 基于Xilinx 16nm Virtex UltraScale+器件VU9P的异构计算实例
基于Xilinx 16nm Virtex UltraScale+器件VU9P的异构计算实例
接下来,我们来看看阿里云对它进行了怎样的改造。
阿里云ECS的异构计算团队和高性能计算团队一直致力于将计算资源"平民化";高性能计算团队在做的E-HPC就是要让所有云上用户都能够瞬间拥有一个小型的超算集群,使得超算不再仅仅是一些超算中心和高校的特权;而我们异构计算团队则致力于将目前最快、最新的计算设备在云上提供给用户,使得曾经高冷的计算资源不再拒人千里之外:我们推出了FPGA云服务器FaaS 服务, 其中的F1和F2实例已经对外提供服务,可以通过一键部署的方式把Intel和Xilinx的小规格的器件计算能力赋予客户。
今天我们很高兴地宣布:新晋的大规格FPGA实例,基于Xilinx 16nm Virtex UltraScale+ 器件VU9P的异构计算实例F3在阿里云上线了!
我们借此机会,对阿里云FPGA计算服务(下面简称FaaS)本身,以及这次发布的F3实例的底层硬件架构和平台架构做一个技术解读。
FaaS阿里FPGA云服务器平台FaaS(FPGA as a Service)在云端提供统一硬件平台与中间件,可大大降低加速器的开发与部署成本。加速器开发商的加速器可以形成服务提供给加速器用户,消除加速技术与最终用户的硬件壁垒。用户则能够在无需了解底层硬件的情况下,直接按需使用加速服务。
为了给加速器提供方和使用方提供更加高效、统一的开发及部署平台,FaaS提供两大套件:HDK和SDK。

