 MIT深度学习基础知识 编码器-解码器架构分析
MIT深度学习基础知识 编码器-解码器架构分析
MIT 深度学习课程系列(6.S091、6.S093、6.S094)。讲座视频与教程对所有人开放
作为麻省理工学院(MIT)深度学习讲座系列与GitHub 教程的一部分,我们将介绍使用神经网络解决计算机视觉、自然语言处理、游戏、自动驾驶、机器人等领域内问题的基础知识。
本文以7 种架构范例简要介绍深度学习,每种范例均提供 TensorFlow 教程链接。以下讲座是 MIT 课程 6.S094 的一部分,其中介绍了深度学习基础知识,而本文对其进行了说明。
深度学习是表征学习,即通过数据自动生成有用的表征。我们表述世界的方式可以使复杂事物简单化,让人类及我们构建的机器学习模型能够容易理解。
我最喜欢的历史示例是哥白尼于 1543 年发表的日心说模型。与先前以地球为中心的地心说模型不同,该模型将太阳置于 “宇宙” 的中心。在最佳情况下,深度学习让我们可以自动处理此步骤,无需哥白尼(即人类专家)即可完成 “特征工程” 过程:

日心说(1543 年)与地心说(公元前 6 世纪)
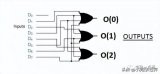
从高层次来看,神经网络可以是编码器、解码器或二者的结合:
-
编码器会在原始数据中找到模式,以生成简洁有用的表征
-
解码器会利用这些表征生成高分辨率数据。所生成的数据是新示例或描述性知识
其余是一些巧妙方法,可帮助我们有效处理视觉信息、语言和音频(范例 1 - 6),甚至可以帮助我们根据这些信息和偶尔的奖励在现实世界中采取行动(范例 7)。以下是总体图示:
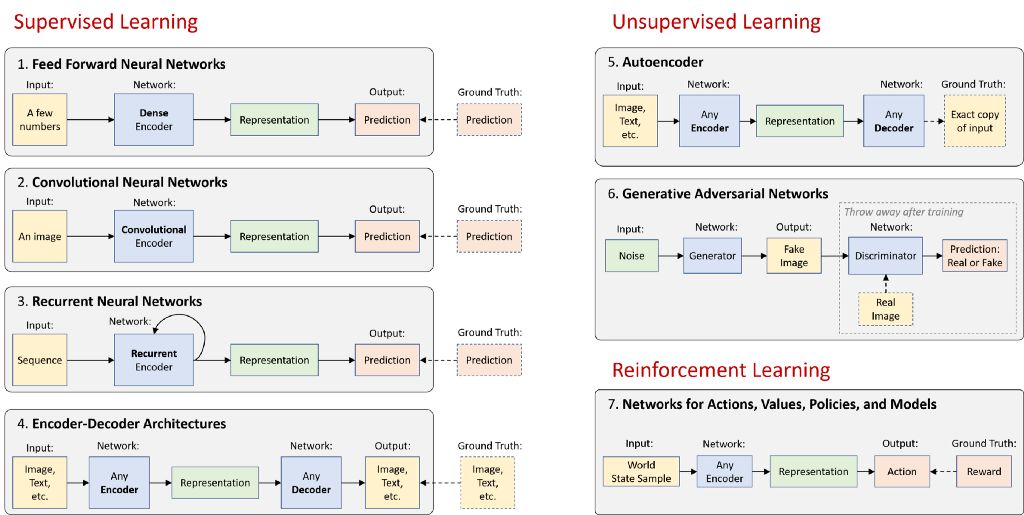
在下面的部分,我将分别简要描述这 7 种架构范例,每种范例均提供 TensorFlow 教程链接,以作说明。请参阅本文结尾的 “基础知识拓展” 部分,其中探讨了一些令人兴奋的深度学习领域,不完全属于这 7 种类别。
1.前馈神经网络 (FFNN)
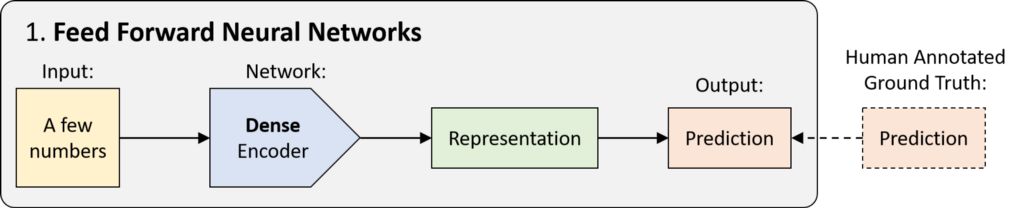
FFNN 的历史可以追溯至 20 世纪 40 年代,只是一种没有任何循环的网络。数据以单次传递的方式从输入传递至输出,而没有任何之前的 “状态记忆”。从技术上讲,深度学习中的大多数网络均可被视为 FFNN,但 “FFNN” 通常指的是其最简单的变体:一种密集连接的多层感知器 (MLP)。
密集编码器用于将输入上已经很紧凑一组数字映射至预测:分类(离散)或回归(连续)数据。
TensorFlow 教程:请参阅 深度学习基础知识教程 的第 1 部分,其中有一个用于预测波士顿房价的 FFNN 示例,属于回归问题:
注:深度学习基础知识教程 链接
https://github.com/lexfridman/mit-deep-learning/blob/master/tutorial_deep_learning_basics/deep_learning_basics.ipynb
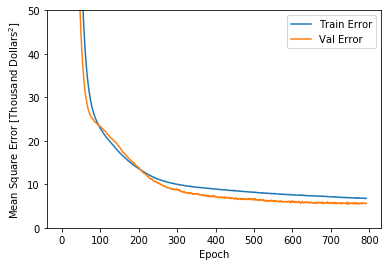
网络学习过程中训练集与验证集中的错误
2.卷积神经网络 (CNN)

