 如何利用非监督学习实现了不同音乐间的乐器、体裁和风格间的转换
如何利用非监督学习实现了不同音乐间的乐器、体裁和风格间的转换
Facebook上月末发表了一篇名为“A Universal Music Translation Network”的文章(原文链接在文末),详细阐述了如何利用非监督学习实现了不同音乐间的乐器、体裁和风格间的转换。相信小伙伴们或多或少地了解过这篇论文。

但是如果从音乐家的角度来看这个过程是如何进行的呢?本文将从四个不同的层次带领我们更深入地理解这篇论文中所描述的方法,看看到底是什么神奇的魔力将长笛的悠扬转换为了钢琴的动听的。
level-0:新手
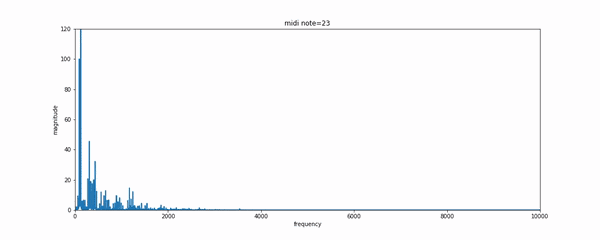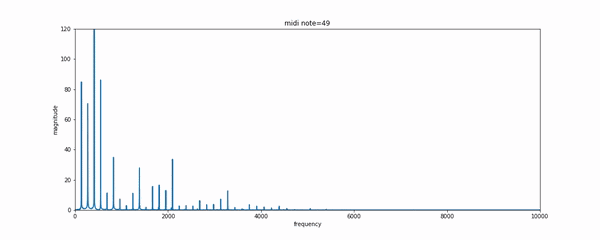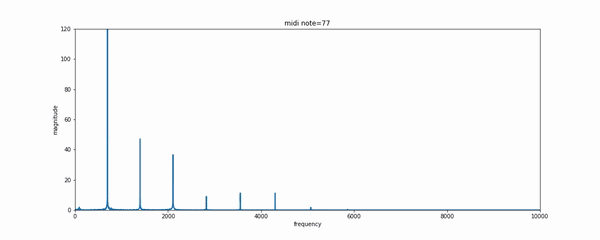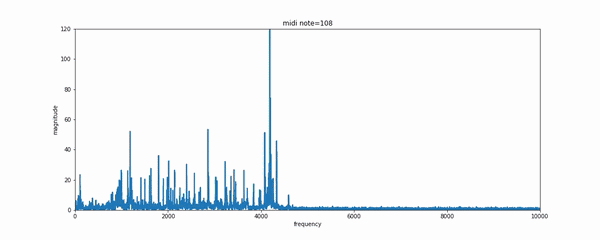
对于新手来说想要快速实现风格转换,傅里叶变换将是一个不错的手段。利用频谱分析将会迅速的找出对应的和弦和音符并在新的乐器上演奏出来。事实上传统的处理方法提供了一系列这样的手段:通过解码器与基于本征乐器的乐器归一化方法或者复调方法来实现。每一种乐器都有独特的音符集和时域瞬态特征,但困难的是即使对于单一乐器来说,其频谱包络在不同的音高下并不服从同峰值模式。同时还有不同的泛音和谐频需要处理。所有的这些使得音乐在不同乐器间的风格转换十分困难。
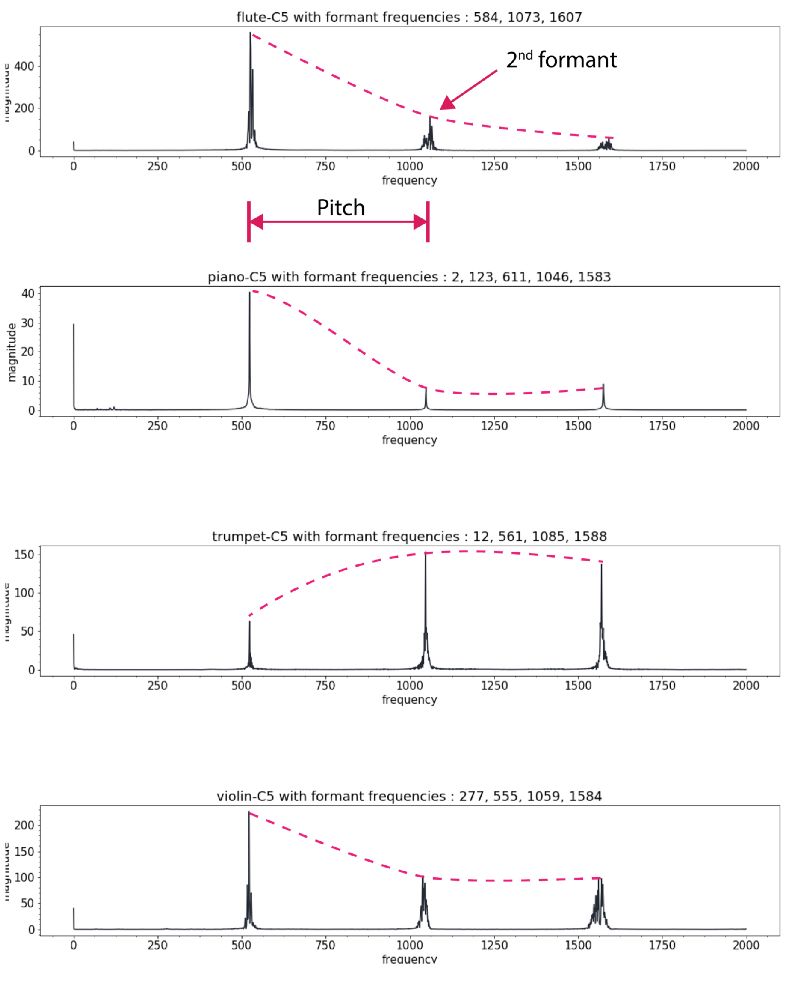
level-1:深度学习专业的同学
如果拥有一点乐理基础的话,可以使用CNN模型通过MIDI格式的音乐生成的label来学习音乐的表达和转录。MIDI是一种在合成器中常用的数字音乐,每一个键被按下或者抬起都意味着一次事件的触发。可以通过如MAPS一样的数据集来实现复调钢琴音乐的转录问题。
level-2:NLP学者将如何处理呢?
