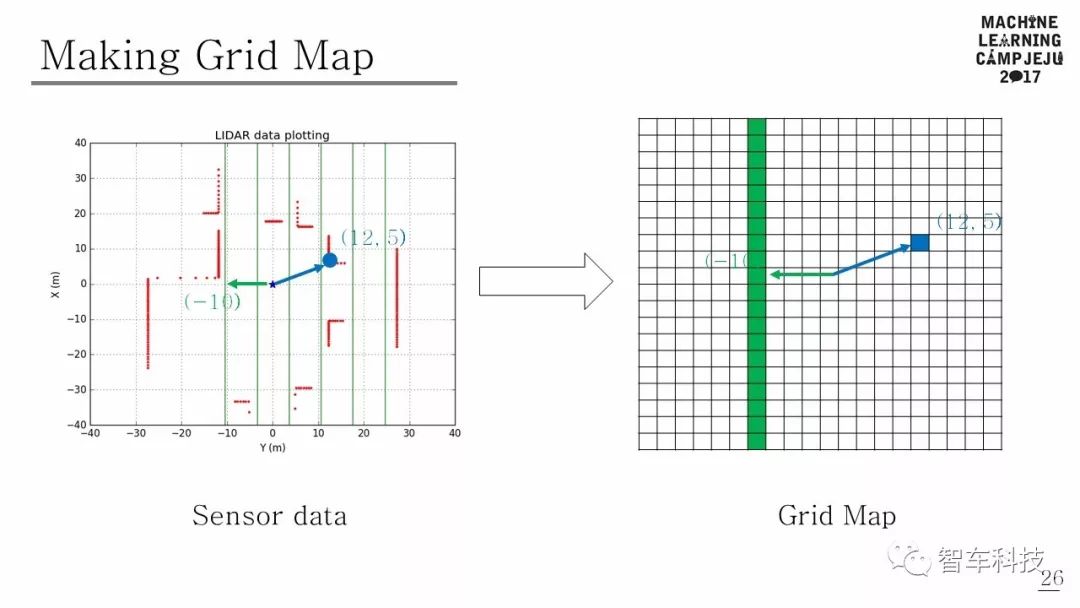
使用LIDAR传感器数据和相机图像数据构建感知状态。传感器配置的总覆盖范围可以在上图中看到。
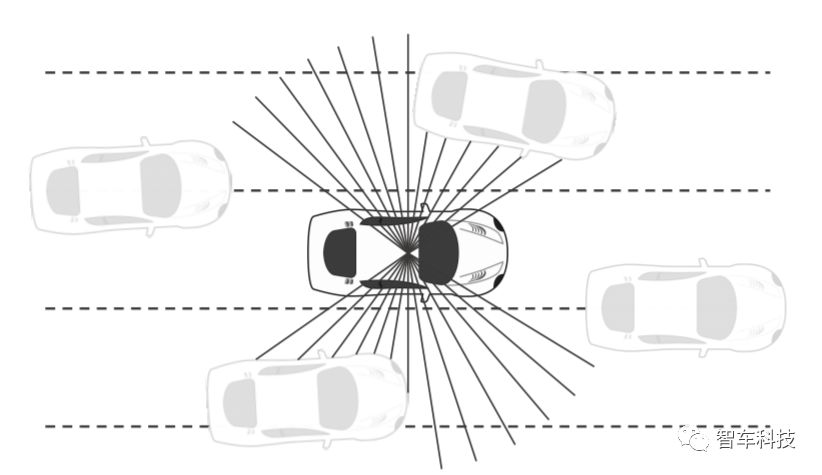
障碍物距离可以从LIDAR传感器获得,也可以从前端摄像头中获得原始图像来辅助感知。由于激光雷达的距离数据和来自相机的图像数据具有完全不同的特点,因此本研究采用多模态输入方案。
3.行动
驾驶决策的行动空间是在离散行动空间中定义的。当我们利用传统DAS的优势时,这个系统的每个动作都可能激活对应的DAS功能。在纵向方向上,有三种动作:1.速度为V + Vcc的巡航控制,其中Vcc为额外目标速度,设定为5km / h,2.当前速度为V的巡航控制,3.速度为巡航控制 V - Vcc。这些纵向行动将触发自主紧急制动(AEB)和自适应巡航控制(ACC)。在横向方向上,还有三种动作:1.保持车道,2.将车道变到左侧,3.将车道变到右侧。由于自动驾驶车辆同时在纵向和横向两个方向上驾驶,我们定义了5个离散行为。(静止,加速,减速,车道改变到左侧,车道改变到右侧)
4.奖励
根据强化学习选择不同的行动,将收到行动结果的奖励。在MDP上解决的问题是找到一个能够最大化未来预期价值奖励的驱动策略。这意味着最佳驾驶策略可以完全不同,具体取决于奖励的设计方式。因此,设计适当的奖励机制对学习正确的驾驶策略非常重要。当车辆在密集的交通情况下行驶时,应该满足以下三个条件:1.找到使车辆高速行驶的策略,2.以无碰撞的轨迹行驶,3.不频繁地改变车道。 基于这三个条件来设计奖励机制。
