 什么是智能内容生成?万字讲述智能内容生成实践
什么是智能内容生成?万字讲述智能内容生成实践
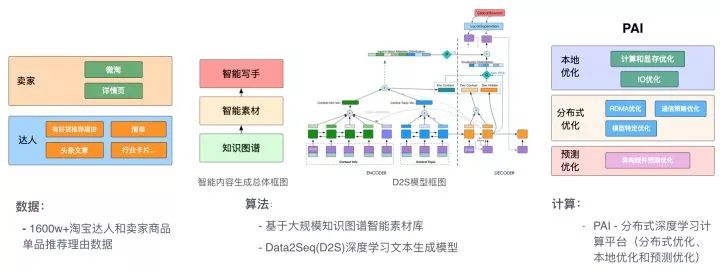
本文主要介绍阿里巴巴-搜索事业部算法团队上半年在智能内容生成方向工作的一些实践和思考。本文最早2017年10月初在集团内部发表,并获得双十一征文 "一骑绝尘" 奖,对外最早发表在阿里云云栖社区。
believe it or not,上图中的文本内容就是智能内容生成的数据,并非人工筛选的结果,线上大量投放。接下来本文介绍下这些商品内容究竟是怎么生成出来的:
一、项目背景
1.1 什么是智能内容生成?更准确的定义应该是智能文本内容生成,指的是训练机器模型,智能生成单品推荐理由、多商品清单文章一类的文本型内容,显然,与智能内容生成相对的概念是达人内容生成。学界相关的技术领域为 NLG (Nature Language Generation),我们在项目内部定义为Data2Seq(D2S),即根据结构化数据(Data)生成文本(Seq)。1.2 为什么要做智能内容生成项目?首先,内容化本身有着重要的业务价值。从手淘业务层面考虑,在移动互联网时代的格局已定的大环境下,各个领域的APP都开始从粗放争夺用户量转向精细化争夺用户时间,内容类公司也是愈发火热。手淘从去年起开始逐渐进行内容化定位,用社区化、内容化去争取用户停留时间。从手淘首页的变化不难管中窥豹,各种各样的内容化场景层出不穷。因此搜索场景在这样的大背景下自然不再只是承载成交转化效率,内容化在搜索有很多场景可以落地且具备巨大业务价值。
其次,目前手淘下各个场景的内容化还是主要依赖达人内容生成,达人内容生成天然存在覆盖商品量少、成本高的问题。
最后,从技术可行性角度考虑,近几年深度学习的浪潮强劲,在图像、语音、自然语言、信息检索等很多领域都取得了突破,内部看搜索算法团队在前沿技术深度积累更多用于搜索场景效率提升,有必要向更general更广阔的场景转移,用技术驱动业务创新。更为重要的是,时至今日,淘宝平台已经积累了千万级的达人训练数据,具备了很强的可行性。而从团队角度出发,我们在过去的工作中积累了一套完善的知识图谱数据、商品理解能力和NLP领域的深度学习相关知识储备,有能力提供系统化的文本内容生成解决方案。1.3 智能内容生成相对达人内容生成的优势是什么?劣势又是什么?智能内容生成除了批量化生成内容和低成本外,在电商三要素"人""货""场"角度都有明显的优势:
货:机器对商品有更深的理解,生成的内容可以有远超达人的信息量。这也是我们最大的point所在,“机器的优势不在于可以说一段类似达人流畅的话,更在于说出达人说不出的干货”。达人对商品了解的信息量实际很有限,而我们拥有淘宝的海量静态和行为数据,可以全面、精准和即时的感知商品信息和流行趋势变化,真正的数据生成文本。
人:机器可以做到个性化的内容生成。从对用户理解出发,我们有非常精细的UserProfile,知道用户的喜欢哪些卖点,个性化内容推送的基础是有个性化的内容生成,达人一般最多做到“场”粒度,显然极难做到个性化粒度。
场:不同场景下,机器可以灵活的定制生成内容的样式风格和所依赖的底层商品池。
机器的劣质其实也很明显,尽管深度学习技术对智能内容生成的发展有了很大的推动,但其本质还是没有脱离从海量数据中统计学习的思路,无法从小样本学习,并且学习的空间其实是相对世界的一个非常小的子集,也基本无法做到像达人一样旁征博引,可以生成更有创造力的文案。
1.4 项目目标是什么?其实写出一段流畅的类似达人的内容文本并非难事,甚至简单的N-Gram模型中也能挑出一些有意思的话,更大的考验在于如果在工业界的线上场景稳定上线,需要很高的准确率和一套完善的质量提升方案。项目目标是能够delivery一套智能内容生成的高质量、系统化的解决方案,在搜索场景和搜索外场景拓展应用,并为未来更好的发展内容生成技术打好基础。
二、NLG问题综述
智能内容生成在学界相关领域为NLG,NLG任务的目标是根据输入数据生成自然语言文本,在NLP领域我们接触更多的是NLU(Nature Language Understanding,如命名实体识别、文本分类等)类任务,NLU的目标则将自然文本转化成结构化数据,显然,NLG和NLU是一对相反的过程。
NLG本身其实是一个很宽泛的概念,如下图所示,广义上来讲只要输出端是自然语言文本的很多任务都属于这个范畴,除了结构化数据到文本的Data2Text任务,比如机器翻译、文本摘要等Text2Text类任务,ImageCaptioning等Image2Text类的任务都是NLG。在学界有关NLG最权威的定义是“根据非文本型的信息生成的自然文本的过程”(Reiter & Dale, 1997, 2000),是狭义上讲的NLG,特指Data2Text(完全等同于Data2Seq),即输入端为Data(结构化数据)输出端为Seq(自然语言文本)。比如根据温度、风向等测量数据生成天气预报文本是Data2Seq的一个经典范例。
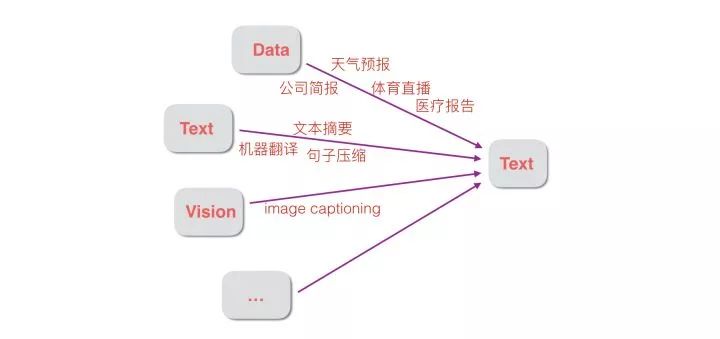
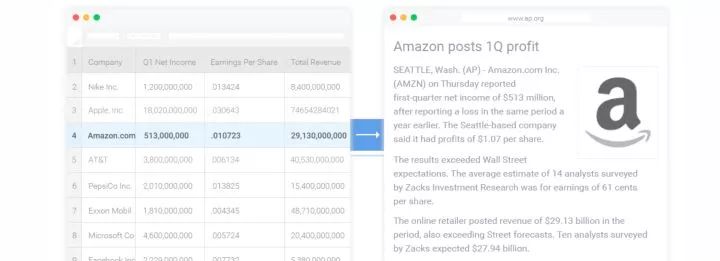
事实上,Data2Seq领域在工业界有着非常大的应用价值,应用领域如天气预报、体育报道、财经新闻和医疗报告等。一些典型的公司如Automated Insights已经撰写了超过3亿篇财经体育等领域报导,下图是其根据Amazon的财报数据自动生成一篇文章的范例,国外其他知名的NLG公司还有ARRIA、NarrativeScience。
我们做智能内容生成项目最大的初心所在,我们的目标不仅仅是为了写出一些达人能写的描述,更在乎既然今天的淘宝拥有如此多的用户数据、商品数据和行为数据,有足够好的计算基础设施,我们能够知道消费者关注什么,知道哪些商品好,好在哪里,我们更要去用好这些data,驱动业务创新,也许是一个产品或品牌综述,也许是多商品对比评测,项目名字之所以叫“阿士比亚”,也正是我们期望他能成为“阿里的莎士比亚”。
传统的NLG的实现套路是将整个文本内容生成过程设计为宏观规划、微观规划和表层实现三个独立的模块串接而成的pipeline,如下图所示,系统的输入分为两部分,一部分是在原始数据中发现的pattern,类比于我们下文将介绍的智能素材库;另一部分是文本生成Goal,类似下文将展开介绍的Data2Seq模型的Control部分,比如在天气预报场景中Goal可以是综述过去N-day的温度还是进行预测未来N-day天气,目标不同则后续的宏观规划甚至微观规划也不相同。具体到文本生成pipeline里面,宏观规划阶段解决“说什么”的问题,微观规划和表层实现则是解决“怎么说”的问题。具体的:
