 详解跨镜追踪(ReID)应用分析与技术展望
详解跨镜追踪(ReID)应用分析与技术展望
跨镜追踪(Person Re-Identification,简称 ReID)技术是现在计算机视觉研究的热门方向,主要解决跨摄像头跨场景下行人的识别与检索。该技术能够根据行人的穿着、体态、发型等信息认知行人,与人脸识别结合能够适用于更多新的应用场景,将人工智能的认知水平提高到一个新阶段。
本期大本营公开课,我们邀请到了云从科技资深算法研究员袁余锋老师,他将通过以下四个方面来讲解本次课题:
1、ReID的定义及技术难点;
2、常用数据集与评价指标简介;
3、多粒度网络(MGN)的结构设计与技术实现;
4、ReID在行人跟踪中的应用分析与技术展望
以下是公开课文字版整理内容
ReID 是行人智能认知的其中一个研究方向,行人智能认知是人脸识别之后比较重要的一个研究方向,特别是计算机视觉行业里面,我们首先简单介绍 ReID 里比较热门的几项内容:
1、行人检测。任务是在给定图片中检测出行人位置的矩形框,这个跟之前的人脸检测、汽车检测比较类似,是较为基础的技术,也是很多行人技术的一个前置技术。
2、行人分割以及背景替换。行人分割比行人检测更精准,预估每个行人在图片里的像素概率,把这个像素分割出来是人或是背景,这时用到很多 P 图的场景,比如背景替换。举一个例子,一些网红在做直播时,可以把直播的背景替换成外景,让体验得到提升。
3、骨架关键点检测及姿态识别。一般识别出人体的几个关键点,比如头部、肩部、手掌、脚掌,用到行人姿态识别的任务中,这些技术可以应用在互动娱乐的场景中,类似于 Kinnect 人机互动方面,关键点检测技术是非常有价值的。

4、行人跟踪“ MOT ”的技术。主要是研究人在单个摄像头里行进的轨迹,每个人后面拖了一根线,这根线表示这个人在摄像头里行进的轨迹,和 ReID 技术结合在一起可以形成跨镜头的细粒度的轨迹跟踪。
5、动作识别。动作识别是基于视频的内容理解做的,技术更加复杂一点,但是它与人类的认知更加接近,应用场景会更多,这个技术目前并不成熟。动作识别可以有非常多的应用,比如闯红灯,还有公共场合突发事件的智能认知,像偷窃、聚众斗殴,摄像头识别出这样的行为之后可以采取智能措施,比如自动报警,这有非常大的社会价值。

6、行人属性结构化。把行人的属性提炼出来,比如他衣服的颜色、裤子的类型、背包的颜色。
7、跨境追踪及行人再识别 ReID 技术。

一、ReID 定义及技术难点
▌(一)ReID 定义
我们把 ReID 叫“跨镜追踪技术”,它是现在计算机视觉研究的热门方向,主要解决跨摄像头跨场景下行人的识别与检索。该技术可以作为人脸识别技术的重要补充,可以对无法获取清晰拍摄人脸的行人进行跨摄像头连续跟踪,增强数据的时空连续性。

给大家举个例子,右图由四张图片构成,黄色这个人是之前新闻报道中的偷小孩事件的人,这个人会出现在多个摄像头里,现在警察刑侦时会人工去检索视频里这个人出现的视频段。这就是 ReID 可以应用的场景,ReID 技术可以根据行人的穿着、体貌,在各个摄像头中去检索,把这个人在各个不同摄像头出现的视频段关联起来,然后形成轨迹,这个轨迹对警察刑侦破案有一定帮助。这是一个应用场景。

▌(二)ReID 技术难点
右边是 ReID 的技术特点:首先,ReID 是属于行人识别,是继人脸识别后的一个重要研究方向。另外,研究的对象是人的整体特征,包括衣着、体形、发行、姿态等等。它的特点是跨摄像头,跟人脸识别做补充。
二、常用数据集与评价指标简介
很多人都说过深度学习其实也不难,为什么?只要有很多数据,基本深度学习的数据都能解决,这是一个类似于通用的解法。那我们就要反问,ReID 是一个深度认知问题,是不是用这种逻辑去解决就应该能够迎刃而解?准备了很多数据,ReID 是不是就可以解决?根据我个人的经验回答一下:“在 ReID 中,也行!但仅仅是理论上的,实际操作上非常不行!”
为什么?第一,ReID 有很多技术难点。比如 ReID 在实际应用场景下的数据非常复杂,会受到各种因素的影响,这些因素是客观存在的,ReID 必须要尝试去解决。

第一组图,无正脸照。最大的问题是这个人完全看不到正脸,特别是左图是个背面照,右图戴个帽子,没有正面照。
第二组图,姿态。绿色衣服男子,左边这张图在走路,右图在骑车,而且右图还戴了口罩。
第三组图,配饰。左图是正面照,但右图背面照出现了非常大的背包,左图只能看到两个肩带,根本不知道背包长什么样子,但右图的背包非常大,这张图片有很多背包的信息。
第四组图,遮挡。左图这个人打了遮阳伞,把肩部以上的地方全部挡住了,这是很大的问题。
图片上只列举了四种情况,还有更多情况,比如:
1、相机拍摄角度差异大;
2、监控图片模糊不清;
3、室内室外环境变化;
4、行人更换服装配饰,如之前穿了一件小外套,过一会儿把外套脱掉了;
5、季节性穿衣风格,冬季、夏季穿衣风格差别非常大,但从行人认知来讲他很可能是同一个人;
6、白天晚上的光线差异等。
从刚才列举的情况应该能够理解 ReID 的技术难点,要解决实际问题是非常复杂的。
ReID 常用的数据情况如何?右图列举了 ReID 学术界最常用的三个公开数据集:

