 神经网络、机器翻译、情感分类和自动评论等研究方向的5篇论文
神经网络、机器翻译、情感分类和自动评论等研究方向的5篇论文
第 56 届计算语言学协会年会ACL 2018将于当地时间7月15-20日在澳大利亚墨尔本举办。腾讯AI Lab 今年共有5 篇论文入选,涉及到神经机器翻译、情感分类和自动评论等研究方向。下面将介绍这 5 篇论文的研究内容。
1、通往鲁棒的神经网络机器翻译指路(Towards Robust Neural MachineTranslation)
论文地址:https://arxiv.org/abs/1805.06130
在神经机器翻译(NMT)中,由于引入了循环神经网络(RNN)和注意机制,上下文中的每个词都可能影响模型的全局输出结果,这有些类似于“蝴蝶效应”。也就是说,NMT对输入中的微小扰动极其敏感,比如将输入中某个词替换成其近义词就可能导致输出结果发生极大变化,甚至修改翻译结果的极性。针对这一问题,研究者在本论文中提出使用对抗性稳定训练来同时增强神经机器翻译的编码器与解码器的鲁棒性。
上图给出了该方法的架构示意,其工作过程为:给定一个输入句子x,首先生成与其对应的扰动输入x',接着采用对抗训练鼓励编码器对于x 和x' 生成相似的中间表示,同时要求解码器端输出相同的目标句子y。这样能使得输入中的微小扰动不会导致目标输出产生较大差异。
研究者在论文中提出了两种构造扰动输入的方法。第一种是在特征级别(词向量)中加入高斯噪声;第二种是在词级别中用近义词来替换原词。
研究表明,该框架可以扩展应用于各种不同的噪声扰动并且不依赖于特定的 NMT 架构。实验结果表明该方法能够同时增强神经机器翻译模型的鲁棒性和翻译质量,下表给出了在NIST 汉语-英语翻译任务上的大小写不敏感 BLEU 分数。
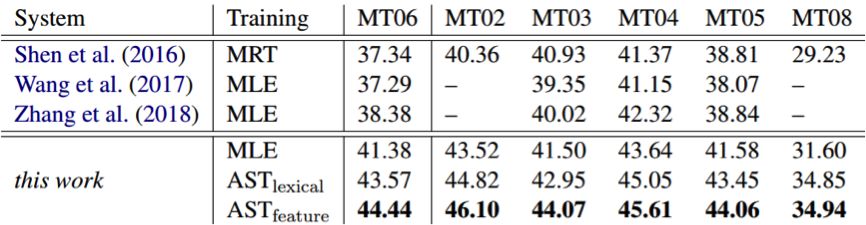
可以看到,研究者使用极大似然估计(MLE)训练的 NMT 系统优于其它最好模型大约3 BLEU。
2、hyperdoc2vec:超文本文档的分布式表示(hyperdoc2vec:Distributed Representations of Hypertext Documents)
论文地址:https://arxiv.org/abs/1805.03793
现实世界中很多文档都具有超链接的结构。例如,维基页面(普通网页)之间通过URL互相指向,学术论文之间通过引用互相指向。超文档的嵌入(embedding)可以辅助相关对象(如实体、论文)的分类、推荐、检索等问题。然而,针对普通文档的传统嵌入方法往往偏重建模文本/链接网络中的一个方面,若简单运用于超文档,会造成信息丢失。
本论文提出了超文档嵌入模型在保留必要信息方面应满足的四个标准并且表明已有的方法都无法同时满足这些标准。这些标准分别为:
内容感知度(content awareness):超文档的内容自然在描述该超文档方面起主要作用
上下文感知度(context awareness):超链接上下文通常能提供目标文档的总结归纳
新信息友好度(newcomer friendliness):对于没有被其它任何文档索引的文档,需要采用适当的方式得到它们的嵌入
语境意图感知度(context intent awareness):超链接周围的“evaluate... by”这样的词通常指示了源超文档使用该引用的原因
为此,研究者提出了一种新的嵌入模型hyperdoc2vec。不同于大多数已有方法,hyperdoc2vec会为每个超文档学习两个向量,以表征其引用其它文档的情况和被引用的情况。因此,hyperdoc2vec可以直接建模超链接或引用情况,而不损失其中包含的信息。下面给出了hyperdoc2vec 模型示意图:
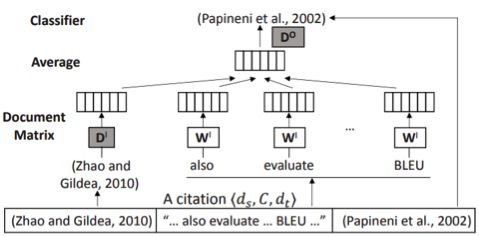
为了评估所学习到的嵌入,研究者在三个论文领域数据集以及论文分类和引用推荐两个任务上系统地比较了hyperdoc2vec 与其它方法。模型分析和实验结果都验证了hyperdoc2vec 在以上四个标准下的优越性。下表展示了在DBLP 上的 F1 分数结果:
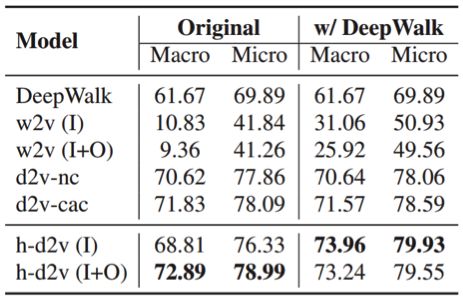
可以看到,添加了 DeepWalk 信息后基本都能得到更优的结果;而不管是否使用了 DeepWalk,hyperdoc2vec的结果都是最优的。
3、TNet:面向评论目标的情感分类架构(TransformationNetworks for Target-Oriented Sentiment Classification)
论文地址:https://arxiv.org/abs/1805.01086
开源项目:https://github.com/lixin4ever/TNet
面向评论目标(opinion target)的情感分类任务是为了检测用户对于给定评论实体的情感倾向性。直观上来说,带注意机制的循环神经网络(RNN)很适合处理这类任务,以往的工作也表明基于这类模型的工作确实取得了很好的效果。
研究者在这篇论文中尝试了一种新思路,即用卷积神经网络(CNN)替代基于注意机制的RNN去提取最重要的分类特征。
由于CNN 很难捕捉目标实体信息,所以研究者设计了一个特征变换组件来将实体信息引入到单词的语义表示当中。但这个特征变换过程可能会使上下文信息丢失。针对这一问题,研究者又提出了一种“上下文保留”机制,可将带有上下文信息的特征和变换之后的特征结合起来。
综合起来,研究者提出了一种名为目标特定的变换网络(TNet)的新架构,如下左图所示。其底部是一个BiLSTM,其可将输入变换成有上下文的词表示(即 BiLSTM 的隐藏状态)。其中部是TNet 的核心部分,由 L 个上下文保留变换(CPT)层构成。最上面的部分是一个可感知位置的卷积层,其首先会编码词和目标之间的位置相关性,然后提取信息特征以便分类。
右图则展示了一个CPT 模块的细节,其中有一个全新设计的TST 组件,可将目标信息整合进词表示中。此外,其中还包含一个上下文保留机制。
研究者在三个标准数据集上评估了新提出的框架,结果表明新方法的准确率和F1值全面优于已有方法;下表给出了详细的实验结果。
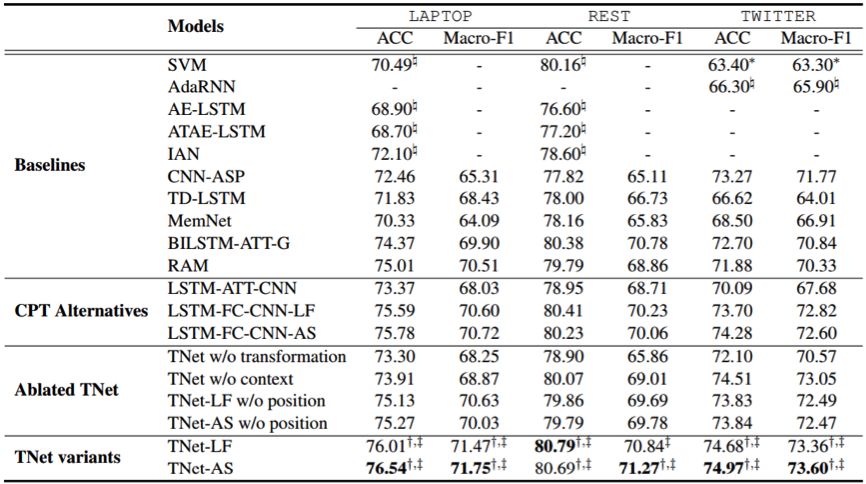
本研究的相关代码已经开源。
4、兼具领域适应和情感感知能力的词嵌入学习(Learning Domain-Sensitive andSentiment-Aware Word Embeddings)
论文地址:https://arxiv.org/abs/1805.03801
词嵌入是一种有效的词表示方法,已被广泛用于情感分类任务中。一些现有的词嵌入方法能够捕捉情感信息,但是对于来自不同领域的评论,它们不能产生领域适应的词向量。另一方面,一些现有的方法可以考虑多领域的词向量自适应,但是它们不能区分具有相似上下文但是情感极性相反的词。
在这篇论文中,研究者提出了一种学习领域适应和情感感知的词嵌入(DSE)的新方法,可同时捕获词的情感语义和领域信息。本方法可以自动确定和生成领域无关的词向量和领域相关的词向量。模型可以区分领域无关的词和领域相关的词,从而使我们可以利用来自于多个领域的共同情感词的信息,并且同时捕获来自不同领域的领域相关词的不同语义。
