 网络语音通话运用了哪些技术?
网络语音通话运用了哪些技术?
当我们使用像Skype、QQ这样的工具和朋友流畅地进行语音视频聊天时,我们可曾想过其背后有哪些强大的技术在支撑?本文将对网络语音通话所使用到的技术做一些简单的介绍,算是管中窥豹吧。
一、概念模型
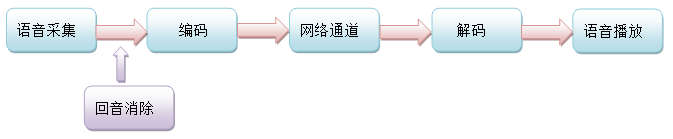
网络语音通话通常是双向的,就模型层面来说,这个双向是对称的。为了简单起见,我们讨论一个方向的通道就可以了。一方说话,另一方则听到声音。看似简单而迅捷,但是其背后的流程却是相当复杂的。我们将其经过的各个主要环节简化成下图所示的概念模型:

这是一个最基础的模型,由五个重要的环节构成:采集、编码、传送、解码、播放。
1. 语音采集
语音采集指的是从麦克风采集音频数据,即声音样本转换成数字信号。其涉及到几个重要的参数:采样频率、采样位数、声道数。
简单的来说:采样频率,就是在1秒内进行采集动作的次数;采样位数,就是每次采集动作得到的数据长度。
而一个音频帧的大小就等于:(采样频率×采样位数×声道数×时间)/8。
通常一个采样帧的时长为10ms,即每10ms的数据构成一个音频帧。假设:采样率16k、采样位数16bit、声道数1,那么一个10ms的音频帧的大小为:(16000*16*1*0.01)/8 = 320 字节。计算式中的0.01为秒,即10ms。
附:可以参考了解语音视频采集组件MCapture相关介绍及Demo源码与SDK下载。
2. 编码
假设我们将采集到的音频帧不经过编码,而直接发送,那么我们可以计算其所需要的带宽要求,仍以上例:320*100 =32KBytes/s,如果换算为bits/s,则为256kb/s。这是个很大的带宽占用。而通过网络流量监控工具,我们可以发现采用类似QQ等IM软件进行语音通话时,流量为3-5KB/s,这比原始流量小了一个数量级。而这主要得益于音频编码技术。
所以,在实际的语音通话应用中,编码这个环节是不可缺少的。目前有很多常用的语音编码技术,像G.729、iLBC、AAC、SPEEX等等。
3. 网络传送
当一个音频帧完成编码后,即可通过网络发送给通话的对方。对于语音对话这样Realtime应用,低延迟和平稳是非常重要的,这就要求我们的网络传送非常顺畅。
4. 解码
当对方接收到编码帧后,会对其进行解码,以恢复成为可供声卡直接播放的数据。
5. 语音播放
完成解码后,即可将得到的音频帧提交给声卡进行播放。
附:可以参考了解语音播放组件MPlayer相关介绍与Demo源码与SDK下载
二、实际应用中的难点及解决方案
如果仅仅依靠上述的技术就能实现一个效果良好的应用于广域网上的语音对话系统,那就没什么太大的必要来撰写此文了。正是有很多现实的因素为上述的概念模型引入了众多挑战,使得网络语音系统的实现不是那么简单,其涉及到很多专业技术。当然,这些挑战大多已经有了成熟的解决方案。首先,我们要为“效果良好”的语音对话系统下个定义,我觉得应该达到如下几点:
低延迟。只有低延迟,才能让通话的双方有很强的Realtime的感觉。当然,这个主要取决于网络的速度和通话双方的物理位置的距离,就单纯软件的角度,优化的可能性很小。
背景噪音小。
声音流畅、没有卡、停顿的感觉。
没有回音。
下面我们就逐个说说实际网络语音对话系统中额外用到的技术。
1. 回音消除 AEC
现在大家几乎都已经都习惯了在语音聊天时,直接用PC或笔记本的声音外放功能。殊不知,这个小小的习惯曾为语音技术提出了多大的挑战。当使用外放功能时,扬声器播放的声音会被麦克风再次采集,传回给对方,这样对方就听到了自己的回音。所以,实际应用中,回音消除的功能是必需的。
在得到采集的音频帧后,在编码之前的这个间隙,是回音消除模块工作的时机。
其原理简单地来说就是,回音消除模块依据刚播放的音频帧,在采集的音频帧中做一些类似抵消的运算,从而将回声从采集帧中清除掉。这个过程是相当复杂的,而且其还与你聊天时所处的房间的大小、以及你在房间中的位置有关,因为这些信息决定了声波反射的时长。 智能的回音消除模块,能动态调整内部参数,以最佳适应当前的环境。