NLP学者最有可能使用的方法应该是sequence to sequence模型了,但这种方法需要同时追踪原始乐器和目标乐器的发音序列。
level-3:直接学习转换和邻域归一化
对于十分优秀的音乐家来说,他们会明白每一种乐器之间的细微差别是MIDI所不能捕捉到的,而这个问题就是facebook文章中的创新所在。研究人员借鉴了wavenet的自回归架构并充分利用它将这一问题转换为了“下一个音符是什么”的类似问题,从而将其变成了一个非监督问题来解决。

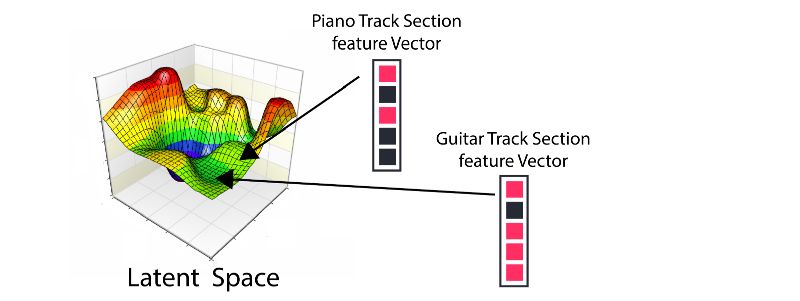
wavenet本质上使用随学习过程不断扩大的卷积得到了增加的感受野,从而可以得到更好的预测结果和包含更为丰富特征的隐含空间。这些特征抓住了人类声音和乐器声音的本质,就像cnn中抽取的图像特征一样。此时如果你想要通过学习一个自回归模型来预测钢琴的下一个音调,你只需要简单的学习一对儿wavenet编码器和解码器。编码器将把原始的音乐序列投射到隐含空间中,而解码器将尽力理解隐含空间的中的数值并解码成下序列的下一个值。
是不是很奇妙?如果一个模型可以编码钢琴但解码成其他乐器是不是就可以实现音乐在不同乐器间的转换啦?这就是FacebookAI研究人员的努力。他们利用一个相同的编码器对多种乐器进行编码,而后利用不同的解码器实现不同乐器的解码,实现了多种乐器之间的风格互转。那么它是如何工作的呢?下面让我我们来具体看一看。
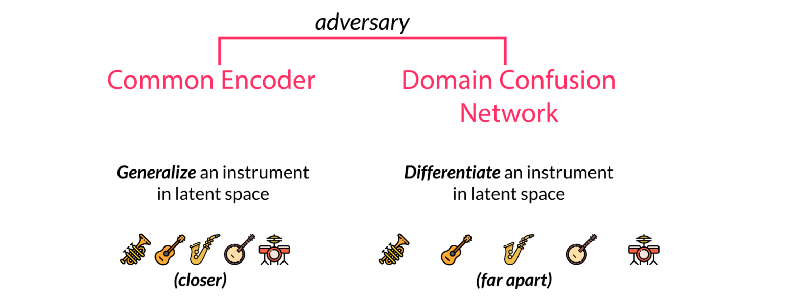
多个乐器间共享同一个解码器会迫使这个解码器去学习音乐间的相同特征。但对于解码器来说,我们需要告诉它这到底是什么乐器,需要解码的目标域是什么。这就需要对于不同乐器的域训练特殊的解码器来实现。论文中使用了对抗的方法来实现这一目标。由于通用的潜在空间希望去寻找通用的特征而忽略了每种乐器的特殊性,而混淆矩阵则希望分割共同特征中不同的表达并尽可能的实现不同的类别特征。通过特殊与一般之间的对抗得到了两个性能强大的编码和解码模型。值得注意的是要想同时获得两个性能优异的编解码模型,需要仔细地选择正则化系数来实现。
让我们来看看这个模型的损失函数。具体的训练过程是这样的,首先在不同乐器的域中选取一个样本sj,随后利用随机变调来避免模型无脑地对数据进行记忆。论文中对0.25-0.5s长的样本使用了-0.5-0.5的半步变调,可以用O(sj,r)来表示,其中r是随机种子。你也许会对这一步感到疑惑,但使用过谷歌magenta模型或者瞬时生成模型的人都会有这样的经历,有的时候模型会像鹦鹉学舌一样简单的重复记忆下的序列,简直是公然的过拟合了。而这就是数据增强和偏移过程的关键所在,也是训练多种乐器的编码器关键所在。