用于决策学习的DEEP RL算法
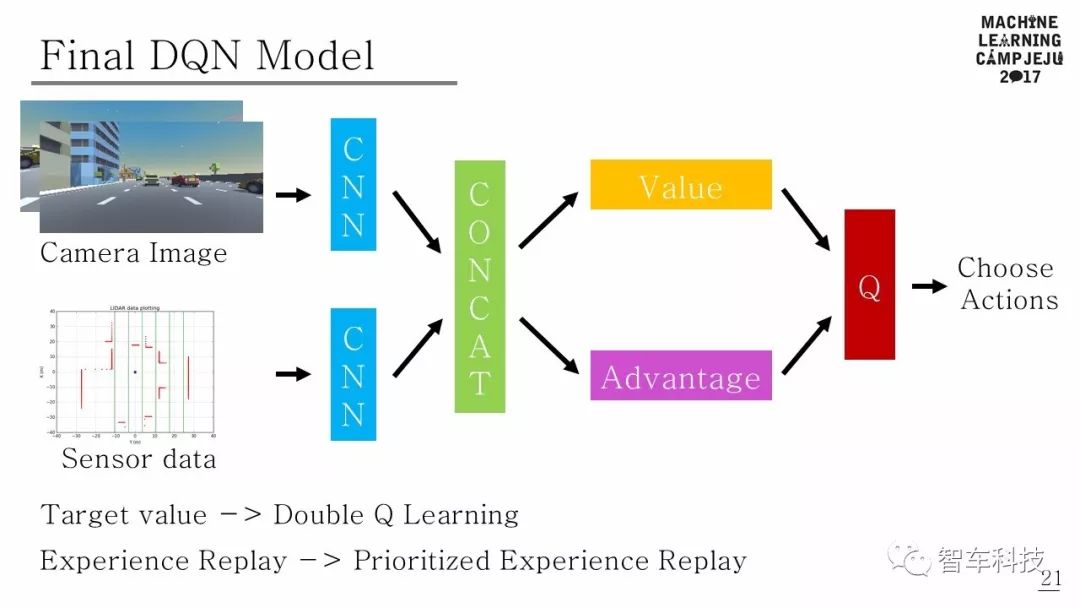
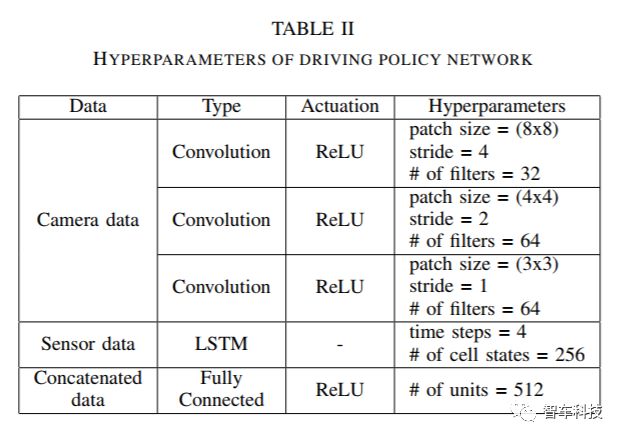
DQN在强化学习和神经网络相结合的游戏领域取得巨大成功之后,对深度强化学习进行了各种研究[16]。尤其是,在基于DQN价值的深层强化学习[17] - [22]中进行了大量研究。在此项研究中,深层增强学习算法由DQN [1],Double DQN [17]和Dueling DQN [19]组合得到最近的算法模型,其中的算法参考了Human-level Control Through Deep Reinforcement Learning[1],Deep Reinforcement Learning with Double Q-Learning[17],Prioritized Experience Replay[18],Dueling Network Architecture for Deep Reinforcement Learning[19]四篇论文中的算法。
项目代码可以在Github上查找:
https://github.com/MLJejuCamp2017/DRL_based_SelfDrivingCarControl
下图为最终的DQN模型。
仿真模拟
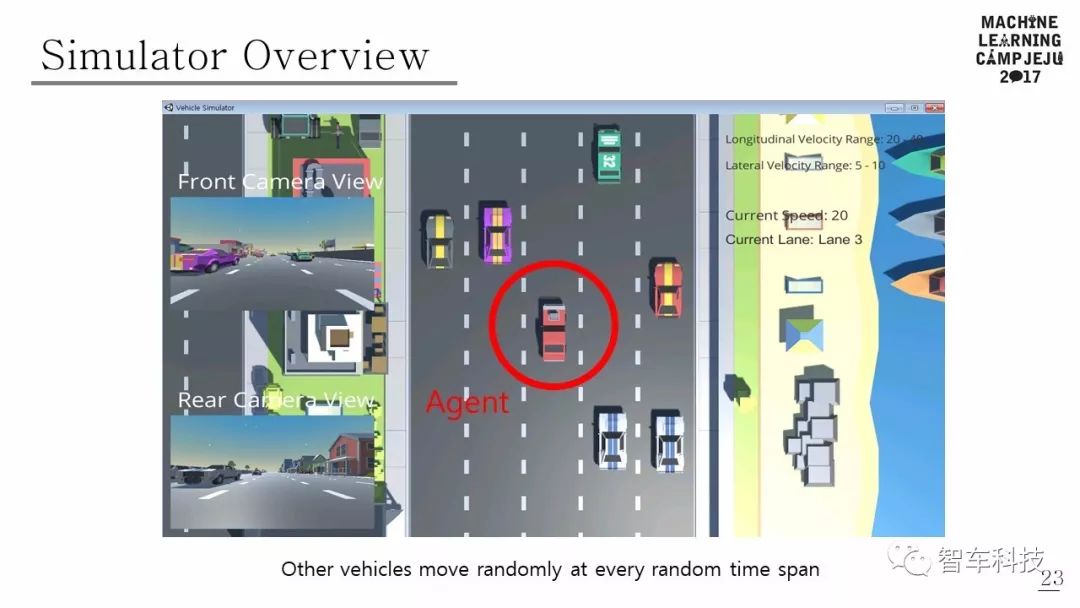
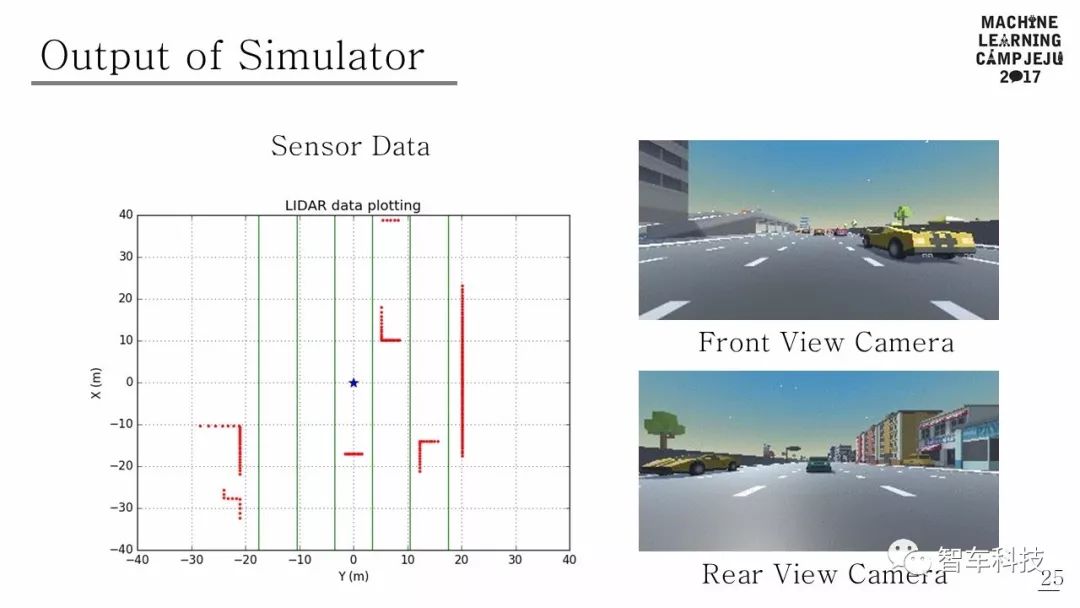
