 如何在Python中进行Elasticsearch操作?
如何在Python中进行Elasticsearch操作?
什么是ElasticSearch?
ElasticSearch(ES)是一个建立在Apache Lucene之上的高度可用的分布式开源搜索引擎。它基于Java构建的,因此可用于许多平台。数据以JSON格式非结构化存储,这也使其成为一种NoSQL数据库。与其他NoSQL数据库不同,ES还提供搜索引擎功能和其他相关功能。
ElasticSearch用例
ES可用于多种目的,下面给出了其中的几个:
你运营着提供大量动态内容的网站,比如电子商务网站或者博客。通过实施ES,你不仅可以为Web应用程序提供强大的搜索引擎,还可以在应用程序中提供原生自动补全功能。
你可以获取不同类型的日志数据,然后可以使用它来查找趋势和统计信息。
设置和运行
安装ElasticSearch最简单的方法就是下载并运行可执行文件。必须确保使用的是Java 7或更高版本。
下载后解压缩并运行它的二进制文件。

滚动窗口中会出现很多文字。如果你看到像下面这样的,那么它应该是完成了。

但是,由于眼见为实,通过cURL 查看类似于这样的欢迎界面以便你知道确实成功安装了:
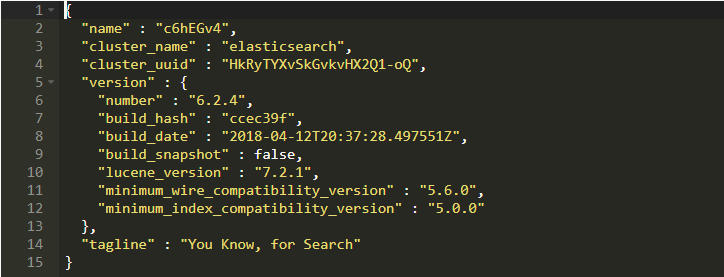
在我开始访问Python中的Elastic Search之前,我们来做一些基本的东西。 正如我提到ES提供了一个REST API接口,我们将使用它来执行不同的任务。
基本示例
你要做的第一件事就是创建索引。一切都以索引形式存储。RDBMS概念中索引相当于一个数据库,因此不要将它与你在RDBMS中学习的典型索引概念混淆。使用PostMan来运行REST API。

如果它成功运行,你会看到如下所示的回应:
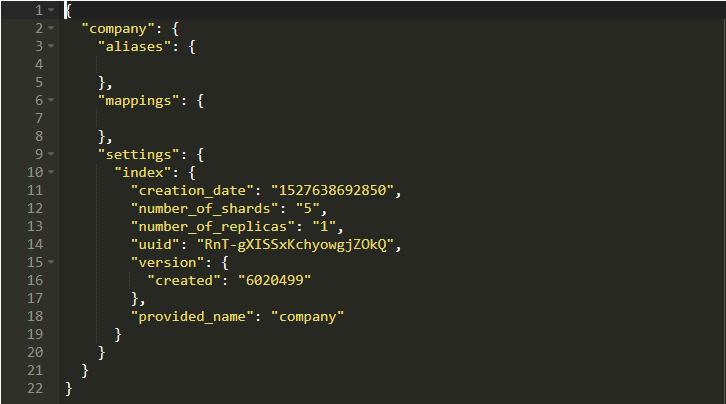
所以我们使用company为名创建了一个数据库。换句话说,我们创建了一个名为“company”的索引。你将看到如下所示的内容:
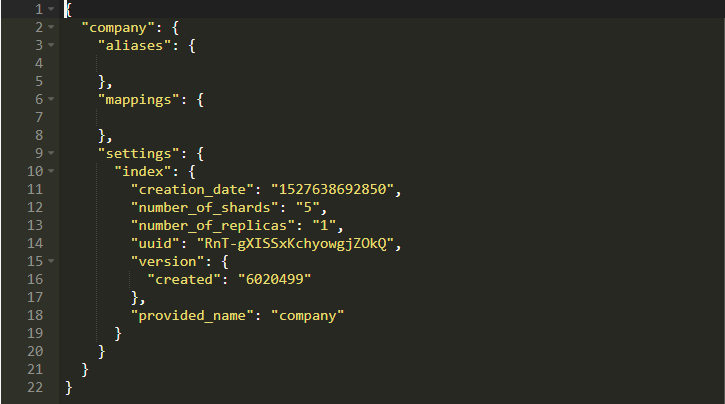
暂时不用管mappings是什么,我们会在后面讨论它。它实际上做的只是创建一个你自己的Schema文档。creation_date是不言自明的。number_of_shards表示将保留此索引数据的分区数量。将整个数据保存在单个磁盘上毫无意义。如果你运行的是多个Elastic节点的集群,那么整个数据都会被分割。简而言之,如果有5个分片,则整个数据可以在5个分片中使用,并且ElasticSearch集群可以服务来自其任何节点的请求。
副本讨论的是你的数据的镜像。如果你熟悉主从概念,那么这对你来说不应该是新事物。你可以了解更多关于基本ES概念。
创建索引的cURL版本是单线程的。