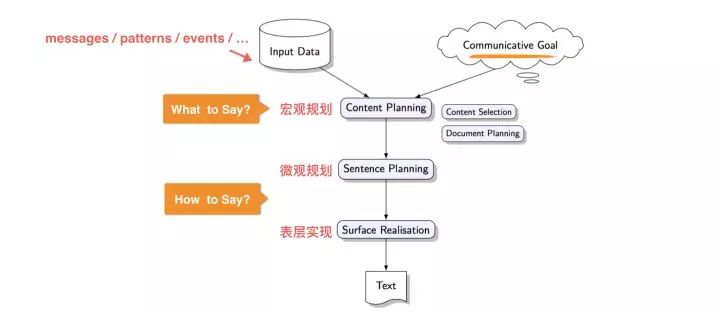
传统NLG系统框架
宏观规划:也被称为内容规划或文档规划,主要目标是选择出需要在文本内提及的内容和文档结构,一般来讲。类比到商品推荐理由生成里面,就是卖点选择和卖点顺序规划过程。
微观规划:也被称为句子规划,顾名思义,就是在句子粒度的优化,这个阶段的输入为宏观规划选中的内容和结构,主要涉及到对句子进行规划以及句子实现,要求最终实现的句子具有正确的语法、形态和拼写,同时采用准确的指代表达。
表层实现:则是句子实现的最上层,类似于写作中文笔润色过程。
显然以上这种pipeline结构的存在的最大问题是将任务拆分成独立几个部分,也就是非端到端,这本身就损失了很多信息上限显然并不高。实际上,尽管NLG领域的研究起源比较早,但在学术界长期处于停滞状态,原因主要在于NLG是一个简单输入复杂输出的任务,问题的复杂度太大,至今没能探索出一个准确高且泛化能力强的方法,不少场景下整体甚至低于人工规则。
另外,NLG领域至今也没有一个客观且准确的优化目标或者说评估标准,这也是限制该领域发展的重要原因。目前的主流的评估方法分两类:人工评测和基于数据评估。人工评测的维度主要是流畅度、可读性、信息量、正确性和冗余度;基于数据的评估主要有三个思路,基于n-gram匹配的BLUE和ROUGE等,基于字符距离的Edit Distance等和基于内容Coverage比率的Jarcard距离等。基于数据的评测在NMT场景还有一定意义,这也是NMT领域最先有所突破的一个重要原因,但在内容生成场景基本意义不大了,无法给出真正有意义的度量,我们在实际项目中基本依赖人工评测和分析为主。
近年来,随着深度学习在广义NLG问题上特别是NMT(Nerual Machine Translation)、Text Summarization领域的突破,基于深度学习的端到端的Data2Seq类模型的研究也越来越多,本文介绍的生成式内容生成模型Data2Seq正是处于这样一个背景,第六章节会详细阐述。另外,借鉴于文本摘要领域抽取式和生成式两种方法的思路,结合淘宝商品数据实际,我们设计并实现了一套基于详情页的抽取式内容生成方法,将在本文第七章节详细阐述。
三、现阶段的产品形态
项目组现阶段的产出是以商品单品的推荐理由为主,因此我们从覆盖商品数量角度出发定义了两种产品形态,即:单品的推荐理由和多商品的智能清单。在这里提前做下产品形态的简单介绍,这样大家读起来会更加有体感。3.1 单品推荐理由顾名思义,就是有关单个商品核心卖点的描述。我们又从文本长度特征出发将单品推荐理由区分成两类:单品的一句话导购短句和多句话短篇推荐理由。下图是我们8月份在搜索-挑尖货场景全量的一句话导购短句的应用实例。
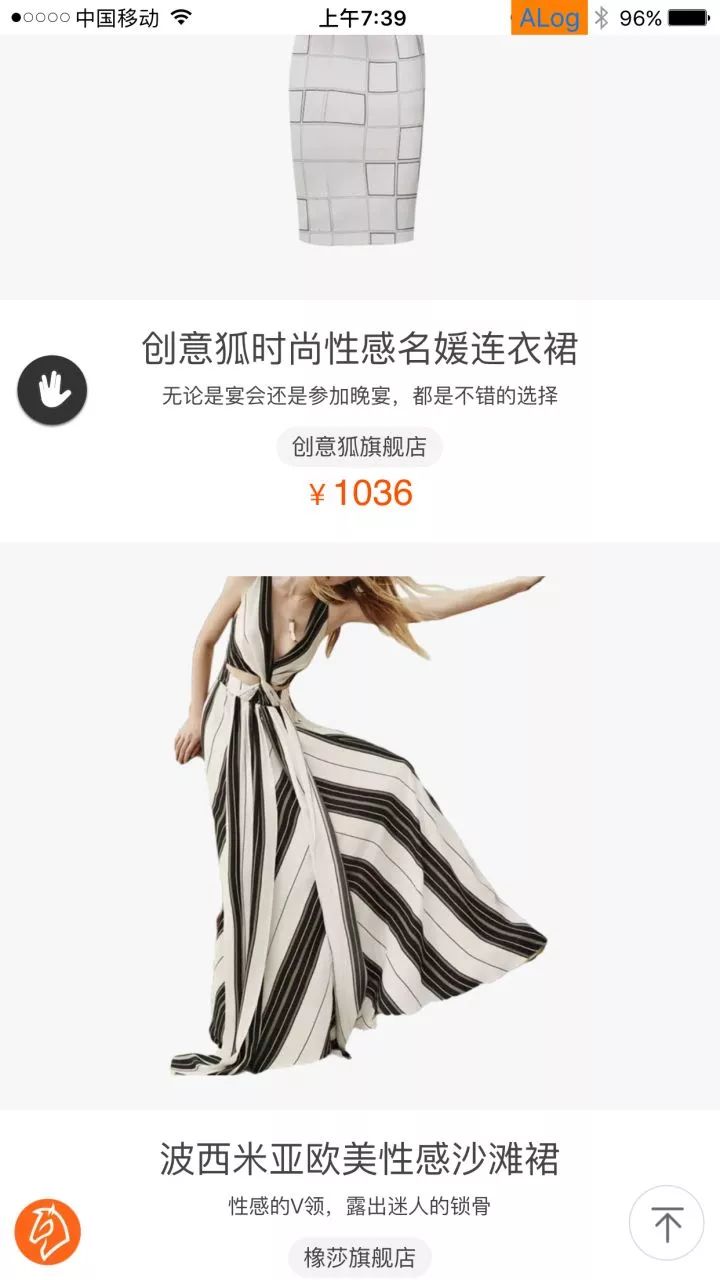
单品推荐理由线上效果示意图
3.2 多商品智能清单智能清单覆盖商品数量一般在10-20个左右,清单内的单品介绍一般类似于单品短篇推荐理由,长度大致在30-40个字居多。智能清单内除了单品短篇推荐理由,还包括清单选品,清单标题两部分。此外清单内的商品推荐理由不同于单品推荐理由的一点是,它既需要考虑清单的主题保持一致性,又要同时考虑其他商品生成的推荐理由以避免重复从而保证多样性。
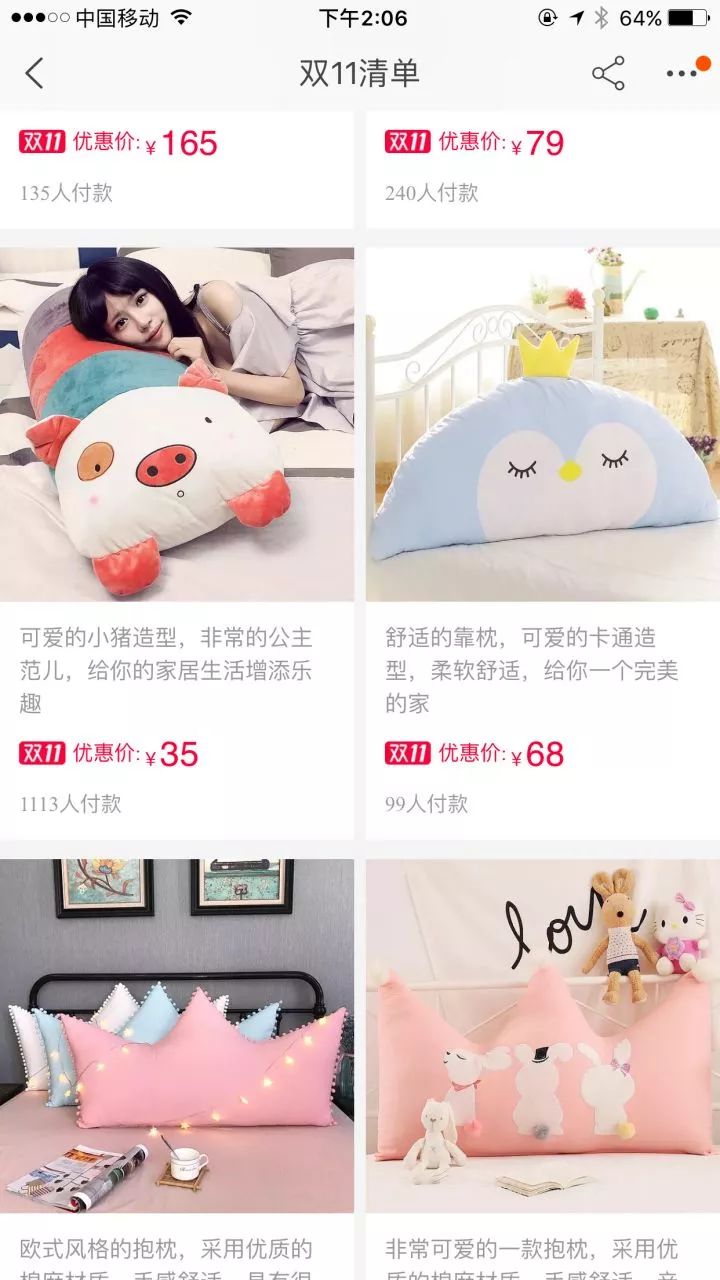
智能清单线上产品形态
四、整体技术方案综述
下图所列的是智能内容生成项目的整体框架。在上文的NLG综述中已经介绍过,内容生成的输入部分有两个,一个是下图中的智能素材库,是内容生成的底料来源,另一部分生成目标则被集成到我们Data2Seq模型中了,在本文第六章节Data2Seq模型部分会详细介绍。而内容生成核心问题两大核心问题说什么(What to Say)和怎么说(How to Say),即宏观规划、微观规划和表层实现在我们的方案中全部融入到深度学习的端到端模型中,同样会在第六章节详细展开。
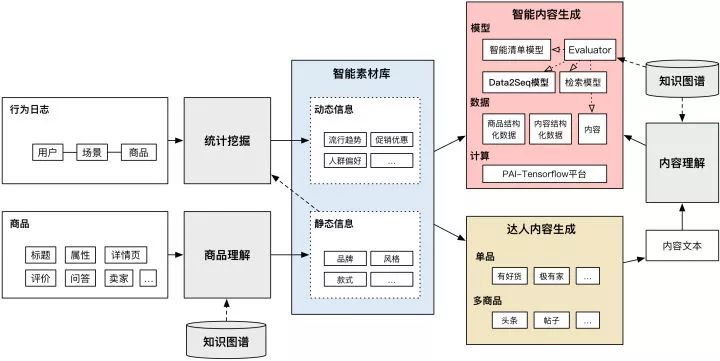
智能内容生成系统框架库
上图主要包括智能素材库和智能内容两个部分,接下来分别做下介绍:4.1 基于知识图谱和统计挖掘的智能素材库智能素材库中主要包括商品相关的动态和静态两类信息,静态信息比如商品的品牌、风格、款式等,动态信息则是类似于流行趋势、人群偏好、促销优惠等。其中静态信息的获取是基于知识图谱的商品理解模块对商品的标题、属性、详情等文本进行理解的结果;动态信息则是基于用户的行为日志和静态信息的分析结果统计挖掘得到的。智能素材库里商品的每个维度的静态信息和动态信息我们统一定义为Topic,又因为全部来源于商品,下文用”Item Topics“或“商品卖点”代指智能素材库中商品的动态静态的结构化信息。智能素材库的用户有两个,一个是提供给达人,达人写作过程中作为参考用,目前已经在达人平台上线;另一个就是提供给智能内容生成训练和预测数据中的Item Topics部分。4.2 智能内容生成智能内容生成部分的核心是Data2Seq模型,它的训练数据输入包括部分:来自素材库的Item Topics和基于知识图谱的内容理解分析的达人内容的Target Topics,目标则是达人内容。模型部分除了Data2Seq模型,还有基于知识图谱的Evaluator模型,事实上Evaluator模型不仅仅工作在预测Seq生成阶段生效,在训练数据和目标的的预处理和过滤同时生效。此外,整个训练基于Pai-Tensorflow平台进行。以上便是项目的整体技术框架,接下来会分别详细阐述。
五、智能素材库
智能素材库的作用前面已经讲的比较多了,该部分主要介绍下商品卖点设计、静态信息计算的基于图谱的商品&内容理解和动态信息计算中的统计挖掘的方法的一些细节。5.1 商品卖点设计
如下图所示,商品卖点素材信息包括静态信息和动态信息两部分。静态部分主要包括商品的基础属性元素,如品牌、款式、风格以及这些属性元素相关的扩展信息,比如品牌的调性、产地,店铺的资质等,这一部分的信息依赖知识图谱和基于其的商品理解。动态部分包括促销活动、上新、成交分布和趋势、评价、搭配和LBS等,其中成交分布和趋势的细分到属性粒度依赖静态信息的理解结果,典型的动态信息比如”最近一个月口红的流行颜色趋势“信息。目前我们基本已经涵盖主要类目的静态信息分析,动态信息上主要集中在成交分布&趋势和上新方面。
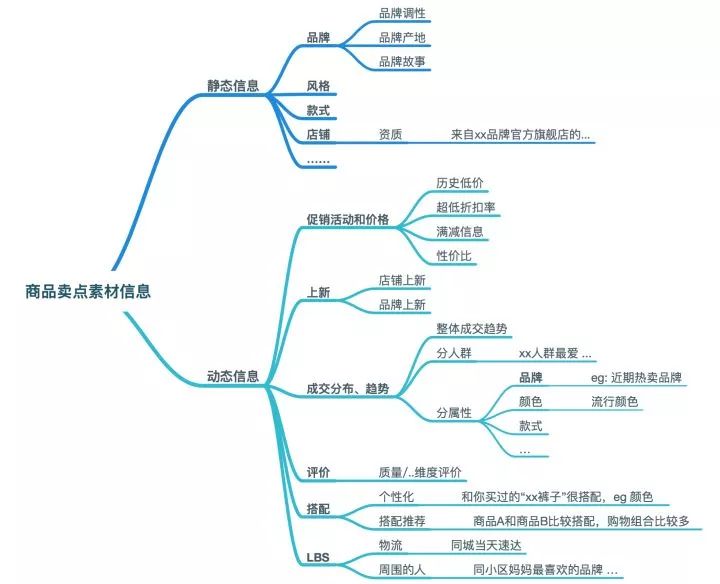
5.2 基于知识图谱的商品理解和内容理解
知识图谱概览:我们内部称之为“云壤知识库”。云壤内涵盖两类知识:词条和关系。词条知识覆盖淘宝电商相关的30种类型知识(如品牌、材质、款式、风格、功能功效、人群等等)目前词条数量1891w(其中品牌词58.8w,品类词8w,风格词3.6k,产地词3.8k,图案词10w,人群词360等)。关系数据包括同义关系、上位关系、下位关系、冲突关系、父子品牌关系等类型,5636w+条关系。知识图谱相应的词条和关系的挖掘算法等接下来会有专门文章介绍,在这里就不再详细展开了。
