 伯克利RISELab推出了多主体强化学习包Ray RLlib 0.6.0
伯克利RISELab推出了多主体强化学习包Ray RLlib 0.6.0
近日伯克利RISELab推出了多主体强化学习包Ray RLlib 0.6.0,并同时与伯克利BAIR合作推进多主体强化学习在不同用户场景下的应用,将现有的单主体算法训练拓展到用户个性化算法的大规模训练上。
为什么需要多主体强化学习?
在使用强化学习的过程中,多主体强化学习的想法常常萦绕在研究人员的脑海里。相较于单主体强化学习算法,多主体的方式将带来以下优势:对于问题更自然地解构。例如如果想要训练一个控制移动通信蜂窝天线塔控制算法的策略,逾期使用一个超级智能体来控制城市中所有的天线,倒不如为每个天线建立独立的模型来的自然,以为在移动通信中只有相邻的天线及其附近的用户才与每个站点的控制相关。具有大规模学习的潜力。首先将观测和行动从一个单一的主体解构成多个简单的主体不仅减少了单个智能体输入输出的维数,同时有效增加了在环境中训练每一步所产生的数据量。其次将行动和观测空间按照主体分为多个部分,其效果与时域抽象很类似,这种方法已经成功地加速了单主体条件下的学习效率。并且一些分层方法也可以利用类似多主体系统的方法来实现。最后,良好的解构还可以更好地迁移到变换的环境中,更具有适应性。而单个超级智能体在特定的环境中可能面临过拟合的危险。
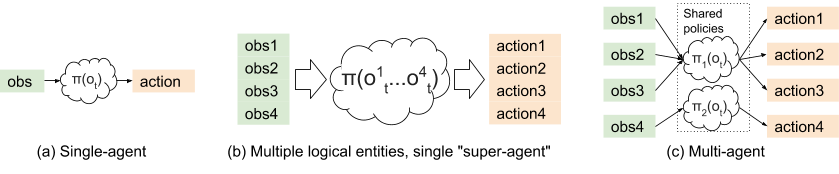
单智能体、超级智能体和多智能体强化学习的区别。
一些多智能体应用场景
在缓解交通拥堵方面,只需要控制极少量自动驾驶车辆的速度,就能大幅度提高交通流的效率。多主体强化学习就可以用于这样的场景,在混合驾驶的情况下我们暂时无法通过单一主体来为交通灯和所有的车辆建模,而利用多主体的方法可以有效的解决大范围内多主体间观测和行动的实时性。下图显示了加入少量红色的无人驾驶车辆,整体通行效率大幅提高。详细报道可以阅读传送门>>无人驾驶与智能算法如何协作处理实际生活中的复杂交通问题?
移动通信中的蜂窝天线控制问题,基站的联合配置可以通过优化局部使用分布和环境形态来得到,这里每一个基站就可以看作是多主体强化学习中的一个,共同覆盖整个城市的通信服务。
在电竞游戏中OpenAI Five的表现令人印象深刻,其中的智能体训练出配合的策略来与人类抗衡。每一个AI主体都有一个独立的神经网络策略并与大规模的PPO(Proximal Policy Optimization)进行联合训练。
支持多主体的强化学习库ray-RLlib
在了解了多主体强化学习的优势的应用场景后,我们就来看看这一新版本的强化学习库具有哪些优势和特点。RLlib兼容多种强化学习分布式算法,包括:A2C / A3C, PPO, IMPALA, DQN, DDPG, 和Ape-XD等等。在接下来的部分中文章将首先探讨多主体强化学习面临的挑战、展示如何通过现有的算法来训练多主体策略,如何在动态和变化增加的多主体环境中实现多特定的算法。这一算法包的目的在于减小研究人员从单主体到多主体强化学习实现过程中的研究成本,加速项目的实施。
支持多主体强化学习的难点
像强化学习这样快速变化的领域构建软件面领着巨大的挑战,多主体强化学习更是如此。下面让我们通过例子来感受一下非静态环境中多主体强化学习面临的难点。下图中红色车辆的学习目标是控制车速,而蓝色车辆的学习目标则是尽可能缩短途中运输的时间。红色的车辆在一开始就简单的初始化为期望的固定速度。然而在多主体的环境下,其他的主体将会不断去优化自己的目标。在这个例子下,蓝色的车就会尝试超越红色的车。在单主体的角度下(红色车)这会引起一系列问题。因为在红色车看来,蓝色车也是环境的一部分。蓝色车超越的行为造成了动态环境的问题,这违背了单主体在Q学习和DQN中需要的马尔科夫假设收敛的条件。