你也可以一次执行索引创建和记录插入任务。你所要做的就是以JSON格式传递你的记录。你可以在PostMan中使用下面的东西:
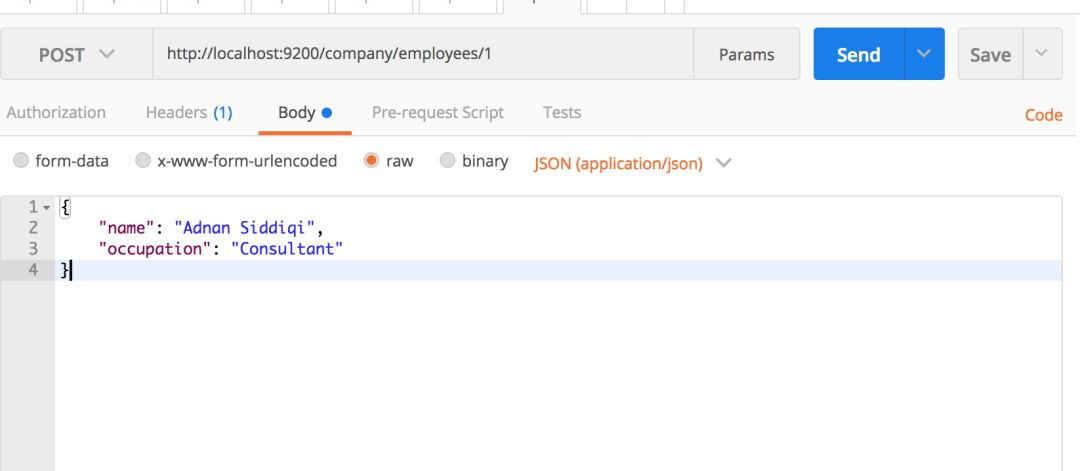
请确保你将Content-Type设置为application/json.
一个名为company的索引会被创建如果它原本不存在的话,然后在这里创建一个名为employees的新类型。Type实际上是RDBMS中的表的ES版本。
上述请求将输出以下JSON结构:
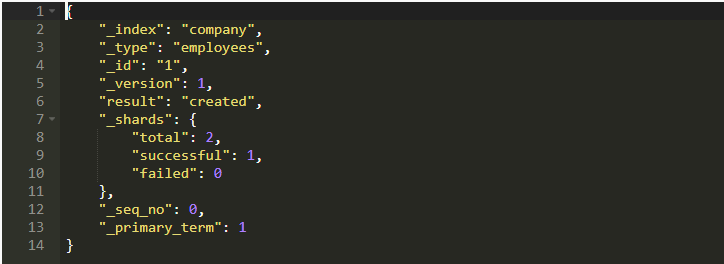
你传递/1作为你的记录的ID,但这是不必要的。它所做的只是将_id字段设置为值1,然后数据以JSON格式传递,最终作为新记录或文档插入。