本文使用的模拟器是由 Unity 和 Unity ML-Agents 构建的。模拟道路环境是由五车道组成的高速公路行车道。其他车辆在距离主车辆一定距离内的随机车道中心产生。另外,假定其他车辆在大多数情况下不会彼此碰撞,并且可以执行五个动作(加速,减速,车道改变到右车道,车道改变到左车道,保持当前状态)。其他车辆的各种行动以多种随机方式出现,改变了模拟环境,因此Agent 可以体验许多不同的情况。模拟器的观测结果有两种类型:一种是图像,另一种是激光雷达范围阵列。由于前面有摄像头,因此每一步都会观察到原始像素图像。 LIDAR传感器检测有一个360度的射线范围,如果光线扫描到物体,它会返回主车辆和物体之间的距离。如果没有障碍物,则返回模拟器每一步的最大感应距离。
结果与结论
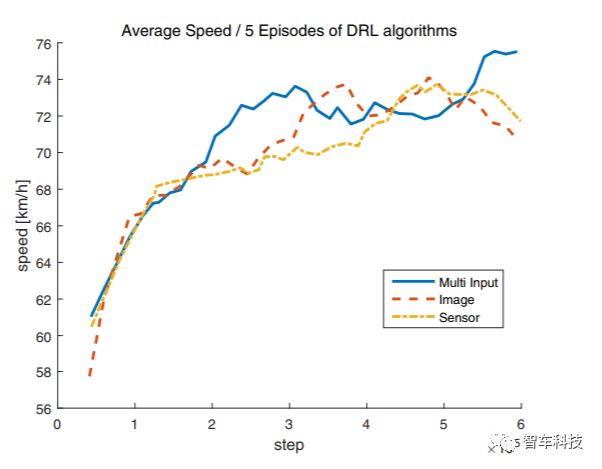
本文提出的驾驶策略算法使用Tensorflow 架构[25]实现的,平均速度,车道变化次数和超车次数等数据都可以从中读出。为验证多输入体系结构的优势,该体系结构分别将来自摄像机和LIDAR的数据通过CNN和LSTM相结合,另外还使用了两个仅用摄像机输入和LIDAR输入的策略网络作为对比。
比较三种不同的不同输入的网络架构:摄像头,LIDAR,摄像头和激光雷达。随着训练的进行,自动驾驶车辆会超越更多的车辆并以更快的速度行驶,而不会在每个输入车辆的环境中,出现不必要的车道变化。结果显示,多输入架构在平均速度和平均超车次数方面表现出最佳性能,分别为73.54km / h和42.2。但是,当使用多输入架构时,车道变化的数量最多,其平均值为30.2。尽管所提出的算法的目标是减少不必要的车道变化的数量,但多输入架构的结果在车道变化的数量方面是最高的。对于LIDAR和摄像头架构中,即使前车速度较慢,它们有时也会显示跟随前方车辆而不更改车道。因此,研究车道变化的数量是寻找最优策略的关键。