HDK给所有的加速器开发者提供统一的FPGA硬件接口,提前帮用户解决了FPGA开发中难度最大的高速接口开发及调试,例如PCIe、SERDES接口、DDR控制器等等;使得用户能够直接得到硬件平台和FPGA接口的最大性能,不会因为团队开发能力和经验的欠缺,造成硬件平台性能浪费;高效、可靠、统一的接口套件也为云上平台的安全隔离、设备稳定提供了保障,不会因为用户的接口设计问题,造成服务器宕机;同时可以杜绝用户在FPGA端对主机的非法操作,为整个云上安全提供保障。
HDK包括两个部分,Shell和 Role;Shell部署在静态区域,提供上述统一接口部分。
在提供统一接口、安全性和便捷性的前提下,阿里云FaaS HDK 也尽最大的努力保证用户设计的灵活性,Role的概念应运而生。Role部署在动态区域,是在Shell之外,预先开发并提供的,用户可以配合用户逻辑(Customer Logic)使用。不同于Shell,用户可以根据需要,随时更换Role部分;这种Shell + Role的组合方式,保证了Shell的最轻量化和稳定性,又兼顾了统一性、便捷性和灵活性。
SDKSDK包括两个部分:
-
和HDK(Shell+Role)对应的主机端驱动(Drivers)和软件库(Libraries)
-
FPGA管理工具 faascmd套件
驱动和软件库和HDK的Shell以及Role相对应,和HDK一起,为用户提供统一及灵活的软件支持,比如DMA驱动、寄存器访问驱动等等。
faascmd工具套件为用户提供云上FPGA管理服务,包括安全校验、FPGA镜像生成、下载及管理、FPGA加速卡状态查询反馈等功能。公有环境使用FPGA,需要考虑用户FPGA文件的安全,faascmd提供的秘钥及OSS bucket指定机制,有效保证了用户的FPGA下载文件的私密性。在线下的开发及应用中,开发者直接对FPGA进行下载操作,但在云上环境,用户对公有的FPGA资源直接操作对安全造成较大影响。Faascmd工具会对用户操作申请和物理FPGA资源进行隔离,保证了用户下载安全的同时,提供给用户类似线下操作的体验;同时会对用户提交的网表进行校验,提高安全、降低风险。faascmd同时也提供调用接口,用户能很容易地在自己的App中调用管理工具,结合自身加速器特性实现各种管理功能。
FaaS 的IP市场FaaS降低了FPGA开发者的开发准入门槛:云上即开即用的FPGA资源、灵活的付费模式使得硬件资源触手可及;同时简化了开发流程,统一了开发接口,把核心加速逻辑从周边硬件设备的接口调试中隔离出来,使得FPGA的新兴应用可以只关注业务加速的核心逻辑,快速迭代;在这两点上,阿里云的FaaS 迈出了FPGA计算资源平民化的第一步。
但即便是大大简化了开发流程、提供了触手可及的硬件资源,FPGA依然有一定的开发门槛。如何把已有的FPGA 逻辑IP价值最大化,联通FPGA加速的需求方和提供方来扩大生态呢?重要的一点就是如何解决在公共云数据中心层面保证FPGA加速IP的安全性,特别是对不可信的第三方进行输出和部署这个难题, FaaS是如何解决这个问题的呢?
答案是通过阿里云FaaS的IP市场。技术上,通过与Xilinx联合开发的定制虚拟化技术达到IP加速与部署环境的强隔离,IP的用户与IP的网表文件完全隔离,网表文件的传输、部署、加速流程全程对用户都不可见;同时加速计算能力又可以透明地向使用该IP的第三方用户开放,这是阿里云在FPGA云上加速服务的另外一个技术创新。这个创新,完全杜绝了FPGA IP在云上输出的时候被盗版的可能,提供了非常高的安全保护机制。
更加严格的保密机制也在规划中:很快可以通过阿里云的KMS加密服务对IP进行加密保护,每次对IP加载前都需要向KMS服务获取秘钥解密,这样一来针对IP的使用下载有据可查;并且使得IP发布方的IP在数据中心内部都是安全的,因为没有了IP提供方的KMS秘钥,即便是阿里云也无法对加密的网表进行解密操作。