第一列,Market1501。用得比较多,拍摄地点在清华大学,图片数量有 32000 张左右,行人数量是 1500 个,相当于每个人差不多有 20 张照片,它是用 6 个摄像头拍的。
第二列,DukeMTMC-reID,拍摄地点是在 Duke 大学,有 36000 张照片,1800 个人,是 8 个摄像头拍的。
第三列,CUHK03,香港中文大学,13000 张照片,1467 个 ID,10 个摄像头拍的。
看了这几个数据集之后,应该能有一个直观的感受,就是在 ReID 研究里,现在图片的数量集大概在几万张左右,而 ID 数量基本小于 2000,摄像头大概在 10 个以下,而且这些照片大部分都来自于学校,所以他们的身份大部分是学生。
这可以跟现在人脸数据集比较一下,人脸数据集动辄都是百万张或者千万张照片,一个人脸的 ID 多的数据集可以上百万,而且身份非常多样。这个其实就是 ReID 面对前面那么复杂的问题,但是数据又那么少的一个比较现实的情况。

这里放三个数据集的照片在这里,上面是 Market1501 的数据集,比如紫色这个人有一些照片检测得并不好,像第二张照片的人只占图片的五分之三左右,并不是一个完整的人。还有些照片只检测到了局部,这是现在数据集比较现实的情况。
总结一下 ReID 数据采集的特点:
1、必须跨摄像头采集,给数据采集的研发团队和公司提出了比较高的要求;
2、公开数据集的数据规模非常小;
3、影响因素复杂多样;
4、数据一般都是视频的连续截图;
5、同一个人最好有多张全身照片;
6、互联网提供的照片基本无法用在 ReID;
7、监控大规模搜集涉及到数据,涉及到用户的隐私问题。

这些都是 ReID 数据采集的特点,可以归结为一句话:“数据获取难度大,会对算法提出比较大的挑战。”问题很复杂,数据很难获取,那怎么办?现在业内尽量在算法层面做更多的工作,提高 ReID 的效果。
这里讲一下评价指标,在 ReID 用得比较多的评价指标有两个:
第一个是 Rank1
第二个是 mAP
ReID 终归还是排序问题,Rank 是排序命中率核心指标。Rank1 是首位命中率,就是排在第一位的图有没有命中他本人,Rank5 是 1-5 张图有没有至少一张命中他本人。更能全面评价ReID 技术的指标是 mAP 平均精度均值。

这里我放了三个图片的检索结果,是 MGN 多粒度网络产生的结果,第一组图 10 张,从左到右是第 1 张到第 10 张,全是他本人图片。第二组图在第 9 张图片模型判断错了,不是同一个人。第三组图,第 1 张到第 6 张图是对的,后面 4 张图检索错了,不是我们模型检索错了,是这个人在底库中总共就 6 张图,把前 6 张检索出来了,其实第三个人是百分之百检索对的。
详细介绍评价指标 mAP。因为 Rank1 只要第一张命中就可以了,有一系列偶然因素在里面,模型训练或者测试时有一些波动。但是 mAP 衡量 ReID 更加全面,为什么?因为它要求被检索人在底库中所有的图片都排在最前面,这时候 mAP 的指标才会高。