非静态环境,两种主体的学习目标不一致造成了环境的变化。
为了解决这一问题,人们提出了多种算法。包括LOLA,RIAI和Q-MIX。在更高的层次这些算法考虑了在强化学习过程中其他主体造成的影响。通常在训练时使用部分中心化的方式,而执行时使用去中心化的方式。这就意味着策略网络依赖于其他的主体。下面是Q-MIX中一个混合网络的例子:
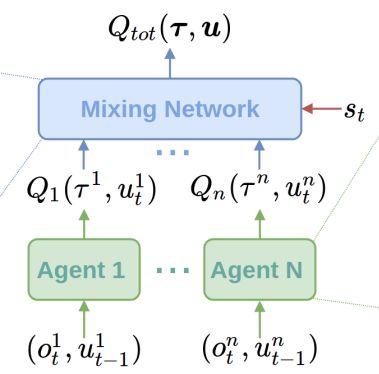
Q-MIX的网络架构,个体的Q估计通过单一的混合网络集成,是的最终的行动计算更有效率。
同样,类似于A3C和PPO这类的策略梯度算法在多主体的情况下会面临很多困难,例如信用分配问题( credit assignment problem)就会随着个体的增加而变得复杂。例如,道路上发生了在很多自动驾驶汽车间交通拥堵,为了避免碰撞,他们会将速度设置为0,那么给主体的奖励与速度的关系将越来越弱,使得拥堵的解决变得困难。
在上图所示的交通拥堵中,我们不清楚哪一辆车造成问题的原因最多,解决拥堵问题我们也不知道那一辆车贡献的最多。对于这些问题,其中一类解决办法就是利用中心化的价值函数(下图中的Q部分)为其他主体造成的影响建模,MA-DDPG,就属于这类方法。通过考虑其他主体的行为,个体的优势估计变换将会变得稳定。
MA-DDPG架构,在执行时策略只用了局域信息、但在训练时充分利用了全局信息。
通过上面的例子可以看到,对于多主体强化学习有两大类不同的挑战和实现方式。有时候利用单主体强化学习算法训练多主体策略可以取得很好的效果。例如OpenAI Five成功地结合了一个大规模的PPO和特定的网络模型,并利用超参数”团队精神”来共享奖励解决多主体训练问题,并利用共享的“主体间最大池化”为模型提供共享的观测信息。
利用RLlib进行多主体训练
为了在多主体的情况下同时考虑特定算法和标准单主体强化学习算法,RLlib使用了两条原则来将这一过程大大简化:策略被表示成了对象:在RLlib中所有基于梯度的算法被视为图对象,其中包含了策略模型、后处理函数以及策略损失等。这一策略图对象充分适应分布式架构对于初始环境、经验收集和改善策略等方面的处理。策略对象是黑箱:为了支持多主体运行,RLlib仅仅需要管理每个环境中多主体策略图的创建和执行即可,并在策略优化时加总损失。策略图对象被视为一个黑箱过程,这意味着它可以使用任意的网络框架来实现,无论是TensorFlow或者pytorch都可以。此外,策略图在使用特定算法时可以共享变量和层而无需而外的架构支持。
多主体环境模型
下面让我们来感受一下这一算法包是如何工作的。在一个多主体的环境中,每一步将会有多个行动产生,下面控制交通流量的例子引入了多个控制量(自动驾驶车和交通灯)来减少高速路上的拥堵。在这一场景中,每个主体行为都表现出不同的时间尺度;环境中主体的行为是一个时间过程。
工具包中的多主体环境可以为多个独立的主体建模,可以为不同的主体分配不同的策略.可以看到交通灯、和不同的自动驾驶汽车使用了不同的策略
利用多主体环境接口,可以得到多个主体在每一步的观测和奖励值:
# Example: using a multi-agent env> env = MultiAgentTrafficEnv(num_cars=20, num_traffic_lights=5)# Observations are a dict mapping agent names to their obs. Not all# agents need to be present in the dict in each time step.