 使用tf.keras 训练、导出及提供神经网络的整个流程
使用tf.keras 训练、导出及提供神经网络的整个流程
Keras 是一种高级神经网络接口,可以在多个后端上运行。其函数式 API 非常人性化且颇具灵活性,可构建各种应用。一经推出,Keras 便迅速受到青睐。2017 年,Keras API 以 tf.keras 的形式实现与核心 TensorFlow 的集成。虽然 tf.keras 和 Keras 拥有独立代码库,但彼此之间紧密耦合。自 TensorFlow 1.9 起发布更新文档和编程人员指南以来,tf.keras 显然成为以 TensorFlow 构建神经网络时要使用的高级 API。
注:更新文档链接
https://www.tensorflow.org/tutorials/
编程人员指南链接
https://www.tensorflow.org/guide/keras
在这篇文章中,我们会介绍使用 tf.keras训练、导出及提供神经网络的整个流程。例如,我们将使用 Kaggle Planet 数据集训练卷积神经网络,以预测亚马逊森林卫星图像的标签。我们的目的是说明真实用例的端到端管道。相关代码可通过github上的可运行笔记本获取。请注意,您将需要安装最新版本的 TensorFlow(1.11.0,每日构建版),以根据指示完成全部操作。这只是 pip 安装,且 requirements.txt 文件会在存储区中提供。或者,您也可以通过Google Colab立即运行内容!
注:github 链接
https://github.com/sdcubber/keras-training-serving/blob/master/training-and-serving-with-tf-keras.ipynb
Google Colab 链接
https://colab.research.google.com/github/sdcubber/keras-training-serving/blob/master/training-and-serving-with-tf-keras.ipynb
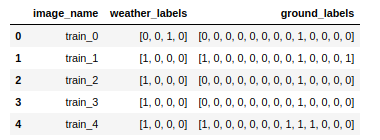
您可在Kaggle下载数据。训练数据由大约 40000 张带标签的亚马逊雨林图像组成,每张图像均与多个标签关联:
注:Kaggle 链接
https://www.kaggle.com/c/planet-understanding-the-amazon-from-space/data
只有一个 “天气” 标签:晴朗、薄雾、多云或局部多云
一个或多个 “地面” 标签:农田、裸地、住宅、道路、水域……
天气标签:多云 地面标签:原始森林,道路
Pandas DataFrame 包含图像名称列、天气标签列和地面标签列,而系统会将这些数据编码为二进制向量。您可前往github以 .csv 文件的形式获取相关内容:
注:github 链接
https://github.com/sdcubber/keras-training-serving/blob/master/KagglePlanetMCML.csv
我们希望训练出的模型能够准确预测新图像的这些标签。为此,我们会尝试使用针对天气和地面标签提供两种独立输出的网络。预测天气标签是多类别分类问题的一个例子,而地面标签可以建模为多标签分类问题。因此,两种输出的损失函数有所不同。训练模型后,我们会使用TensorFlow Serving导出和提供模型,,如此一来,我们就可以通过 HTTP 发送请求以获得图像的预测结果。
指定模型
我们将从头开始构建自己的模型¹。我们会采用十分经典的配置,包括一些卷积层、ReLU 激活函数和两个位于顶层的密集分类器:
1import tensorflow as tf
2IM_SIZE = 128
3
4image_input = tf.keras.Input(shape=(IM_SIZE, IM_SIZE, 3), name='input_layer')
5
6# Some convolutional layers
7conv_1 = tf.keras.layers.Conv2D(32,
8kernel_size=(3, 3),
9padding='same',
10activation='relu')(image_input)
11conv_1 = tf.keras.layers.MaxPooling2D(padding='same')(conv_1)
12conv_2 = tf.keras.layers.Conv2D(32,
13kernel_size=(3, 3),
14padding='same',
15activation='relu')(conv_1)
