 多智体深度强化学习研究中首次将概率递归推理引入AI的学习过程
多智体深度强化学习研究中首次将概率递归推理引入AI的学习过程
受人类递归推理思维启发,UCL汪军教授组在多智体深度强化学习研究中首次将概率递归推理引入AI的学习过程,让智能体在决策前预测其他智能体的反应对自身的影响。这项工作提升了AI群体思考深度,也为MARL研究提供了全新的思路。
开始之前,先来做个游戏。
假设你跟其他正在看这篇文章的读者一起玩一个游戏,从0到100当中猜出一个数,最后最接近所有人猜的数字平均值的2/3的那个人获胜,那么作为一个个体,你会说几?
这个游戏来自著名的博弈论游戏“猜平均数的三分之二”(guess 2/3 of the average-game),严格来说,人类玩家之间并没有一个必胜的策略。但是,通过不断思考对手可能的决策,这个游戏的众多答案中就会出现一个唯一的纳什均衡,也就是0。
猜平均数的三分之二
0到100的平均值是50, 如果每个个体完全不考虑对手的数字而是随机选择一个数字,那么猜的数字的均值就是50.
这时候有人就可以想了,假设其他人都是无脑瞎猜,那么要获胜,自己就需要多想一步,说出50的三分之二——也就是“50*2/3=33”。
假设其他人都说“33”,又会有人想,要获胜,自己就需要再多想一步,说出33的2/3——“22”。
这个过程不断重复下去,最终,就会得到0。实际上,0也是这个问题的纳什均衡。
但注意,这是在所有人都完全极度理性的情况下,现实生活中,没有人是绝对理性的,所以并不会出现所有人都猜到0的情况,一般群体能收敛到“22-33”之间已经很不错了。
更重要的是,这个游戏充分说明了预测其他人猜的数字对自己将要给出的结果的影响——即使是完全理性的玩家,在这样的游戏中也不应该猜“0”,除非能够确认:1)其他玩家也都是理性的,2)每个玩家都知道其他玩家是理性的。
只要上述两点没有同时成立,也即存在非理性玩家的情况下,要获胜至少应该猜大于0的数字。现实生活中,大多数情况下人类的决策都会有非理性的因素。为了对真实的决策过程更好的建模,那么考虑非理性的因素对于多智能体AI的研究来说就是至关重要了。
1981年,Alain Ledoux在他的法国杂志《游戏与策略》(Jeux et Stratégie)中提出了“猜平均数的三分之二”这个游戏,结果分布如下图。

1981年2898位读者参与“猜平均数2/3”的结果分布,来源:维基百科
这个游戏也可以用来反映群体的“思维深度”,最终数字越小,说明群体的思考层数(回数)越多。
实验心理学领域详细研究了不同职业不同人的思维深度,厉害的国际象棋大师能够预测未来7个来回甚至更远的情况,然后根据预测,返回来决定眼下在哪里落子。事实上,人类作为一个整体平均的思维深度是1.5– 2。
绝大多数的人都会在做事前对自己行为的结果进行某种程度上的预估,具体说,人会先预测自己的行为可能对他人影响,然后再进一步预测受了影响的他人将如何反过来影响自己,这是一个递归的过程。
认知心理学认为,递归推理(recursive reasoning)也即推测他人认为自己在想什么,是人类固有的一种思维模式,在社交生活中对人类行为决策起到重要作用。放在猜数字游戏里,就是“我猜你猜我在想什么”。