2. 噪声抑制 DENOISE
噪声抑制又称为降噪处理,是根据语音数据的特点,将属于背景噪音的部分识别出来,并从音频帧中过滤掉。有很多编码器都内置了该功能。
3. 抖动缓冲区 JitterBuffer
抖动缓冲区用于解决网络抖动的问题。所谓网络抖动,就是网络延迟一会大一会小,在这种情况下,即使发送方是定时发送数据包的(比如每100ms发送一个包),而接收方的接收就无法同样定时了,有时一个周期内一个包都接收不到,有时一个周期内接收到好几个包。如此,导致接收方听到的声音就是一卡一卡的。
JitterBuffer工作于解码器之后,语音播放之前的环节。即语音解码完成后,将解码帧放入JitterBuffer,声卡的播放回调到来时,从JitterBuffer中取出最老的一帧进行播放。
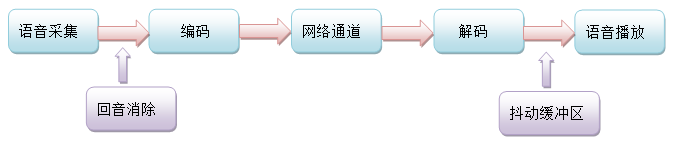
JitterBuffer的缓冲深度取决于网络抖动的程度,网络抖动越大,缓冲深度越大,播放音频的延迟就越大。所以,JitterBuffer是利用了较高的延迟来换取声音的流畅播放的,因为相比声音一卡一卡来说,稍大一点的延迟但更流畅的效果,其主观体验要更好。
当然,JitterBuffer的缓冲深度不是一直不变的,而是根据网络抖动程度的变化而动态调整的。当网络恢复到非常平稳通畅时,缓冲深度会非常小,这样因为JitterBuffer而增加的播放延迟就可以忽略不计了。
在语音对话中,要是当一方没有说话时,就不会产生流量就好了。静音检测就是用于这个目的的。静音检测通常也集成在编码模块中。静音检测算法结合前面的噪声抑制算法,可以识别出当前是否有语音输入,如果没有语音输入,就可以编码输出一个特殊的的编码帧(比如长度为0)。
特别是在多人视频会议中,通常只有一个人在发言,这种情况下,利用静音检测技术而节省带宽还是非常可观的。
5. 混音算法
在多人语音聊天时,我们需要同时播放来自于多个人的语音数据,而声卡播放的缓冲区只有一个,所以,需要将多路语音混合成一路,这就是混音算法要做的事情。即使,你可以想办法绕开混音而让多路声音同时播放,那么对于回音消除的目的而言,也必需混音成一路播放,否则,回音消除最多就只能消除多路声音中的某一路。
混音可以在客户端进行,也可以在服务端进行(可节省下行的带宽)。如果使用了P2P通道,那么混音就只能在客户端进行了。如果是在客户端混音,通常,混音是播放之前的最后一个环节。
综合上面的概念模型以及现实中用到的网络语音技术,下面我们给出一个完整的模型图:
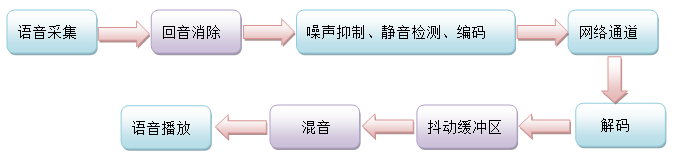
本文是我们在实现OMCS语音部分功能的一个粗略的经验总结。在这里,我们只是对图中各个环节做了一个最简单的说明,而任何一块深入下去,都可以写成一篇长篇论文甚至是一本书。所以,本文就算是为那些刚刚接触网络语音系统开发的人提供一个入门的地图,给出一些线索。
-
Skype
+关注
关注
0文章
27浏览量
13913 -
噪声抑制
+关注
关注
0文章
29浏览量
12174 -
语音通话
+关注
关注
0文章
30浏览量
9417
原文标题:浅谈网络语音技术
文章出处:【微信号:Imgtec,微信公众号:Imagination Tech】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
干货!全面解析几种LTE语音通话技术
基于ZigBee网络的语音应急通信可行性研究
移动视频语音通话/全平台视频监控/视频直播源码出售
移动视频语音通话/全平台视频监控/视频直播源码出售
多方通话中的语音优先技术
启英泰伦通话降噪方案,采用深度学习降噪算法,让通话更清晰
基于VoWLAN终端实现无线VoIP语音通话解决方案
中移动称4G通话比2G清晰 语音通话质量提升2倍
Volte是基于IMS域的纯IP的语音通话技术
VoLTE语音通话究竟是一个什么样的技术





 工商网监
工商网监
评论