给大家举个例子,这里放了两组图,图片 1 和图片 2 是检索图,第一组图在底库中有 5 张图,下面有 5 个数字,我们假设它的检索位置,排在第 1 位、第 3 位、第 4 位、第 8 位,第 20 位,第二张图第 1 位、第 3 位、第 5 位。
它的 mAP 是怎么算的?对于第一张图平均精度有一个公式在下面,就是 0.63 这个位置。第一张是 1 除以 1,第二张是除以排序实际位置,2 除以 3,第三个位置是 3 除以 4,第四个是 4 除以 8,第五张图是 5 除以 20,然后把它们的值求平均,再总除以总的图片量,最后得出的 mAP 值大概是 0.63。
同样的算法,算出图片 2 的精度是 0.756。最后把所有图片的 mAP 求一个平均值,最后得到的 mAP 大概是 69.45。从这个公式可以看到,这个检索图在底库中所有的图片都会去计算 mAP,所以最好的情况是这个人在底库中所有的图片都排在前面,没有任何其他人的照片插到他前面来,就相当于同一个人所有的照片距离都是最近的,这种情况最好,这种要求是非常高的,所以 mAP 是比较能够综合体现这个模型真实水平的指标。
再来看一下 ReID 实现思路与常见方案。ReID 从完整的过程分三个步骤:
第一步,从摄像头的监控视频获得原始图片;
第二步,基于这些原始图片把行人的位置检测出来;
第三步,基于检测出来的行人图片,用 ReID 技术计算图片的距离,但是我们现在做研究是基于常用数据集,把前面图像的采集以及行人检测的两个工作做过了,我们 ReID 的课题主要研究第三个阶段。
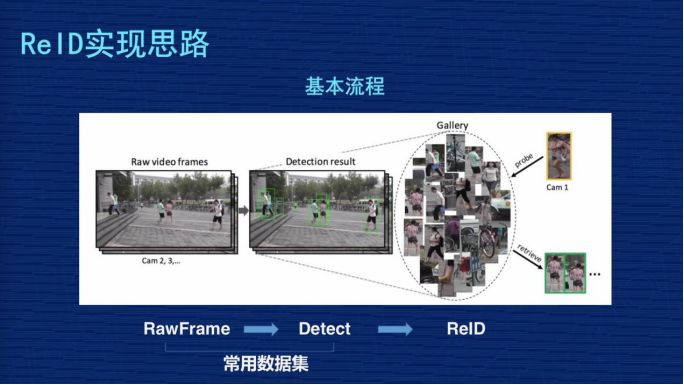
ReID 研究某种意义上来讲,如果抽象得比较高,也是比较清晰的。比如大家看下图,假设黄色衣服的人是检索图,后面密密麻麻很多小图组成的相当于底库,从检索图和底库都抽出表征图像的特征,特征一般都抽象为一个向量,比如 256 维或者 2048 维,这个 Match 会用距离去计算检索图跟库里所有人的距离,然后对距离做排序,距离小的排在前面,距离大的排在后面,我们理解距离小的这些人是同一个人的相似度更高一点,这是一个比较抽象的思维。
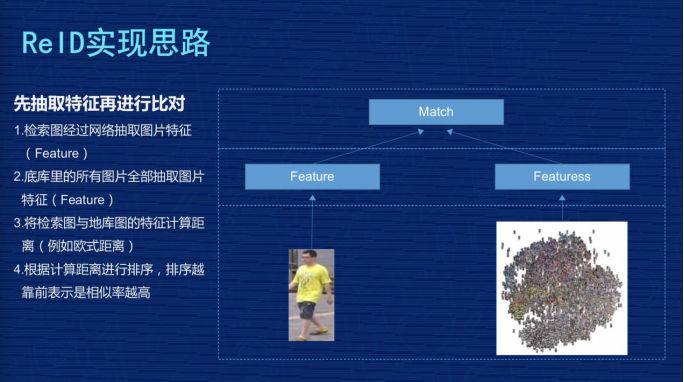
刚才讲到核心是把图像抽象成特征的过程,我再稍微详细的画一个流程,左图的这些图片会经过 CNN 网络,CNN 是卷积神经网络,不同的研究机构会设计自己不同的网络结构,这些图片抽象成特征 Feature,一般是向量表示。
然后分两个阶段,在训练时,我们一般会设计一定的损失函数,在训练阶段尽量让损失函数最小化,最小化过程反向把特征训练得更加有意义,在评估阶段时不会考虑损失函数,直接把特征抽象出来,用这个特征代表这张图片,放到前面那张 PPT 里讲的,去计算它们的距离。
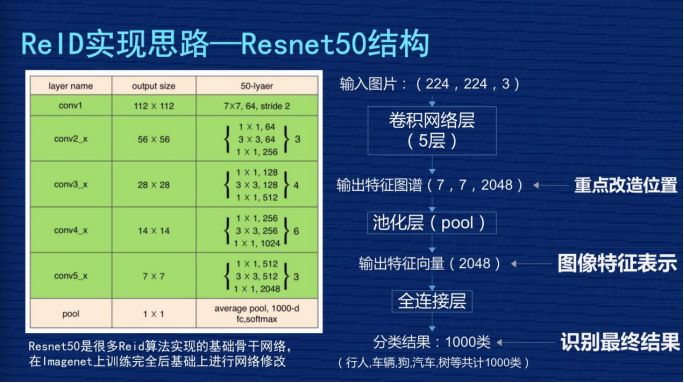
因为现在 ReID 的很多研究课题都是基于 Resnet50 结构去修改的。Resnet 一般会分为五层,图像输入是 (224,224,3),3 是 3 个通道,每层输出的特征图谱长宽都会比上一层缩小一半,比如从 224 到 112,112 到 56,56 到 28,最后第五层输出的特征图谱是 (7,7,2048)。
最后进行池化,变成 2048 向量,这个池化比较形象的解释,就是每个特征图谱里取一个最大值或者平均值。最后基于这个特征做分类,识别它是行人、车辆、汽车。我们网络改造主要是在特征位置(7,7,2048)这个地方,像我们的网络是 384×128,所以我们输出的特征图谱应该是 (12,4,2048)的过程。
下面,我讲一下 ReID 里面常用的算法实现:
▌第一种,表征学习。
给大家介绍一下技术方案,图片上有两行,上面一行、下面一行,这两行网络结构基本是一样的,但是两行中间这个地方会把两行的输出特征进行比较,因为这个网络是用了 4096 的向量,两个特征有一个对比 Loss,这个网络用了两种 Loss,第一个 Loss 是 4096 做分类问题,然后两个 4096 之间会有一个对比 Loss。
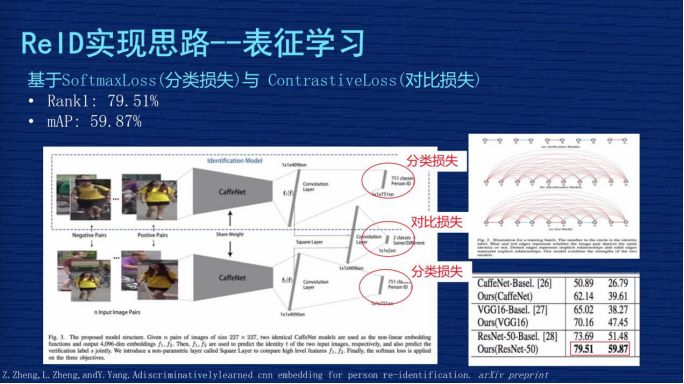
这个分类的问题是怎么定义的?在我们数据集像 mark1501 上有 751 个人的照片组成,这个分类相当于一张图片输入这个网络之后,判断这个人是其中某一个人的概率,要把这个图片分类成 751 个 ID 中其中一个的概率,这个地方的 Loss 一般都用 SoftmaxLoss。机器视觉的同学应该非常熟悉这个,这是非常基本的一个 Loss,对非机器视觉的同学,这个可能要你们自己去理解,它可以作为分类的实现。
这个方案是通过设计分类损失与对比损失,来实现对网络的监督学习。它测试时取的是 4096 这个向量来表征图片本人。这个文章应该是发在 2016 年,作者当时报告的效果在当时的时间点是有一定竞争力的,它的 Rank1 到了 79.51%,mAP 是 59.87%
▌第二种,度量学习方案。
基于TripletLoss 三元损失的 ReID 方案。TripletLoss 是计算机视觉里另外一个常用的 Loss。