人类社交中的递归推理过程。图片来源:Gläscher Lab
UCL首次将递归推理引入多智体深度强化学习
在传统的多智体学习过程当中,有研究者在对其他智能体建模(也即“对手建模”, opponent modeling)时使用了递归推理,但由于算法复杂和计算力所限,目前还尚未有人在多智体深度强化学习(Multi-Agent Deep Reinforcement Learning)的对手建模中使用递归推理。
在被深度学习顶会ICLR 2019高分接收的一篇最新论文中,UCL汪军教授组首次将递归推理的思维模式引入多智体深度强化学习。
具体说,他们提出了一个递归概率推理框架Probabilistic Recursive Reasoning, 简称PR2,让每个智能体在决策时考虑其他智能体将如何回应自己接下来的行动,然后做出最优的决策。
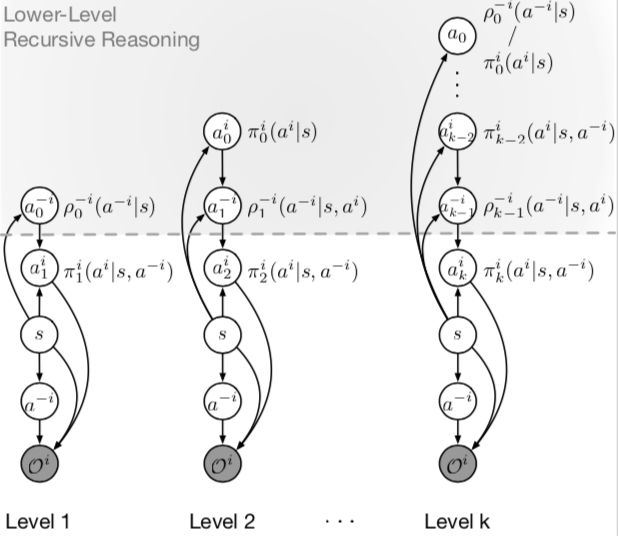
k 阶递归推理图模型。a代表思考深度,隐式的对手建模用函数ρ-i逼近。0阶模型认为对手完全随机。上图灰色区域表示智能体 i 的递归推理思考过程。想得更深一级的智能体返回得出当前轮次的最优结果。每一级计算都包含上一级的计算,比如2阶包含1阶。来源:https://arxiv.org/abs/1901.09216
基于PR2框架,研究人员提出了分别对应连续和离散动作空间的PR2-Q 和 PR2-Actor-Critic算法。有趣的是,这些算法是天生的分布式算法,不需要Centralized Value Function。多次实验结果表明,PR2有效提升了多智体强化学习中单个智能体的学习效率。
“我们在MARL智能体的递归推理中,使用了概率图模型建模,最后得到了一个soft learning的结果,”参与这项工作的UCL计算机学院博士生Yaodong Yang告诉新智元:“巧妙的是,这和单智能体的最大熵强化学习有相通之处。”
研究人员希望这项工作为MARL的对手建模带来一个全新的角度。论文的第一作者、UCL计算机学院的博士生温颖在接受新智元采访时表示:“在PR2的基础上,针对更深层的递归推理,我们设计了一个特殊的trick,能保证训练时每一步更深层的推理都比上一次迭代要好,同时不是无限制地计算下去,那样的话计算资源的消耗太大。”
研究负责人UCL汪军教授说:“ICLR的工作主要是考虑了1阶递归思考,也就是考虑别人会怎么想自己,接下来,我们将继续研究多智体强化学习中AI的递归推理,在ICML 2019的投稿中,我们将其推广到 n 阶递归思考的过程,从而让多智能体AI在更加有效有意义的纳什均衡,相关理论将在机器人、自动驾驶汽车等应用中都有重要意义。”
-
AI
+关注
关注
87文章
30726浏览量
268870 -
智能体
+关注
关注
1文章
144浏览量
10575 -
强化学习
+关注
关注
4文章
266浏览量
11245
原文标题:ICLR19高分论文:为思想“层次”建模,递归推理让AI更聪明
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
什么是深度强化学习?深度强化学习算法应用分析

将深度学习和强化学习相结合的深度强化学习DRL
萨顿科普了强化学习、深度强化学习,并谈到了这项技术的潜力和发展方向
DeepMind发布强化学习库RLax
机器学习中的无模型强化学习算法及研究综述

模型化深度强化学习应用研究综述

基于深度强化学习的路口单交叉信号控制
基于深度强化学习仿真集成的压边力控制模型
《自动化学报》—多Agent深度强化学习综述

语言模型做先验,统一强化学习智能体,DeepMind选择走这条通用AI之路






 工商网监
工商网监
评论