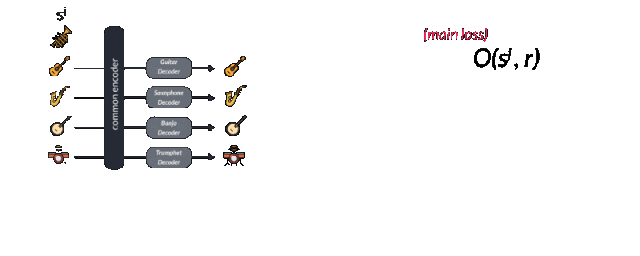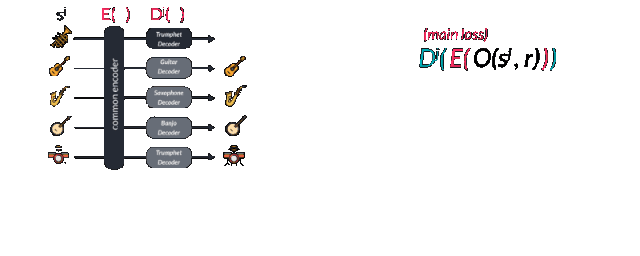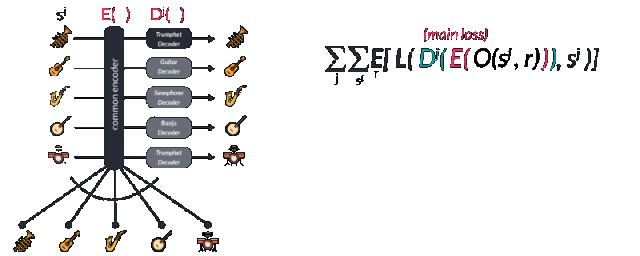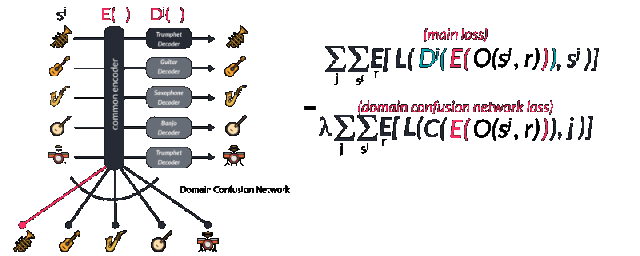
随后增强数据通过wavenet编码器中扩大的卷积层转换到了隐含空间中,并通过对应的解码器Dj还原到了其对应的乐器空间中并预测出了下一个音符输出。研究人员通过交叉熵比较实际的下一个输出和预测的下一个输出来计算损失函数。其中第一项代表重建误差要尽可能的小,而第二项领域分类的误差则用于尽可能的分开不同域的特征,这也是网络进行对抗训练的表现。作为一个对抗模型,一个监督的正则项通过后编码的特征矢量用于预测不同的域。它被称为域混淆网络(Domain Confusion Network)。
网络在实际工作过程中,输入的一个交响乐片段会被转换和翻译为一种特殊的乐器,但这个模型最令人惊叹的能力还不止于此。当输入一种模型从未见过的乐器时,通过自动编码和解码过程它依然可以完美的工作!这证明了模型中的编码器确实可以提取出音乐中的一般化特征并在隐含空间中表示出来,及时没有见过这个乐器。这是很多生成算法的核心概念,像GANs和变分自编码都利用这一思想创造了很多迷人的工作。
-
Facebook
+关注
关注
3文章
1429浏览量
54718 -
傅里叶变换
+关注
关注
6文章
441浏览量
42590 -
深度学习
+关注
关注
73文章
5500浏览量
121107
原文标题:深度解析Facebook的音乐转换AI模型
文章出处:【微信号:thejiangmen,微信公众号:将门创投】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
深非监督学习-Hierarchical clustering 层次聚类python的实现
基于半监督学习框架的识别算法
英伟达通过利用GAN及无监督学习,实现了场景间的四季转换
你想要的机器学习课程笔记在这:主要讨论监督学习和无监督学习
如何用Python进行无监督学习
机器学习算法中有监督和无监督学习的区别
最基础的半监督学习
半监督学习最基础的3个概念






 工商网监
工商网监
评论