 如何基于Keras和Tensorflow用LSTM进行时间序列预测
如何基于Keras和Tensorflow用LSTM进行时间序列预测
编者按:本文将介绍如何基于Keras和Tensorflow,用LSTM进行时间序列预测。文章数据来自股票市场数据集,目标是提供股票价格的动量指标。
GitHub:github.com/jaungiers/LSTM-Neural-Network-for-Time-Series-Prediction
什么是LSTM?
自提出后,传统神经网络架构一直没法解决一些基础问题,比如解释依赖于信息和上下文的输入序列。这些信息可以是句子中的某些单词,我们能用它们预测下一个单词是什么;也可以是序列的时间信息,我们能基于时间元素分析句子的上下文。
简而言之,传统神经网络每次只会采用独立的数据向量,它没有一个类似“记忆”的概念,用来处理和“记忆”有关各种任务。
为了解决这个问题,早期提出的一种方法是在网络中添加循环,得到输出值后,它的输入信息会通过循环被“继承”到输出中,这是它最后看到的输入上下文。这些网络被称为递归神经网络(RNN)。虽然RNN在一定程度上解决了上述问题,但它们还是存在相当大的缺陷,比如在处理长期依赖性问题时容易出现梯度消失。
这里我们不深入探讨RNN的缺陷,我们只需知道,既然RNN这么容易梯度消失,那么它就不适合大多数现实问题。在这个基础上,Hochreiter&Schmidhuber于1997年提出了长期短期记忆网络(LSTM),这是一种特殊的RNN,它能使神经元在其管道中保持上下文记忆,同时又解决了梯度消失问题。具体工作原理可读《一文详解LSTM网络》。
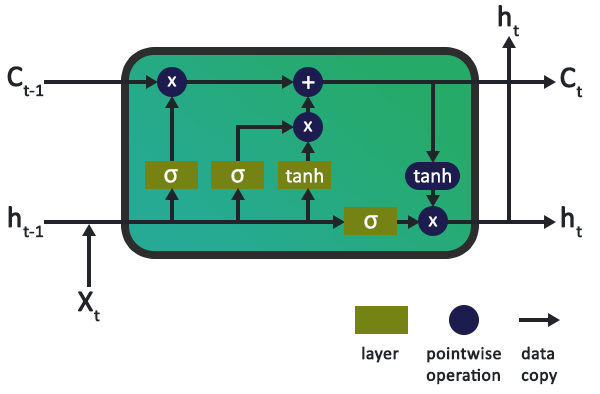
上图是LSTM的一个典型内部示意图,它由若干节点和若干操作组成。其中,操作充当输入门、输出门和遗忘门,为节点状态提供信息。而节点状态负责在网络中记录长期记忆和上下文。
一个简单的正弦曲线示例
为了演示LSTM在预测时间序列中的作用,我们先从最基础的开始:一个时间序列——标准正弦曲线。
代码数据文件夹中提供的数据包含我们创建的sinewave.csv文件,该文件包含5001个正弦曲线时间段,幅度和频率为1(角频率为6.28),时间差为0.01。它的图像如下所示:
正弦曲线数据集
有了数据,接下来就是实现目标。在这个任务中,我们希望LSTM能根据提供的数据学习正弦曲线,并预测此后的N步,持续输出曲线。
为了做到这一点,我们需要先对CSV文件中的数据进行转换,把处理后的数据加载到pandas的数据框架中。之后,它会输出numpy数组,馈送进LSTM。Keras的LSTM一般输入(N, W, F)三维numpy数组,其中N表示训练数据中的序列数,W表示序列长度,F表示每个序列的特征数。
在这个例子中,我们使用的序列长度是50(读取窗口大小),这意味着网络能在每个序列中都观察到完整的正弦曲线形状,便于学习。
序列本身是滑动窗口,因此如果我们每次只移动1,所得图像其实和先前的图像是完全一样的。下面是我们在示例中截取的窗口图像:
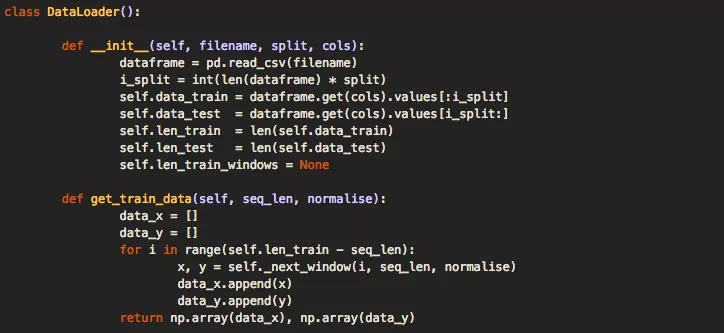