你可以看到元和实际记录。
cURL版本将是:
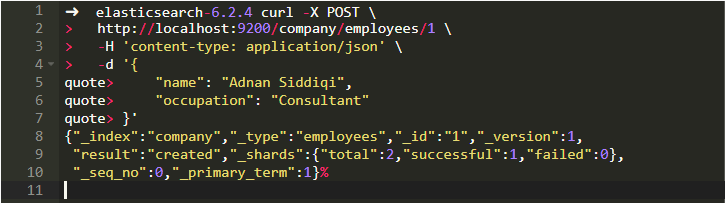
如果你想更新该记录怎么办?这很简单。你所要做的就是改变你的JSON记录。如下所示:
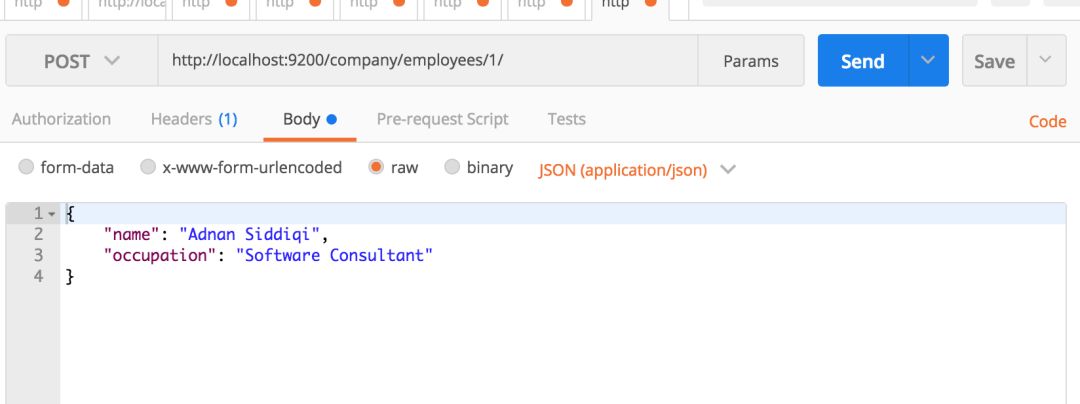
它会生成以下输出:
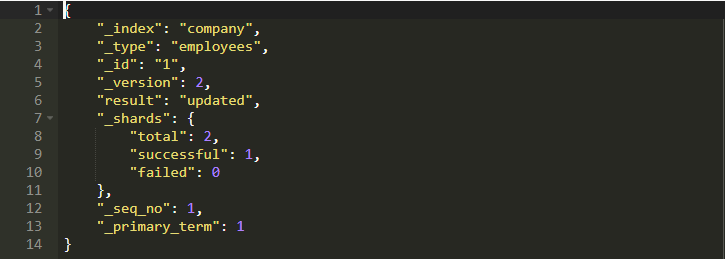
注意现在_result字段设置为updated而不是created。
当然,你也可以删除某些记录。
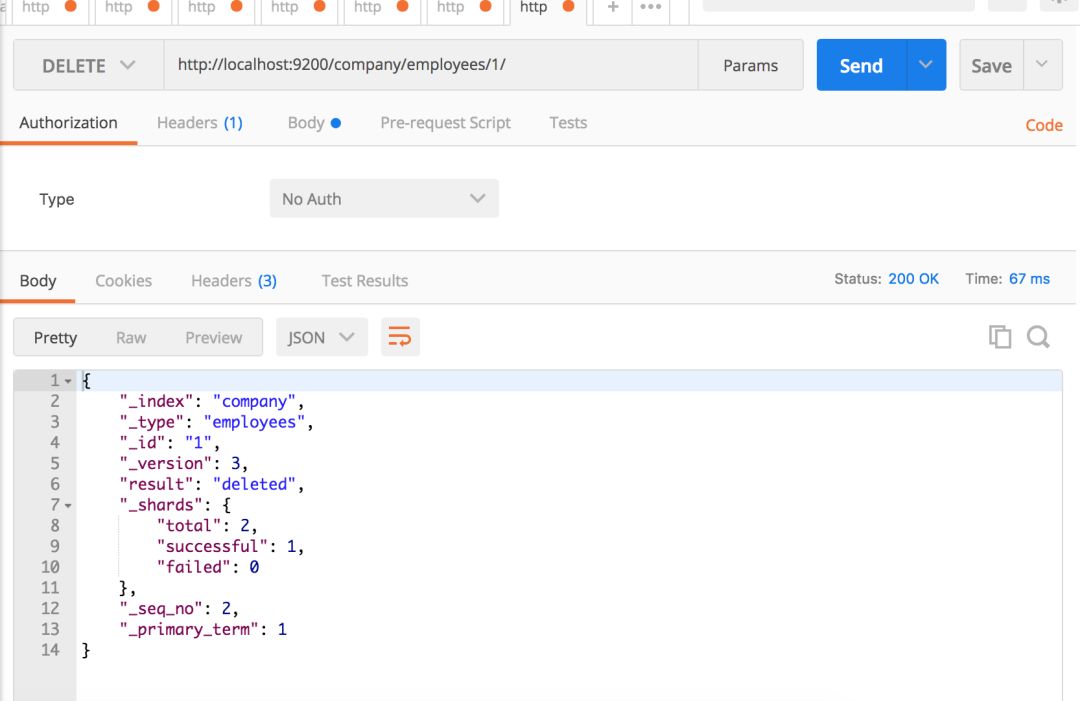
如果你疯了,或者你的女朋友甩了你,你可以通过从命令行运行curl -XDELETE localhost:9200/_all来毁掉整个世界。
让我们做一些基本的搜索。 它将搜索employees类型下的所有字段并返回相关记录。