它的设计思路是左图下面有三个点,目的是从数据里面选择三个图片,这三个图片由两个人构成,其中两张图片是同一个人,另外一张图片不是同一个人,当这个网络在没有训练的时候,我们假设这同一个人的两张照片距离要大于这个人跟不是同一个人两张图片的距离。
它强制模型训练,使得同一个人两张图片的距离小于第三张图片,就是刚才那张图片上箭头表示的过程。它真正的目的是让同类的距离更近,不同类的距离更远。这是TripletLoss的定义,大家可以去网上搜一下更详细的解释。
在 ReID 方案里面我给大家介绍一个 Batchhard的策略,因为 TripletLoss 在设计时怎么选这三张图是有很多文章在实现不同算法,我们的文章里用的是 Batchhard算法,就是我们从数据集随机抽取 P 个人,每个人 K 张图片形成一个 Batch,每个人的 K 张图片之间形成一个 K×(K-1)个 ap 对,再在剩下其他人里取一个与该 ap 距离最近的 negtive,组成 apn 组,然后我们这个模型使得 apn 组成的 Loss 尽量小。
这个 Loss 怎么定义?右上角有一个公式,就是 ap 距离减 an距离,m 是一个gap,这个值尽量小,使得同类之间尽量靠在一起,异类尽量拉开。右图是 TripletLoss 的实验方案,当时这个作者报告了一个成果,Rank1 到了 84.92%,mAP 到了 69%,这个成果在他发文章的那个阶段是很有竞争力的结果。
▌第三种,局部特征学习。
1、基于局部区域调整的 ReID 解决方案。多粒度网络也是解决局部特征和全局特征的方案。这是作者发的一篇文章,他解释了三种方案。
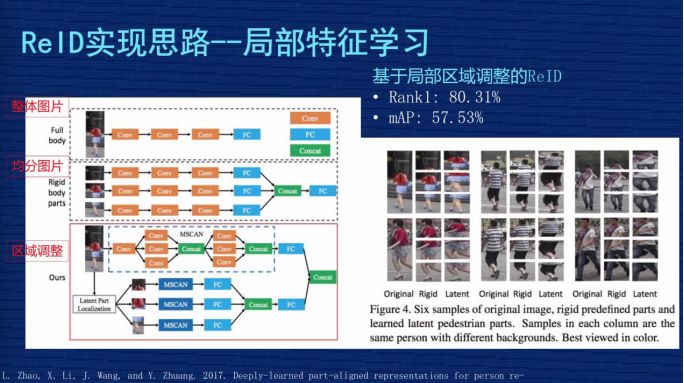
左图第一种方案是把整张图输进网络,取整张图的特征;
第二种方案是把图从上到下均分为三等,三分之一均分,每个部分输入到网络,去提出一个特征,把这三个特征又串连起来;
第三种方案是文章的核心,因为他觉得第二种均分可能出现问题,就是有些图片检测时,因为检测技术不到位,检测的可能不是完整人,可能是人的一部分,或者是人在图里面只占一部分,这种情况如果三分之一均分出来的东西互相比较时就会有问题。
所以他设计一个模型,使得这个模型动态调整不同区域在图片中的占比,把调整的信息跟原来三分的信息结合在一起进行预估。作者当时报告的成果是 Rank1为80% 左右,mAP为57%,用现在的眼光来讲,这个成果不是那么显著,但他把图片切分成细粒度的思路给后面的研究者提供了启发,我们的成果也受助于他们的经验。
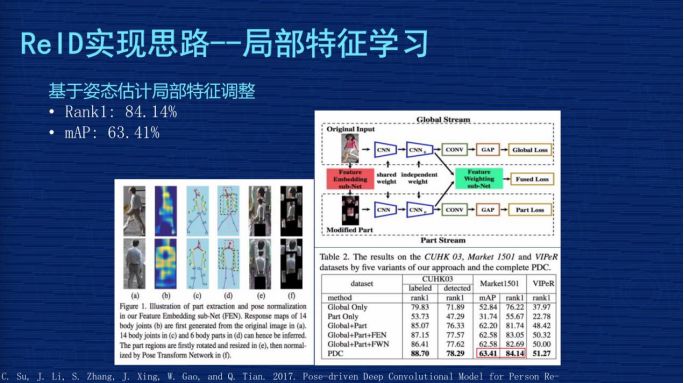
2、基于姿态估计局部特征调整。局部切割是基于图片的,但对里面的语义不了解,是基于姿态估计局部位置的调整怎么做?先通过人体关键点的模型,把这个图片里面人的关节位置取出来,然后按照人类对人体结构的理解,把头跟头比较,手跟手比较,按照人类的语义分割做一些调整,这相对于刚才的硬分割更加容易理解。基于这个调整再去做局部特征的优化,这个文章是发表在 2017 年,当时作者报告的成果 Rank1为84.14%,mAP为63.41%。
3、PCB。发表在 2018 年 1 月份左右的文章,我们简称为 PCB,它的指标效果在现在来看还是可以的,我们多粒度网络有一部分也是受它的启发。下图左边这个特征图较为复杂,可以看一下右边这张图,右图上部分蓝色衣服女孩这张图片输入网络后有一个特征图谱,大概个矩形体组成在这个地方,这是特征图谱。这个图谱位置的尺寸应该是 24×8×2048,就是前面讲的那个特征图谱的位置。