16conv_2 = tf.keras.layers.MaxPooling2D(padding='same')(conv_2)
17
18# Flatten the output of the convolutional layers
19conv_flat = tf.keras.layers.Flatten()(conv_2)
20
21# Some dense layers with two separate outputs
22fc_1 = tf.keras.layers.Dense(128,
23activation='relu')(conv_flat)
24fc_1 = tf.keras.layers.Dropout(0.2)(fc_1)
25fc_2 = tf.keras.layers.Dense(128,
26activation='relu')(fc_1)
27fc_2 = tf.keras.layers.Dropout(0.2)(fc_2)
28
29# Output layers: separate outputs for the weather and the ground labels
30weather_output = tf.keras.layers.Dense(4,
31activation='softmax',
32name='weather')(fc_2)
33ground_output = tf.keras.layers.Dense(13,
34activation='sigmoid',
35 name='ground')(fc_2)
36
37# Wrap in a Model
38model = tf.keras.Model(inputs=image_input, outputs=[weather_output, ground_output])
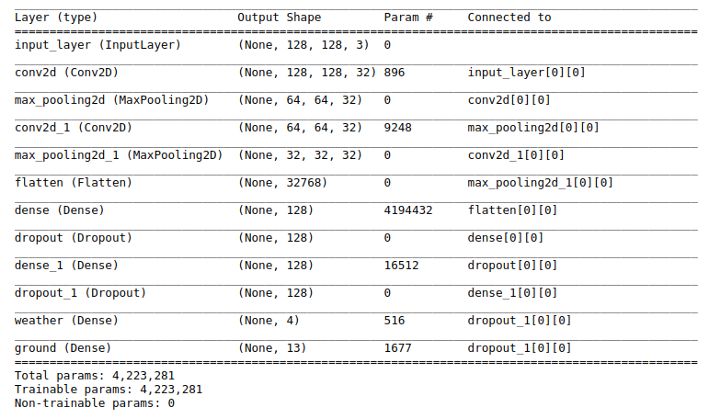
我们有两个输出层,因此在指定模型时应将这些层以输出列表的形式传递。请注意,天气和地面输出层的激活函数并不相同。很方便的是,Model 实现 tf.keras 时会采用简便的 summary() 方法:
编译模型时,系统会以字典的形式提供两个不同的损失函数,而此字典会将张量名称映射到损失:
1model.compile(optimizer='adam',
2loss={'weather': 'categorical_crossentropy',
3'ground': 'binary_crossentropy'})
编译模型时,系统会以随机权重对其进行初始化,并允许我们选择优化算法来训练网络。
[1] 正如在 Kaggle 竞赛中所证明的那样,通过大型预训练网络进行迁移学习是取得成功的一大关键。但这里的重点并不是在 Kaggle 中获胜。如需获取有关如何实现绝佳性能的提示,请观看介绍如何处理此数据集的精彩 fast.ai课程。
注:如何处理此数据集的精彩 fast.ai 链接
http://course.fast.ai/lessons/lesson3.html
模型训练
我们开始训练模型吧!我会在我的笔记本电脑上训练此模型,但这台电脑的内存不够,无法存储整个数据集。处理图像数据时经常会出现这种情况。Keras 提供 model.fit_generator() 方法,而该方法可以使用自定义 Python 生成器从磁盘生成图像以进行训练。不过,从 Keras 2.0.6 开始,我们可以使用 Sequence 对象(而不是生成器)实现安全的多进程处理,这意味着您可以显著提升运行速度并降低 GPU(如果您有)遇到瓶颈的风险。Keras 文档已经提供出色的示例代码,我会稍微自定义一下,以实现下列目的:
让其使用将图像名称映射到标签的 DataFrame
每隔一个周期打乱训练数据
1import ast
2import numpy as np
3import math
4import os
5import random
6from tensorflow.keras.preprocessing.image import
7img_to_array as img_to_array
8
9from tensorflow.keras.preprocessing.image import load_img as load_img
def load_image(image_path, size):
10# data augmentation logic such as random rotations can be added here
11return img_to_array(load_img(image_path, target_size=(size, size))) / 255.
