 如何让多个智能体学会一起完成同一个任务,学会彼此合作和相互竞争
如何让多个智能体学会一起完成同一个任务,学会彼此合作和相互竞争
当前人工智能最大的挑战之一,是如何让多个智能体学会一起完成同一个任务,学会彼此合作和相互竞争。在发表于ICML 2018的一项研究中,伦敦大学学院汪军教授团队利用平均场论来理解大规模多智能体交互,极大地简化了交互模式。他们提出的新方法,能够解决数量在成百上千甚至更多的智能体的交互,远远超过了所有当前多智能体强化学习算法的能力范围。
柯洁挥泪乌镇一周年,AI已经重新书写了围棋的历史。而创造出地球上最强棋手AlphaGo系列的DeepMind,早已经将目光转向下一个目标——星际争霸。
玩星际争霸,需要AI在不确定的情况下进行推理与规划,涉及多个智能体协作完成复杂的任务,权衡短中长期不同的收益。相比下围棋这样的确定性问题,星际争霸的搜索空间要高出10个数量级。
从现实意义上来说,研究多智能体协作也具有广泛的应用场景。例如,股票市场上的交易机器人博弈,广告投标智能体通过在线广告交易平台互相竞争,电子商务协同过滤推荐算法预测用户兴趣,等等。
伦敦大学学院(UCL)计算机科学系教授汪军博士及其团队一直从事多智能体协作的研究。汪军教授认为,目前通用人工智能(AGI)研究有两个大方向,一是大家熟知的AlphaGo,这是单智体,其背后的经典算法是深度强化学习;另一个就是多智体(Multi-agent),也可以理解为集体智能,这是人工智能的下一个大方向。
目前,人工智能最大的挑战之一,就是如何让多个智能体学会一起完成同一个任务,学会彼此合作和相互竞争。如何利用一套统一的增强学习框架去描述这个学习过程。
研究负责人、伦敦大学学院(UCL)的汪军教授
在一项最新的研究中,汪军和他的团队利用平均场论来理解大规模多智能体交互,极大地简化了交互模式,让计算量大幅降低。他们提出的新方法,能够解决数量在成百上千甚至更多的智能体的交互,远远超过了所有当前多智能体强化学习算法的能力范围。相关论文已经被ICML 2018接收,作者将在7月13日下午5点在ICML会场做报告,欢迎大家去现场交流。
“我们发现在处理大规模智能体学习时,把多体问题抽象成二体问题是一种有效的方法,”论文作者Yaodong Yang告诉新智元:“这个想法的初衷异常简单,就是把环境中所有领域内其他智能体对中心个体的影响,仅仅用一个它们的均值来抽象,而不用一一分别考虑建模。”
他们设计的平均场Q-learning算法成功vwin 并求解了物理领域的伊辛模型(ising model)。Yaodong表示:“用强化学习的框架可以解决物理学中的伊辛模型,这一发现非常令人振奋。”
上海交通大学张伟楠助理教授团队也积极参与了此次工作,张伟楠认为:“使用平均场计算领域智能体的行动分布,并整合于强化学习中在计算上十分高效,在不同算法互相对战的实验中,平均场Q-learning算法能稳定提高群体智能的效果,在battle中碾压传统多智能体强化学习的算法。”

在一个混合式的合作竞争性战斗游戏中,研究人员证明了平均场MARL相对其他多智能体系统的基线获得了更高的胜率。其中,蓝方是平均场Q-learning算法,红方是传统的强化学习算法DQN。
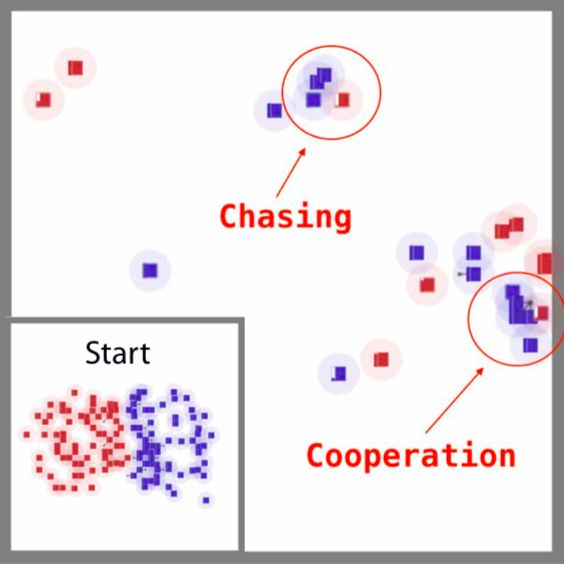
对战局部,agent彼此间的合作与竞争。
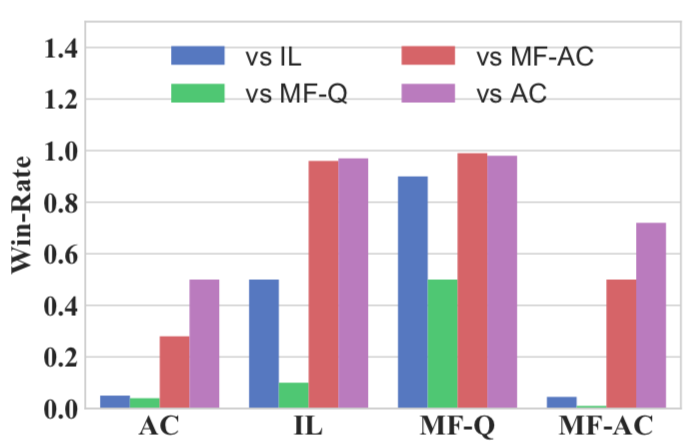
对战结果:经过2000多轮比较实验,新提出的平均场Q-learning算法(MF-Q)相对于其他传统强化学习算法的胜率(绿色)。很明显,在所有的指标中,MF-Q的胜率都高出一大截。
由于大幅降低了计算量,他们的方法可以推广用于很多实际场景,比如终端通讯设备流量分配,互联网广告竞价排名,智能派单等大规模分布式优化场景中。
