 北大语言计算与机器学习研究组推出一套全新中文分词工具包pkuseg
北大语言计算与机器学习研究组推出一套全新中文分词工具包pkuseg
日前,北京大学语言计算与机器学习研究组研制推出一套全新中文分词工具包 pkuseg,这一工具包有如下三个特点:
高分词准确率。相比于其他的分词工具包,当使用相同的训练数据和测试数据,pkuseg 可以取得更高的分词准确率。
多领域分词。不同于以往的通用中文分词工具,此工具包同时致力于为不同领域的数据提供个性化的预训练模型。根据待分词文本的领域特点,用户可以自由地选择不同的模型。而其他现有分词工具包,一般仅提供通用领域模型。
支持用户自训练模型。支持用户使用全新的标注数据进行训练。
各项性能对比如下:
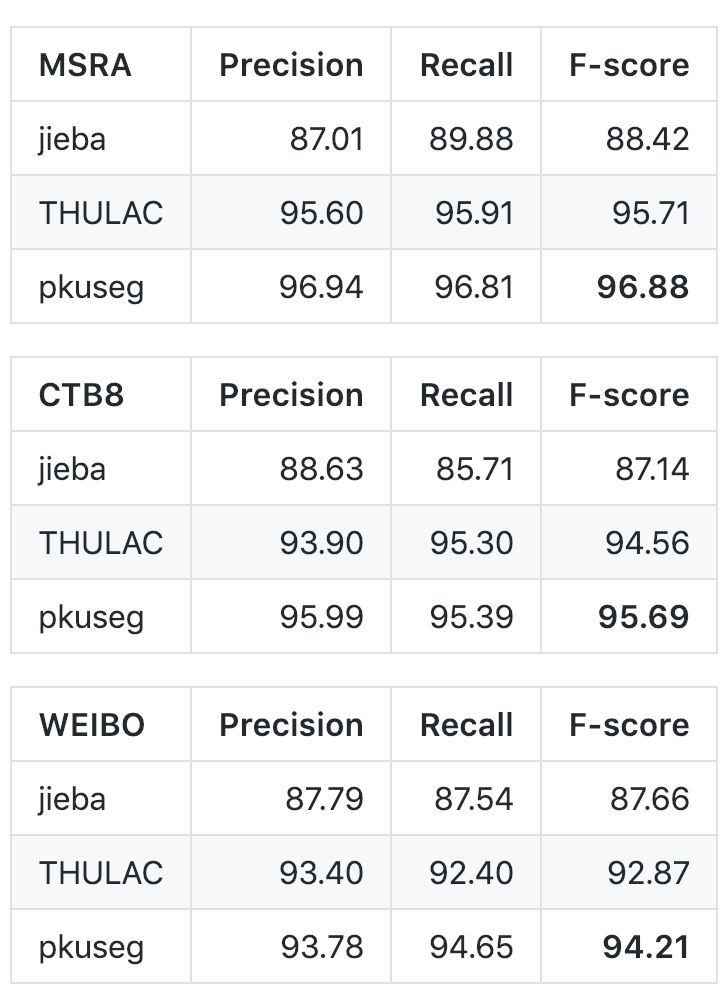
与 jieba、THULAC 等国内代表分词工具包进行性能比较:
考虑到 jieba 分词和 THULAC 工具包等并没有提供细领域的预训练模型,为了便于比较,开发团队重新使用它们提供的训练接口在细领域的数据集上进行训练,用训练得到的模型进行中文分词。他们选择 Linux 作为测试环境,在新闻数据(MSRA)、混合型文本(CTB8)、网络文本(WEIBO)数据上对不同工具包进行了准确率测试。在此过程中,他们使用第二届国际汉语分词评测比赛提供的分词评价脚本,其中 MSRA 与 WEIBO 使用标准训练集测试集划分,CTB8 采用随机划分。对于不同的分词工具包,训练测试数据的划分都是一致的;即所有的分词工具包都在相同的训练集上训练,在相同的测试集上测试。
以下是在不同数据集上的对比结果:
同时,为了比较细领域分词的优势,开发团队比较了他们的方法和通用分词模型的效果对比。其中 jieba 和 THULAC 均使用了软件包提供的、默认的分词模型:
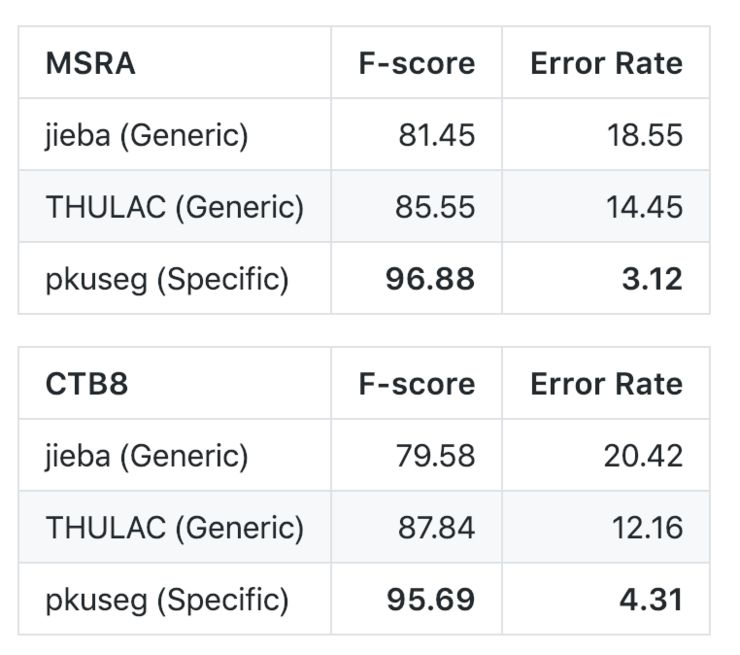
从结果上来看,当用户了解待分词文本的领域时,细领域分词可以取得更好的效果。然而 jieba 和 THULAC 等分词工具包仅提供了通用领域模型。
目前,该工具包已经在 GitHub 开源,编译、安装和使用说明如下。
编译和安装
pip install pkuseg之后通过 import pkuseg 来引用
2. 从 github 下载(需要下载模型文件,见预训练模型)
将 pkuseg 文件放到目录下,通过 import pkuseg 使用模型需要下载或自己训练。
使用方式
1. 代码示例
代码示例1 使用默认模型及默认词典分词import pkusegseg = pkuseg.pkuseg() #以默认配置加载模型text = seg.cut('我爱北京***') #进行分词print(text)
代码示例2 设置用户自定义词典import pkuseglexicon = ['北京大学', '北京***'] #希望分词时用户词典中的词固定不分开seg = pkuseg.pkuseg(user_dict=lexicon) #加载模型,给定用户词典text = seg.cut('我爱北京***') #进行分词print(text)
代码示例3import pkusegseg = pkuseg.pkuseg(model_name='./ctb8') #假设用户已经下载好了ctb8的模型并放在了'./ctb8'目录下,通过设置model_name加载该模型text = seg.cut('我爱北京***') #进行分词print(text)
代码示例4import pkusegpkuseg.test('input.txt', 'output.txt', nthread=20) #对input.txt的文件分词输出到output.txt中,使用默认模型和词典,开20个进程
代码示例5import pkusegpkuseg.train('msr_training.utf8', 'msr_test_gold.utf8', './models', nthread=20) #训练文件为'msr_training.utf8',测试文件为'msr_test_gold.utf8',模型存到'./models'目录下,开20个进程训练模型