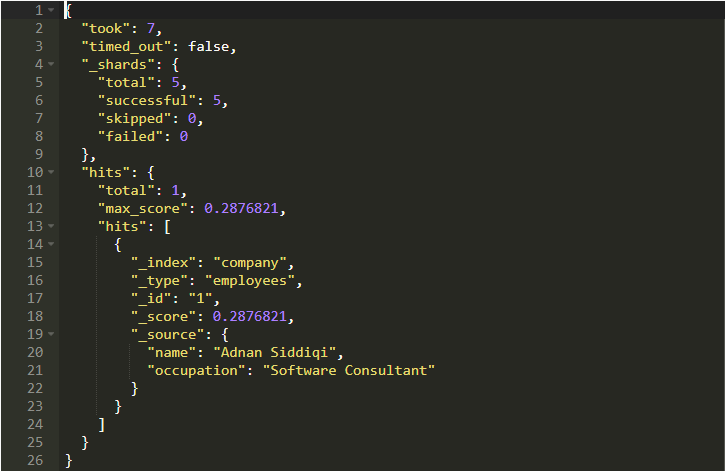
max_score字段表示记录的相关性,即记录的最高分数。如果有多个记录,那么它会是一个不同的数字。
你还可以通过传递字段名称将搜索条件限制到某个字段。
我刚刚介绍了基本的例子。ES可以做很多事情,但是希望你自己通过阅读文档来进一步探索它,而我将继续介绍在Python中使用ES。
在Python中使用ElasticSearch
说实话,ES的REST API已经足够好了,可以让你使用requests库执行所有任务。不过,你可以使用ElasticSearch的Python库专注于主要任务,而不必担心如何创建请求。
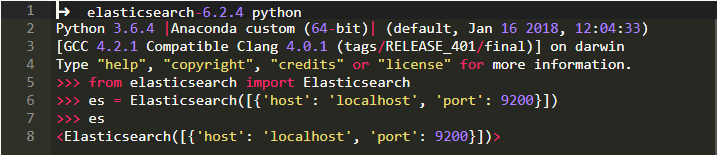
通过pip安装它,然后你可以在你的Python程序中访问它。