目前知识图谱主要支持的线上业务是主搜索的query理解、属性相关性(“丝绸之路”)、产品库和平台治理负向发布端管控、搜索端管控等。下图是云壤知识库的前端界面。
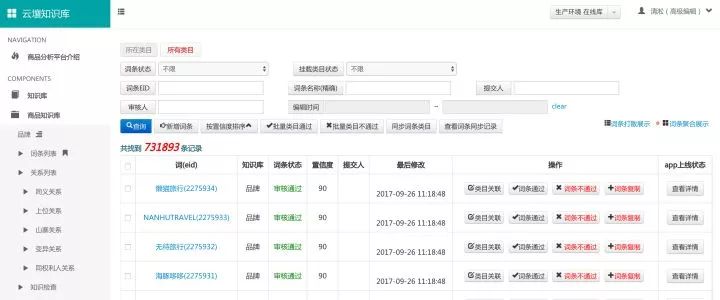
云壤知识库前端界面
基于知识图谱的词条和关系,我们有一套商品理解和内容理解系统,核心模块包含词条匹配和消歧两个模块,其中消歧模型的主要技术方案见下,主要是基于双向LSTM+CRF的思路实现的,同上详细的细节在本文不展开了,后面的图是商品理解结果的前端示意图。
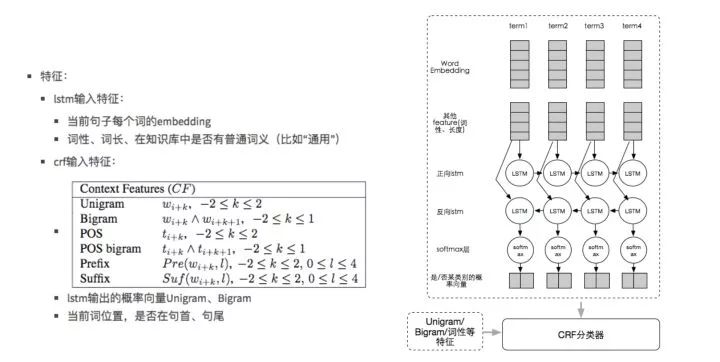
消歧技术方案
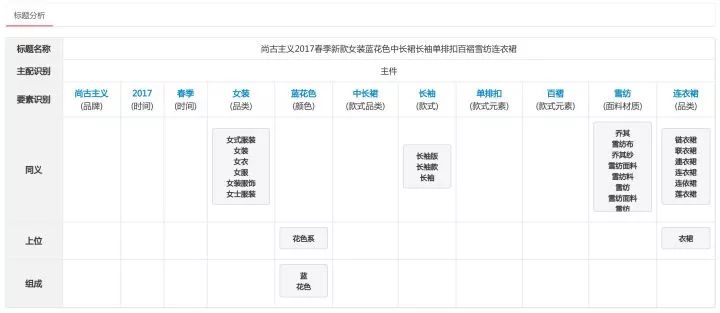
基于知识图谱的商品理解结果示意图
5.3 基于行为日志的统计挖掘
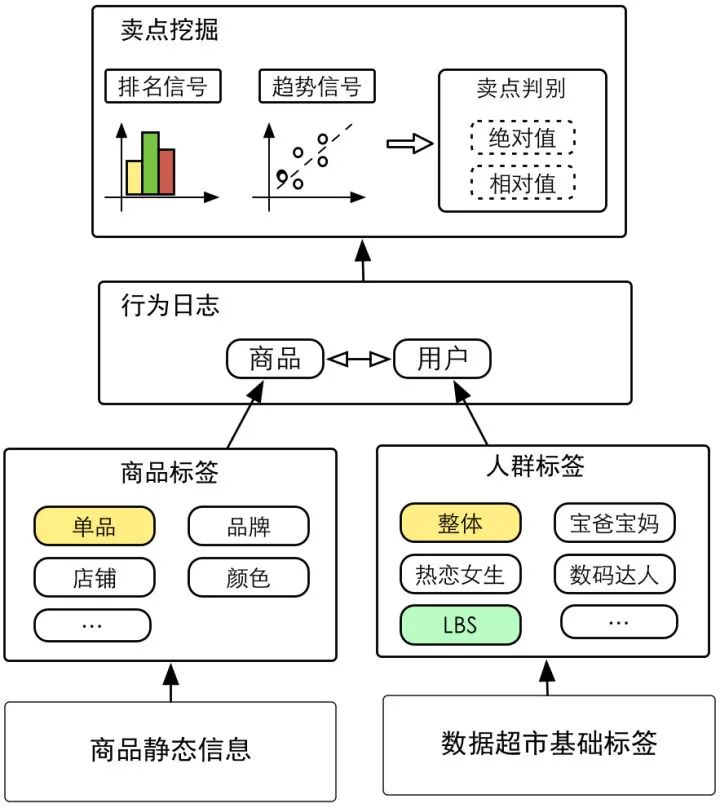
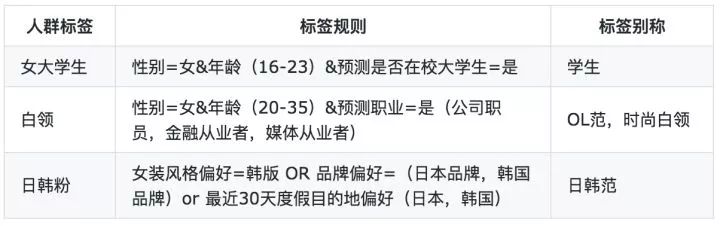
具体的方法是我们在商品和人群端分别挖掘标签,然后根据相互的笛卡尔积交叉得到各个维度计算排名和趋势信号(其中趋势信号用day-维度线性回归即可),具体的计算过程见下图。其中商品标签来源于基于知识图谱的的商品理解结果;人群标签方面,我们主要依赖阿里巴巴数据超市的基础Tag组合而成人群标签,下面的表是人群标签的几个范例,标签别名是在生成内容时为了增加多样性而设置的不同说法。
5.4 达人用户视角的智能素材库
最后简单介绍下提供给达人用的智能素材库界面。如下图所示,达人在给商品写推荐理由时,通过素材库可以获得商品相关的静态和动态信息,比如品牌Slogan/品牌故事,用户关心的问题、评价热点、详情页关键信息(数据由第七章节介绍抽取式详情页内容生成支持)等,可以快速的建立对商品多维度理解。这样一方面加快了达人写作速度,另外也更好的为智能内容写手提供素材。

六、Data2Seq模型
该部分是基于深度学习的端到端解决方案,也是智能内容生成中最为核心的部分。本章节将按AI三驾马车:数据、算法和计算三个角度依次展开,其中计算方面的优化我们和PAI-Tensorflow同学8月初开始立项合作优化,本文只关注在数据和算法部分,有关计算优化的详细介绍请关注后续九丰和慕琢的项目分享。
6.1 数据训练数据的数量和质量的对深度学习类任务的重要性就无须赘述了。有足够大数据量且质量足够好的训练数据之后,简单模型也足以取得相当好的baseline,数据也是一切复杂模型的基础。具体介绍下我们在商品单品推荐理由训练数据的处理方法:
训练数据量:我们通过官方渠道背书和优质达人的数据扩展训练数据。
官方渠道:有好货、极有家、淘宝头条、手淘行业其他卡片、清单商品推荐理由等。
优质达人:实际上,很多达人是不停在平台生成内容的,但生产的内容中很多并没有被官方渠道选中,也或许他们生产内容的动力不仅在于投稿也在于粉丝关注,我们根据达人的粉丝、历史招投稿信息等圈中了优质达人,把这些达人每天的单品推荐理由内容设置为候选集。这些数据的增量还是非常可观的,贡献了约一半的训练数据量。
训练数据质量:事实上,原始训练数据的质量远没有那么理想,除了一些语法错误外,有很多推荐理由甚至是商品原始标题,特别是优质达人来源数据质量更是非常低。因此这个部分我们开发了比较系统化的插件式的Evaluator模型,用于处理和过滤训练数据,主要包括预处理和判别模块。
预处理:基础的繁简转换、大小写归一之外,对语法或冗余字符也做了过滤处理。
判别:判别模块我们主要解决堆砌重复问题、badPattern、低置信语法和标点规范等维度问题。
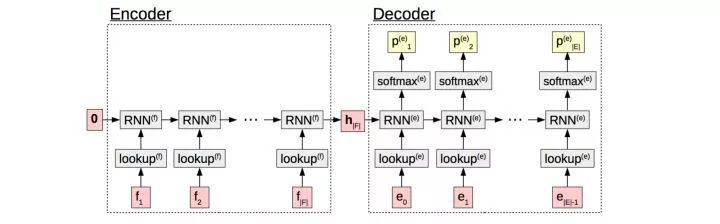
最终我们使用的有效可用的推荐理由训练数据量超过1600w,基本已经达到了目前淘宝平台可用训练数据的极限。6.2 模型Data2Seq领域近年的发展主要得益于参考NMT领域的突破,下图是NMT中标准的Encoder-Decoder结构,在Encoder阶段把输入序列的信息通过RNN_forward encoder到固定向量h_|F|中,decoder阶段根据h_|F|逐个解码得到输出序列。
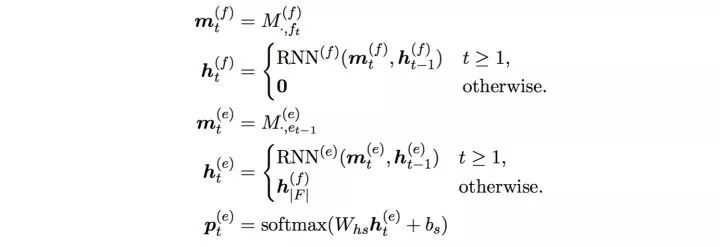
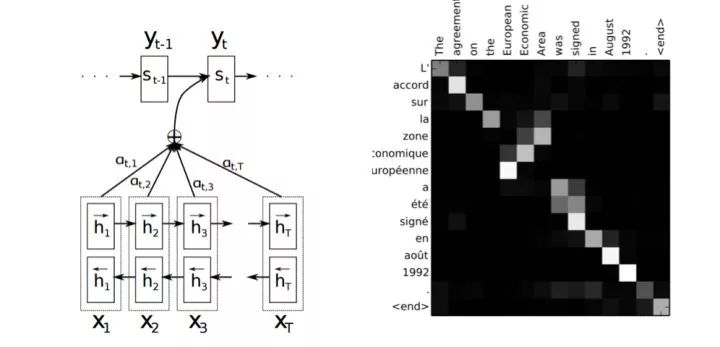
但是标准的Encoder-Decoder结构中把源端信息都通过RNN_forward encoder到固定大小的向量中,但RNN本身存在长距离依赖问题,且把任意长度句子都encoder到固定长度会导致句子太长时无法充分表达源文本信息,句子太短时不但浪费存储和计算资源,而且容易过拟合。显然这时候该Attention登场了,Attention机制允许解码时动态搜索源文本中与预测目标词相关的部分,很好的解决了上面的问题。下图就是大家都比较熟悉的Bahdanau-Attention对齐模型的算法原理和对齐效果示意图,不展开介绍了。
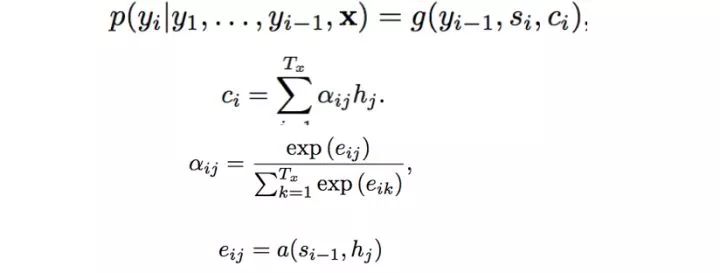
我们的Data2Seq(D2S)模型,虽然主要借鉴与NMT的Attention-based Seq2Seq模型,核心的框架同样也是Encoder-Decoder,但深入思考下两个任务的特点,我们不难发现D2S与NMT有着比较大的差异,也正是这些差异决定了我们不能只是简单的拿NMT领域适用的Encoder-Decoder结构去理解D2S模型。下面是NMT和D2S对比图:
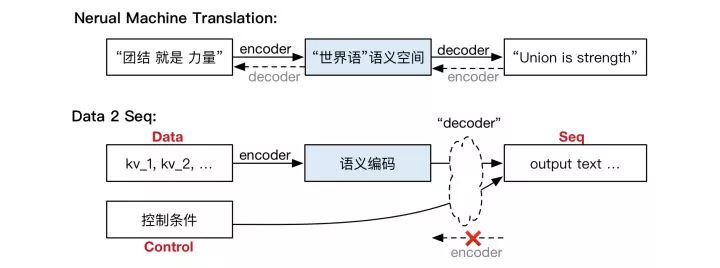
NMT相对D2S的最大不同在于它的任务中输入输出基本可以理解为一一对应的,且是可逆的。比如上图中中译英的例子,"团结就是力量"和"Union is strength"之间是可逆的,也就意味着他们在一个虚拟的“世界语”语义空间共享同一个编码,这也是为什么NMT可以做迁移学习的一个重要原因,即有了中译英和中译法可以很容易翻译出英译法。
而在D2S任务中,即便是完全相同的输入,不同的输出都可能是对的,也就是说输入输出是一对多的,显然输出文本不可能再还原回输入文本了。这个很容易理解,比如同一商品,不同的达人选择的卖点和最终介绍的文本可以完全不同,但都可能是正确的。从这个角度出发,在输入端额外设计控制条件是由D2S模型一对多的特点所决定的,甚至是必须的,模型最终因此拥有的控制能力则是果而非因,绝非为了控制而控制。从另外一个角度去理解,Control部分实际对应的是第三部分讲的传统NLG流程里面的Communicative Goal模块。
