 Atari游戏史上最强通关算法来了——Go-Explore!
Atari游戏史上最强通关算法来了——Go-Explore!
Atari游戏史上最强通关算法来了——Go-Explore!蒙特祖玛获分超过200万,平均得分超过40万;Pitfall平均超过21000分!
通关Atari游戏的最强算法来了!
在强化学习中,解决经典Atari游戏《蒙特祖玛的复仇》和《Pitfall》一直是个巨大的挑战。
这些游戏代表了一大类具有挑战性的、现实世界中的问题,这些问题被称为“硬探索问题(hard-exploration problems)”,而智能体必须通过奖励(reward)来学习复杂的任务。
在采用最先进算法的情况下,蒙特祖玛的平均得分为11347分,最高得分为17500分,并在十次尝试中能通过一个关卡。然而令人惊讶的是,尽管进行了大量的研究,到目前为止还没有算法在Pitfall上得到大于0的分数。
而一个新的算法Go-Explore,能够在蒙特祖玛中获得超过200万分,平均得分超过40万分!Go-Explore非常稳定地把整个游戏都通关了,级别甚至能达到159级!
在Pitfall上,Go-Explore的平均分超过了21000分,远远超过了人类的平均成绩,并且在所有学习算法上,首次得到超过0分的成绩。要做到这一点,智能体需要穿过40个房间,摇摆于水上的绳索,跳过鳄鱼、陷阱以及滚动桶等。
总而言之,Go-Explore使得蒙特祖玛和Pitfall在技术水平上都得到了大幅度的提高。它无需涉及“人类的演示”,并且在结果和性能上完败目前最先进的算法。
Go-Explore可以从人工领域知识(domain knowledge)中获益,无需人类先行通关来演示。领域知识是最小的,很容易从像素中获得,突出了Go-Explore利用最小先验知识的能力。而即使没有任何领域知识,Go-Explore在蒙特祖玛中得分也超过了3.5万分,是目前最高水平的三倍多。
Go-Explore与其他深度强化学习算法有很大区别。它可以在许多重要的且具有挑战性的问题上取得突破性进展,尤其是机器人技术。
“稀疏奖励”和“欺骗性”是最具难度的挑战
奖励(reward)较少的问题是比较棘手的,因为随机行动不可能产生奖励,因此无法学习。《蒙特祖玛的复仇》就是一种“稀疏奖励问题(sparse reward problem)”。
更具挑战的是当奖励具有欺骗性时,这意味着在短期内最大化奖励会让智能体在获得更高分数时出错。Pitfall就是具有欺骗性的,因为许多行为会导致较小的负面奖励(比如攻击敌人),因此大多数算法学习到的结果就“不动”。
许多具有挑战性的现实问题也是既稀疏又具有欺骗性。
普通的强化学习算法通常无法从蒙特祖玛的第一个房间(得分400或更低)中跳出,在Pitfall中得分为0或更低。为了解决这类挑战,研究人员在智能体到达新状态(情境或地点)时,会给他们奖励,这种探索通常被称为内在动机(intrinsic motivation,IM)。
尽管IM算法是专门设计用来解决稀疏奖励问题的,但它们在蒙特祖玛和Pitfall表现依旧不佳:在蒙特祖玛中,很少能通过第一关,在Pitfall中就完全是失败的,得分为0。
IM算法分离的例子。绿色区域表示内在奖励,白色区域表示没有内在奖励的区域,紫色区域表示算法目前正在探索的区域。
假设当前IM算法的一个主要缺点是分离,算法会忘记它们访问过的“有奖励”的区域,这意味着它们不会返回这些区域,来查看它们是否会导致新的状态。
比如,两个迷宫之间有一个智能体,首先它会随机地向西开始探索左边的迷宫,由于算法在行为或参数中加入了随机性,智能体可能在探索完左边50%的迷宫的时候,开始探索向东探索右边的迷宫。右边的迷宫探索完之后,智能体可以说已然是“遗忘”了刚才探索左边迷宫的事情了。
而更糟糕的是,左边的迷宫已经有一部分是探索过的,换句话说,智能体在左边迷宫已经“消费”了一定的奖励,当它再回头探索相同的迷宫时,不会再有更多的奖励了,这就严重的影响了学习的效果。
Go-Explore
Go-Explore算法概述
Go-Explore将学习分为两个步骤:探索和强化。
第一阶段:探索,直到解决。Go-Explore构建了一个有趣的不同游戏状态(我们称之为“单元格”)和导致这些状态的轨迹档案,在问题解决之前会一直做如下的重复:
随机选择存档中的单元格;
回到那个单元格;
从该单元格中探索(例如,随机进行n个步骤);
对于所有访问的单元格(包括新的单元格),如果新的轨迹更好(例如更高的分数),则将其作为到达该单元格的轨迹进行交换。
第二阶段:强化。如果找到的解决方案对噪声不够鲁棒(就像Atari轨迹那样),就用vwin 学习算法将它们组合成一个深层神经网络。
单元格表示(Cell representation)
要在像Atari这样的高维状态空间中易于处理,Go-Explore需要一个低维的单元表示来形成它的存档。因此,单元格表示应该合并足够相似而不值得单独研究的状态。重要的是,创建这样的表示并不需要游戏特定的领域知识。最简单的单元格表示方式所得到的结果会非常好,即简单地对当前游戏框架进行下采样。
下采样单元格表示。 完全可观察状态(彩色图像)缩小为具有8个像素强度的11×8灰度图像。
返回单元格(Returning to cells)
根据环境的限制,可以通过三种方式返回单元格(在进行探索之前)。按效率排序:
在可重置环境中,可以简单地将环境状态重置为单元格的状态;
在确定性环境中,可以将轨迹重放到单元格;
在随机环境中,可以训练目标条件策略(goal-conditioned policy),学习返回到单元。
采用稳健的深度神经网络策略的结果
试图从通关蒙特祖玛的复仇第1级的轨迹中产生稳健的策略的努力都取得了成效。平均得分为35410分,是之前最好成绩的11347分的3倍多,略高于人类专家平均水平的34900分!