用平均场论解决大规模多智能体交互,大幅简化计算
多智体强化学习(Multi-agent reinforcement learning, MARL)假设有一组处在相同环境下的自主智能体。在MARL中学习非常困难,因为agent不仅与环境交互,而且还会相互作用:一个agent的策略变化会影响其他agent的策略,反之亦然。
例如,在星际争霸中,让一组20个agent去攻击另外一组的20个agent,每个agent就要考虑周围39个agents的行为从而做出最优决策。对于每个个体来说,要学会理解的状态空间是很庞大的,这还不包括其他智能体在探索环境时产生的噪声。当agent增多到1000乃至上万个时,情况就变得超级复杂,现有的多智能体强化学习算法有很大局限性,也没有那么大的计算力。
但是,推测其他agent的策略来计算额外的信息,对每个agent自身是有好处的。研究表明,一个学习了联合行动效应的agent,比那些没有学习的agent表现更好,无论是在合作博弈、零和随机博弈和一般和随机博弈中,情况都是如此。这也很好理解,知彼知己,才能百战不殆。
因此,结果就是,现有的均衡求解方法虽然可行,但只能解决少数agent的问题,大部分的实验还局限于两个agent之间的博弈。而在实践当中,却常常会需要有大量agent之间的策略互动。
如何解决这个问题?UCL的研究者想到了平均场论。
平均场论(Mean Field Theory,MFT)是一种研究复杂多体问题的方法。在物理学场论和机器学习的变分推断中,平均场论是对大且复杂的随机模型的一种简化。未简化前的模型通常包含巨大数目的含相互作用的小个体。平均场理论则做了这样的近似:对某个独立的小个体,所有其他个体对它产生的作用可以用一个平均的量给出,这样,简化后的模型对于每个个体就成了一个单体问题。
在他们的研究中,UCL团队没有去分别考虑单个智能体对其他个体产生的不同影响,而是将领域内所有其他个体的影响用一个均值来代替。这样,对于每个个体,只需要考虑个体和这个均值的交互作用就行了。这种抽象的方法,当研究对象大到无法表达的时候尤其有用。
平均场论的方法能快速收敛,用强化学习解决伊辛模型
应用平均场论后,学习在两个智能体之间是相互促进的:单个智能体的最优策略的学习是基于智能体群体的动态;同时,集体的动态也根据个体的策略进行更新。
在此基础上,研究人员提出了平均场Q-learning算法(MF-Q)和平均场Actor-Critic算法(MF-AC),并通过伊辛模型验证了它们的解是否能够快速收敛。
易辛模型(Ising model),是一个以物理学家恩斯特·易辛为名的数学模型,用于描述物质的铁磁性。该模型中包含了可以用来描述单个原子磁矩的参数,其值只能为+1或-1,分别代表自旋向上或向下(在多智能体的情况下,就是向上或者向下移动)。这些磁矩通常会按照某种规则排列,形成晶格,并在模型中引入特定交互作用的参数,使得相邻的自旋互相影响。
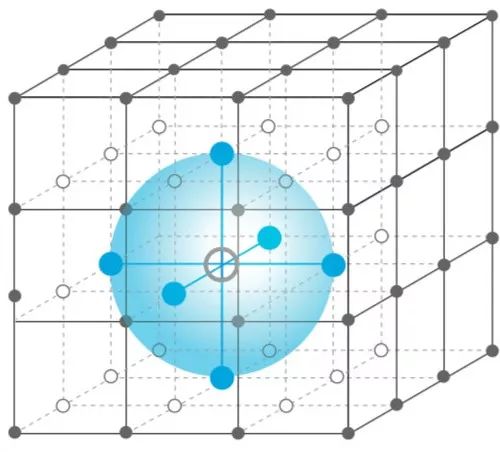
平均场近似。每个agent都表示为网格中的一个节点,它只受邻居(蓝色区域)的平均效果影响。多个agents相互作用被有效地转换为两个代理的相互作用。
虽然伊辛模型相对于物理现实是一个相当简化的模型,但它却和铁磁性物质一样,在不同温度下会产生相变。事实上,一个二维的方晶格易辛模型是已知最简单而且会产生相变的物理系统。在这个场景下, 虽然每一个磁矩对整个磁体的性质的影响非常有限, 但是通过微观的相互作用, 磁矩之间却会形成宏观的趋势, 而这种趋势能够决定我们所关心的整体磁场的性质。
在多智体强化学习这个领域,特定的任务可以被有效的抽象为同质智能体(homogeneous agent)之间的相互学习以及博弈的过程。