为确保它的安装正确,请从命令行运行以下基本片段:
网页搜索和Elasticsearch
我们来讨论一下使用Elasticsearch的一些实际用例。我们的目标是访问在线食谱并将它们存储在Elasticsearch中以用于搜索和分析。我们将首先从Allrecipes中获取数据并将其存储在ES中。我们还将创建一个严格的模式或映射,以便我们确保数据以正确的格式和类型进行索引。最后只要列出沙拉食谱的清单。我们开始吧!
获取数据
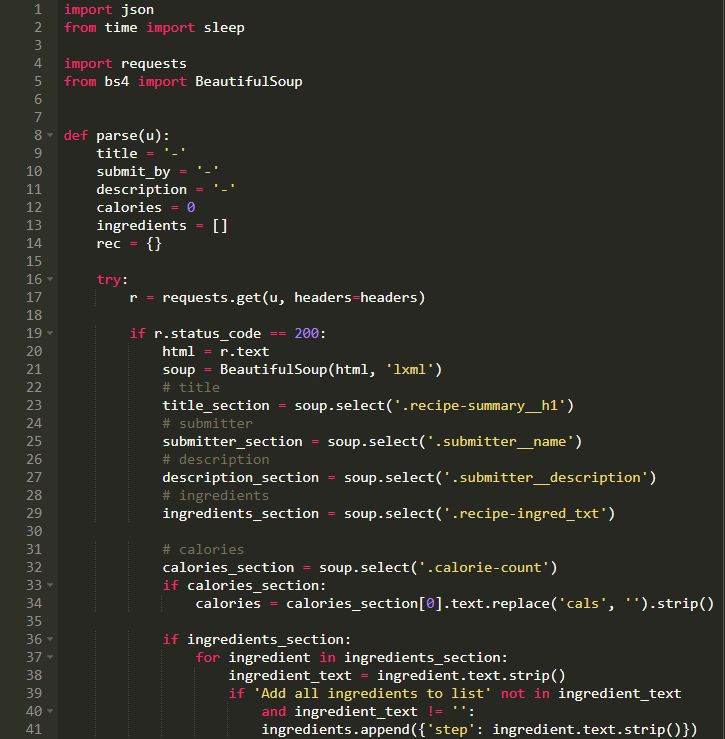
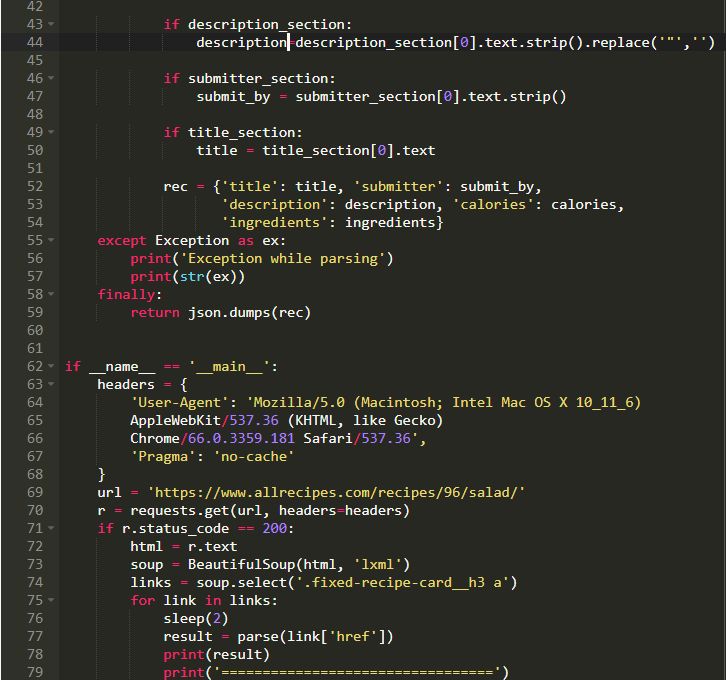
所以这是获取数据的基本程序。因为我们需要JSON格式的数据,所以我对其进行了相应的转换。
创建索引
我们得到了所需的数据,接下来我们必须存储它。我们要做的第一件事就是创建一个索引。让我们将其命名为recipes。 该类型将被称为salads。我要做的另一件事是创建我们的文档结构的映射。
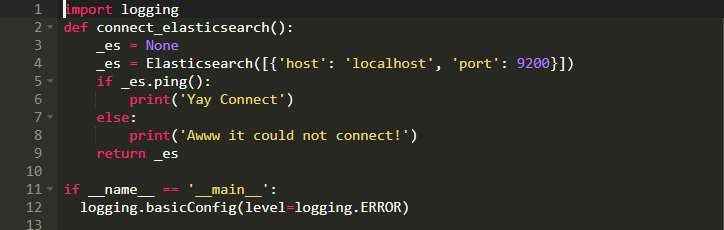