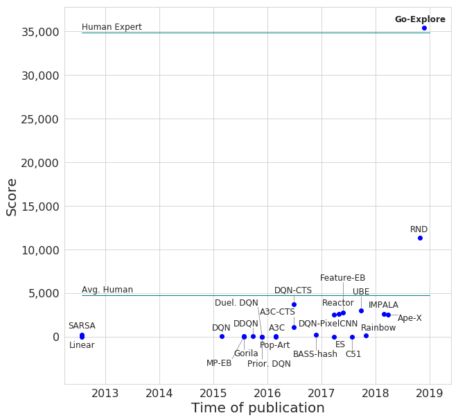
无领域知识的Go-Explore与其他RL算法在蒙特祖玛的复仇中的比较。图中的每一点都代表了蒙特祖玛的复仇上测试的不同算法。
添加领域知识
算法如果能集成易于取得的领域知识,这是一项重要的能力。Go-Explore提供了在cell representation中利用领域知识的机会。我们在蒙特祖玛的复仇中测试了具有领域知识的Go-Explore版本,其中cell被定义为智能体的x-y坐标、当前房间、当前关卡和当前持有的密钥数量的唯一组合。我们编写了一些简单的代码来直接从像素中提取这些信息。
使用这种改进的state representation,Go-Explore在Phase 1找到了238个房间,平均通关了超过9个关卡,并且与缩小的图像单元表示相比,模拟器步骤减少了一半。
Go-Explore在Phase 1发现的房间数量
Robustified的结果
对Go-Explore领域知识版本中发现的轨迹进行Robustifying,可以生成深度神经网络策略,可靠地解决了蒙特祖玛的复仇的前3个关卡。因为在这个游戏中,关卡3之外的所有关卡几乎都是相同的(如上所述),Go-Explore已经解决了整个游戏!
事实上,我们的agent超越了它们的初始轨迹,平均解决了29个关卡,平均得分达到469209分!这打破了针对蒙特祖玛的复仇的传统RL算法和模仿学习算法的最高水平,这两种算法都以人类演示的形式给出解决方案。令人难以置信的是,Go-Explore的一些神经网络得分超过200万,达到159关!为了充分了解这些agent能够做到什么程度,我们不得不增加了OpenAI的Gym允许agent玩游戏的时间。Go-Explore的最高分数远远超过了人类1,219,200分的世界纪录,即使是最严格的“超越人类表现”的定义,它也达到了。
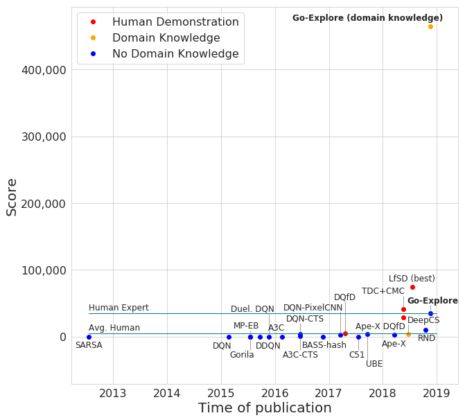
具有领域知识的Go-Explore与其他RL算法在蒙特祖玛的复仇游戏中的比较。红点表示以人类演示的形式给出解决方案的算法。
即使加速了4倍,这个破纪录的运行的完整视频也有53分钟。并且,agent还没有死,只是达到了时间限制(时间已经大大增加)。
Pitfall游戏
Pitfall也需要大量的探索,而且比蒙特祖玛的复仇更难,因为它的奖励更稀疏(只有32个正面的奖励分散在255个房间中),而且许多操作产生的负面奖励很小,这阻碍了RL算法探索环境。到目前为止,我们所知的RL算法还没有在这个游戏中得到哪怕是一个正面的奖励(在没有给出人类演示的情况下)。
相比之下,Go-Explore只需要最少的领域知识(屏幕上的位置和房间号,都可以从像素中获取),就能够到达所有255个房间,收集超过60000点。在没有领域知识(即缩小的像素表示)的情况下,Go-Explore找到了22个房间,但没有找到任何奖励。我们认为缩小的像素表示在Pitfall中表现不佳,因为游戏包含许多具有相同像素表示的不同状态(即游戏中位置不同、但外观相同的房间)。在没有领域知识的情况下区分这些状态可能需要考虑先前状态的状态表示,或者开发其他技术。