所以基于以上考虑,我们提出了把整个D2S模型划分为Data/Seq/Control三个部分:
Data端:涉及数据的表达和建模的方式,也就是素材库内容如何体现。这部分会介绍下Data端的Encoder方法,重点介绍下我们在数据端的测试的三种模式以及动态数据的训练。
Seq端:核心在于文本序列生成能力,一般来讲,最简单的Seq端就是N-Gram模型。Seq端指的是基于RNN(或其变形LSTM/GRU)的语言模型,我们在这里可以玩的是decoder设计更复杂或更精巧的模型、使用更多更准确的训练数据,使得模型具备强大的表达能力。主要会介绍下深度残差连接网络的应用。
Control端:这也是D2S中特有且非常重要的部分,上文也提到了生成一段流畅的话向来不是难点,重要的是如何从不同维度精准的控制Seq端的生成,分别介绍下重复问题控制、结果正确性、确保主题相关、长度控制、风格控制、卖点选择控制、多样性控制等,这也是NLG领域研究的热点所在。实现这样的控制,既需要在模型的Encoder和Decoder端同时发力,同时需要在解码预测同时控制。
下图是D2S模型的整体结构,我们实际采用的模型是这个模型结构的子集,encoder端分为两部分,encoder的方法包括RNN/CNN和简单的Embedding,decoder端生成文本时通过Attention机制进行卖点选择,控制信号在DecoderRnn的输入端和预测下一次词的Softmax层之前参与控制。接下来按照Data/Seq/Control端的顺序分别介绍下我们的工作,最后再简单介绍下我们在清单生成方面的工作。
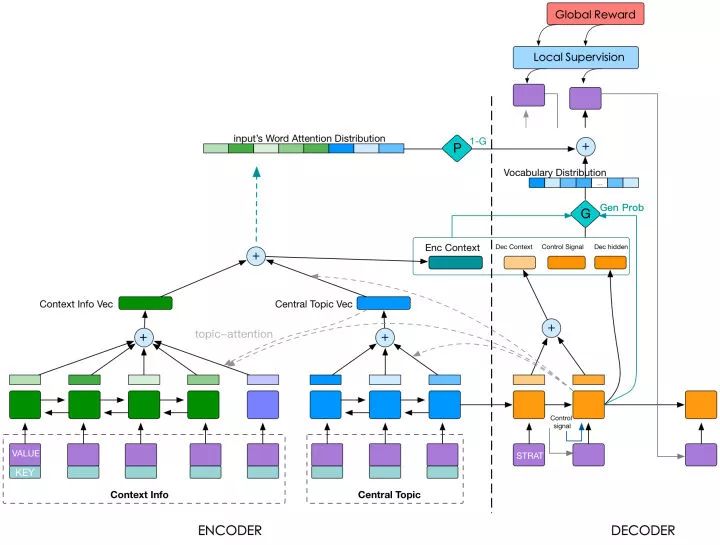
D2S模型整体结构
6.2.1 Data端
6.2.1.1 Data的表示如下图中所示,D2S中输入数据(即一个"卖点"或"Topic")通过Key和Value两个field来进行共同进行表达。其中KEY是知识库的词条类型ID,即KID,Value是利用知识图谱里面的同义词知识归一之后的词条ID。比如商品原始文本有"Chanel",对应模型的输入topic为“KID=品牌;VAULE=香奈儿”。且除了KID识别和同义归一之外,我们还利用知识图谱本身的扩展信息扩充了商品Topic的覆盖,比如对于对于香奈儿,我们还会扩展出“品牌产地:法国”“品牌档次:奢侈品”等信息,以此丰富我们的输入信息。
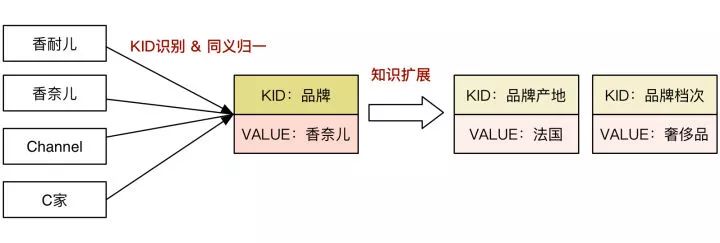
KID识别和同义归一的处理则有两个好处,首先KID的引入赋予了模型很强的泛化能力,能够起到类似于"模板"的功能,对于一个稀有的Value,我们能够通过KID知道该如何表达和描述,后面将介绍的动态信息的训练中也正是借助KID实现的,其实本质上其实也是实现了Copy机制;其次,Value经过同义词归一之后,噪音数据更少,使得模型学起来更加容易,因为Data端更关心的是语义signal而非表达多样性,语义归一的必要性自然是非常必要的选择。
在模型内的具体语义表达方面,topic的Key和Value分别有一个独立的EmbeddingDict分别获得其语义维度的表示,两者concat起来得到的是模型内topic的表示。而对于整个输入的表示,我们共对比测试了三种模式的encoder方法:RNN、CNN和Concat,最终使用的方案是Concat模式,即只用topic的Key和Value的Embedding语义编码作为encoder阶段的输出,输入端不用RNN或CNN提取feature。
Encoder用的Concat模式,乍听起来比较奇怪,这里面除了降低计算复杂度的考虑之外,最重要的原因是RNN和CNN本质上都是通过捕获局部相关性而起作用的,具体到自然语言领域,提取的是类似n-gram的信息。然而在Data2Seq模型的设计中,事实上不同的topic之间是独立的且无序的,而CNN和RNN模型是无法在这样的无序的假设条件下work的,否则对于同一输入,扰乱顺序后捕获的语义表示就变了,显然不是我们希望的。实际数据的测试也印证了我们的假设,即便在我们不太认可的ROUGE指标上和mle loss,RNN模型并没有体现明显优势,具体的实验数据还需要重新回归。6.2.1.2 Data的内容和结构
解决了Data的表示后,Data包含哪些内容,采用什么结构就是亟待要解决的问题了。我们参考了类似百度写诗的paper的做法,设计了一个Planning-Based的D2S模型。百度写诗的训练数据见下图,其直接在目标内容(即诗句)中用textRank方法提取KeyWord(下图第一列)作为Data部分,之前的诗句作为Context进行训练。在预测阶段(下面第二张图)用户的Query经过Keyword Extraction & Keyword Expansion阶段后规划处四个Keyword,然后逐步生成每行诗。


这种结构看起来还是很通畅的,好处是可以借助知识图谱进行Keyword扩展,如下图所示,输入“奥巴马”也可以规划“西风/巴马”“总统”“美国”“民主”。但这种方法存在最大的问题也恰恰是Planning的难度很高,另外诗歌场景前后两句尽管有关联,本质上还是有可以一定程度断开的独立的,所以不管是百度写诗还是微软小冰写诗都可以用这样的结构,但我们的商品推荐理由则是连续的一段话,不能在这个层面运用Planning-Based的方法,但可以尝试比如在段落粒度运用Planning。

具体实践中我们发现,Planning-Based的方法好处自然是我们可以任意的控制topic,但存在的具体的问题第一是规划出的topic之间的搭配会导致较多不通顺的case;另外就是这种模式只能学到直接的关系,比如输入topic是“五分裤”,生成的文本基本很难出现“半裤”这样的相近词,也就是模型有点“直”。为了解决这个问题,下图是后来我们在Data端的内容和结构做的设计:
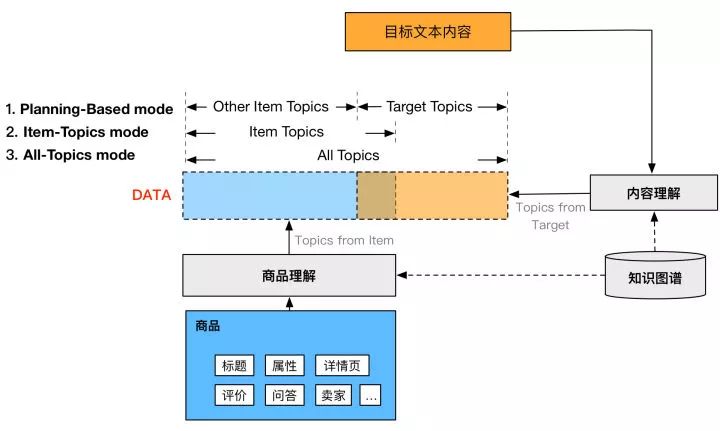
如上图,DATA部分总共有两个来源,一个是图中蓝色部分来自商品理解后的结果,另一个是来自目标文本内容理解后的结果,且两部分有一定的交集。Planning-Base mode就是我们前面讲的,Data结构分成两部分,一部分是核心topics,另一部分是context topics;第二三种模式都是只有一层扁平的输入,区别是Item-Topics mode中topic全部来源于商品本身,而All-Topics mode则是汇聚了商品和目标的结果。