CNN(又名 ConvNet)是一种前馈神经网络,其使用空间不变性技巧来有效学习图像中最常见的局部模式。举例而言,若图像左上方与右下方的猫耳拥有相同的特征,我们便可将其称为空间不变性。CNN 可跨空间共享权重,从而更高效地检测出猫耳及其他模式。
CNN 不是只使用密集连接层,而是使用卷积层(卷积编码器)。这些网络可用于图像分类、对象检测、视频动作识别,以及任何在结构上具备一些空间不变性的数据(例如语音音频)。
TensorFlow 教程:请参阅深度学习基础知识教程的第 2 部分,了解用于对 MNIST 数据集中的手写数字进行分类的 CNN 示例。我们利用影像变形技术创造梦幻般的精彩扭曲效果,并通过数据集之外生成的高分辨率手写数字对分类器进行测试:
利用影像变形技术生成手写数字(左侧)并进行分类预测(右侧)
3.递归神经网络 (RNN)

RNN 是具有循环的网络,因此具有 “状态记忆”。这种网络可适时展开,以成为共享权重的前馈网络。正如 CNN 可跨 “空间” 共享权重一样,RNN 可跨 “时间” 共享权重。这使其能够处理并有效表示序列数据中的模式。
我们已开发出 RNN 模块的许多变体(包括LSTM和GRU),以帮助学习较长序列中的模式。其应用包括自然语言建模、语音识别、语音生成等。
TensorFlow 教程:递归神经网络的训练颇具挑战性,但同时也让我们可以对序列数据进行一些有趣而强大的建模。利用 TensorFlow 生成文本是我最喜欢的教程之一,因为只需几行代码便可完成一些事情:逐字生成合理文本:
注:利用 TensorFlow 生成文本 链接
https://www.tensorflow.org/tutorials/sequences/text_generation
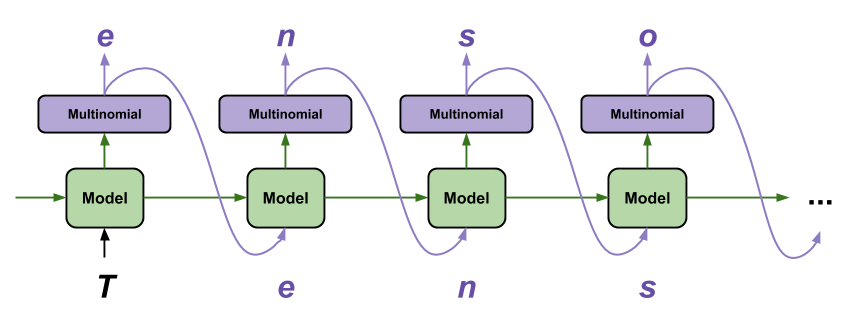
资料来源:利用 TensorFlow 生成文本
4.编码器-解码器架构