它的优化主要是在这个位置,它干了个什么事?它沿着纵向将24 平均分成 6 份,纵向就是 4,而横向是 8,单个特征图谱变为4×8×2048,但它从上到下有 6 个局部特征图谱。6个特征图谱变为6个向量后做分类,它是同时针对每个局部独立做一个分类,这是这篇文章的精髓。这个方式看起来非常简单,但这个方法跑起来非常有效。作者报告的成果在 2018 年 1 月份时 Rank1 达到了 93.8%,mAP 达到了 81.6%,这在当时是非常好的指标了。
三、多粒度网络(MGN)的结构设计与技术实现
刚才讲了 ReID 研究方面的 5 个方案。接下来要讲的是多粒度网络的结构设计与实现。有人问 MGN 的名字叫什么,英文名字比较长,中文名字是对英文的一个翻译,就是“学习多粒度显著特征用于跨境追踪技术(行人在识别)”,这个文章是发表于 4 月初。

▌(一)多粒度网络(MGN)设计思路。
设计思想是这样子的,一开始是全局特征,把整张图片输入,我们提取它的特征,用这种特征比较 Loss 或比较图片距离。但这时我们发现有一些不显著的细节,还有出现频率比较低的特征会被忽略。比如衣服上有个 LOGO,但不是所有衣服上有 LOGO,只有部分人衣服上有 LOGO。全局特征会做特征均匀化,LOGO 的细节被忽略掉了。

我们基于局部特征也去尝试过,用关键点、人体姿态等。但这种有一些先验知识在里面,比如遮挡、姿态大范围的变化对这种方案有一些影响,效果并不是那么强。
后来我们想到全局特征跟多粒度局部特征结合在一起搞,思路比较简单,全局特征负责整体的宏观上大家共有的特征的提取,然后我们把图像切分成不同块,每一块不同粒度,它去负责不同层次或者不同级别特征的提取。
相信把全局和局部的特征结合在一起,能够有丰富的信息和细节去表征输入图片的完整情况。在观察中发现,确实是随着分割粒度的增加,模型能够学到更详细的细节信息,最终产生 MGN 的网络结构。
下面演示一下多粒度特征,演示两张图,左边第一列有 3 张图,中间这列把这3张图用二分之一上下均分,你可以看到同一个人有上半身、下半身,第三列是把人从上到下分成三块——头部、腹胸、腿部,它有 3 个粒度,每个粒度做独立的引导,使得模型尽量对每个粒度学习更多信息。

右图表示的是注意力的呈现效果,这不是基于我们模型产生的,是基于之前的算法看到的。左边是整张图在输入时网络在关注什么,整个人看着比较均匀,范围比较广一点。第三栏从上到下相当于把它切成 3 块,每一块看的时候它的关注点会更加集中一点,亮度分布不会像左边那么均匀,更关注局部的亮点,我们可以理解为网络在关注不同粒度的信息。
▌(二)多粒度网络(MGN)——网络结构
这是 MGN 的网络架构完整的图,这个网络图比较复杂,第一个,网络从结构上比较直观,从效果来讲是比较有效的,如果想复现我们的方案还是比较容易的。如果你是做深度学习其他方向的,我们这个方案也有一定的普适性,特别是关注细粒度特征时,因为我们不是只针对 ReID 做的。我们设计的结构是有一定普适性,我把它理解为“易迁移”,大家可以作为参考。