为了加载这些数据,我们在代码中创建了一个DataLoader类。你可能会注意到,在初始化DataLoader对象时,会传入文件名、传入确定用于训练与测试的数据百分比的拆分变量,以及允许选择一列或多列数据的列变量用于单维或多维分析。
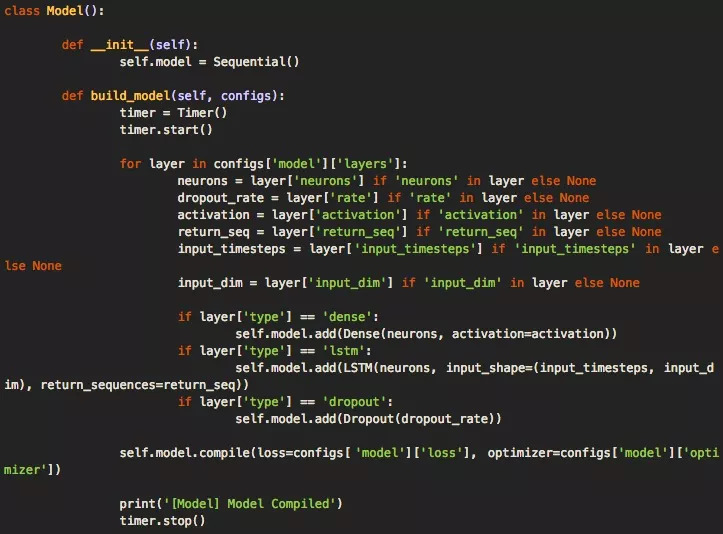
当我们有一个允许加载数据的数据对象之后,就是时候准备构建深层神经网络模型了。我们的代码框架利用模型类型和config.json文件,再加上存储在配置文件中的架构和超参数,可以轻松构建出模型。其中执行构建命令的主要函数是build_model(),它负责接收解析的配置文件。
这个函数的代码如下所示,它可以轻松扩展,以便用于更复杂的架构。
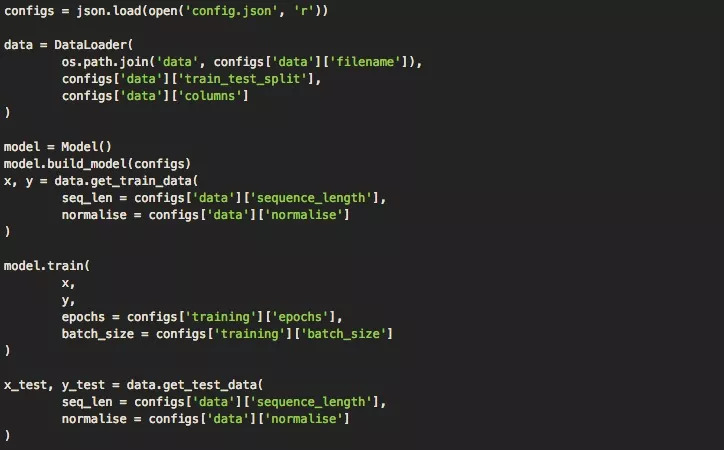
加载数据并建立模型后,现在我们可以用训练数据训练模型。如下代码所示,我们创建了一个单独的运行模块,它会利用我们的模型和DataLoader一起训练,输出预测结果和可视化。
对于输出,我们会进行两种类型的预测:一是逐点预测,即先让模型预测单个点的值,在图中绘出位置,然后移动滑动窗口,用完整的测试数据预测下个点的值。二是预测一个完整序列,即只用训练数据的第一部分初始化一次训练窗口,然后就像逐点预测一样,不断移动滑动窗口并预测下一个点。
和第一种做法不同的是,第二种做法是在用预测所得的数据进行预测,即在第二次预测时,模型所用数据中有一个数据点(最后一个点)来自之前的预测;第三次预测时,数据中就有两个点来自之前的预测……以此类推,到第50次预测时,测试集里的数据已经完全是预测的数据。这意味着模型可预测的时间序列被大大延长。
逐点预测结果
完整序列预测结果
作为参考,你可以在下面的配置文件中看到用于正弦曲线示例的网络架构和超参数。
我们可以从上面两幅图中发现,如果用第二种方法进行预测,随着测试集中被不断加入新的预测数据点,模型的性能会渐渐下降,预测结果和真实结果的误差越来越大。但正弦函数是一个非常简单的零噪声震荡函数,总体来看,我们的模型在没有过拟合的同时还是能很好的模型曲线大致情况的。
接下来,就让我们在股票数据上试试LSTM。
没那么简单的股票市场
很多股民都做过这样一个梦:如果我能准确预测大盘走向,那一夜暴富岂不是手到擒来?但一觉醒来,现实是残酷的,预测这件事并不像数字vwin 那么简单。
和正弦曲线不同,股票市场的时间序列并不是某个特定静态函数的映射,它最明显的属性是随机性。真正的随机是不可预测的,也没有预测的价值,但是,很多人相信股票市场不是一个纯粹的随机市场,它的时间序列可能存在某种隐藏模式。而根据上文的介绍,LSTM无疑是捕捉这种长期依赖关系的一个好方法。
下文使用的数据是Github数据文件夹中的sp500.csv文件。此文件包含2000年1月至2018年9月的标准普尔500股票指数的开盘价、最高价、最低价、收盘价以及每日交易量。
在第一个例子中,正弦曲线的取值范围是-1到1,这和股票市场不同,收盘价是个不断变化的绝对价格,这意味着如果我们不做归一化处理就直接训练模型,它永远不会收敛。
为了解决这个问题,我们设训练/测试的滑动窗口大小为n,对每个窗口进行归一化,以反映从该窗口开始的百分比变化。
n = 价格变化的归一化列表[滑动窗口]
p = 调整后每日利润的原始列表[滑动窗口]
归一化:ni= pi/p0- 1