2. 参数说明
pkuseg.pkuseg(model_name='ctb8', user_dict=[])model_name 模型路径。默认是'ctb8'表示我们预训练好的模型(仅对pip下载的用户)。用户可以填自己下载或训练的模型所在的路径如model_name='./models'。user_dict 设置用户词典。默认不使用词典。填'safe_lexicon'表示我们提供的一个中文词典(仅pip)。用户可以传入一个包含若干自定义单词的迭代器。
pkuseg.test(readFile, outputFile, model_name='ctb8', user_dict=[], nthread=10)readFile 输入文件路径outputFile 输出文件路径model_name 同pkuseg.pkuseguser_dict 同pkuseg.pkusegnthread 测试时开的进程数
pkuseg.train(trainFile, testFile, savedir, nthread=10)trainFile 训练文件路径testFile 测试文件路径savedir 训练模型的保存路径nthread 训练时开的进程数
预训练模型
分词模式下,用户需要加载预训练好的模型。开发团队提供了三种在不同类型数据上训练得到的模型,根据具体需要,用户可以选择不同的预训练模型。以下是对预训练模型的说明:
MSRA: 在MSRA(新闻语料)上训练的模型。新版本代码采用的是此模型。
下载地址:https://pan.baidu.com/s/1twci0QVBeWXUg06dK47tiA
CTB8: 在CTB8(新闻文本及网络文本的混合型语料)上训练的模型。
下载地址:https://pan.baidu.com/s/1DCjDOxB0HD2NmP9w1jm8MA
WEIBO: 在微博(网络文本语料)上训练的模型。
下载地址:https://pan.baidu.com/s/1QHoK2ahpZnNmX6X7Y9iCgQ
开发团队预训练好其它分词软件的模型可以在如下地址下载:
jieba: 待更新
THULAC: 在 MSRA、CTB8、WEIBO、PKU 语料上的预训练模型,下载地址:https://pan.baidu.com/s/11L95ZZtRJdpMYEHNUtPWXA,提取码:iv82
其中 jieba 的默认模型为统计模型,主要基于训练数据上的词频信息,开发团队在不同训练集上重新统计了词频信息。对于 THULAC,他们使用其提供的接口进行训练(C++版本),得到了在不同领域的预训练模型。
-
机器学习
+关注
关注
66文章
8406浏览量
132553 -
数据集
+关注
关注
4文章
1208浏览量
24688
原文标题:学界 | 北大开源中文分词工具包 pkuseg
文章出处:【微信号:CAAI-1981,微信公众号:中国人工智能学会】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
恩智浦车规级深度学习工具包使新一代汽车应用性能提高30倍
Facebook推出ReAgent AI强化学习工具包
Python人工智能学习工具包+入门与实践资料集锦
中文分词研究难点-词语切分和语言规范
爱特梅尔推出全新的汽车应用开发工具包ATAPMxx
Google Kubernetes机器学习工具包Kubeflow发布0.1版
Python网页爬虫,文本处理,科学计算,机器学习和数据挖掘工具集
北大开源了一个中文分词工具包,名为——PKUSeg
ToolKit是一套应用于嵌入式系统的通用工具包
搭建一套优秀的嵌入式软件框架必备的通用工具包
Microchip 推出 MPLAB® 机器学习开发工具包,助力开发人员轻松将机器学习集成到 MCU 和 MPU中
Microchip(微芯)推出MPLAB机器学习开发工具包






 工商网监
工商网监
评论