 Python3网络爬虫入门实战解析
Python3网络爬虫入门实战解析
网络爬虫简介
网络爬虫,也叫网络蜘蛛(WebSpider)。它根据网页地址(URL)爬取网页内容,而网页地址(URL)就是我们在浏览器中输入的网站链接。
在浏览器的地址栏输入URL地址,在网页处右键单击,找到检查。(不同浏览器的叫法不同,Chrome浏览器叫做检查,Firefox浏览器叫做查看元素,但是功能都是相同的)
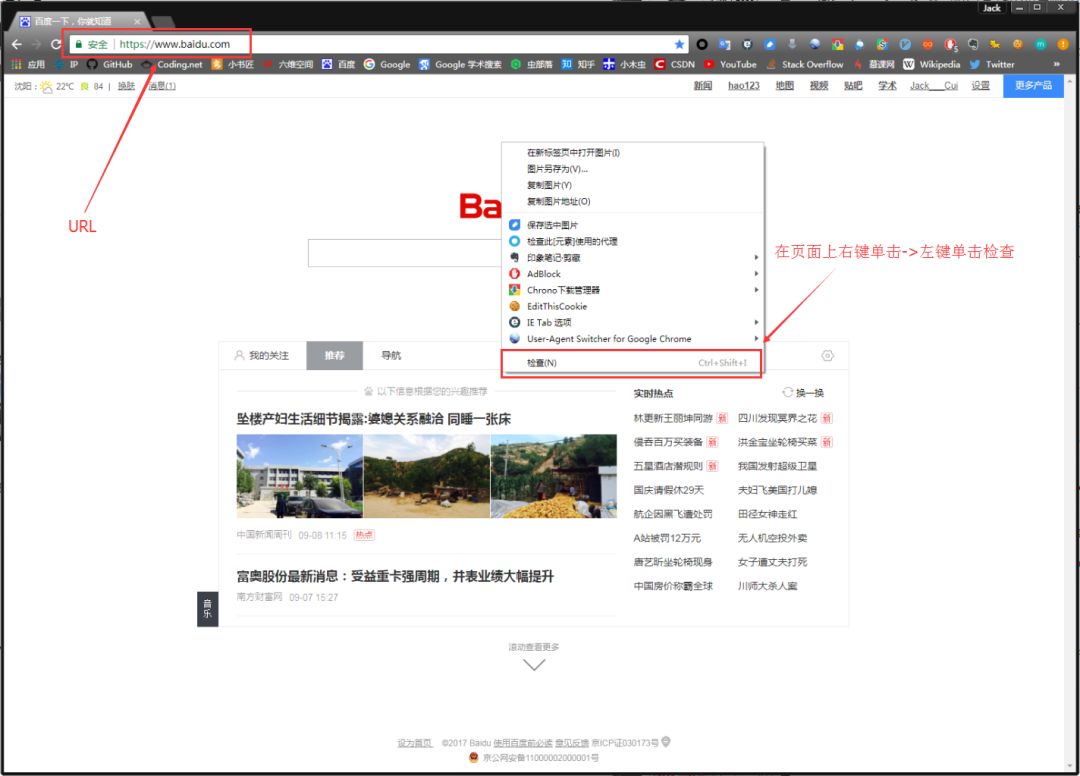
我们可以看到,右侧出现了一大推代码,这些代码就叫做HTML。什么是HTML?举个容易理解的例子:我们的基因决定了我们的原始容貌,服务器返回的HTML决定了网站的原始容貌。
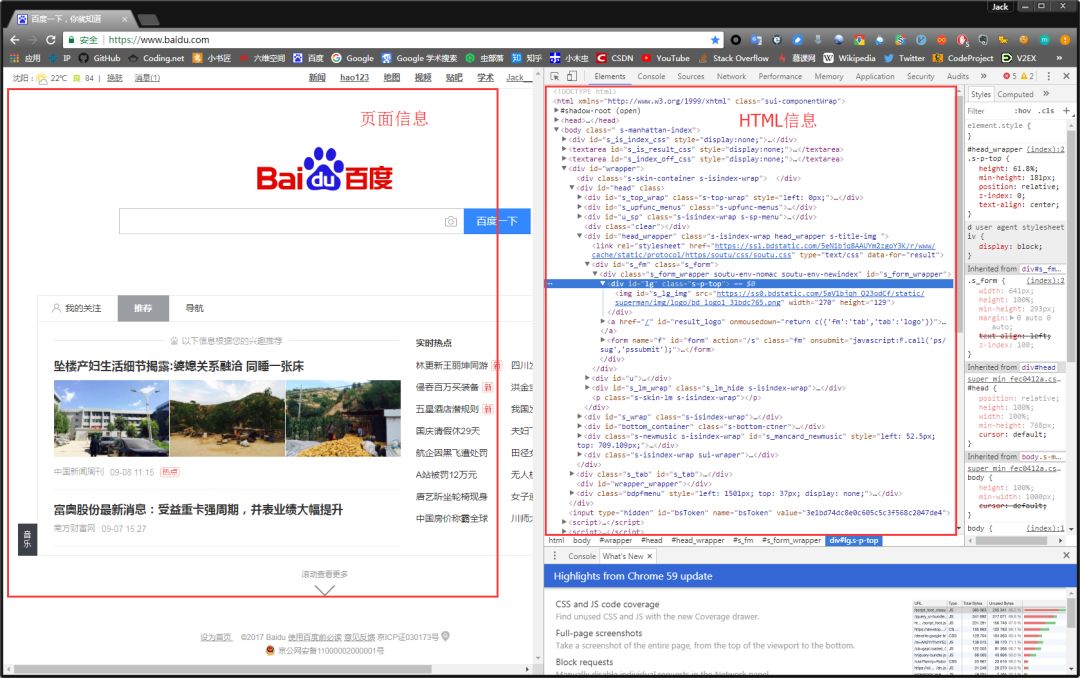
为啥说是原始容貌呢?因为人可以整容啊!扎心了,有木有?那网站也可以"整容"吗?可以!请看下图:
我能有这么多钱吗?显然不可能。我是怎么给网站"整容"的呢?就是通过修改服务器返回的HTML信息。我们每个人都是"整容大师",可以修改页面信息。我们在页面的哪个位置点击审查元素,浏览器就会为我们定位到相应的HTML位置,进而就可以在本地更改HTML信息。
再举个小例子:我们都知道,使用浏览器"记住密码"的功能,密码会变成一堆小黑点,是不可见的。可以让密码显示出来吗?可以,只需给页面"动个小手术"!以淘宝为例,在输入密码框处右键,点击检查。
可以看到,浏览器为我们自动定位到了相应的HTML位置。将下图中的password属性值改为text属性值(直接在右侧代码处修改):
我们让浏览器记住的密码就这样显现出来了:
说这么多,什么意思呢?浏览器就是作为客户端从服务器端获取信息,然后将信息解析,并展示给我们的。我们可以在本地修改HTML信息,为网页"整容",但是我们修改的信息不会回传到服务器,服务器存储的HTML信息不会改变。刷新一下界面,页面还会回到原本的样子。这就跟人整容一样,我们能改变一些表面的东西,但是不能改变我们的基因。
2、简单实例
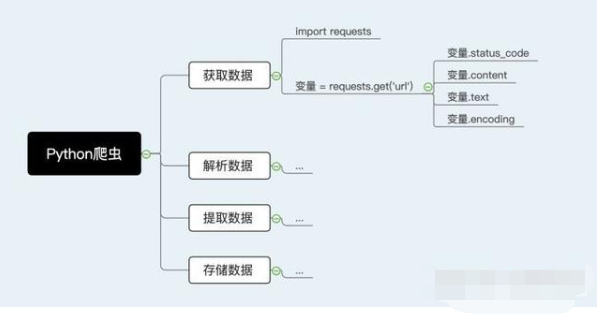
网络爬虫的第一步就是根据URL,获取网页的HTML信息。在Python3中,可以使用urllib.request和requests进行网页爬取。
urllib库是python内置的,无需我们额外安装,只要安装了Python就可以使用这个库。
requests库是第三方库,需要我们自己安装。
requests库强大好用,所以本文使用requests库获取网页的HTML信息。requests库的github地址:https://github.com/requests/requests
(1)requests安装
在cmd中,使用如下指令安装requests:
pip install requests
或者:
easy_install requests
(2)简单实例
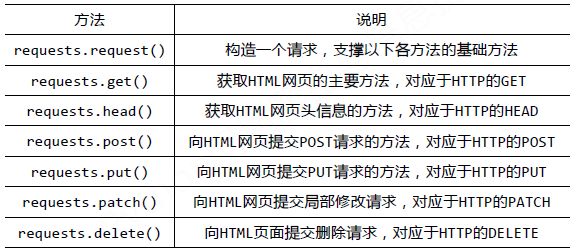
requests库的基础方法如下:
官方中文教程地址:http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
requests库的开发者为我们提供了详细的中文教程,查询起来很方便。本文不会对其所有内容进行讲解,摘取其部分使用到的内容,进行实战说明。
首先,让我们看下requests.get()方法,它用于向服务器发起GET请求,不了解GET请求没有关系。我们可以这样理解:get的中文意思是得到、抓住,那这个requests.get()方法就是从服务器得到、抓住数据,也就是获取数据。让我们看一个例子(以 www.gitbook.cn为例)来加深理解:
# -*- coding:UTF-8 -*-import requestsif __name__ == '__main__': target = 'http://gitbook.cn/' req = requests.get(url=target) print(req.text)
requests.get()方法必须设置的一个参数就是url,因为我们得告诉GET请求,我们的目标是谁,我们要获取谁的信息。运行程序看下结果:
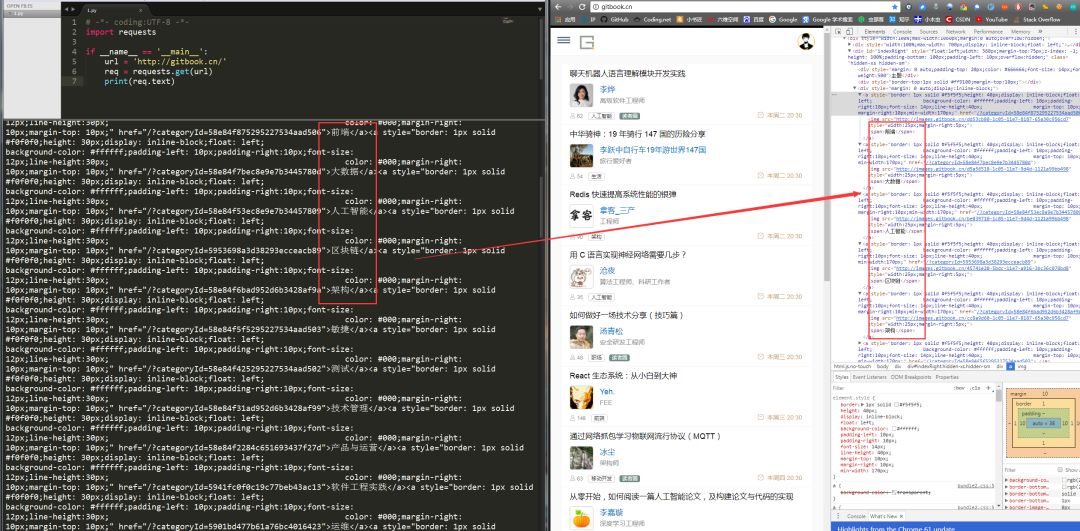
左侧是我们程序获得的结果,右侧是我们在www.gitbook.cn网站审查元素获得的信息。我们可以看到,我们已经顺利获得了该网页的HTML信息。这就是一个最简单的爬虫实例,可能你会问,我只是爬取了这个网页的HTML信息,有什么用呢?客官稍安勿躁,接下来会有网络小说下载(静态网站)和优美壁纸下载(动态网站)实战,敬请期待。
-
网络爬虫
+关注
关注
1文章
52浏览量
8647 -
python3
+关注
关注
0文章
18浏览量
3897
原文标题:最通俗的 Python3 网络爬虫入门
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Python数据爬虫学习内容
安装python3的步骤
Python爬虫简介与软件配置
python网络爬虫概述


python爬虫入门教程之python爬虫视频教程分布式爬虫打造搜索引擎
Python爬虫入门知识:解析数据篇
如何使用Python3检查文件是否存在







 工商网监
工商网监
评论