12
13class KagglePlanetSequence(tf.keras.utils.Sequence):
14"""
15Custom Sequence object to train a model on out-of-memory datasets.
16"""
17
18def __init__(self, df_path, data_path, im_size, batch_size, mode='train'):
19"""
20df_path: path to a .csv file that contains columns with image names and labels
21data_path: path that contains the training images
22im_size: image size
23mode: when in training mode, data will be shuffled between epochs
24"""
25self.df = pd.read_csv(df_path)
26self.im_size = im_size
27 self.batch_size = batch_size
28self.mode = mode
29
30# Take labels and a list of image locations in memory
31self.wlabels = self.df['weather_labels'].apply(lambda x: ast.literal_eval(x)).tolist()
32self.glabels = self.df['ground_labels'].apply(lambda x: ast.literal_eval(x)).tolist()
33self.image_list = self.df['image_name'].apply(lambda x: os.path.join(data_path, x + '.jpg')).tolist()
34
35def __len__(self):
36return int(math.ceil(len(self.df) / float(self.batch_size)))
37
38def on_epoch_end(self):
39# Shuffles indexes after each epoch
40self.indexes = range(len(self.image_list))
41if self.mode == 'train':
42self.indexes = random.sample(self.indexes, k=len(self.indexes))
43
44def get_batch_labels(self, idx):
45# Fetch a batch of labels
46return [self.wlabels[idx * self.batch_size: (idx + 1) * self.batch_size],
47self.glabels[idx * self.batch_size: (idx + 1) * self.batch_size]]
48
49def get_batch_features(self, idx):
50# Fetch a batch of images
51batch_images = self.image_list[idx * self.batch_size: (1 + idx) * self.batch_size]
52return np.array([load_image(im, self.im_size) for im in batch_images])
53
54def __getitem__(self, idx):
55batch_x = self.get_batch_features(idx)
56batch_y = self.get_batch_labels(idx)
57return batch_x, batch_y
您可以使用此 Sequence 对象(而不是自定义生成器)和 fit_generator() 来训练模型。请注意,您无需提供每个周期的步骤数量,因为 __len__ 方法会实现生成器的相应逻辑。
1seq = KagglePlanetSequence('./KagglePlanetMCML.csv',
2'./data/train/',
3im_size=IM_SIZE,
4batch_size=32)
此外,tf.keras 让您可以使用所有可用的 Keras 回调,以用于提升训练循环。这些调用非常强大,可提供提前停止、安排学习速率及存储 TensorBoard 文件等选项……在这里,我们将在每个周期结束后使用 ModelCheckPoint 回调来保存模型,如此一来,之后我们便可在有需要时继续训练。默认情况下,系统会存储模型架构、训练配置、优化器状态和权重,以便通过单个文件重新创建整个模型。
我们开始训练模型一个周期:
1callbacks = [
2tf.keras.callbacks.ModelCheckpoint('./model.h5', verbose=1)
3]
4
5model.fit_generator(generator=seq,
6verbose=1,
7epochs=1,
8use_multiprocessing=True,
9workers=4,
10callbacks=callbacks)
Epoch 1/1Epoch 00001: saving model to ./model.h51265/1265 [==============================] - 941s 744ms/step - loss: 0.8686 - weather_loss: 0.6571 - ground_loss: 0.2115
假设我们想在后期阶段微调模型,只需读取模型文件并继续训练,而无需重新编译:
1another_model = tf.keras.models.load_model('./model.h5')
2another_model.fit_generator(generator=seq, verbose=1, epochs=1)
最后,比较好的做法是,实例化 Sequencein 测试模式(即不打乱)并将其用于为整个数据集进行预测,以验证我们的 Sequence 是否有效传递所有数据:
1test_seq = KagglePlanetSequence('./KagglePlanetMCML.csv',
2'./data/train/',
3im_size=IM_SIZE,
4batch_size=32, mode='test')
5predictions = model.predict_generator(generator=test_seq, verbose=1)
6len(predictions[1]) == len(df_train) # This is True!