反归一化:pi= p0( ni+ 1)
处理完数据后,我们就可以和之前一样运行模型。但是,我们做了一个重要的修改:不使用model.train() ,而是用model.traingenerator()。这样做是为了在处理大型数据集时节约内存,前者会把完整数据集全部加载到内存中,然后一个窗口一个窗口归一化,容易内存溢出。此外,我们还调用了Keras的fitgenerator()函数,用python生成器动态训练数据集来绘制数据,进一步降低内存负担。
在之前的例子中,逐点预测的结果比完整序列预测更精确,但这有点欺骗性。在这种情况下,除了预测点和最后一次预测的数据点之间的距离,神经网络其实不需要了解时间序列本身,因为即便它这次预测错误了,在进行下一次预测时,它也只会考虑真实结果,完全无视自己的错误,然后继续产生错误预测。
虽然这听起来不太妙,但其实这种方法还是有用的,它至少能反映下一个点的范围,可用于波动率预测等应用。
逐点预测结果
接着是完整序列预测,在正弦曲线那个例子中,这种方法的偏差虽然越来越大,但它还是保留了整体波动形状。如下图所示,在复杂的股票价格预测中,它连这个优势都没了,除了刚开始橙线略有波动,它预测的整体趋势是一条水平线。
完整序列预测结果
最后,我们对该模型进行了第三种预测,我将其称为多序列预测。这是完整序列预测的混合产物,因为它仍然使用测试数据初始化测试窗口,预测下一个点,然后用下一个点创建一个新窗口。但是,一旦输入窗口完全由过去预测点组成,它就会停止,向前移动一个完整的窗口长度,用真实的测试数据重置窗口,然后再次启动该过程。
实质上,这为测试数据提供了多个趋势线预测,以便我们评估模型对未知数据的预测性能。
多序列预测结果
如上图所示,神经网络似乎正确地预测了绝大多数时间序列的趋势(和趋势幅度),虽然不完美,但它确实表明LSTM在时间序列问题中确实有用武之地。
结论
虽然本文给出了LSTM应用的一个示例,但它只触及时间序列预测问题的表面。现如今,LSTM已成功应用于众多现实问题,从文本自动纠正、异常检测、欺诈检测到自动驾驶汽车技术开发。
它还存在一些局限性,特别是在金融时间序列任务上,通常这类任务很难建模。此外,一些基于注意力机制的神经网络也开始在其他任务上表现出超越LSTM的性能。
但截至目前,LSTM相比传统神经网络还是进步明显,它能够非线性地建模关系并以非线性方式处理具有多个维度的数据,这是几十年前的人们梦寐以求的。
-
神经网络
+关注
关注
42文章
4771浏览量
100708 -
keras
+关注
关注
2文章
20浏览量
6082 -
rnn
+关注
关注
0文章
89浏览量
6886
原文标题:基于LSTM深层神经网络的时间序列预测
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
TensorFlow常用Python扩展包
自回归滞后模型进行多变量时间序列预测案例分享
小波回声状态网络的时间序列预测
Keras和TensorFlow究竟哪个会更好?
TensorFlow和Keras哪个更好用?
如何用Python进行时间序列分解和预测?

融合EMD与LSTM网络的频谱占用度预测模型
基于TensorFlow和Keras的图像识别






 工商网监
工商网监
评论