首先,输入图的尺寸是 384×128,我们用的是 Resnet50,如果在不做任何改变的情况下,它的特征图谱输出尺寸,从右下角表格可以看到,global 这个地方就相当于对 Resnet 50不做任何的改变,特征图谱输出是 12×4。
下面有一个 part-2 跟 part-3,这是在 Res4_1 的位置,本来是有一个stride等于 2 的下采样的操作,我们把 2 改成1,没有下采样,这个地方的尺寸就不会缩小 2,所以 part-2 跟 part-3 比 global 大一倍的尺寸,它的尺寸是 24×8。为什么要这么操作?因为我们会强制分配 part-2 跟 part-3 去学习细粒度特征,如果把特征尺寸做得大一点,相当于信息更多一点,更利于网络学到更细节的特征。
网络结构从左到右,先是两个人的图片输入,这边有 3 个模块。3 个模块的意思是表示 3 个分支共享网络,前三层这三个分支是共享的,到第四层时分成三个支路,第一个支路是 global 的分支,第二个是 part-2 的分支,第三个是 part-3 的分支。在 global 的地方有两块,右边这个方块比左边的方块大概缩小了一倍,因为做了个下采样,下面两个分支没有做下采样,所以第四层和第五层特征图是一样大小的。
接下来我们对 part-2 跟 part-3 做一个从上到下的纵向分割,part-2 在第五层特征图谱分成两块,part-3 对特征图谱从上到下分成三块。在分割完成后,我们做一个 pooling,相当于求一个最值,我们用的是 Max-pooling,得到一个 2048 的向量,这个是长条形的、横向的、黄色区域这个地方。
但是 part-2 跟 part-3 的操作跟 global 是不一样的,part-2 有两个 pooling,第一个是蓝色的,两个 part 合在一起做一个 global-pooling,我们强制 part-2 去学习细节的联合信息,part-2 有两个细的长条形,就是我们刚才引导它去学细节型的信息。淡蓝色这个地方变成小方体一样,是做降维,从 2048 维做成 256 维,这个主要方便特征计算,因为可以降维,更快更有效。我们在测试的时候会在淡蓝色的地方,小方块从上到下应该是 8 个,我们把这 8 个 256 维的特征串连一个 2048 的特征,用这个特征替代前面输入的图片。
▌(三)多粒度网络(MGN)——Loss设计
Loss 说简单也简单,说复杂也复杂也复杂,为什么?简单是因为整个模型里只用了两种Loss,是机器学习里最常见的,一个是 SoftmaxLoss 一个是 TripletLoss。复杂是因为分支比较多,包括 global 的,包括刚才 local 的分支,而且在各个分支的 Loss 设计上不是完全均等的。我们当时做了些实验和思考去想 Loss 的设计。现在这个方案,第一,从实践上证明是比较好的,第二,从理解上也是容易理解的。
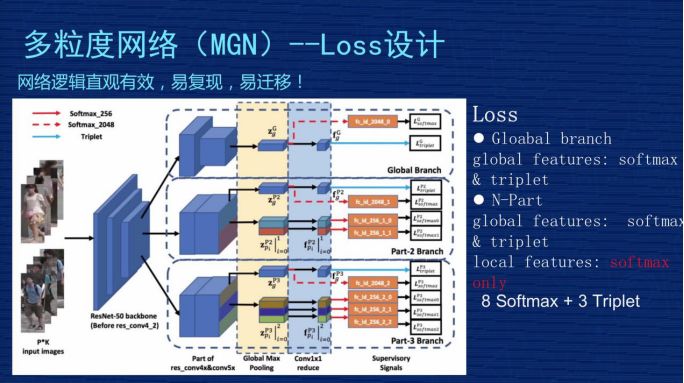
首先,看一下 global 分支。上面第一块的 Loss 设计。这个地方对 2048 维做了SoftmaxLoss,对 256 维做了一个 TripletLoss,这是对 global 信息通用的方法。下面两个部分 global 的处理方式也是一样的,都是对 2048 做一个 SoftmaxLoss,对 256 维做一个 TripletLoss。中间 part-2 地方有一个全局信息,有 global 特征,做 SoftmaxLoss+TripletLoss。
但是,下面两个 Local 特征看不到 TripletLoss,只用了 SoftmaxLoss,这个在文章里也有讨论,我们当时做了实验,如果对细节当和分支做 TripletLoss,效果会变差。为什么效果会变差?
一张图片分成从上到下两部分的时候,最完美的情况当然是上面部分是上半身,下面部分是下半身,但是在实际的图片中,有可能整个人都在上半部分,下半部分全是背景,这种情况用上、下部分来区分,假设下半部分都是背景,把这个背景放到 TripletLoss 三元损失里去算这个 Loss,就会使得这个模型学到莫名其妙的特征。
比如背景图是个树,另外一张图是某个人的下半身,比如一个女生的下半身是一个裙子,你让裙子跟另外图的树去算距离,无论是同类还是不同类,算出来的距离是没有任何物理意义或实际意义的。从模型的角度来讲,它属于污点数据,这个污点数据会引导整个模型崩溃掉或者学到错误信息,使得预测的时候引起错误。所以以后有同学想复现我们方法的时候要注意一下, Part-2、part-3 的 Local 特征千万不要加 TripletLoss。
▌(四)多粒度网络(MGN)——实验参数
图片展示的是一些实验参数,因为很多同学对复现我们的方案有一定兴趣,也好奇到底这个东西为什么可以做那么好。其实我们在文章里把很多参数说得非常透,大家可以按照我们的参数去尝试一下。
我们当时用的框架是 Pytorch。TripletLoss 复现是怎么选择的?我们这个 batch是选 P=16,K=4,16×4,64 张图作为 batch,是随机选择16 个人,每个人随机选择 4 张图。