那么,数据集 API 又是什么呢?
tf.data API 是一个功能强大的内容库,让您可以使用来自各种来源的数据并将其传递给 TensorFlow 模型。我们可以使用 tf.data API 而不是 Sequence 对象来训练 tf.keras 模型吗?可以。首先,我们将图像和标签一起序列化为 TFRecord 文件,这是在 TensorFlow 中序列化数据所推荐生成的格式:
1# Serialize images, together with labels, to TF records
2def _bytes_feature(value):
3returntf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
4
5tf_records_filename = './data/KagglePlanetTFRecord_{}'.format(IM_SIZE)
6writer = tf.python_io.TFRecordWriter(tf_records_filename)
7
8# List of image paths, np array of labels
9im_list = [os.path.join('./data/train', v + '.jpg') for v in df_train['image_name'].tolist()]
10w_labels_arr = np.array([ast.literal_eval(l) for l in df_train['weather_labels']])
11g_labels_arr = np.array([ast.literal_eval(l) for l in df_train['ground_labels']])
12
13# Loop over images and labels, wrap in TF Examples, write away to TFRecord file
14for i in range(len(df_train)):
15w_labels = w_labels_arr[i].astype(np.float32)
16g_labels = g_labels_arr[i].astype(np.float32)
17im = np.array(img_to_array(load_img(im_list[i], target_size=(IM_SIZE, IM_SIZE))) / 255.)
18
19example = tf.train.Example(features=tf.train.Features(feature={'image': _bytes_feature(im.tostring()),
20 'weather_labels': _bytes_feature(w_labels.tostring()),
21 'ground_labels': _bytes_feature(g_labels.tostring())}))
22
23writer.write(example.SerializeToString())
24
25writer.close()
将图像和标签转储到 TFRecord 文件后,我们可以使用 tf.data API 设计另一个生成器。其理念是实例化我们文件中的 TFRecordDataset,并告诉它如何使用 map() 操作来解析序列化数据。
1featdef = {
2 'image': tf.FixedLenFeature(shape=[], dtype=tf.string),
3 'weather_labels': tf.FixedLenFeature(shape=[], dtype=tf.string),
4 'ground_labels': tf.FixedLenFeature(shape=[], dtype=tf.string)
5}
6
7def _parse_record(example_proto, clip=False):
8"""Parse a single record into image, weather labels, ground labels"""
9example = tf.parse_single_example(example_proto, featdef)
10im = tf.decode_raw(example['image'], tf.float32)
11im = tf.reshape(im, (IM_SIZE, IM_SIZE, 3))
12weather = tf.decode_raw(ex['weather_labels'], tf.float32)
13ground = tf.decode_raw(ex['ground_labels'], tf.float32)
14return im, weather, ground
15
16# Construct a TFRecordDataset
17ds_train = tf.data.TFRecordDataset('./data/KagglePlanetTFRecord_{}'.format(IM_SIZE)).map(_parse_record)
18ds_train = ds_train.shuffle(1000).batch(32)
Dataset 对象提供多种方法来生成迭代器对象以循环使用数据。不过,从 TensorFlow 1.9 开始,我们可以直接将 ds_train 传递给 model.fit() 以训练模型:
1model = tf.keras.Model(inputs=image_input, outputs=[weather_output, ground_output])
2
3model.compile(optimizer='adam',
4loss={'weather': 'categorical_crossentropy',
5'ground': 'binary_crossentropy'})
6
7history = model.fit(ds_train,
8 steps_per_epoch=100, # let's take just a couple of steps
9 epochs=1)
Epoch 1/1
