 人工智能使用的数据集多存在性别歧视和种族主义
人工智能使用的数据集多存在性别歧视和种族主义
编者按:上个月,李飞飞曾推荐斯坦福学者发表在Nature上的一则短文,文章指出现在人工智能使用的数据集多存在性别歧视和种族主义:“医生”是男性,“护士”是女性,维基百科人物词条中只有18%是女性,而这些女性的事迹会被频繁链接到男性事迹中。这个问题的解决办法有两个,一是规范数据集制作,二是开发纳入约束机制的算法。本文介绍的Quicksilver就是其中的第一种方法。
生成示例:Andrej Karpathy
是的,你没看错,作为计算机视觉和深度学习领域的顶级专家之一,特斯拉人工智能与自动驾驶视觉总监,李飞飞高徒,维基百科没有收录Andrej Karpathy本人的词条。
以下是Quicksilver为它编写的词条内容(英语直译):
Andrej Karpathy是特斯拉研究员1,2,人工智能和深度学习领域的专家3,4。
Andrej Karpathy是加利福尼亚州斯坦福大学的计算机科学博士生,研究方向是用于语言建模的自然语言处理(NLP)和循环神经网络(RNN)5。他主要在学术界工作,但去年9月,他作为研究科学家加入了特斯拉的人工智能部门OpenAI6。Karpathy的大部分研究都围绕图像识别和图像理解7。他的Reddit用户名badmephisto,同样也是他的YouTube账号名,来自他致力于解决的问题——魔方7。
事迹
如何实现完美自拍,基于200万张图像的研究——2015年10月30日 这些是Karpathy在研究中挑选出的顶级自拍图像,原图来自网络。斯坦福大学计算机科学毕业生Andrej Karpathy使用来自网络的200万张自拍图像,训练了一个人工神经网络,用来区分哪些是好自拍,哪些是差自拍。他的神经网络包含1.4亿个不同的参数,可以为输入的数百万张图像输出结果。他得出的结论是:自拍的好坏很大程度上取决于图像风格,而不仅仅是人的外貌。10
特斯拉聘请深度学习专家Andrej Karpathy领导Autopilot——2017年6月21日 ……(略)
上任两年后,特斯拉的Autopilot首席执行官辞职——2018年4月26日 ……(略)
引用
A.I. Researchers Leave Elon Musk Lab to Begin Robotics Start-UpNew York Times,2017-11-07
A.I. Researchers Are Making More Than $1 Million, Even at a NonprofitNew York Times,2018-04-19 ……
维基百科的问题
每当我们在Google上搜索著名人物时,维基百科通常是第一个弹出来的页面。现如今,从查找作业资料的学生,到搜集资料的编辑记者,这个免费的数字百科全书已经成为各个年龄段的首选工具。但近期人们却发现,维基百科也出现了令人不安的趋势。
不少人指出,维基百科正显示出性别歧视,简而言之,即很多著名女性人物没有她们的专属页面。以Mirian Adelson为例,她是一名多才多艺的医生,一生发表过上百篇关于生理成瘾和治疗的研究论文,她在拉斯维加斯经营着一家备受瞩目的药物滥用诊所,她也是以色列最大报纸的出版商、著名慈善家。但维基百科并没有收录她的词条(8月4日更新后新增了)。
拥有相同遭遇的还有MIT MechE的部门的新负责人Evelyn Wang,她致力于为沙漠地区居民研究生成饮用水的设备。如果说维基百科在收录女性词条上更苛刻,但它其实对看似被“优待”的男性也不完全友好。研究人员统计了30000名计算机科学家,发现维基百科只收录了其中的15%。
换言之,面对不断更新的信息,维基百科在时效性和完备性上仍面对重大挑战。
事实上,除了以上提及的缺漏现象,维基百科在现有词条维护上也有些力不从心,以华盛顿大学校长Ana Mari Cauce为例。自从特朗普政府宣布启动延迟儿童入境行动(DACA)以来,Cauce多次声明华盛顿大学会继续向移民学生提供各项福利,这在美国产生极大影响,但他的词条内容却迟迟没有更新。