在我们创建索引之前,我们必须连接ElasticSearch服务器。
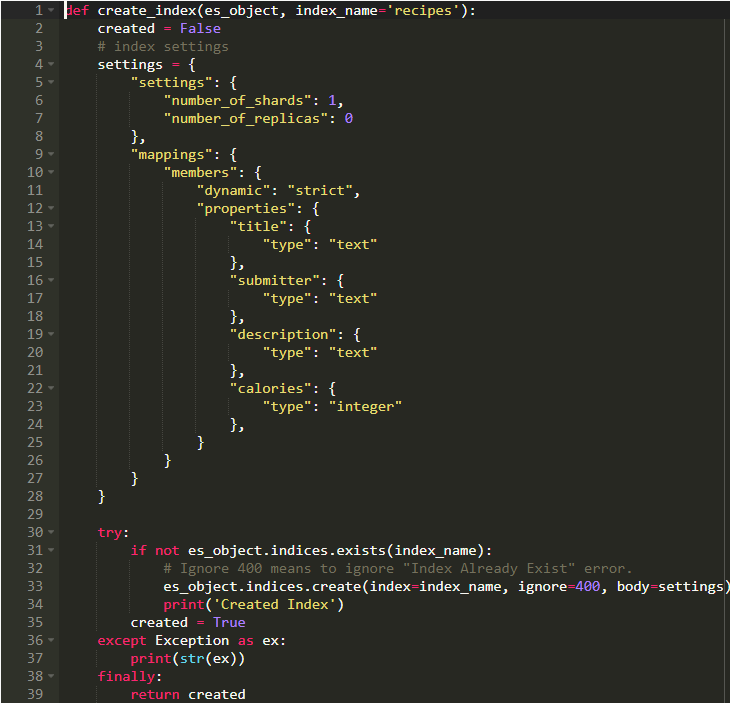
这里有很多要说的事。首先,我们传递了一个包含整个文档结构映射的配置变量。映射是模式这一术语在Elastic的版本。就像我们在表格中设置特定的字段数据类型一样,我们在这里做类似的事情。检查文档,它涵盖的不仅仅是这些。所有字段都是文本类型,但是calories类型为Integer。
接下来,我确保索引不存在,然后创建它。参数ignore = 400在检查后不再需要,但存在性证明是必要的,因为这可以防止错误地覆盖现有索引。虽然这很危险。这就像覆盖数据库。
如果索引成功创建,你可以验证它,它会输出如下所示的内容:
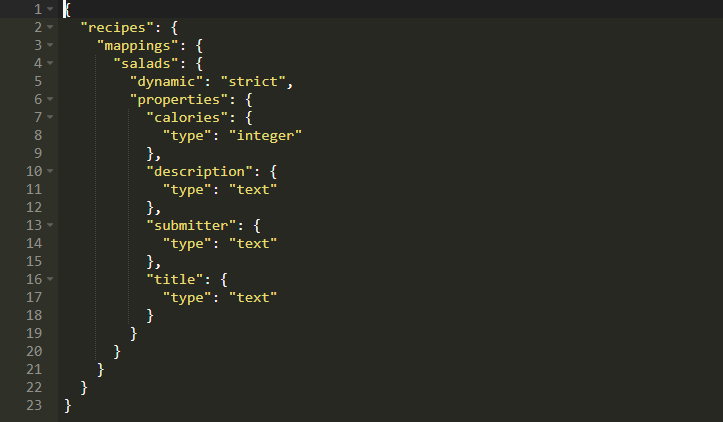
通过传递dynamic:strict我们使Elasticsearch严格检查任何传入的文档。在这里,salads实际上是文档类型。Type实际上是Elasticsearch对RDBMS表的回答。
记录索引
下一步是存储实际的数据或文档。