100/100 [==============================] - 76s 755ms/step - loss: 0.5460 - weather_loss: 0.3780 - ground_loss: 0.1680
效果不错。这种运作方式让习惯使用 TFRecords 的用户注意到 tf.keras。如果您想使用验证数据,只需通过验证数据实例化另一个 Dataset,再同样传递给 model.fit() 即可。
提供模型
什么是提供模型?我们的目的在于:在客户端生成输入图像。我们希望将此图像包装在某种消息中,然后将其发送到托管我们训练模型的远程服务器,最后从服务器接收预测作为响应。
提供 ML 模型:客户端发送输入请求,服务器从模型中获取预测结果并将其作为响应发回给客户端
首先,我们希望以服务器可以处理的格式导出模型。TensorFlow 提供 SavedModel 格式作为导出模型的通用格式。在后台,我们的 tf.keras 模型完全是根据 TensorFlow 对象来指定,因此我们可以使用 TensorFlow 方法将其导出。
导出模型背后的主要理念是通过签名定义指定推理计算。SignatureDef 完全是根据输入和输出张量来指定,最终会与模型权重存储在一起。不过,TensorFlow 提供了一个便利函数 tf.saved_model.simple_save(),抽离出部分相关细节,并适用于大多数用例:
1import tensorflow as tf
2
3# The export path contains the name and the version of the model
4tf.keras.backend.set_learning_phase(0) # Ignore dropout at inference
5model = tf.keras.models.load_model('./model.h5')
6export_path = './PlanetModel/1'
7
8# Fetch the Keras session and save the model
9# The signature definition is defined by the input and output tensors
10 # And stored with the default serving key
11with tf.keras.backend.get_session() as sess:
12tf.saved_model.simple_save(
13sess,
14export_path,
15inputs={'input_image': model.input},
16outputs={t.name:t for t in model.outputs})
INFO:tensorflow:No assets to save.INFO:tensorflow:No assets to write.INFO:tensorflow:SavedModel written to: ./PlanetModel/1/saved_model.pb
请注意,我已在导出路径中指定版本号。原因在于,TensorFlow Serving 会根据存储目录的名称推断出模型版本。如果我们想出更好的模型,便可将其存储在 PlanetModel/2 下,而 TF Serving 会自动更新以托管新模型。模型图会存储在版本子目录中,而变量则存储在另一个子目录中:
$ tree
.└── 1 ├── saved_model.pb └── variables ├── variables.data-00000-of-00001 └── variables.index
在设置真实服务器之前,我想强调一下 TensorFlow 的 SavedModel 命令行工具,其有助于快速检查我们模型的输入和输出规格:
$ saved_model_cli show --dir ./ --allThe given SavedModel SignatureDef contains the following input(s): inputs['input_image'] tensor_info: dtype: DT_FLOAT shape: (-1, 128, 128, 3) name: input_layer_2:0The given SavedModel SignatureDef contains the following output(s): outputs['ground_2/Sigmoid:0'] tensor_info: dtype: DT_FLOAT shape: (-1, 13) name: ground_2/Sigmoid:0 outputs['weather_2/Softmax:0'] tensor_info: dtype: DT_FLOAT shape: (-1, 4) name: weather_2/Softmax:0Method name is: tensorflow/serving/predict
我们甚至可以访问 CLI 中的 Numpy(即 np),以向模型发送一些随机输入,进而验证模型是否可正常运作:
$ saved_model_cli run --dir ./ --tag_set serve --signature_def serving_default --input_exp 'input_image=np.random.rand(1,128,128,3)'
Result for output key ground_2/Sigmoid:0:[[6.5955728e-01 9.8123280e-03 1.4992488e-02 1.9942504e-06 3.5892407e-07 3.2538961e-04 2.4094069e-02 6.0808718e-01 9.8486900e-01 7.9137814e-01 1.4336356e-05 1.6872218e-05 3.8697788e-01]]Result for output key weather_2/Softmax:0:[[7.1896911e-01 2.9373894e-04 2.5214682e-05 2.8071195e-01]]
看来可以正常运作!