在阿里云FaaS IP 市场的帮助下,即便是从来没有任何FPGA开发经验的用户,也可以一键从IP市场中获取相应的加速逻辑,并快速部署到对应的FPGA器件上面去。我们相信,通过即开即用的硬件资源、统一的软硬件逻辑开发接口和IP市场,阿里云能够真正兑现FPGA计算资源平民化的承诺。
F3硬件架构阿里云FaaS的F3实例在底层硬件上,是使用阿里云自主研发的高性能单卡双芯片的VU9P的板卡。这里要划重点啦:单卡双芯片。一定有用户要问为什么要这么设计呢?单卡双芯片的硬件设计有什么好处呢?
首先,对于用户来说,通过单卡双芯片这样的规格设计,与阿里云配套自研的服务器一起,最高可以提供单实例16 块 VU9P的计算实例。16块 VU9P是非常高的计算密度了,这是设计单卡双芯片的第一个目的:通过提高计算密度,在同等计算单元下集成了更多的加速芯片,能够有效降低单位计算力的成本,从成本大幅降低和单位实例的垂直计算力提升上,客户可以双重受益。
单卡双芯片的两个VU9P芯片通过PCIe 桥接入系统,那么双芯片之间的互相通信呢?是不是只能通过PCIe的总线来进行呢,答案是否定的,除了FPGA Direct这种通过PCIe互相通信的能力之外,在阿里云的自研的板卡上也是有特殊考虑的。在两个芯片之间,我们设计了一个高速互联通道,使得两个FPGA之间可以通过这个特殊的通道以高达600Gb/s的速率进行通信,这个通信技术我们称之为FPGA Link。要知道,现在的数据中心主流部署的接入交换机光口通信也只能达到100Gb/s的通信速率,更高的200Gb/s的交换机还在试部署中。
试想一下,无需额外的交换机和光口硬件,两个FPGA芯片可以通过FPGA Link技术以超短时延通过6倍于主流光口通信的速率进行通信,这个将会以极低的成本帮助用户开启大量新的FPGA加速应用模式。比如,小规模的芯片仿真,需要两个器件才能部署得下的情况,可以将整体仿真模块拆解之后部署到两个芯片上,两个芯片之间的数据通路和同步信号通过高速通道互联;还有其他的应用场景,需要把功能模块部署到两个FPGA芯片之上,而两者之间需要大量的数据交换,比如视频转码场景:把小规模但是模块数目比较多的解码单元、视频处理单元部署到一个FPGA之上,把面积占用比较多的编码单元放到另外一个FPGA上,编解码模组之间通过高速互联交换裸视频流。这将大大改善部署的难度,以及极大的解耦两个模块之间的相互依赖和设计难度。以上举了两个例子,读者一定能够举一反三地想到,其他需要流水线处理并需要大量数据交换的场景,阿里云的F3实例的双芯片实例能够为客户提供最大的价值。
不少应用场景对板载的DDR存储还是有要求的。阿里云的F3实例,为每个FPGA搭配了客户可见的64GB的DDR内存,这64GB的DDR分成4个通道,分别连接到VU9P的3个硅单元上面,其中一个通道对应的16GB DDR保留常驻,其余3个通道对应的48GB存储以可选的方式可被客户逻辑加载使用。
目前,我们看到了双芯片实例除了FPGA Direct技术和高达600Gb/s的FPGA Link高速互联能力之外,另外值得一提的是:双芯片的实例与其他的双芯片实例板卡之间也可以通过400Gb/s的光口进行互联,而且400Gb/s的以太协议驱动是通过Xilinx预置的MAC硬核来加速,不占用逻辑面积;通过以太或者自定义的轻量级通信协议,能够在16芯片之间,以及更多的芯片之间搭建2维Mesh或者环形互联,进一步扩展多片互联的使用模式和应用场景。
最后,上一张图,让大家对上面做的硬件的技术解析有一个更具体的认识:
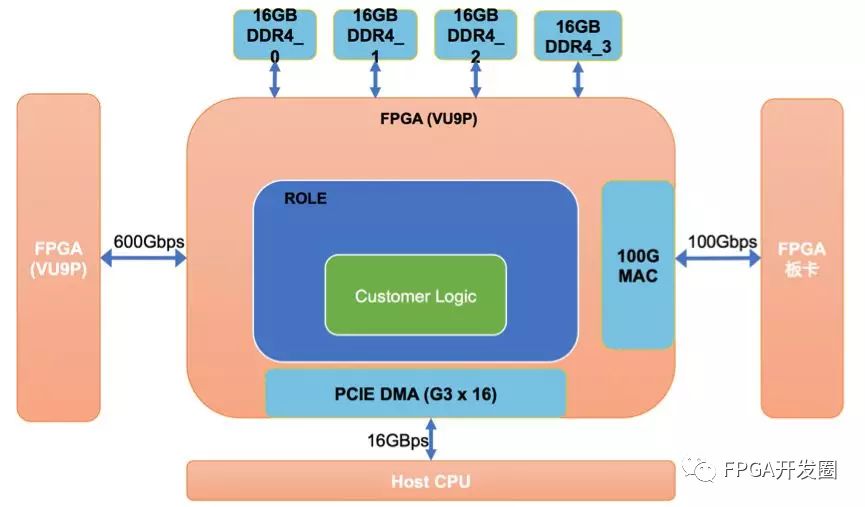
F3逻辑结构,技术分析之前,先给大家上一幅逻辑架构图:

★SHELL:
Shell是FPGA的静态区域,内部包含用户PCIe、管理PCIEe、板卡管理系统和一个DDR访问通道。为了提高板卡的安全和稳定性,用户无权修改SHELL区域。
★ROLE:
我们在设计中提出了Role的概念,Role和Shell是类似的封装。而Role跟Custom Logic一起在动态区域。Role的提出使我们可以更加轻量化Shell。我们通过Role实现了同一个Shell既可以支持OpenCL开发,也可以支持RTL开发;最后就是Role的再次抽象降低了用户对于FPGA的开发门槛。我们提供基础的Role,也允许用户自行设计Role。我们希望更多第三方的设计者通过分享自己Role,使得FaaS平台更加精彩。
ROLE内部结构简介Interconnect:该部分主要是提供给用户四路DDR通道的访问和USER_PCIe对四路DDR通路的访问。 该模块帮助用户隔离了时钟域,使用户逻辑在同一个时钟域上对4路DDR通道进行访问。
Inter chip interconnect: FPGA 单卡双芯片间互联通路;
Card interconnect: FPGA 卡间互联通路;
Custom Logic:用户自定义逻辑部分;
Custom Logic介绍用户逻辑是属于Role的一部分,属于动态加载区域。 为了方便用户标准化使用,我们在RTL设计中使用了标准的AXI-4和AXI-LITE接口。
1.我们将详细介绍用户接口,其列表如下:
|
接口 |
Name |
Direction |
Clock Domain |
Description |
|
时钟和复位 |
I |
/ |
寄存器通路时钟50Mhz |
|
|
sys_alite_aresetn |
I |
|||
|
usr_clk |
I |
用户时钟,300Mhz,该时钟固定不可配置 |
||
|
usr_rstn |
I |
|||
|
kernel_clk_300m |
I |
用户时钟,300Mhz,该时钟固定可配置 |
||
|
kernel_clk_rstn |
I |
|||
|
kernel2_clk_500m |
I |
用户时钟,500Mhz,该时钟固定可配置 |
||
|
寄存器通路 |
AXI_LITE |
sys_alite_aclk |
axi4_alite接口,用户寄存器传输,地址空间0x0~0x7fffff |
|
|
DDR AXI4 |
C0_sys_axi* |
/ |
kernel_clk_300m |
dimm0 数据交互访问接口(base addr:0x0000_0000_0000_0000) |
|
C1_sys_axi* |
/ |
dimm0 数据交互访问接口(base addr:0x0000_0004_0000_0000) |
||
|
C2_sys_axi* |
/ |
dimm0 数据交互访问接口(base addr:0x0000_0008_0000_0000) |
||
|
C3_sys_axi* |
/ |
dimm0 数据交互访问接口(base addr:0x0000_000c_0000_0000) |
||
|
Dma AXI4 |
Dma_axi_* |
/ |
kernel_clk_300m |
用户逻辑直接dma访问通路 |
|
Interrupt |
usr_int_en |
I |
kernel_clk_300m |
中断使能 |
|
usr_int_req |
I |
中断请求,最大支持16个中断 |
||
|
usr_int_ack |
O |
中断应答 |
||
|
错误检测 |
ddr_cal_done |
I |
kernel_clk_300m |
|
|
dma_4k_r_err_flag |
I |
|||
|
dma_4k_w_err_flag |
I |
注:板间互联,卡卡互联接口邀测阶段缺省不提供,需要特殊申请对外开放。
2.AXI-4 and AXI-Lite 限制
|
AxBURST |
Only INCR burst is supported. |
|
AxLOCK |
Lock is not supported. |
|
AxCACHE |
Memory type is not supported |
|
AxPROT |
Protection type is not supported |
|
AxQOS |
Quality of Service is not supported |
|
AxREGION |
Region identifier is not supported |
3. 正如我们在介绍Role中所述,用户可以定制化Role操作。我们阿里云FaaS团队为了方便用户更有效的使用平台,多个Role版本正在发布中,敬请关注。降低用户使用门槛,缩短开发时间,健全FPGA使用生态始终是我们的使命。
-
FPGA
+关注
关注
1629文章
21728浏览量
602953 -
加速器
+关注
关注
2文章
796浏览量
37837 -
Xilinx
+关注
关注
71文章
2166浏览量
121289
原文标题:如何将FPGA资源平民化?阿里工程师有了新突破
文章出处:【微信号:FPGA-EETrend,微信公众号:FPGA开发圈】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
ALINX 发布 AXVU13P:AMD Virtex UltraScale+ 高端 FPGA PCle 3.0 综合开发平台

【一文看懂】什么是异构计算?

AMD/Xilinx Zynq® UltraScale+ ™ MPSoC ZCU102 评估套件

PCIe收发卡设计资料:611-基于VU9P的2路4Gsps AD 2路5G DA PCIe收发卡

为两个Xilinx(TM)LX240 Virtex-6(TM)器件供电


打造异构计算新标杆!国数集联发布首款CXL混合资源池参考设计

AvaotaA1全志T527开发板AMP异构计算简介
异构计算:解锁算力潜能的新途径
中高端FPGA如何选择
中国台湾将资助当地16nm以下芯片研发 最高补贴50%
AMD推出全新Spartan UltraScale+ FPGA系列

高通NPU和异构计算提升生成式AI性能
AMD推出全新Spartan UltraScale+ FPGA系列
采用UltraScale/UltraScale+芯片的DFX设计注意事项





 工商网监
工商网监
评论