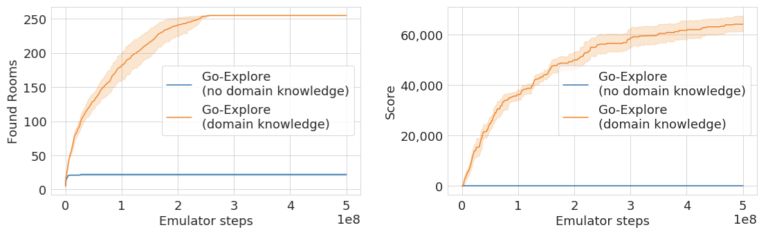
图:Go-Explore在Pitfall游戏的探索阶段找到的房间(左)和获得的奖励(右)
从探索阶段收集的轨迹中,我们能够可靠地对收集超过21,000点的轨迹进行强化,这大大超过了目前最优的水平和人类的平均表现。事实证明,较长的、得分较高的轨迹很难区分,这可能是因为视觉上难以区分的状态可能需要不同的行为。
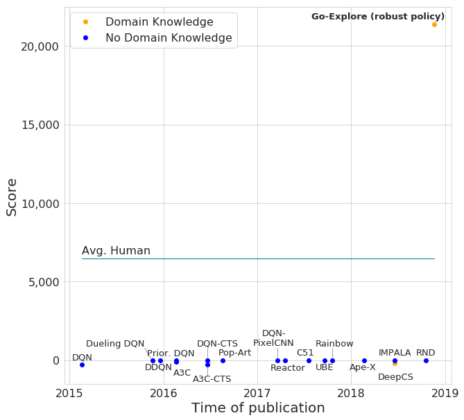
Go-Explore生成的深度神经网络策略与其他RL算法在Pitfall上的比较。
Pitfall游戏中得分超过21000分的AI
三个关键见解
Go-Explore在硬探索问题上的表现非常出色,原因有三个:
1、记住探索过程中好的情况(垫脚石)
2、先回到一个状态,然后探索
3、先解决问题,然后进行强化(如果需要的话)
这些原则在大多数RL算法中都不存在,但是将它们编入其中会很有趣。正如上面所讨论的,当前的RL算法不会做第1点。第2点很重要,因为当前的RL算法通过随机扰动现行策略的参数或行为来探索新领域的环境,但当大幅打破或改变策略时,这种方法是无效的,因为不能在进一步探索之前先返回难以到达的状态。
达到某种状态所需的动作序列越长、越复杂、越精确,这个问题就越严重。Go-Explore解决了这个问题,它首先返回到一个状态,然后从那里开始探索。这样做可以进行深入的探索,从而找到问题的解决方案,然后对问题进行纠正,进而产生可靠的策略(原则3)。
值得注意的是,Go-Explore的当前版本在探索过程中采取完全随机的行动(没有任何神经网络!),甚至在对状态空间进行非常简单的离散化时,它也是有效的。尽管如此简单的探索取得了成功,但它强烈地表明,记住和探索好的垫脚石是有效探索的关键,而且即使是在其他简单的探索中这样做,也比当代deepRL方法更有助于寻找新的状态并表示这些状态。通过将其与有效的、可学习的表示形式结合起来,并将当前的随机探索替换为更智能的探索策略,Go-Explore可能会更加强大。我们正在研究这两种途径。
结论
总的来说,Go-Explore是一个令人兴奋的新算法家族,用于解决难以探索的强化学习问题,即那些具有稀疏和/欺骗性奖励的问题。它开辟了大量新的研究方向,包括不同的cell representations,不同的探索方法,不同的robustification方法,如不同的模仿学习算法等。
我们也很兴奋地看到Go-Explore在哪些领域擅长,在什么时候会失败。它给我们的感觉就像一个充满各种可能性的游乐场,我们希望你能加入我们的行列一起来研究这个领域。
我们将很快提供Go-Explore的源代码和完整论文。
-
智能体
+关注
关注
1文章
144浏览量
10575 -
强化学习
+关注
关注
4文章
266浏览量
11245
原文标题:史上最强Atari游戏通关算法:蒙特祖玛获分超过200万!
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐







 工商网监
工商网监
评论