> print(env.reset()) { "car_1": [[...]], "car_2": [[...]], "traffic_light_1": [[...]], } # Actions should be provided for each agent that returned an observation.> new_obs, rewards, dones, infos = env.step( actions={"car_1": ..., "car_2": ...})# Similarly, new_obs, rewards, dones, infos, etc. also become dicts> print(rewards) {"car_1": 3, "car_2": -1, "traffic_light_1": 0}# Individual agents can early exit; env is done when "__all__" = True> print(dones) {"car_2": True, "__all__": False}
任何OpenAI gym中的离散的字典、元组或者Box观测空间都可以被用于这些独立的个体上,这使得每个主体多传感器输出成为可能(也包括了主体间的通信过程)在API中包含了多层级的API,从单主体的共享策略到多策略,再到完全用户定制化的策略优化:
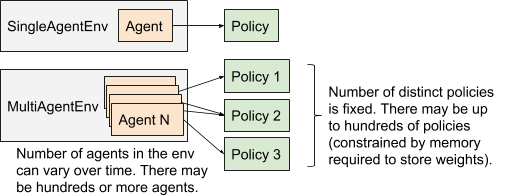
多主体执行模型与单主体执行模型的比较
API分为了三个层次,分别是多主体和共享策略、多主体多策略以及定制化的训练策略。使用这三种不同的策略可以在不同的层次针对不同的场景来训练模型。
性能
RLlib设计的初衷就在于大规模集群多主体的使用,但同时研究人员了为单核机器设计了较好的接口,是的小型电脑也可以有效地执行多主体APIs。下图展示了多主体策略的表现。其中基准是一个小型的浮点数适量,策略网络利用了16*16的小型全连接网络。并未每一个主体分配策略池中的策略。结果表明,RLlib在单CPU上,为单个环境中的1万个主体每秒管理7万次行动,当矢量化关闭时性能下降了近四十倍。
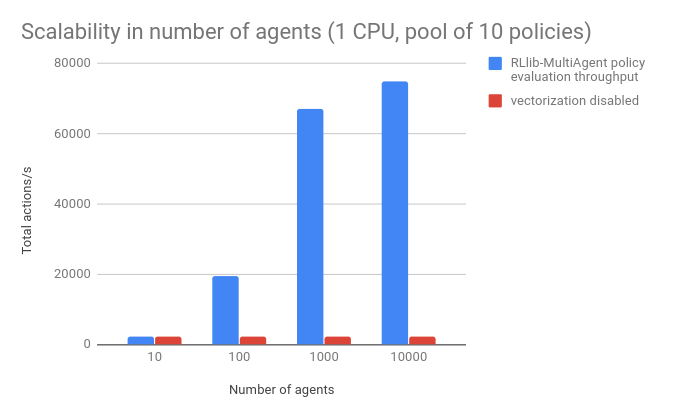
同时也测试了1-50个不同策略数量下的表现:
希望这工具能为强化学习领域的小伙伴们带来一种对于多主体强化学习迅速和通用的解决框架,如果你希望使用这个工具包,只需要使用pip安装即可:pip install ray[rllib]更多详细资料请参看:doc: https://ray.readthedocs.io/en/latest/rllib.htmllab:https://rise.cs.berkeley.edu/blog/scaling-multi-agent-rl-with-rllib/
-
智能体
+关注
关注
1文章
144浏览量
10575 -
强化学习
+关注
关注
4文章
266浏览量
11245
原文标题:伯克利推出大规模多主体强化学习算法库
文章出处:【微信号:thejiangmen,微信公众号:将门创投】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Facebook推出ReAgent AI强化学习工具包

美国劳伦斯伯克利国家实验室开发出“病毒发电”元件
伯克利(Berkeley)联网程序代码介绍
华为投入1百万美元和伯克利合作推进 AI 技术
谷歌和UC伯克利的新式Actor-Critic算法快速在真实世界训练机器人
推特公开宣布了伯克利机器人学习实验室最新开发的机器人BLUE
UC伯克利新机器人成果:灵活自由地使用工具
加州大学伯克利分校研发可以操控的机器人
美国伯克利市考虑2027年出台汽油车禁售令
《自动化学报》—多Agent深度强化学习综述






 工商网监
工商网监
评论