在 DSE 模型中,研究者为词汇表中的每个词都设计了一个用于描述该词是领域无关词的概率的分布。这个概率分布的推理是根据所观察的情感和上下文进行的。具体而言,其推理算法结合了期望最大化(EM)方法和一种负采样方案,其过程如下算法1 所示。

其中,E 步骤使用了贝叶斯规则来评估每个词的 zw(一个描述领域相关性的隐变量)的后验分布以及推导目标函数。而在M 步骤中则会使用梯度下降法最大化该目标函数并更新相应的嵌入。
研究者在一个亚马逊产品评论数据集上进行了实验,下表给出了评论情感分类的实验结果:
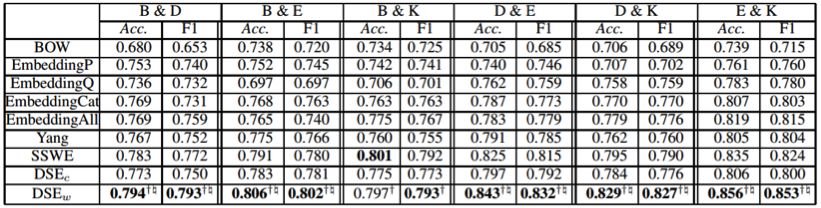
实验结果表明,本工作提供了一个有效的学习兼具领域适应和情感感知能力的词嵌入的方法,并提高了在句子层面和词汇层面的情感分类任务的性能。
5、自动评论文章:任务和数据集(Automatic Article Commenting: theTask and Dataset)
论文地址:https://arxiv.org/abs/1805.03668
公开数据集:https://ai.tencent.com/upload/PapersUploads/article_commenting.tgz
在线文章的评论可以提供延伸的观点以及提升用户的参与度。因而,自动产生评论正成为在线论坛和智能聊天机器人中的一个很有价值的功能。
本论文提出了一个新的自动评论文章任务,并为这个任务构建了一个大规模的中文数据集:它包含数百万条真实评论和一个人工标注的、能够表达评论质量的子集。下图给出了这个数据集的统计信息和分类情况:
这个数据集是从腾讯新闻(news.qq.com)收集的。其中每个实例都有一个标题以及文章的文本内容,还有一组读者评论及辅助信息(sideinformation),该辅助信息中包含编辑为该文章划分的类别以及每个评论获得的用户点赞数。
研究者爬取了 2017 年 4 月到 8 月的新闻文章及相关内容,然后使用Python 库Jieba 对所有文本进行了token 化,并过滤掉了文本少于 30 词的短文章和评论数少于 20 的文章。所得到的语料又被分成了训练集、开发集和测试集。该数据集的词汇库大小为1858452。文章标题和内容的平均长度分别为 15 和 554 中文词(不是汉字)。平均评论长度为17 词。辅助信息方面,每篇文章都关联了44 个类别中的一个。每条评论的点赞数量平均在 3.4-5.9 之间,尽管这个数字看起来很小,但该分布表现出了长尾模式——受欢迎的评论的点赞数可达成千上万。
该数据集已开放下载。
通过引入评论质量的人工偏好,本论文还提出了多个自动评价度量(W-METEOR、W-BLEU、W-ROUGE、W-CIDEr),它们拓展了现有主流的基于参考答案的度量方法而且它们获得了与人类评价更好的相关度。研究者也演示了该数据集和相关评价度量在检索和生成模型上的应用。
-
编码器
+关注
关注
45文章
3638浏览量
134419 -
神经网络
+关注
关注
42文章
4771浏览量
100709 -
机器翻译
+关注
关注
0文章
139浏览量
14880
原文标题:【ACL2018】腾讯AI Lab入选5篇论文解读:神经机器翻译、情感分类等
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
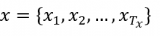





 工商网监
工商网监
评论