 数据挖掘的功能
数据挖掘的功能
数据挖掘的功能
1、数据分类
数据分类为数据挖掘中常见的功能之一,顾名思义即是将分析对象依不同的属性分类加以定义,建立不同的类组。数据挖掘中的分类是指针对未发生的结果进行预测分类,主要包括归纳和推论两步骤,其主要目的在于提高分类的准确度,建立分类规则,再评估准则的优劣。常用“判定树”算法。
2、数据估计
根据不同相关属性数据的连续性数值,找出各属性间的关联性,以了解并获得某一特定属性未知的连续性数值,常用“回归分析”及“类神经网络算法”。
3、数据预测
预测工作的目的在于以其他属性的值为基础来预测特定属性的值。而这个被预测属性的值通常称为目标变量或是因变量;而其他属性则称为解释变量或自变量,预测的主要方法在于建立数据当中因变量与自变量间的关系。常用“回归分析”“时间序列分析”及“类神经网络”算法。
4、数据关联分组
数据关联分组主要用来发现数据中特征属性间具有高度关联性的一种模式,其所发现的模式通常是用规则来表现。常用“关联规则(又称购物蓝分析)”算法。
5、数据聚类
数据聚类主要是利用数据中类似或相同的项目,将同构型较高的数据区隔为不同的聚类,聚类内数据相似度越高越好,聚类间差异度越大越好。在一大群的研究对象中,根据不同的研究目的必定会有异质化的现象,但异质化的现象可能是几个同质化的群组所造成,数据聚类的主要目的便是将不同的同质化的组别差异找出来,常用“判别分析”与聚类分析“算法。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表德赢Vwin官网 网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
- 数据挖掘
+关注
关注
1文章
406浏览量
24135
发布评论请先登录
相关推荐
中科曙光受邀参加第十届中国数据挖掘会议
近日,国内
数据
挖掘领域最主要的学术活动之一—第十届中国
数据
挖掘会议(CCDM2024)于山东泰安举行,中科曙光参与并分享了曙光AI构建产学研用的生态实践。
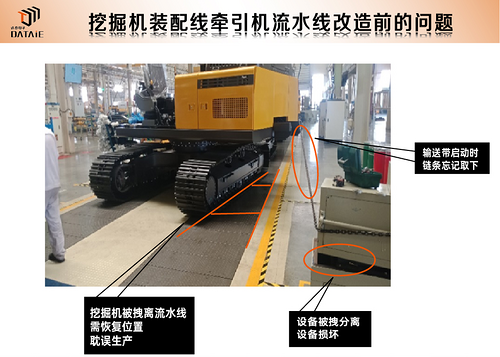
挖掘机生产装配线无线通讯应用
一、应用背景 山东某
挖掘机机械有限公司主要产品有装载机、
挖掘机、道路机械及核心关键零部件等系列工程机械产品。为加速新旧动能转换,全新
挖掘机整机装配线配合劳动组合的调整,提高装配水平和生产效率;可集中
数据挖掘的应用领域,并举例说明
数据
挖掘(Data Mining)是一种从大量
数据中提取出有意义的信息和模式的技术。它结合了
数据库、统计学、机器学习和人工智能等领域的理论和方法,通过高效的算法和工具,对大
Volteq推出电动遥控迷你挖掘机Sky 1000
Sky 1000 不仅支持常规的直立操作模式,同时也支持远程遥控,用户仅需手持遥控器,即可从最远处约 48.8 米处轻松操控
挖掘机。此举让操作者拥有更广阔的观察视角,降低安全风险。针对可能出现的突发事件,遥控器及
挖掘机本机均配置了紧急停止按钮。
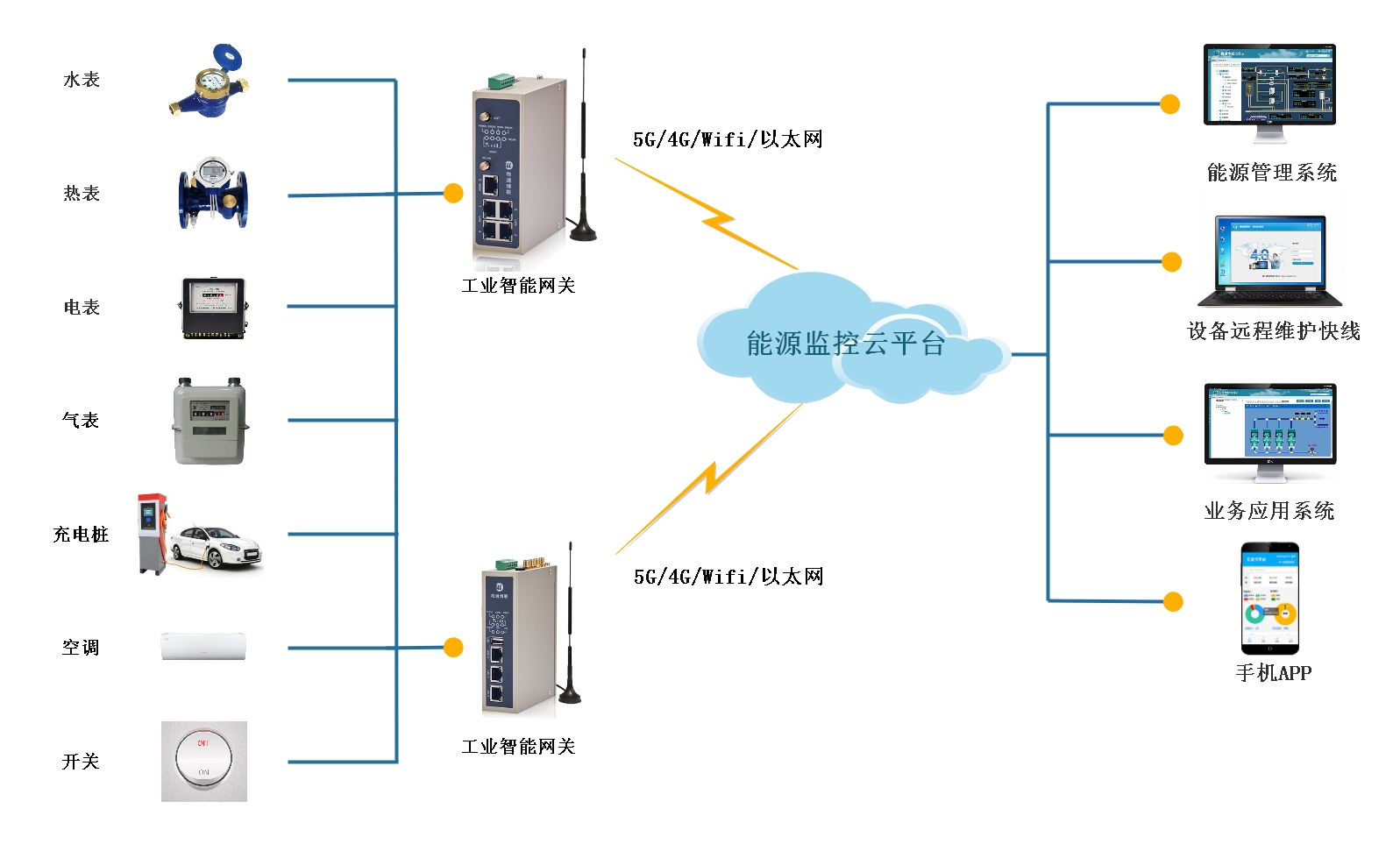
如何通过能源数据管理挖掘智慧楼宇的节能空间
性能的同时优化能耗,对此我们需要了解建筑内各种能源的使用结构、使用时间等信息。对此,物通博联提供智慧楼宇的能源
数据管理系统,实现楼宇内各种能源的
数据采集与可视化监控,并建立能源全面
数据视图,帮助确定可以
数据挖掘示波器与传统示波器的区别在哪里?
数据采集方式:传统示波器通过将模拟信号转换为数字信号进行采集和显示。而
数据
挖掘示波器主要用于数字信号的采集和分析,例如从数字通信系统、传感器网络等获取的数字信号进行处理和分析。