使用 TensorFlow Serving 托管模型服务器
我们会使用TensorFlow Serving内容库来托管模型:
TensorFlow Serving 是一种灵活的高性能服务系统,适用于机器学习模型,并专为生产环境而设计。
Servable是 TensorFlow Serving 的核心抽象概念,并将代表模型。除此之外,TF Serving还提供处理实际服务、加载新版本和卸载旧版本的来源、加载器和管理器。
在本教程中,我们将在本地设置服务器。在生产环境中,您可以在某些微服务架构(例如,在 Kubernetes 集群的 pod 上)中以完全相同的方式设置服务器。
只需一个命令,您便可以在顶层模型目录中托管模型。我截断了一些输出并突出显示 TF Serving 后端的一些组件,如下所示:
$ tensorflow_model_server --model_base_path=$(pwd) --rest_api_port=9000 --model_name=PlanetModelI tensorflow_serving/core/basic_manager] Successfully reserved resources to load servable {name: PlanetModel version: 1}I tensorflow_serving/core/loader_harness.cc] Loading servable version {name: PlanetModel version: 1}I external/org_tensorflow/tensorflow/cc/saved_model/loader.cc] Loading SavedModel with tags: { serve };I external/org_tensorflow/tensorflow/cc/saved_model/loader.cc] SavedModel load for tags { serve }; Status: success. Took 1048518 microseconds.I tensorflow_serving/core/loader_harness.cc] Successfully loaded servable version {name: PlanetModel version: 1}I tensorflow_serving/model_servers/main.cc] Exporting HTTP/REST API at:localhost:9000 ...
在服务器启动并运行时,我们可以向其发出请求。从 TensorFlow Serving 1.8 开始,我们可以通过 gRPC 或 HTTP 调用受托管模型。这两种情况的理念相同:我们希望填充有效负载消息并将其发送给服务器,然后服务器应返回包含预测结果的消息。对于 gRPC,有一些 Python 绑定可用于填充 protobuf 文件格式的消息。如要发送 HTTP 请求,只需使用 Python requests 模块在有效负载 json 中包装我们的输出:
1import requests
2import json
3
4image = img_to_array(load_img('./data/train/train_10001.jpg', target_size=(128,128))) / 255.
5payload = {
6"instances": [{'input_image': image.tolist()}]
7}
8r = requests.post('http://localhost:9000/v1/models/PlanetModel:predict', json=payload)
9json.loads(r.content)
请求网址是根据 TF Serving 文档中所述的一些规则而组成的。发送请求后,服务器会立即返回天气和地面标签的输出列表:
{u'predictions': [ {u'ground_2/Sigmoid:0': [ 0.153237, 0.000527727, 0.00555856, 0.00542973, 0.00105254, 0.000256282, 0.103614, 0.0325185, 0.998204, 0.072204, 0.00745501, 0.00326175, 0.0942268], u'weather_2/Softmax:0': [ 0.963947, 0.000207846, 0.00113924, 0.0347063] }]}
预测:原始森林天气晴朗,但缺少农田和道路的天气状况。请返回训练
总结
tf.keras 让 TensorFlow 用户可以充分利用 Keras 的全部功能和灵活性。tf.keras 使用起来很有趣,其与核心 TensorFlow 的集成绝对使我们向更广泛的受众提供深度学习这一目标向前迈进一大步。事实上,它们像任何其他 TF 模型一样,能够以 SavedModel 格式导出并使用 TensorFlow Serving 提供模型,这使在生产环境中使用 tf.keras 变得简单直观。
-
神经网络
+关注
关注
42文章
4771浏览量
100712 -
图像
+关注
关注
2文章
1083浏览量
40449 -
tensorflow
+关注
关注
13文章
329浏览量
60527
原文标题:使用 tf.keras 训练和提供 ML 模型
文章出处:【微信号:tensorflowers,微信公众号:Tensorflowers】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐






 工商网监
工商网监
评论