然后用 SGD 去训练,我们的参数用的是 0.9。另外,我们做了weightdecay,参数是万分之五。像 Market1501 是训练 80epochs,是基于 Resnet50 微调了。我们之前实验过,如果不基于 Resnet50,用随机初始化去训练的话效果很差,很感谢 Resnet50 的作者,对这个模型训练得 非常有意义。
初始学习率是百分之一,到 40 个 epoch 降为千分之一,60 个 epoch 时降为万分之一。我们评估时会对评估图片做左右翻转后提取两个特征,这两个特征求一个平均值,代表这张图片的特征。刚才有人问到我们用了什么硬件,我们用了 2 张的 TITAN 的 GPU。
在 Market1501 上训练 80 epoch的时间大概差不多是 2 小时左右,这个时间是可以接受的,一天训练得快一点可以做出 5-10 组实验。
▌(五)多粒度网络(MGN)——实验结果
我们发表成果时,这个结果是属于三个数据集上最好的。
1、Market1501。我们不做 ReRank 的时候,原始的 Rank1 是 95.7%,mAP 是 86.9%,跟刚才讲的业内比较好的 PCB 那个文章相比,我们的 Rank1 提高差不多 1.9 个点,mAP 整整提高 5.3 个点,得到非常大的提升。
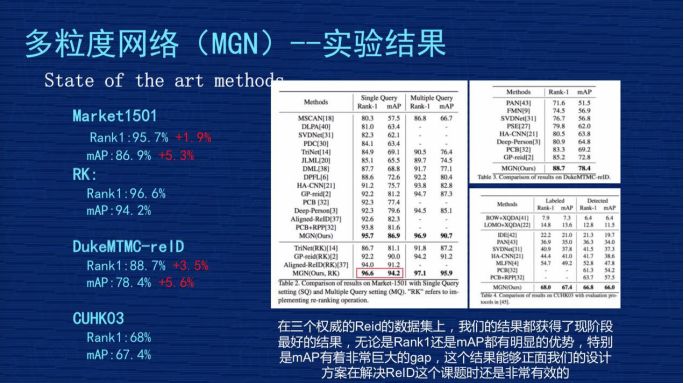
2、RK。Rank1 达到 96.6%,mAP 是 94.2%。RK 是 ReRank 重新排序的简称,ReID 有一篇文章是专门讲 ReRank 技术的,不是从事 ReID 的同学对 ReRank 的技术可能有一定迷惑,大家就理解为这是某种技术,这种技术是用在测试结果重新排列的结果,它会用到测试集本身的信息。因为在现实意义中很有可能这个测试集是开放的,没有办法用到测试集信息,就没有办法做ReRank,前面那个原始的 Rank1 和 mAP 比较有用。
但是对一些已知道测试集数据分布情况下,可以用 ReRank 技术把这个指标有很大的提高,特别是 mAP,像我们方案里从 86.9% 提升到 94.2%,这其中差不多 7.3% 的提升,是非常显著的。
3、DukeMTMC-reID和 CUHKO3这两个结果在我们公布研究成果时算是最好的,我们是4月份公布的成果,现在是 6 月份了,最近 2 个月 CEPR 对关于 ReID 的文章出了差不多 30 几篇,我们也在关注结果。现在除了我们以外最好的成果,原始 Rank1 在 93.5%-94% 之间,mAP 在83.5%-84% 之间,很少看到 mAP 超过 84% 或者 85% 的关于。
▌(六)多粒度网络(MGN)——有趣的对比实验
因为网络结构很复杂,这么复杂的事情能说得清楚吗?里面各个分支到底有没有效?我们在文章里做了几组比较有意思的实验,这里跟大家对比一下。
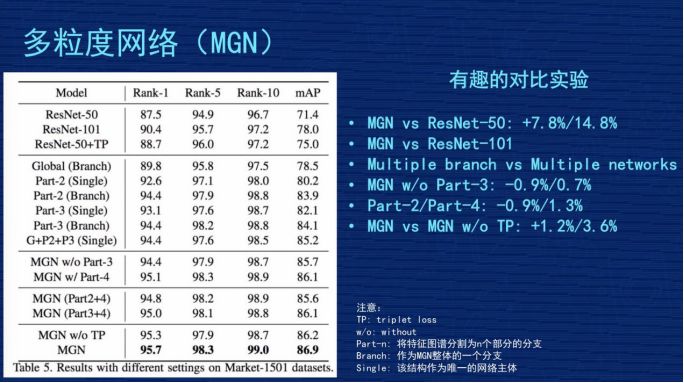
第一个对比,对比 MGN 跟 Resnet50,这倒数第二行,就是那个 MGN w/o TP,跟第一行对比,发现我们的多粒度网络比 Resnet50 水平,Rank1 提高了 7.8%,mAP 提高了14.8%,整体效果是不错的。
第二个对比,因为我们的网络有三个分支,里面参数量肯定会增加,增加的幅度跟 Resnet101的水平差不多,是不是我们网络成果来自于参数增加?我们做了一组实验,第二行有一个 Resnet101,它的 rank1 是 90.4%,mAP 是 78%,这个比 Resnet50 确实好了很多,但是跟我们的工作成果有差距,说明我们的网络也不是纯粹堆参数堆出来的结果,应该是有网络设计的合理性在。
第三个对比,表格第二个大块,搞了三个分支,把这三个分支做成三个独立的网络,同时独立训练,然后把结果结合在一起,是不是效果跟我们差不多,或者比我们好?我们做了实验,最后的结果是“G+P2+P3(single)”,Rank1 有 94.4%,mAP85.2%,效果也不错,但跟我们三个网络联合的网络结构比起来,还是我们的结构更合理。我们的解释是不同分支在学习的时候,会互相去督促或者互相共享有价值的信息,使得大家即使在独立运作时也会更好。
▌(七)多粒度网络(MGN)——多粒度网络效果示例
这是排序图片的呈现效果,左图是排序位置,4 个人的检索结果,前 2 个人可以看到我们的模型是很强的,无论这个人是侧身、背身还是模糊的,都能够检测出来。尤其是第 3 个人,这张图是非常模糊的,整个人是比较黑的,但是我们这个模型根据他的绿色衣服、白色包的信息,还是能够找出来,尽管在第 9 位有一个判断失误。第 4 个人用了一张背面的图,背个包去检索,可以发现结果里正脸照基本被搜出来了。

右边是我们的网络注意力模型,比较有意思的一个结果,左边是原图,右边从左到右有三列,是 global、part2、part3 的特征组,可以看到 global 的时候分布是比较均匀的,说明它没有特别看细节。
越到右边的时候,发现亮点越小,越关注在局部点上,并不是完整的整个人的识别。第 4 个人我用红圈圈出来了,这个人左胸有一个 LOGO,看 part3 右边这张图的时候,整个人只有在 LOGO 地方有一个亮点或者亮点最明显,说明我们网络在 part3 专门针对这个 LOGO 学到非常强的信息,检索结果里肯定是有这个 LOGO 的人排列位置比较靠前。
四、应用场景与技术展望
▌(一)ReID 的应用场景
第一个,与人脸识别结合。
之前人脸识别技术比较成熟,但是人脸识别技术有一个明显的要求,就是必须看到相对清晰的人脸照,如果是一个背面照,完全没有人脸的情况下,人脸识别技术是失效的。
但 ReID 技术和人脸的技术可以做一个补充,当能看到人脸的时候用人脸的技术去识别,当看不到人脸的时候用 ReID 技术去识别,可以延长行人在摄像头连续跟踪的时空延续性。右边位置2、位置3、位置4 的地方可以用 ReID 技术去持续跟踪。跟人脸识别结合是大的 ReID 的应用方向,不是具象的应用场景。