前 3 部分介绍的 FFNN、CNN 和 RNN 都只是分别使用密集编码器、卷积编码器或递归编码器进行预测的网络。这些编码器可以组合或切换,具体取决于我们尝试生成有用表征的原始数据类型。“编码器 — 解码器” 架构是一种更高层次的概念,此架构基于编码步骤而构建,通过对压缩表征进行上采样的步骤来生成高维输出,而不是进行预测。
请注意,编码器与解码器彼此之间可能大不相同。例如,图像描述生成 (image captioning) 网络可能采用卷积编码器(用于图像输入)和递归解码器(用于自然语言输出)。其应用包括语义分割、机器翻译等。
TensorFlow 教程:请参阅我们的 驾驶场景分割教程,其中展示了用于处理无人车辆感知问题的最先进分割网络:
注:驾驶场景分割教程 链接
https://github.com/lexfridman/mit-deep-learning/blob/master/tutorial_driving_scene_segmentation/tutorial_driving_scene_segmentation.ipynb
教程:利用 TensorFlow 进行驾驶场景分割
5.自动编码器
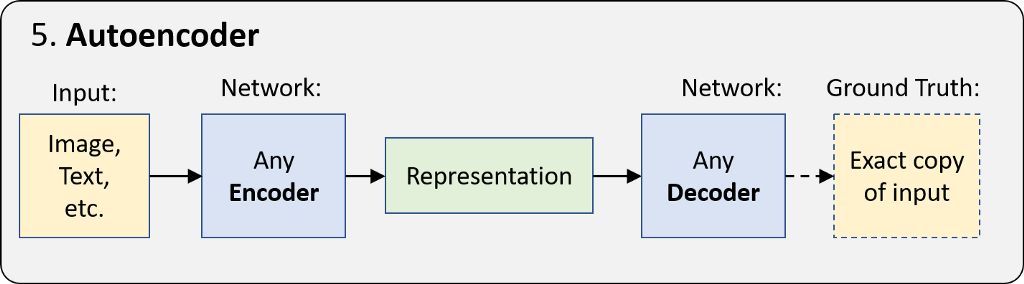
自动编码器是其中一种更简单的 “无监督学习” 形式,其采用编码器 — 解码器架构,并学习生成输入数据的精确副本。由于编码表征比输入数据小得多,此网络被迫学习如何生成最有意义的表征。
其 ground truth 数据来自输入数据,因此无需人工操作。换言之,此网络可自我监督。其应用包括无监督嵌入、图像降噪等。但最重要的是,其 “表征学习” 的基本思想是下个部分的生成模型与所有深度学习的核心。
TensorFlow 教程:在这个TensorFlow Keras 教程中,您可以探索自动编码器在以下两方面的功能:(1) 对输入数据进行降噪,(2) 在 MNIST 数据集中生成嵌入。
注:TensorFlow Keras 教程 链接
https://www.kaggle.com/vikramtiwari/autoencoders-using-tf-keras-mnist
6.生成对抗网络 (GAN)
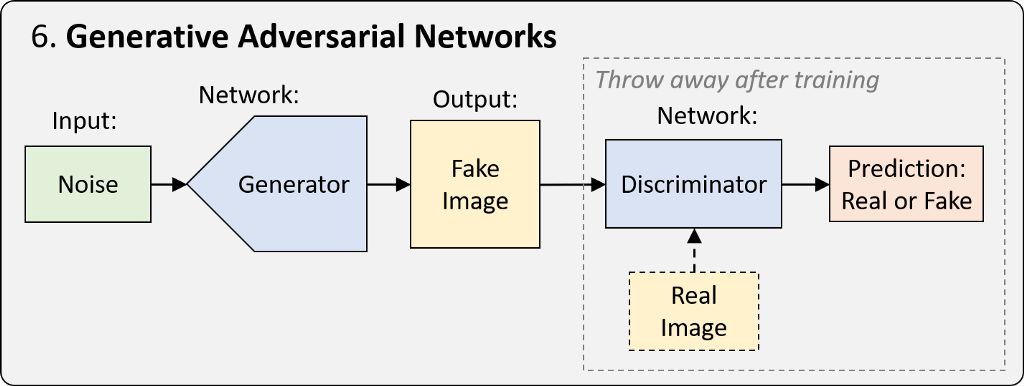
GAN 是一种训练网络框架,已经过优化,可以通过特定表征生成新的真实样本。简单而言,其训练过程涉及两个网络。其中一个网络称为生成器 (generator),它会生成新的数据实例并试图欺骗另一个网络,即判别器 (discriminator),后者会对图像的真伪进行分类。
在过去几年,GAN 出现了许多变体和改进,包括从特定类别生成图像的能力,以及将图像从一个域映射到另一个域的能力,而且所生成图像的真实度也有极大提升。请观看有关 深度学习先进技术的讲座,其中谈及并探讨了 GAN 的快速发展过程。例如,看看 BigGAN 从单个类别(毒蝇伞)中生成的三张样本(arXiv 论文):
注:深度学习先进技术的讲座 链接
https://www.youtube.com/watch?v=53YvP6gdD7UarXiv 论文 链接
https://arxiv.org/abs/1809.11096
BigGAN生成的图像
TensorFlow 教程:如需 GAN 早期变体的示例,请参阅有关条件 GAN和DCGAN的教程。随着课程的进展,我们将在GitHub上发布有关 GAN 先进技术的教程。
注:条件GAN 链接
https://github.com/tensorflow/tensorflow/blob/r1.13/tensorflow/contrib/eager/python/examples/pix2pix/pix2pix_eager.ipynb