在平均场多智体伊辛模型中,网格中的每个agent向上和向下的奖励是不同的,如果最终能让所有agent都朝同一个方向移动(都变为黑色),也就表明了平均场方法能够比较快速的收敛。通过下面的动图,可以更直观地看到这种快速收敛的效果。
研究难点及未来方向
研究人员表示,这项工作有两方面的难点。首先是理论部分,只有一套严格自洽的理论才能作为后续实验以及分析的基础。在将平均场论融入多智体强化学习的过程中,他们利用了不同领域里的多项理论,包括平均场论的近似化方法,在stochastic games中的纳什均衡学习理论(nash q learning),不动点分析,以及最优化理论中的压缩映射(contraction mapping)。最后,理论证明了他们所提出的平均场强化学习在一些温和条件的收敛性,并且提供了近似化中误差的上下界 。
另一方面的难点在于实验,由于目前没有良好的针对多智体强化学习的测试平台,团队设计构建了一个实验环境,用于提供必要的测试条件。
研究人员表示,据他们所知,某些大厂已经在实验室阶段实现了他们的算法,用于大规模派单和通讯设备流量分配。因为这个算法适合处理的特定问题是大规模智能体,并且每个智能体都有相同程度的相似性,实际应用的场景会非常广阔,例如广告竞价、智能城市等等。
目前,关于多智能体的深度强化学习上,理论层面还是没有看到太多的发展。这个领域缺乏一个大家都认可的理论框架。例如,多智能体在学习的时候目标函数到底应该是什么,是否应该是纳什均衡,还有很多争论。
更有学者认为,多智能体学习不应该专注个体的决策,反而应该从种群的角度去理解,也就是演化博弈论(evolutionary game theory)的理论框架。演化博弈论认为,关注的重心应该是一个种群里选择某些行动的agent的比例是不是在进化意义上是稳定的,也就是evolutionary stable strategies的想法。
对此,UCL团队的研究人员认为,他们接下来将进一步完善理论和实验方法,探索潜在的实际应用。
论文:平均场多智体强化学习
摘要
现有的多智体(multi-agent)强化学习方法通常限制于少数的智能体(agent)。当agent的数量增加很多时,由于维数以及agent之间交互的指数级的增长,学习变得很困难。
在这篇论文中,我们提出平均场强化学习(Mean FieldReinforcement Learning),其中,agent群体内的交互以单个agent和总体或相邻agent的平均效应之间的交互来近似;两个实体之间的相互作用是相互加强的:个体agent的最佳策略的学习取决于总体的动态,而总体的动态则根据个体策略的集体模式而变化。
我们提出了使用的平均场 Q-learning 算法和平均场 Actor-Critic算法,并分析了纳什均衡解的收敛性。Gaussian squeeze、伊辛模型(Ising model)和战斗游戏的实验,证明了我们的平均场方法的学习有效性。此外,我们还通过无模型强化学习方法报告了解决伊辛模型的第一个结果。
-
人工智能
+关注
关注
1791文章
47182浏览量
238197 -
智能体
+关注
关注
1文章
144浏览量
10575 -
强化学习
+关注
关注
4文章
266浏览量
11245
原文标题:UCL汪军团队新方法提高群体智能,解决大规模AI合作竞争
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
请问怎么在同一个PCB文件中设计多个PCB板?
一个APP如何控制多个智能硬件
四大科技巨头都如何利用AI来相互竞争
如何让RTOS多任务访问同一个UART?
SS-431 使多个 Modbus 设备如同一个设备被访问

FPGA中电源管脚在同一个BANK为何需要多个引脚?

两个网络IP地址是否在同一个段中的判断方法





 工商网监
工商网监
评论