最终在模型中选择的是All-Topics mode,预测中用Item-Topics做预测。而终没有用Item-Topics mode原因除了mle loss下降更明显外,主要的原因是我们分析了下,实际上内容里面的topics和商品的topics交集远没有我们想象的高,大约只有20%左右,这就意味着模型会学到没有卖点A但是还是写出卖点A相关文本的模式,这种模式下就会导致很多生成的内容和源卖点不匹配的case。而内容提取的topics不完全存在于商品topics中是很好理解的,有些是达人通过图片或很难提取信息的详情页获取的,有差集是很正常的。
All-Topics mode最大贡献在于确保预测结果的正确性,除此之外,这种方式相对Planning-Based mode最大的优势在于赋予了模型卖点选择的能力,下图是我们8月份在搜索-挑尖货场景全量的一句话导购短句的例子,同样是短裙类目的商品,仔细看下四个商品的导购短句,每个商品被提到的卖点都还是很有其独特性的。
6.2.1.3 动态Data的训练以上的针对的主要是静态数据训练相关的设计,而前文已讲到,D2S模型的一个很重要point是通过动态数据获得更多的信息量,写的更为干货。但动态数据本身的样本标注其实还是比较困难的,接下来以"流行趋势"这类动态数据的训练为例,简单介绍下我们的做法。
训练阶段我们先通过先验规则和W2V语义相似度挖掘出流行趋势相关的词,比如”流行“ ”大热“ ”热门“等,然后将其所在短句最可能的卖点原来的KID置换成”KID=流行“,在预测阶段则对从数据中挖掘到的流行的卖点,将其KID替换成”流行“,生成的数据效果如下所示:
对于第一个商品我们将“KID=颜色 Value=深棕色“的KID替换成“KID=流行”之后,生成的单品推荐理由:“今年很流行这种深棕色的针织衫,很有女人味的一款套装,穿在身上很显身材,而且还能很好的拉长腿部线条,很显高哦 。”就非常准确的描述了深棕色的流行趋势,做到了言之有据,且有关流行趋势的说法还是比较丰富的。
当然完全的把KID替换掉会导致商品丢失原始KID信息缺失,正在补一个采用双KID相加后得到新KID方式的实验。6.2.2 Seq端
6.2.2.1 基础的单层RNN-语言模型简单intro一下基础的RNN-Language Model。语言模型本身是在计算一个句子E=e_1,e_2,...e_T(e_t是其中第t个词)是自然语言的概率,语言模型的目标是
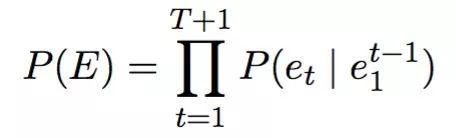
,不难看出语言模型的核心问题可以转化成预测 P(e_t|e_1~e_t-1),即根据e_1~e_t-1预估e_t,最简单是基于统计的n-gram LM(Language Model),即预估e_t时只考虑前面n-1个词。下图是基于Nerual Network的tri-gram LM,显然在预估e_t时值需要考虑e_t-1, e_t-2即可。我们经常用的Word2Vec正是NN-LM的lookup表的一个中间产物。

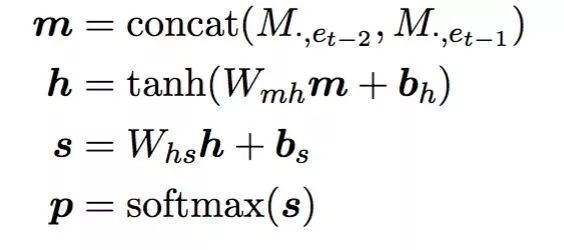
但显然NN-LM无法摆脱他本质是n-gram模型的缺陷,即建模的长度有限最多只能使用前n-1个词,且在上图的concat模式下加大n个数量,由于前面各个位置的权重是一样的反而会导致模型学习效果下降。实际上自然语言中,长距离依赖的情况是非常常见的,比如下图的例子中,预估"himself"和"herself"时,显然分别要依赖于句子最前面的"He"和"She"。

下图便是RNN-LM的公式,m_t是第t-1个词的Embedding结果,与NN-LM不同的是,RNN-LM的输入只有一个,原因是前面的信息都融入到h_t-1中了,这样就不需要直接把更靠前的序列作为输入了。当然RNN本身存在梯度消失问题,内容生成模型的decoder端实际使用的是RNN的一个variant LSTM。
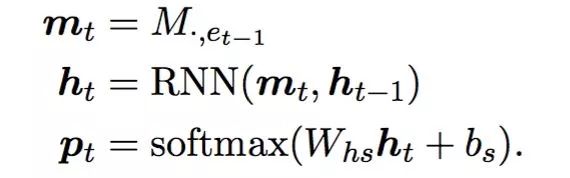
6.2.2.2 多层残差连接网络由于我们使用的训练数据量比较大,能够支撑我们在模型的decoder阶段进行复杂模型、大容量模型的尝试。我们再这方面的主要尝试从网络宽度、网络深度两个角度出发。网络宽度方面我们主要测试的是增加num_hidden size,效果还是比较明显的,网络深度方面我们测试的是下图中的残差连接方式的stacked RNN。
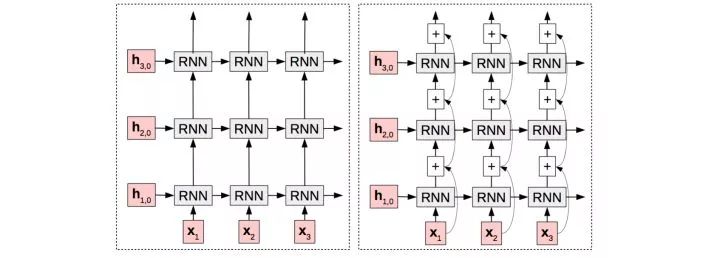
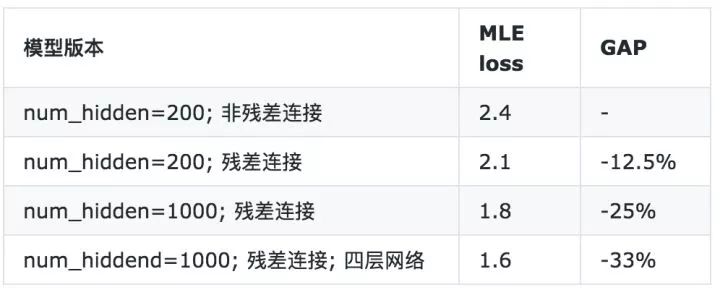
以下是不同版本的MLE loss上的变化,单层网络-残差连接方式loss下降说明在预估前一个词时,直接将上一次词作为输入是有收益的,增加网络宽度和深度loss都能有所降低,但受限于模型容量问题,目前在16G的单卡GPU只能最大测试到num_hidden=100,4层的残差网络。
这个部分计划尝试下Densely Connected深层网络和Recurrent Highway Networks,受其他项目优先级的挤压暂时先hold住了,待后续实验后再补充。6.2.2.3 双层RNN网络的尝试我们在Seq的网络结构方面做了下双层RNN双层Attention的尝试,网络结构图见下图,核心点是在拆分出句子维度和词维度的两层RNN网络,同样的在卖点选择方面也是双层Attention共同作用。之所以尝试双层RNN的原因是希望模型有更好的能在长篇幅写作能力,但暂时的实验效果并不是很明显暂时hold住了,分析主要原因是推荐理由的训练数据不像诗歌类天然有好的断句结果,达人的内容的断句质量很差,对效果影响很大。
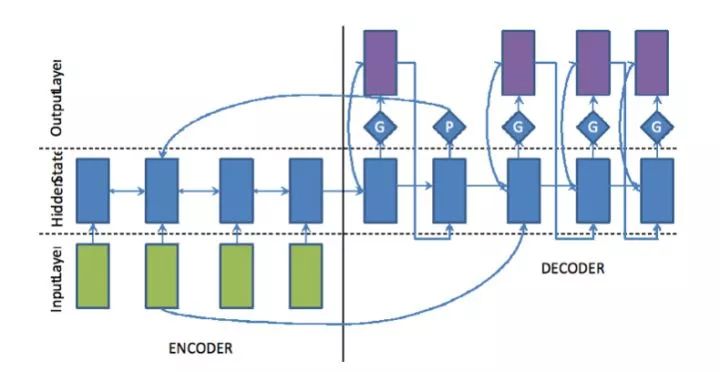
6.2.2.4 Copy机制Copy机制本质上是在combine生成式和抽取式模型。在这方面学界有很多的研究涉及该领域,主要为了解决OOV(Out Of Vocabulary)词的问题。我们使用的做法把Pointer和Generator分离单独训练一个Pointer/Generator swich概率网络,另外一种套路如上面的整体框图所示,把源端的Attention向量的概率和每个词的概率用P/G值加和求max,这种方法的原理是更合理,但训练起来非常慢,实际并没有采用。
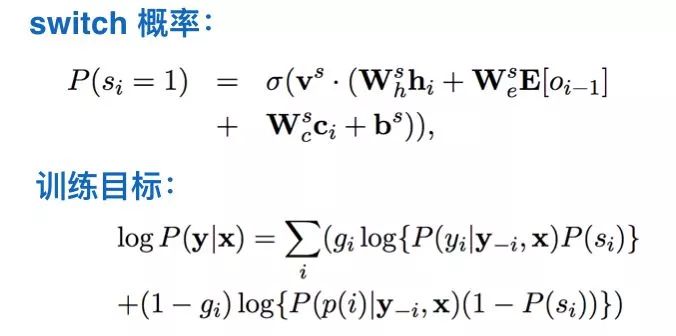
事实上,我们训练的数据足够充分、网络比较大的情况下,词汇粒度OOV带来的问题比较少,词粒度收益测试并不明显。而在Copy机制更深层次的考虑方面,我们更想尝试的是如何把抽取式的内容生成和生成式内容生成有机的结合起来。比如我们分析了下达人的推荐理由数据和详情页句子的交集还是比较高的,也就是说达人在写内容时候也是”参考详情页的内容“,这样的”参考“动作就是Copy机制需要承载的,远不是词汇粒度的Copy而是句子或片段粒度的Copy。相信如果能解决好这个问题,对内容生成的技术领域的贡献还是比较大的,这部分的工作我们还在推进中,在这里暂时留白后续有结果后补充下。6.2.3 Control端