DCGAN 链接
https://github.com/tensorflow/tensorflow/blob/r1.11/tensorflow/contrib/eager/python/examples/generative_examples/dcgan.ipynb
7.深度强化学习 (Deep RL)
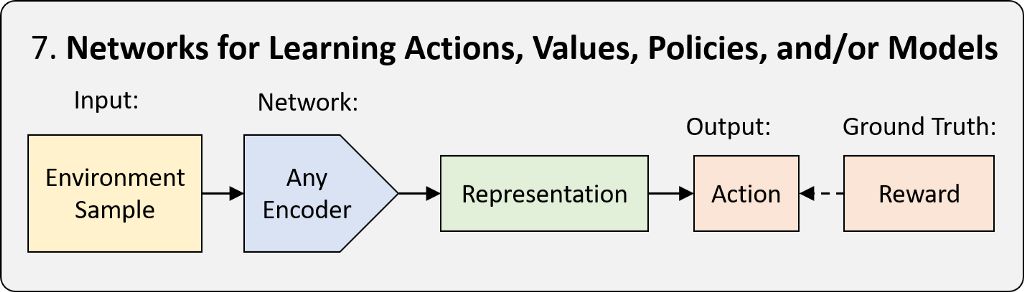
强化学习 (RL) 是一种框架,可以教导智能体如何以使奖励最大化的方式在现实世界中采取行动。我们将由神经网络完成的学习称为深度强化学习 (Deep RL)。RL 框架有三种类型:基于策略、基于值和基于模型。三者的区别在于神经网络需要学习的内容。如需了解更多详情,请观看 MIT 课程 6.S091 的Deep RL 简介讲座。当我们需要作出一系列决策时,可以借助 Deep RL 在vwin 环境或真实环境中应用神经网络。其中包括游戏操作、机器人、神经架构搜索等等。
注:Deep RL 简介讲座 链接
https://www.youtube.com/watch?v=zR11FLZ-O9M&list=PLrAXtmErZgOeiKm4sgNOknGvNjby9efdf
教程:我们的 DeepTraffic 环境提供了 教程 与 代码示例,可以让您快速地在浏览器中探索、训练和评估 Deep RL 智能体。此外,我们很快将在GitHub上发布支持 GPU 训练的 TensorFlow 教程:
注:教程 链接
https://selfdrivingcars.mit.edu/deeptraffic-documentation/
代码示例 链接
https://github.com/lexfridman/deeptraffic
MIT DeepTraffic:深度强化学习竞赛
基础知识拓展
深度学习中有几个重要概念并非由上述架构直接表示。例如,变分自编码器 (VAE)、LSTM/GRU或神经图灵机环境中的 “记忆” 概念、胶囊网络、一般的注意力、迁移学习及元学习理念,以及 RL 中基于模型、基于值和基于策略的方法与 actor-critic 方法的区别。最后,许多深度学习系统以复杂的方式将这些架构结合起来,从而共同从多模态数据中学习,或共同学习解决多个任务。其中很多概念在本课程的其他讲座中均有涉及,我们很快会介绍更多概念。
就个人而言,正如我在评论中所说,我很荣幸能有机会在 MIT 授课,并对加入 AI 和 TensorFlow 社区感到兴奋不已。感谢大家在过去几年的支持与热烈讨论。这是一次绝妙的旅程。如果您对我在未来的讲座中应谈及的主题有任何建议,请在Twitter或LinkedIn上告诉我。
-
MIT
+关注
关注
3文章
253浏览量
23388 -
深度学习
+关注
关注
73文章
5500浏览量
121109 -
tensorflow
+关注
关注
13文章
329浏览量
60527
原文标题:MIT 深度学习基础知识:TensorFlow 简介与概览
文章出处:【微信号:tensorflowers,微信公众号:Tensorflowers】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
怎么理解真正的编码器和解码器?
编码器和解码器的区别是什么,编码器用软件还是硬件好
详解编码器和解码器电路:定义/工作原理/应用/真值表

PyTorch教程-10.6. 编码器-解码器架构

基于transformer的编码器-解码器模型的工作原理
基于 RNN 的解码器架构如何建模
基于 Transformers 的编码器-解码器模型
神经编码器-解码器模型的历史
详解编码器和解码器电路
视频编码器与解码器的应用方案





 工商网监
工商网监
评论