在本文中,驾驶策略网络充分利用传统的DAS功能,在大多数情况下保证了车辆行驶的安全性。使用深度强化学习算法训练的自主车辆,在模拟高速公路场景中成功驾驶,所提出的策略网络使用多模式输入,不会造成不必要的车道变化,在平均速度,车道变化次数和超车次数方面,车辆比具有单输入的车辆更好地驾驶。这项研究的结果表明,自主车辆可以由受过深度强化学习训练的主管来控制。
-
DAS
+关注
关注
0文章
106浏览量
31074 -
自动驾驶
+关注
关注
784文章
13784浏览量
166371 -
强化学习
+关注
关注
4文章
266浏览量
11245
原文标题:IEEE IV 2018:基于深度增强学习的高层驾驶决策研究
文章出处:【微信号:IV_Technology,微信公众号:智车科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
一文聊聊自动驾驶测试技术的挑战与创新

如何使用 PyTorch 进行强化学习
人工智能的应用领域有自动驾驶吗
NVIDIA推出全新深度学习框架fVDB
FPGA在自动驾驶领域有哪些优势?
FPGA在自动驾驶领域有哪些应用?
TensorFlow与PyTorch深度学习框架的比较与选择
深度学习在自动驾驶中的关键技术
中级自动驾驶架构师应该学习哪些知识
初级自动驾驶架构师应该学习哪些知识
智能驾驶大模型:有望显著提升自动驾驶系统的性能和鲁棒性
端到端自动驾驶的基石在哪里?
端到端自动驾驶的基石到底是什么?





 工商网监
工商网监
评论