维基百科是学界重要的语料来源之一,但它却展示出非常严重的滞后性和偏见,可想而知,我们不能指望用它来构建合理模型。
Quicksilver如何运作
从自然语言处理角度看,用模型自动生成维基百科风格词条是可能的。对于这类问题,现在采取的普遍方法是多本文摘要:给定一组包含有关实体信息的参考文档,生成实体的摘要。
前人的研究
其实早在十年前,Biadsy等人就已经尝试过生成类似人物介绍,他们提出的算法是对源文本中的相关句子进行排序和剪切,然后再拼凑成最终文本。这样做的优点是语句十分连贯,因为它们都由人类编写。但它的局限也很大,就是机器只能组合人类写过的内容,无法自己创作。
近年来,研究人员开始由上述提取式生成转向抽象概括,这种技术使用神经语言模型来动态生成文本,缺点是模型为了“连贯性”会生成不少无意义内容。对此,斯坦福大学的See等人提出指针生成器网络,它可以为抽象模型提供一个信息提取回退的选项,有机结合了提取式和抽象概括式两种方法。
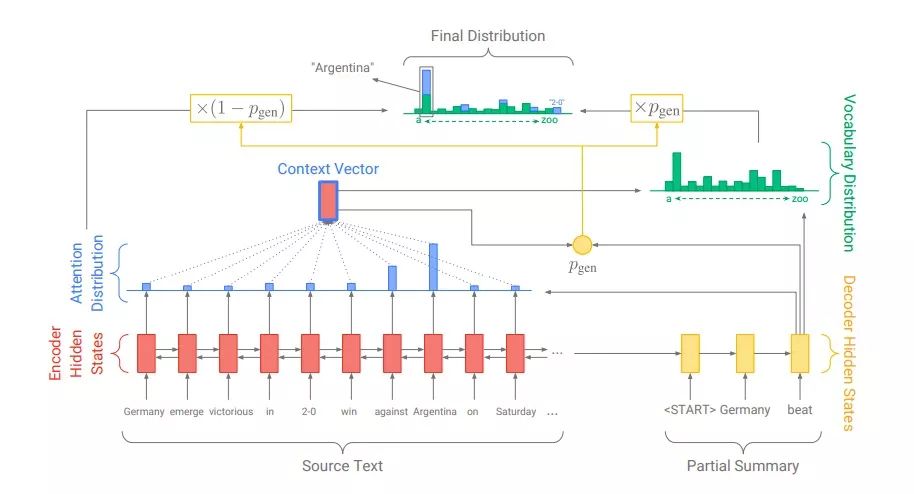
为了避免从源文本中引用重复内容,See等人提出的指针生成器网络可以通过指向复制单词,从固定词汇表生成单词,从而纠正提取式摘要的表述
基于上述研究,今年Google AI的Peter Liu团队在ICLR上展示了一篇论文:Generating WIKIPEDIA by Summarizing Long Sequences。他们先把提取式摘要作为约束输入文本的第一步,再对输出文本进行抽样概括,这样做形成的文本非常惊艳,它们既保留了人类编写的流畅性,也出现了大量模型“自创”的表述。
Quicksilver
Quicksilver是美国创业公司Primer开发的一款软件,它沿用了Google AI的基础架构,但目的更加简单实在,就是开发一个可用于构建和维护维基百科等知识库的系统,而不是将维基百科作为文本摘要算法的学术测试平台。除了生成连贯文本,Quicksilver还需要能追踪数据来源,以便最终输出的任何语句都能指示其引用来源。
简单来看,它的基本思路就是通过交叉引用维基百科词条和从学术搜索引擎(文中称为语义学者)中抽取的作者列表,来检测其中和词条人物有关的信息。提取这些信息并进行组合,最后用只包含一个解码器的抽象概括模块使输出文本更连贯。
为了追求时效性,研究人员基于维基数据,制作了一个和seq2seq模型相结合的知识库。对于了解科学家的生平事迹,使用维基数据的结构数据是一个关键突破,它既做到了映射新闻文档,又可以通过添加远程监督机制,让知识库实现自我更新。
以下是Quicksilver的具体流程:
目前,Quicksilver已经在3万份科学家数据中经过训练,并生成了40000余份维基百科风格的人物简介,其中有多篇已被维基百科收录。它也重点关照了女性词条缺失的现象,在2小时内为70名女科学家更新了她们的词条。
小结
维基百科的受欢迎程度和它对社会造成的影响息息相关,学界呼吁一个更具代表性的数据集,我们也期望一本剔除了不平等思维的百科全书。Quicksilver让我们看到了用机器学习技术纠正偏见思维的可能性,这项研究不仅有助于把代表性不足的科学家群体置于灯光下,它也成了后期ML研究的一个光辉榜样。
Quicksilver背后的算法不难理解,但它的设计依然非常复杂。除了学术上的启示,从工业角度看,这种技术在中文维基百科和国内其他百科的维护上都有用武之地,值得进行尝试。
-
算法
+关注
关注
23文章
4607浏览量
92826 -
人工智能
+关注
关注
1791文章
47183浏览量
238243 -
机器学习
+关注
关注
66文章
8406浏览量
132558
原文标题:告别歧视和偏见,用AI自动生成维基百科词条
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论