6.2.3.1 软硬结合的控制策略在控制端,需要完成对目标文本的控制,控制的策略总体上分为两类:Soft类方法,即设计机制让模型自己学习到对目标的方法;Hard类方法,即在Decoder过程中进行强干预。Soft类方法的好处是更能获得一个整体效果比较高的提升,坏处是很难确保解决干净。其实采用软硬结合的方式做控制显然是一个不需要过多论证的问题,道理我们都懂,重要的在于方法论。
我们在具体的控制策略上主要依赖InputFeeding机制和预测的Decoder阶段Evaluator模型两种方法。
a). Soft方法:Inform机制
由于各个细分问题的不同,在Soft方法上难有比较完全一致的的方法,但总归大致的思路还是定义为InputForm机制,具体的做法如下图所示,把控制信号在LSTM的输入端和预估下一个词的softmax层的输入端生效,之所以在这两个端同时生效还是有逻辑的:我们相信在RNN输入能够使得模型一定程度上感知目标的动态完成程度,Softmax端的输入能够让模型始终感知最终目标是什么,实际的效果也验证了这种方法的有效性。
b). Hard方法:Evaluator机制
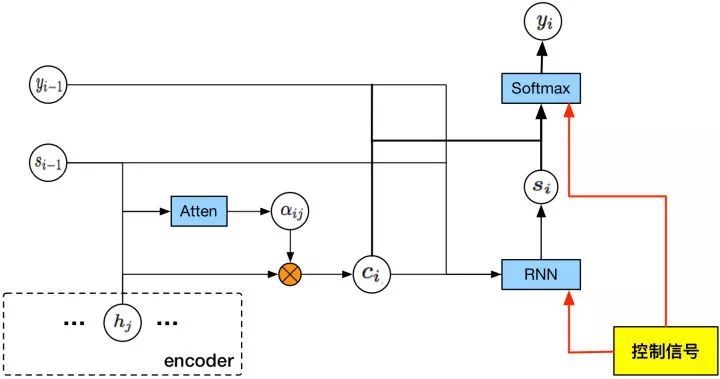
在训练数据的质量提升部分就提到过Evaluator模型,和这里是同一个模型。所谓Evaluator机制的Hard方法指的是在模型预测阶段边预测边评估。
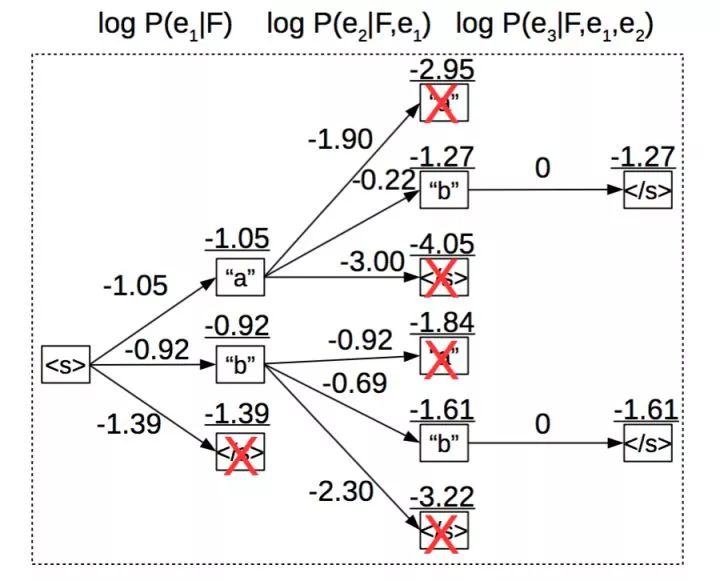
先简单intro下Decoder过程:文本生成的的预测过程是word by word的方式进行的,每一步生成一个词,面临的选择其实是整个词汇空间,一般词汇大小要到10w量级,也就是每一步解码都有10w中选择,如果平均序列长度n,最终候选序列也要10w的n次方可能,计算和存储上是绝不可行的。实际常用的解码方法是beam_search,每一步保留最优的前M个最大概率序列,本质上式压缩版的维特比解码。下图所示的beam_search的beam_size=2,即每一步保留最佳的两个序列,其他序列全部被剪枝掉(即下图中X号)。
beam_search剪枝的过程依赖的模型控制的Soft机制和LM共同作用的概率,我们设计的Evaluator机制工作在同一个维度。具体的,在评估候选序列是否保留时,除了继续考虑模型输出的概率之外,额外增加下图公式红色部分的fuction_evaluator,函数输入为已生成序列 e_1~t-1,具体的评估逻辑就取决于不同的控制目标,就比较有操作空间了。
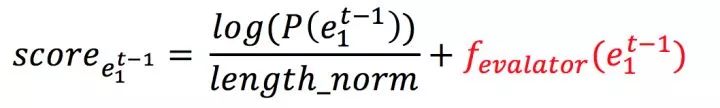
6.2.3.2 重复问题控制重复问题在内容生成领域是一个比较常见的问题,问题的根本来源在于经典的Attention机制每次都是独立的进行Attention计算,没有考虑历史已经生成的序列或Attention历史,显然是一种次优的做法。Attention机制带来的这个坑倒是给学界的研究带来了不小的空间,简单介绍下我们解决重复问题的机制,自然是Soft和Hard并行解决的。
Soft的方法主要是在Data端避免重复注意和在Seq端避免重复生成两种套路。
a). Data端避免重复Attention:Coverage机制、Intra-temporal attention机制
Coverage概念来源于传统机器翻译方法里面保留已经覆盖翻译的词记录的概念。我们采用的是一种”间接“的解决方法,如下图公式,思路是保存下生成过程中已有的Attention权重向量,作为生成下一个词的Attention计算的输入,让模型自己学习到避免重复的条件。NMT中还会增加一个Coverage loss,避免”过翻译“和“欠翻译”,需要注意的是内容生成中只需要避免”过翻译“即可。
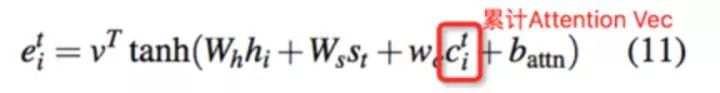
另外一种比较直接的方法就是直接根据已有的累计Attention weight对计算Attention的Softmax层前的结果降权,方法相对比较粗暴,并没有对比测试。
b).Seq端避免重复生成:Intra-decoder attention机制
除了Data端避免重复注意外,对已生成的序列信息同样需要inform模型,避免重复生成,我们设计的整体框架图中的的DecContext就是在解决这个问题。
c).Hard方法:三个维度的重复检测
而Hard方法则是比较简单粗暴可依赖,我们对已生成序列进行卖点维度重复检测、常用连接词重复检测和n-gram重复检测三部分,命中这三种任何一种重复检测的序列的score将设置的非常低。实践中,这种方法对我们整体的重复问题的解决贡献是最大的。6.2.3.3 语义正确性控制语义正确性的控制的soft方法在前文已经提到,就是在训练模式上采用All-Topics模式,让模型自己去学到卖点相关文本的生成需要在Data端有据可依的强条件,这点对我们语义正确性的贡献还是很大的。
另外一个非常重要的解决语义错误问题的就是基于知识图谱的Evaluator模型。具体的过程见下图,知识图谱中存储有同义关系、上下位关系、冲突关系等多种类型的关系数据,在beamSearch解码过程中,候选词和n-gram粒度的词和源端进行校验,如果出现冲突关系则强制不出现,比如下图中的候选token ”夏天“和Data端的”春秋“冲突关系,而比如是上位关系,下图Data端有”连衣裙“,生成”裙子“则是可以的,反之则不行。
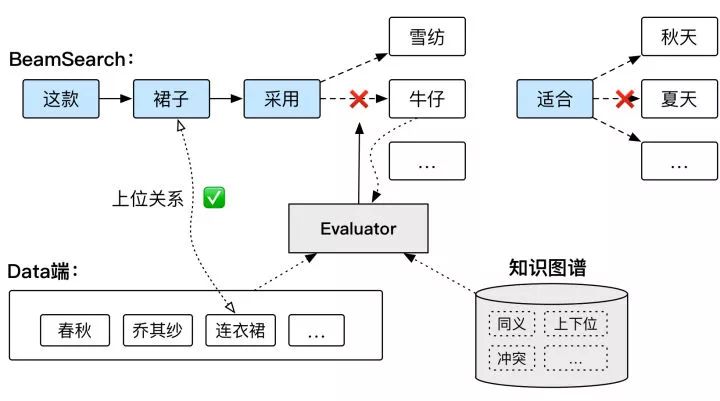
利用知识图谱解决语义正确的一个好处是可以引入其他数据源生成的信息进行校验,避免受数据偏差影响;另一个好处是实际的线上系统生效难免遇到badcase,利用补充知识的方式快速有效干预线上case实现一个很好的闭环,是必须的。
具体的实践中,我们与知识图谱中的平台治理业务维护的违禁词打通,因为模型生成内容是平台背书,避免模型生成违禁信息,并且因为客观属性如品牌、材质、功能功效、季节、颜色的错误比起主观属性如风格等的错误影响更大,我们重点对客观属性的正确性问题进行了线下评测和知识补全。
6.2.3.4 品类相关控制品类相关性的控制我们单独做了处理,在LSTM的输入端和Softmax输入端分别把叶子类目ID的signal输入给模型,让模型自己去学习到这些相关性,直接在loss上做处理反而效果不理想,也未必必要。
下图分别背景墙瓷砖和女装套装两个叶子类目的商品,topics中同样包含”简约“,且描述都是”简约而不简单“的情况下,后面跟的描述则分别是”为你的家...“和”更具时髦感“则是受类目的影响较多。严格的情况下应该对比有无类目控制的效果,实验成本比较高待后续补一下。