第二个,智能安防。
它的应用场景是这样子的,比如我已经知道某个嫌疑犯的照片,警察想知道嫌疑犯在监控视频里的照片,但监控视频是 24 小时不间断在监控,所以数据量非常大,监控摄像头非常多,比如有几百个、几十个摄像头,但人来对摄像头每秒每秒去看的话非常费时,这时可以用 ReID 技术。
ReID 根据嫌疑犯照片,去监控视频库里去收集嫌疑犯出现的视频段。这样可以把嫌疑犯在各个摄像头的轨迹串连起来,这个轨迹一旦串连起来之后,相信对警察的破案刑侦有非常大的帮助。这是在智能安防的具象应用场景。

第三个,智能寻人系统。
比如大型公共场所,像迪斯尼乐园,爸爸妈妈带着小朋友去玩,小朋友在玩的过程中不小心与爸爸妈妈走散了,现在走散时是在广播里播一下“某某小朋友,你爸爸妈妈在找你”,但小朋友也不是非常懂,父母非常着急。
这时可以用 ReID 技术,爸爸妈妈提供一张小朋友拍的照片,因为游乐园里肯定拍了小朋友拍的照片,比如今天穿得什么衣服、背得什么包,把这个照片输入到 ReID 系统里,实时的在所有监控摄像头寻找这个小朋友的照片,ReID 有这个技术能力,它可以很快的找到跟爸爸妈妈提供的照片最相似的人,相信对立马找到这个小朋友有非常大的帮助。
这种大型公共场所还有更多,比如超市、火车站、展览馆,人流密度比较大的公共场所。智能寻人系统也是比较具象的 ReID 应用场景。

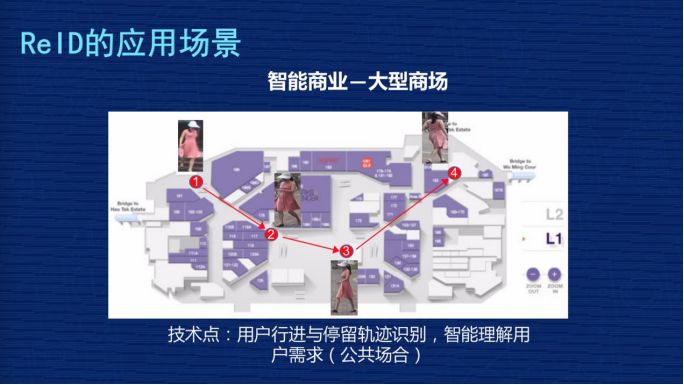
第四个,智能商业-大型商场。
想通过了解用户在商场里的行为轨迹,通过行为轨迹了解用户的兴趣,以便优化用户体验。ReID 可以根据行人外观的照片,实时动态跟踪用户轨迹,把轨迹转化成管理员能够理解的信息,以帮助大家去优化商业体验。
这个过程中会涉及到用户隐私之类的,但从 ReID 的角度来讲,我们比较提倡数据源来自于哪个商场,那就应用到哪个商场。因为 ReID 的数据很复杂,数据的迁移能力是比较弱的,这个上场的数据不见得在另外一个商场里能用,所以我们提倡 ReID 的数据应用在本商场。
第五个,智能商业-无人超市。
无人超市也有类似的需求,无人超市不只是体验优化,它还要了解用户的购物行为,因为如果只基于人脸来做,很多时候是拍不到客户的正面,ReID 这个技术在无人超市的场景下有非常大的应用帮助。

第六个,相册聚类。
现在拍照时,可以把相同人的照片聚在一起,方便大家去管理,这也是一个具象的应用场景。

第七个,家庭机器人。
家庭机器人通过衣着或者姿态去认知主人,做一些智能跟随等动作,因为家庭机器人很难实时看到主人的人脸,用人脸识别的技术去做跟踪的话,我觉得还是有一些局限性的。但是整个人体的照片比较容易获得,比如家里有一个小的机器人,它能够看到主人的照片,无论是上半年还是下半年,ReID 可以基于背影或者局部服饰去识别。

▌(二)ReID 的技术展望
第一个,ReID 的数据比较难获取,如果用应用无监督学习去提高 ReID 效果,可以降低数据采集的依赖性,这也是一个研究方向。右边可以看到,GAN生成数据来帮助 ReID 数据增强,现在也是一个很大的分支,但这只是应用无监督学习的一个方向。
第二个,基于视频的 ReID。因为刚才几个数据集是基于对视频切好的单个图片而已,但实际应用场景中还存在着视频的连续帧,连续帧可以获取更多信息,跟实际应用更贴近,很多研究者也在进行基于视频 ReID 的技术。

第三个,跨模态的 ReID。刚才讲到白天和黑夜的问题,黑夜时可以用红外的摄像头拍出来的跟白色采样摄像头做匹配。
第四个,跨场景的迁移学习。就是在一个场景比如 market1501 上学到的 ReID,怎样在 Duke数据集上提高效果。
第五个,应用系统设计。相当于设计一套系统让 ReID 这个技术实际应用到行人检索等技术上去。
-
人工智能
+关注
关注
1791文章
47183浏览量
238200 -
REID
+关注
关注
1文章
18浏览量
10856
原文标题:云从科技资深算法研究员:详解跨镜追踪(ReID)技术实现及难点 | 公开课笔记
文章出处:【微信号:AI_Thinker,微信公众号:人工智能头条】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
电流镜设计步骤详解【全过程】
使用LabVIEW进行物体追踪图像处理分析
人工智能即将从“刷脸”跨到“识人”的新纪元
澎思科技ReID技术取得新突破
ReID行人重识别再破行业新高,多目标定位与追踪精准呈现
Vulkan光线追踪技术,实现跨平台和跨系统
基于其自主知识产权的新一代商用级跨镜追踪Re-ID技术





 工商网监
工商网监
评论