运行它,你会看到:

你能猜到为什么会这样吗?由于我们没有在我们的映射中设置ingredients,因此ES不允许我们存储包含ingredients字段的文档。现在你知道事先分配映射的优势了。你可以通过这样做避免破坏数据。现在,让我们稍微修改一下映射,现在看起来如下所示:
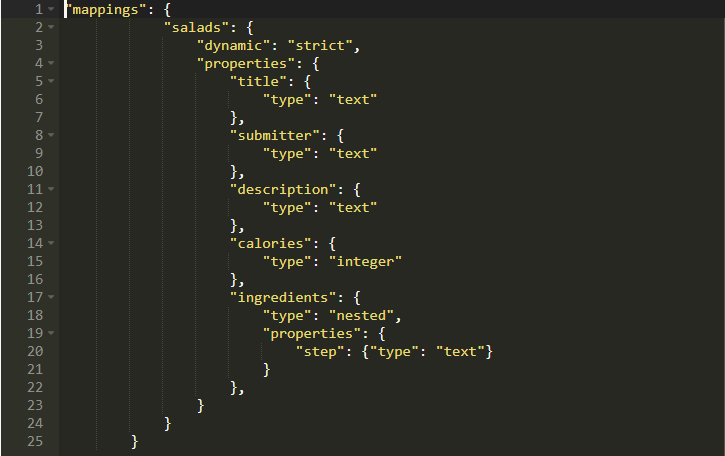
我们添加nested类型的ingrdients,然后分配内部字段的数据类型,即在我们的案例中的text。
nested数据类型允许设置嵌套的JSON对象的类型。再次运行它,你将看到以下输出:
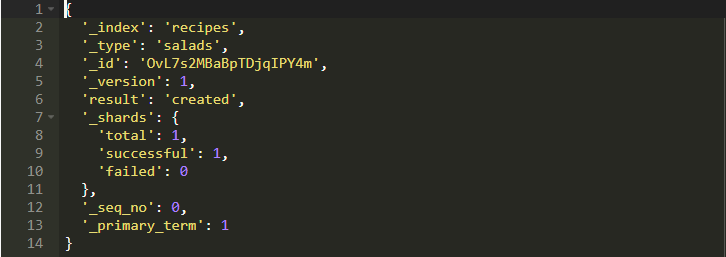
由于你根本没有传递_id,因此ES本身为存储的文档分配了一个动态ID。 我使用Chrome,借助名为ElasticSearch Toolbox的工具使用ES数据查看器来查看数据。
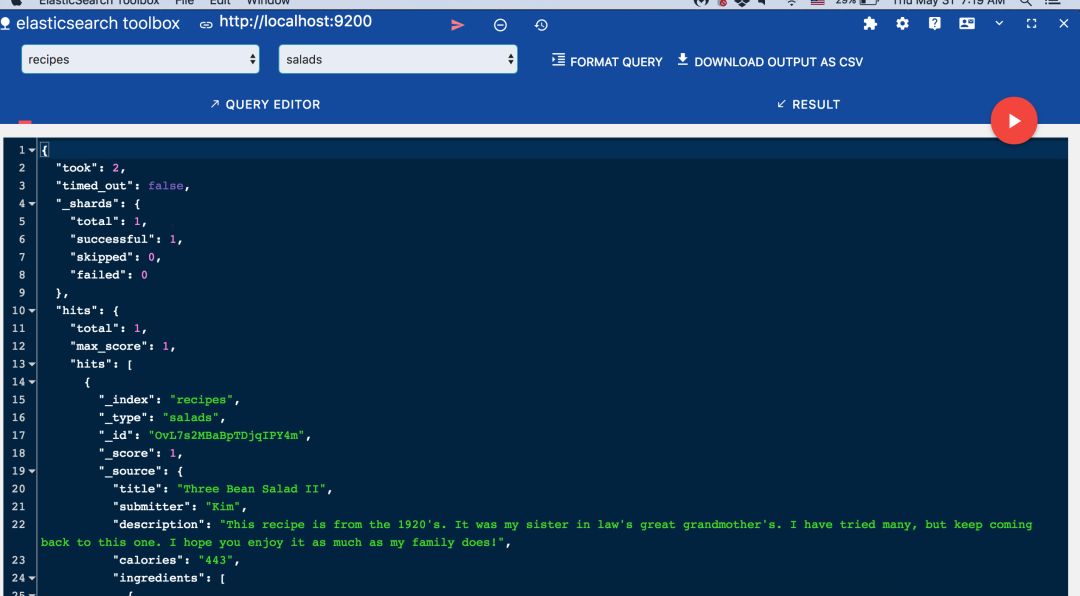
在我们继续之前,让我们在calories字段中发送一个字符串,看看它是如何发生的。请记住,我们已将其设置为整数。 在编制索引时出现以下错误:

所以现在你知道为文档分配一个映射的好处了。如果你不这样做,它仍然会工作,因为Elasticsearch将在运行时分配它自己的映射。
查询记录
现在,记录被编入索引,是时候根据我们的需要查询它们了。我将创建一个名为search()的函数,它将显示我们的查询结果。

这是非常基本的。 你在其中传递索引和搜索条件。让我们尝试一些查询。

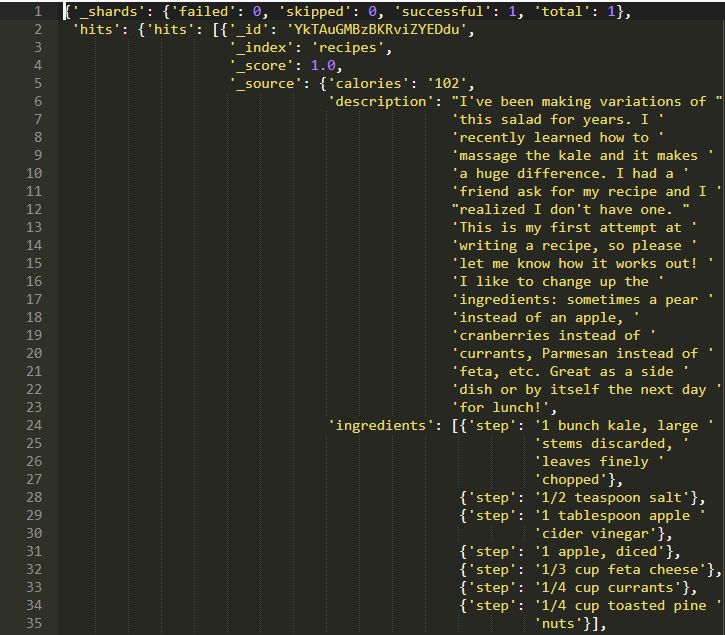

如果你想获得卡路里超过20的记录怎么办?

你也可以指定想要返回的列或字段。上述查询将返回卡路里大于20的所有记录。此外,它将仅在_source下显示title字段。
结论
Elasticsearch是一个功能强大的工具,它可以提供强大的功能帮助你来返回最准确的结果集,从而使你现有的或新的应用程序可搜索。我刚刚讲述了它的要点,你可以继续阅读文档并熟悉这个强大的工具。尤其是模糊搜索功能非常棒。如果我有机会,我会在即将发布的帖子中介绍Query DSL。
-
JAVA
+关注
关注
19文章
2966浏览量
104699 -
引擎
+关注
关注
1文章
361浏览量
22545 -
python
+关注
关注
56文章
4792浏览量
84623
原文标题:在Python中使用Elasticsearch
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
如何在ADS中进行EM仿真
如何在Arduino中进行编程
如何在PADS 3D Layout中进行命令操作

如何在环境安装使用Python操作word
Python 更新 Elasticsearch 的几种方法






 工商网监
工商网监
评论