 混合精度训练的优势!将自动混合精度用于主流深度学习框架
混合精度训练的优势!将自动混合精度用于主流深度学习框架
传统上,深度神经网络训练采用的是IEEE单精度格式,但借助混合精度,可采用半精度进行训练,同时保持单精度的网络精度。这种同时采用单精度和半精度表示的技术被称为混合精度技术。
混合精度训练的优势
通过使用Tensor核心,可加速数学密集型运算,如线性和卷积层。
与单精度相比,通过访问一半的字节来加速内存受限的运算。
降低训练模型的内存要求,支持更大规模的模型或更大规模的批量训练。
启用混合精度包括两个步骤:移植模型,以适时使用半精度数据类型;以及使用损耗定标,以保留小梯度值。
仅通过添加几行代码,TensorFlow、PyTorch和MXNet中的自动混合精确功能就能助力深度学习研究人员和工程师基于NVIDIA Volta和Turing GPU实现高达3倍的AI训练加速。
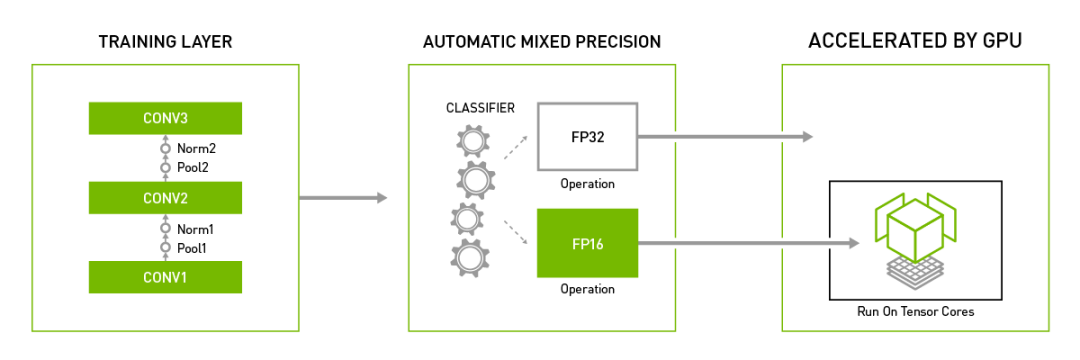
将自动混合精度用于主流深度学习框架
TensorFlow
NVIDIA NGC容器注册表中TensorFlow容器可提供自动混合精度功能。要在容器内启用此功能,只需设置一个环境变量:
export TF_ENABLE_AUTO_MIXED_PRECISION=1
或者,您也可以在TensorFlow Python脚本中设置环境变量:
os.environ['TF_ENABLE_AUTO_MIXED_PRECISION'] = '1'
自动混合精度使用单一环境变量,在TensorFlow内部应用这两个步骤,并在必要时进行更细粒度的控制。
PyTorch
GitHub的Apex存储库中提供了自动混合精度功能。可将以下两行代码添加至当前训练脚本中以启用该功能:
model, optimizer = amp.initialize(model, optimizer)
with amp.scale_loss(loss, optimizer) as scaled_loss:scaled_loss.backward()
MXNet
我们正在构建适用于MXNet的自动混合精度功能。您可通过GitHub了解我们的工作进展。可将以下代码行添加至当前训练脚本中以启用该功能:
amp.init()amp.init_trainer(trainer)with amp.scale_loss(loss, trainer) as scaled_loss:autograd.backward(scaled_loss)
-
神经网络
+关注
关注
42文章
4771浏览量
100713 -
gpu
+关注
关注
28文章
4729浏览量
128890 -
深度学习
+关注
关注
73文章
5500浏览量
121111
原文标题:Tensor核心系列课 | 探究适用于深度学习的自动混合精度
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
国际巨头重金投入,国产深度学习框架OneFlow有何优势?
混合系统的优势所在
Nanopi深度学习之路(1)深度学习框架分析
PyTorch 1.6即将原生支持自动混合精度训练
浅谈字节跳动开源8比特混合精度Transformer引擎
视觉深度学习迁移学习训练框架Torchvision介绍






 工商网监
工商网监
评论