6.2.3.5 长度控制长度控制的方法和品类相关控制套路是一样的。我们采用的是商品&内容理解后的token作为词,长度的控制是也是在”token“粒度。虽然没有精确的统计过,但从我们看的case数据看,对token长度的控制是非常精确,且不是简单的截断。下图是一个商品长度控制在10/20/30/40/50 token的范例,显然随着长度变长所选择卖点的数量也逐渐在增加。
6.2.3.6 风格控制
这里的风格控制并不是严格意义上单纯的风格控制,准确的说应该是卖点选择和风格综合的控制。原因是我们是依靠达人的UserID来实现风格控制的,不同达人的写作除了风格不同外,选取的卖点可能不同。具体做法是:训练阶段将文章数量超过100篇以上的达人ID Embedding到20维的向量空间中;预测阶段用Kmeans方法聚合出不同簇的UserID代表不同风格。
下图是服饰类目最好的达人”追梦的小丫“和其Embedding距离最远的簇中心”潮流汇bing“的同一商品的推荐理由对比,文本风格其实是一个很难量化的概念,从我们统计数据看,以”追梦的小丫“为UserID生成的内容以”这款“作为开头推荐理由比例只有20%,而”潮流汇bing“的这一数据则达到了82%。以此管中窥豹,认为两者的风格的差异还是体现出来了。且从下面的文本对比看,”追梦的小丫“文风似乎更有渲染力一些。
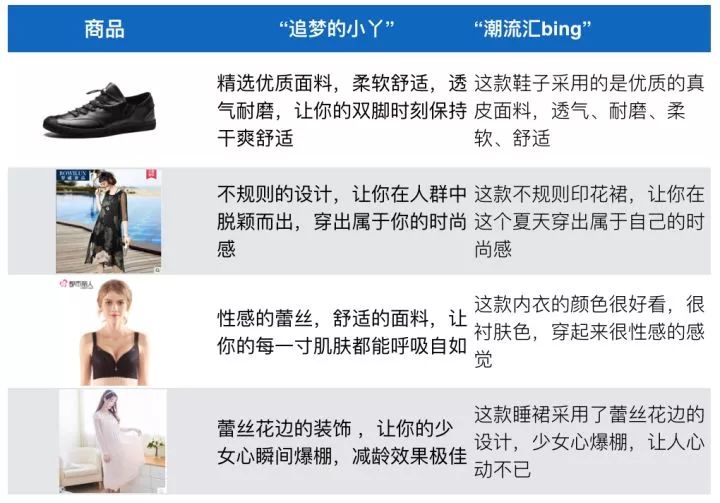
我们认为行业的最好达人生成内容最有吸引力,所以我们默认使用其UserID生成推荐理由。除此之外,我们同样借用不同簇中心用户卖点选择的差异,用在清单维度多样性上。
6.2.3.7 卖点选择控制之所以需要做卖点选择控制,主要用在下一小节的智能清单中。在All-Topics的模式下,模型的卖点选择能力是通过Attention机制承载的,卖点的数量基本和长度控制的长度比较相关。
具体的实现控制的方法上,我们尝试在训练阶段有选择的进行0/1标注是否被选择到,并把这种先验的选择输入给模型的Attention计算部分,预测时通过0/1权重干预,效果还是比较直接。另一个就是对于单纯的不写某个卖点的需求,我们采用的是概率Drop机制,按概率强制从预测Data中去掉即可。6.2.3.8 多样性控制详细内容合并到清单多样性中一起阐述。6.2.4 智能清单生成清单一般包括10-20个商品,核心依赖于单品推荐理由能力,但相对来讲需要额外考虑多个商品间内容的多样性和一致性,且还有独特的清单标题生成和清单选品。目前我们的工作主要focus在解决清单多样性和清单标题生成问题。6.2.4.1 清单多样性清单多样性主要解决的是生成多个商品推荐理由间的重复问题,解决这个问题的关键在于多商品间全局优化。
我们采用的方法是预测时把相同清单的商品放到同一个batch中,batch_size即为清单商品数,然后在Evaluator模型中维护当前清单维度、所在类目维度在卖点、常用连接词、N-Gram维度的统计计数,然后根据出现次数以相应概率drop掉某些token,具体的概率计算方法就是经验值了。
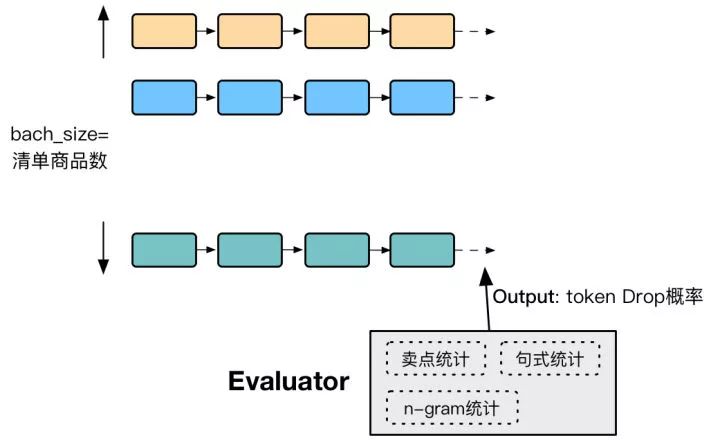
再好好思考下为什么模型多个商品写作时会出现重复问题,根本原因在于解码预测时采用的beam_search本质上选择的是概率最大的序列,是不考虑多样性的,这就难怪会导致模型生成的结果在卖点、句式上有些雷同了。而另外一种依赖概率的random_search解码方法在语句通顺的效果却不慎理想,因此在beam_search中辅以多维度进行概率Drop的思路自然是合理的。
我们在实践过程中发现,D2S模型相同句式的case比较多,比如”让“这个词用的频率最高,我们做了一个强制不生成”让“出现的实验,见下图。从对比可见,即便没有最高频的”让“句式,模型仍然可以找到其他说法,比如把”让人“换成”给人“,甚至直接换一个说法把”让人爱不释手“换成”深受广大消费者人的喜爱“。因此这样的多样性控制策略我们不仅在清单中生效,同样在单品中进行多样性控制(即6.2.3.8部分)。

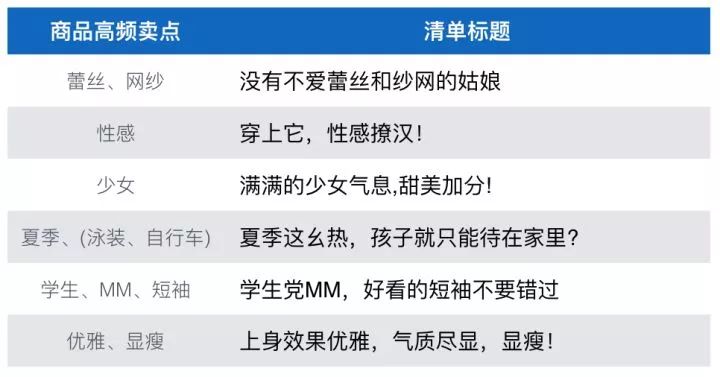
6.2.4.2 清单一致性清单一致性目的在于保持清单内内容和风格的连贯,这部分的工作刚刚开始展开,后续有实验结论再回来填坑。6.2.4.3 清单标题生成清单标题的模型基本复用商品推荐理由的D2S框架,不同的是由于训练数据量远比推荐理由少,模型的复杂度下降了一个level。训练数据主要来源于达人的清单和头条的标题,Data是清单和头条覆盖商品的Topics,预测阶段采用清单覆盖商品的Topics作为输入。清单标题的风格和推荐理由还是完全不同的,更加的写意,随性,富有渲染力!下图是生成的清单标题数据贴出来感受下。
6.2.4.4 清单选品目前的选品策略还比较基础,因为我们很多清单是在搜索场景生效,目前主要依赖query-category-user_tag维度的交叉,结合场景的底层商品池完成清单选品。当然目前的选品策略中还有一个统一的优质商家的优质商品。同样的暂不展开阐述了。6.3 计算D2S模型是基于PAI-Tensorflow平台运行的,模型比较重训练起来也是很消耗资源,为了加速迭代我们8月初开始和PAI-Tensorflow团队开展计算优化的合作。分别在本地、分布式和预测进行优化。本地优化累计提升了超过10倍以上的性能,意味着原本一个月的计算量,3天就搞定了,对D2S的快速迭代很是重要。
目前还在最后的优化分布式性能,具体的细节还请期待九丰和穆琢的分享,后续补充链接。
七、详情页抽取模型
D2S模型是生成式的内容生成模型,我们在上文的Copy机制部分也提到,达人写作过程中其实也是边”造“边”抄“的过程,”抄写“的来源大部分是商品详情页。商品详情页本身是一个宝库,且是商品的详细准确描述,比如下图所示的详情页显然如果都是非常好的推荐理由来源,最终目标是希望能够融合抽取式和生成式两种模式,现阶段还是分离的,接下来简单介绍下单独的详情页抽取模型。
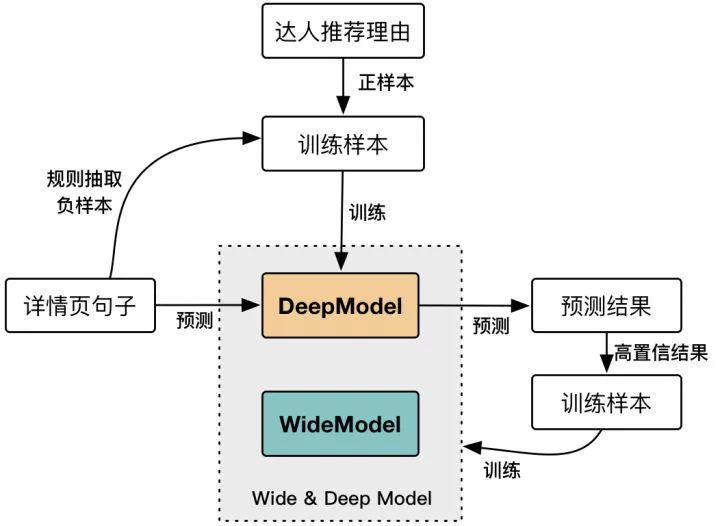
7.1 Boostrap方式的模型训练详情抽取模型本身可以抽象为文本分类问题,文本分类问题和模型相对都比较成熟了不过多展开,核心问题在于label的设置方式重点介绍下。
我们采用的方式是是先用达人的推荐理由作为正样本,利用规则筛选负样本,用Deep模型训练一个基础版本模型;然后再利用Deep模型的预测结果的高置信度的预测结果生成详情页本身的正负样本,加入详情页特有的feature和Deep模型组合起来训练最终的Deep&Wide模型,具体训练过程见下图:
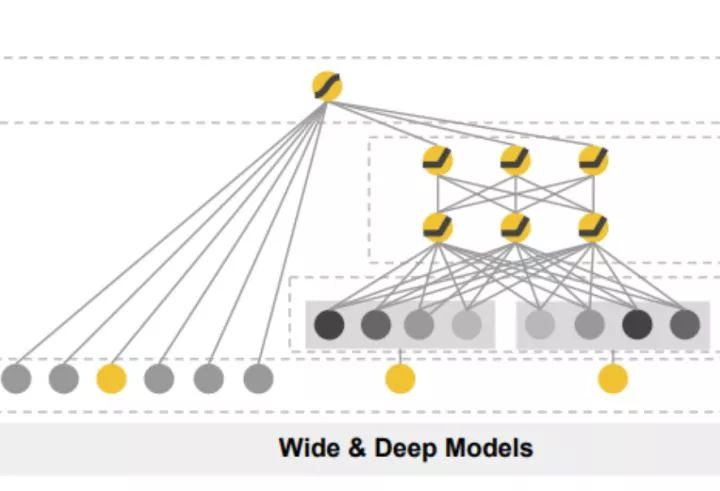
Wide & Deep模型参考的就是google之前的DWL的paper了,见下图,其中Deep部分用的是CNN提取深度feature,Wide主要特征有完成图片维度(文本面积占比/不规范图/小图/上下文指示信息/图片句子数量)和句子维度(字体大小/价格信息/黑名单词/无中文/重复)特征等。
目前在挑尖货场景数据已经全量,数据示例见下图,详情页抽取的结果相对更加贴切和优质的。
7.2 目前的难点详情页本身是个含金量大的”金矿“,但”黄金密度“有限,噪音信号特别多,模型召回提升难度大。而且大部分详情页都是以图片的形式存在的,依赖的OCR是单行粒度的,重新组合后会遇到各式各样的奇葩断句case,给Evaluator模型带来很大挑战。
除此之外,详情抽取的短句和生成式模型D2S的融合目前还停留在提供item topics层面,我们还在继续尝试扩展Copy机制更有机的融合抽取和生成,留白,值得期待。
八、业务场景应用
目前我们的数据已经逐渐在搜索和搜索外场景应用,简单介绍下,欢迎合作。8.1 单品推荐理由8.1.1 手淘挑尖货场景我们第一个全量的场景就是搜索的定位于高端用户的”挑尖货“场景,上线的是一句话导购形式的推荐理由。8月份做了下AB-test测试核心指标都有提升,已全量。
挑尖货场景导购短句效果图
8.1.2 其余不再具体介绍
8.2 智能清单
8.2.1 手淘 - 搜索双十一Tab和淘攻略
双十一Tab是搜索结果页的内容固定坑位中,会根据相关性等因素展示D2S的清单或招商的达人清单。下面是双十一Tab和淘攻略场景的产品PRD图,双十一期间开始生效,左边是SRP入口样式,右边是清单详情页。
8.2.2 其余场景也不再具体介绍
九、感想和未来规划
做下来这个项目,最大的感受是既惊喜又敬畏。惊喜的是原本图像是深度学习应用最为成功的领域,今天在NLP领域也可以完成过去想的到但做不了的事情,D2S模型写出的文章竟然也能如此的生动、富有渲染力,甚至很多产品、运营同学纷纷反馈很难辨别文章究竟是机器还是达人写作的。而另一层面则是这个过程中对人脑的敬畏,人类可以在创作中进行充分的演绎、联想,从更加丰富的层面上进行创作,表达自己的观点和立场,而今天的神经网络本质上还只是一个不具备思维能力的模式识别机。
我们重新思考下机器和达人之间的关系,现在一定是共生存的关系,机器一定需要依赖达人去学习,但是今天的机器写作可以去定义达人的入门门槛。像我们阿士比亚公众号的那句话所说:”在人工智能替代一切的将来,唯有超越阿士比亚的内容创造无可替代“。集团内其他team也有很多同学focus在NLP(NLG/NLU)领域或深度学习其他领域,希望我们能加强交流,一道把这个门槛提的更高。
最后感谢项目推进过程中所有合作方和项目组同学的付出和努力,感谢各个团队各位老大们的支持!
十、主要参考文献
如果对NLG领域感兴趣希望精读一些paper,可以看下我们精选的NLG、NMT和TextSummarization领域的以下这些paper。
Context-aware Natural Language Generation with Recurrent Neural Networks
Neural Text Generation from Structured Data with Application to the Biography Domain
Semantically Conditioned LSTM-based Natural Language Generation for Spoken Dialogue Systems
Towards Constructing Sports News from Live Text Commentary
What to talk about and how? Selective Generation using LSTMs with Coarse-to-Fine
Chinese Poetry Generation with Planning based Neural Network 2016
Neural Machine Translation by Jointly Learning to Align and Translate 2015
Google’s Neural Machine Translation System- Bridging the Gap between Human and Machine Translation
Temporal Attention Model for Neural Machine Translation
Effective approaches to attention-based neural machine translation 2015
Abstractive sentence summarization with attentive recurrent neural networks 2016
A neural attention model for abstractive sentence summarization 2015
Abstractive Text Summarization using Sequence-to-sequence RNNs and Beyond
Get To The Point- Summarization with Pointer-Generator Networks
SummaRuNNer- A Recurrent Neural Network based Sequence Model for Extractive
A Deep Reinforced Model for Abstractive Summarization
-
深度学习
+关注
关注
73文章
5500浏览量
121109 -
自然语言
+关注
关注
1文章
287浏览量
13346 -
知识图谱
+关注
关注
2文章
132浏览量
7703
原文标题:淘宝总知道你要什么?万字讲述智能内容生成实践 | 技术头条
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
生成式AI如何在智能家居中落地?
基于用户生成内容的位置推断方法
智能语音在广播内容中的应用表现
基于关键字的自定义古诗句生成设计与实现

2023年第一届人工智能生成内容国际会议(AIGC2023)
《生成式人工智能服务管理暂行办法》正式施行,商汤「数字水印」护航生成式AI可信和著作权保护
在线研讨会 | 9 月 19 日,利用 GPU 加速生成式 AI 图像内容生成






 工商网监
工商网监
评论