系统逻辑漏洞挖掘实践
当谈及安全测试时,逻辑漏洞
挖掘一直是一个备受关注的话题,它与传统的安全漏洞(如SQL注入、XSS、CSRF)不同,无法通过WAF、杀软等安全系统的简单扫描来检测和解决。这类漏洞往往涉及到权限控制和校验方面的设计问题,通常在系统开发阶段未充分考虑相关
功能的安全性。

关于数据挖掘的十种算法原理讲解
数据
挖掘主要分为三类:分类算法、聚类算法和相关规则,基本涵盖了当前商业市场对算法的所有需求。这三类包含了许多经典算法。市面上很多关于
数据
挖掘算法的介绍都是深奥难懂的。今天我就用我的理解
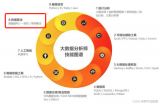
一文弄懂数据挖掘的十大算法,数据挖掘算法原理讲解
数据
挖掘主要分为三类:分类算法、聚类算法和相关规则,基本涵盖了当前商业市场对算法的所有需求。这三类包含了许多经典算法。市面上很多关于
数据
挖掘算法的介绍都是深奥难懂的。今天我就用我的理解
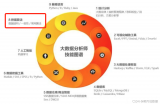
缆索挖掘机维护—小传感器,大作用!
应用背景缆索
挖掘机缆索
挖掘机的特点是具有坚固的部件,如上部结构、回转环和底盘。底盘是用于移动
挖掘机的下部机械部件,根据尺寸和型号的不同,由轮子或履带引导,并承载可转动的上部车厢。回转环连接上部和下部






 工商网监
工商网监
评论